基于矩阵和权重下的并行改进算法*
2023-01-06黄树成
周 迎 王 芳 黄树成
(江苏科技大学计算机学院 镇江 212001)
1 引言
当今网络时代有着海量的信息,其中有很多隐藏的人们未知的相互关系,为了找到其中的关联,人们采用了数据挖掘[1]。数据挖掘方法被广泛使用,提起关联分析,人们最先想到的的就是“购物篮”的例子,这主要针对的是超市的消费顾客,通过关联规则挖掘算法,比如从海量的消费者购物数据中获取关联规则。
提取频繁项集的算法很多,最广为人知的一定有Apriori算法[2]。Apriori算法使用是一种先验性质,从下至上迭代。根据算法的性质,如果给定的项集是频繁项集,那么它所包含的非空子集也必是频繁项集。Apriori算法的步骤最关键一是寻找频繁项集,二是生成强关联规则[3]。然而,在挖掘过程中,算法最大的不足就是对数据库扫描多次,由此它将导致系统的输入输出开销增加,进一步使得算法的效率降低[4]。
为解决上述问题,本篇论文提出了改进算法RTI_Apriori。主要改进有两点:1)引入MapReduce,根据数据块的数量对数据进行并行处理;2)改变存储结构,使用布尔矩阵存储事务信息,减少系统扫描数据库的次数,并且通过删除矩阵中全为零的行,合并事务相同的行等操作来对矩阵进行压缩,由此提高算法效率[5]。
2 问题陈述
2.1 关联规则
项集即表示项的集合,可用I={i1,i2,i3,…,in}来表示数据库中的项的集合,其中ik(k=1,2,3,…,n)为项集中n个数据项[6]。项集的长度等于项集中所包含的数据项数,K-项集就表示了项集中包含了K个项。用D来表示在数据挖掘过程中用到的数据集,D={t1,t2,t3,…,tm},D由数据构成,其中tk(k=1,2,3,…,m)称为事务。每个事务都有其对应的独有标识,通常用TID来表示,每个事务则由若干个项组成,由此可知T⊆I。例如,超市中的所有可购买商品的集合就是项集I,每一个完成的购物交易就是一个事务T,一次交易完成后购物清单上的商品就是项。
关联规则可以形式化的描述为下列形式:若X,Y均为项集,X⊂I,Y⊂I且X∩Y=∅,则形如X→Y的蕴含表达式就是关联规则,它表示项X和项Y之间的关系,其中X和Y分别成为先导和后继,或称之为前件和后件。关联规则最重要的是展示两个事物之间的依赖关系,支持度与置信度是当中两个最重要的参数[7]。
支持度指数据项{X,Y}出现的概率,即在所有的事务总和中,X,Y同时出现所占的比重,可写为式(1)。置信度指包含X的事务中Y再出现的概率,即事务{X,Y}在事务X单独发生的情况下所占的比重,可写为式(2)。
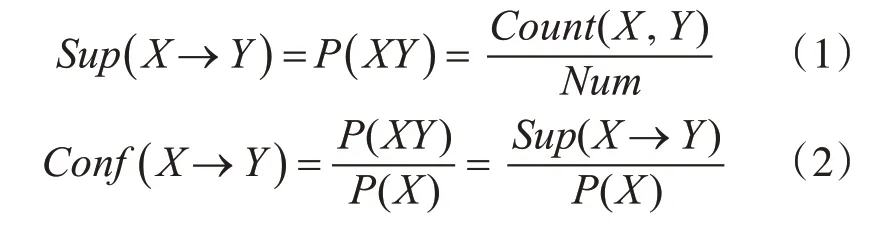
在开始前我们会事先设定一个最小支持度阈值(min_sp),假使一个项集M的支持度大于等于设定的阈值,即sup(M)≥min_sp,那么这个项集M就可以称作为频繁项集,若此时的频繁项集中包含了K个项,那么就称这项集为为频繁K-项集[12]。
2.2 Apriori算法
Apriori算法是一种广度优先搜索算法,主要是利用与自身项集连接和剪枝的操作对数据库中的数据进行迭代处理,预设的最小支持度(min_sp)是用来限制项集最少要出现的次数,通常根据具体的需求来设定。
最小置信度(min_conf)则是衡量最小可靠程度 的 数 值。如 果 能 够 有Sup(X⇒Y)/P(X)≥min_conf条件成立,那么就可以得到”X→Y”的规则[13]。
Apriori算法的步骤如下:
Step1:扫描全部数据得到候选1-项集得到集合为C1;依照设定的min_sp进而得到频繁1-项集的集合L1;设定n的初始值为1;
Step2:对Ln与本身连接生成的集合执行剪枝操作从而得到候选(n+1)-项集的集合Cn+1;根据算法性质,进而得到频繁(n+1)-项集的集合Ln+1;
Step3:此时若Ln+1集合不为空,对n进行加1操作后返回上一步;否则算法继续;
Step4:根据上述得步骤寻找隐藏其中的关联规则,至此算法结束[8]。
2.3 Apriori算法的缺点
如上所示,候选集的规模越大,所产生的消耗越多,呈现指数型增长,尽管在连接后进行了剪枝操作,但仍存在许多不必要的候选项集。若有104个频繁单项集,经过连接就将产生候选2-项集的数据为108个候选集对,从生成的大量候选集对里找到所需的候选集是算法中时间需求最大的阶段。计算支持度时算法要将集合Ck中记录的所有候选项集都计算一遍进行对比,造成不必要的资源浪费。
3 改进算法
3.1 改进算法思想
从最小化事务数据库扫描次数以及降低候选集数量方面着手改进,进而提高挖掘的效率。
首先,使用Map和Reduce来查找频繁1-项集,将数据分成N个数据块分配给计算机的Map进程来进行计算。接着考虑用布尔映射矩阵来存储事务项集。行表示事务,列表示项,分别用“0”和“1”来表示项Ii是否在事务Tj中出现,扫描数据库,根据数据库中的所有1-项集生成m*n阶布尔矩阵,对这个布尔矩阵进行操作。
3.2 矩阵
设矩阵中第i行,第j列所在的元素为aij,矩阵的行和列的数量分别由事务和项的个数决定。设定a,由这个规则所生成的矩阵就是事务所对的布尔矩阵。
若DB有m条交易记录和n个项,扫描并生成对应的布尔矩阵,则可得到一个m*n阶矩阵。在得出的矩阵后添加一行,用来统计每列中相同项出现的次数记为CountCi,在矩阵后添加两列,第一列为ConutRT,用来统计每一行中项的个数;第二列为Repetition,用来统计事务不同但包含的项相同的事务出现的次数,将这些事务压缩,以此实现数据库扫描次数减少的目标。
矩阵中每一列值为“1”的元素个数总和就是候选1-项集C1的支持度,根据CountCi和CountRT降序排列,将小于最小设定的最小支持度的项从矩阵中删除,从而得到频繁1-项集。数据子集的列与列之间进行“与”运算操作后,比对其“1”的个数和与最小支持度的大小关系,符合条件保留不符合删除,以此循环直到项集空则终止[9]。

表1 样本数据
设置最小支持度阈值min_sp=2,根据数据库的扫描结果,事务T002和事务T010所含项集相同,则可对其进行压缩,由此令事务T002的Repetition值为2,其余事务的值为1。根据结果降序排列,此得到矩阵D:
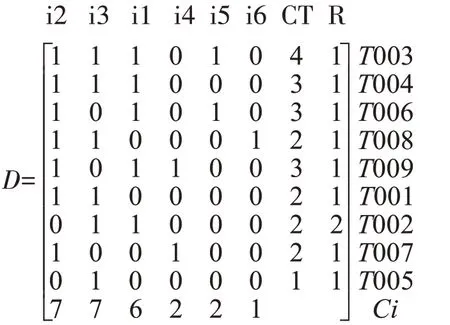
由上表可以看出,i6的支持数小于min_sp,则删掉删掉i6对应的矩阵所在列,由此得到矩阵D1:
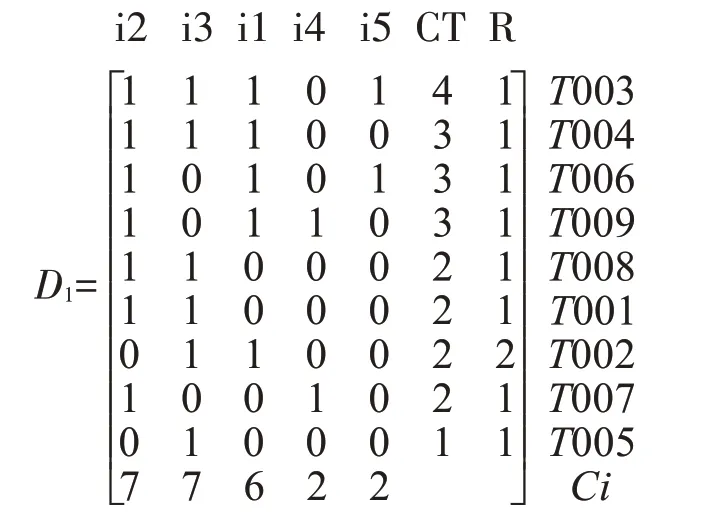
得频繁1-项集L1={i2,i3,i1,i4,i5}。
对矩阵D1采取进一步压缩,例如事务T005对应的事务数为1,小于2,所以在求频繁2-项集时可以直接删掉,重新计算等到矩阵D2:

对矩阵D2各列进行”与”计算,例如i2和i3,i2∧i3=11010100,sup_count(i2,i3)=1*1+1*1+0*1+1*1+0*1+1*1+0*2+0*1=4。因为sp_count(i2,i3)>min_sp。因为sp_count(i2,i3)=min_sp,所以{i2,i3}属于频繁2-项集,同理计算得出频繁2-项集L2={{i1,i2},{i1,i3},{i1,i5},{i2,i3},{i2,i5}}。
对矩阵D2采取进一步压缩,下一步求频繁3-项集,所以项集小于3的行向量可以删除,重新计算等到矩阵D3:

对矩阵D3各列进行“与”计算,例如i1,i2,i3,i1∧i2∧i3=1100,sup_count(i1,i2,i3)=1*1+1*1+0*1+0*1=2。因为sp_count(i1,i2,i3)>min_sp,所以{i1,i2,i3}属于频繁3-项集,同理计算得出频繁3-项集L3={{i1,i2,i3},{i1,i2,i5}}。
对矩阵D4进行进一步压缩,下一步求频繁4-项集,所以项集小于4的行向量可以删除,重新计算等到矩阵D4:

对矩阵D4各列进行”与”计算,i1∧i2∧i3∧i5=1,sup_count(i1,i2,i3,i5)=1*1=1。因为sp_count(i1,i2,i3,i5)<min_sp,所以{i1,i2,i3,i5}不属于频繁4-项集,算法结束。
综上频繁项集L=L1∪L2∪L3={{i2},{i3},{i1},{i4},{i5}},{i1,i2},{i1,i3},{i1,i5},{i2,i3},{i2,i4},{i2,i5},{i1,i2,i3},{i1,i2,i5}
4 算法性能验证及结果分析
为验证RTI_Apriori改进算法的有效性,将RTI_Apriori算法与原算法在相同的实验环境下进行实验结果比较测试。文中算法的实验环境如表1所示。

表1 实验软硬件环境配置环境
第一组实验主要测试方向是比较两种算法在不同最小支持度条件下的执行时间。
从图1的实验结果横向来看,两种算法的执行时间都随着最小支持度数值的增加而逐渐下降,纵向的看,在支持度数值一致的情况下,RTI_Apriori算法的执行时间明显更小,主要原因是RTI_Apriori算法在寻找频繁项集的过程中只需要扫描一次数据库,从而算法的执行时间减少了,效率提高了[14]。

图1 不同最小支持度条件下的执行时间
第二组实验主要测试了两种算法在事务数量不同的情况下的执行时间。
从图2的实验结果看出,两种算法的执行时间都随着事务数量的增加而逐渐上升,而且RTI_Apriori算法的执行时间在事务数量相同的情况下更优[15]。当事务数量比较小时,RTI_Apriori算法和Apriori算法的执行时间差距并不大,但两者的执行时间的差距随着事务数量的增长而变大。

图2 事务数量不同的情况下的执行时间
从上述的两组实验结果可以看出,改进后的RTI_Apriori算法的执行效率更高,花费的时间更短。RPI_Apriori算法避免了原算法多次扫描数据库的缺陷,时间和空间效率都得到了提升。
5 结语
本文针对Apriori算法在挖掘频繁项集时一些固有问题进行算法改进,引用了布尔矩阵,使得算法在执行过程中不需要对数据库进行多次扫描,从而避免算法执行过程中出现的大量冗余候选集的问题。分析改进算法RTI_Apriori算法,并结合实际用例模拟了算法的执行过程。最后,两组实验数据的实验结果也表明RTI_Apriori算法更优。
