基于半监督学习的中文电子病历命名实体识别
2023-01-05张杰,黄杰,万健
张 杰,黄 杰,万 健
(浙江科技学院 信息与电子工程学院,杭州 310023)
中文电子病历(chinese electronic medical record,CEMR)具有安全可靠、时效性强、存储便利等优点,已经被广泛应用于医疗体系中[1]。面向中文电子病历的命名实体识别(named entity recognition,NER)指从CEMR中识别出医疗相关的实体名称,如疾病名称、病症描述、药物名称等。命名实体识别技术可用于挖掘CEMR中包含的医疗信息,基于医疗信息构建的知识库和知识图谱可以辅助医生完成疾病诊断和药物推荐等工作[2]。因此,研究中文电子病历命名实体识别具有现实意义和实际经济价值。
随着深度学习技术和神经网络模型的不断发展,卷积神经网络(convolutional neural network,CNN)、双向长短期记忆网络[3](bidirectional long-short-term memory,BiLSTM)、双向门控循环单元[4](bidirectional gated recurrent unit,BiGRU)、条件随机场(conditional random field,CRF)等模型被广泛应用于NER任务中。医疗领域包含众多专业名词,直接将通用领域NER模型应用于中文电子病历命名实体识别任务时,模型的识别效果不佳,研究者将医疗领域特征引入NER模型,有效地提升了模型的实体识别效果。Wang等[5]提出一种基于多粒度语义字典和多模态树的NER模型,利用多模态树提取词汇特征及词边界特征,试验结果表明该模型能显著提升实体识别的效果。Ji等[6]提出一种将医疗词汇信息和词语纠错规则引入BiLSTM-CRF的集成模型,试验结果表明该模型在准确率和召回率上均优于传统NER模型。Yin等[7]提出一种基于部首级特征和自注意力机制的NER模型,试验结果表明该模型能显著提升实体识别的效果。Wu等[8]提出一种融合多特征的医疗NER模型,使用预训练语言模型获得文本的字符特征,引入BiLSTM提取文本的部首特征,试验结果表明该模型极大地提高了医疗实体识别的性能。
上述方法引入额外的医疗特征(如词典特征、部首特征等)来提升实体识别效果,但是,这类方法依赖于大规模的标注语料和文本特征。现存的中文电子病历标注语料十分匮乏且规模较小,而未标注的中文电子病历语料却海量且易获得,如何利用未标注语料来提高NER效果已成为研究的热点[9]。部分研究者提出利用海量未标注医疗文本进行训练的语言模型,如Tang等[10]提出一种融合语言模型和自注意力模型的方法,利用大量的未标注医疗语料训练双向语言模型,深入捕捉医疗文本的语义特征;Wen等[11]使用双向语言模型和掩码语言模型获取未标注医疗语料中包含的上下文语义特征,分别通过权重迁移和特征融合的方法与字符特征向量进行拼接,有效地提升了NER效果;Yu等[12]使用海量的未标注生物医学文本训练基于转换器的双向编码表征模型[13](bidirectional encoder representation from transformers,BERT),将自举算法结合NER模型进行迭代训练,充分利用有限的标注语料和大量未标注语料,显著提升实体识别效果。以上3种方法利用语言模型训练大量未标注语料,通过捕捉文本中的深层语义特征来提高识别的准确率,然而在缺乏大量未标注训练语料或训练语料长度较短的领域,使用该类方法进行命名实体识别则效果欠佳。
针对上述问题,本研究提出一个基于半监督学习的融合双向语言模型(bidirectional language model,BiLM)和自举(bootstrapping)算法的命名实体识别模型(BiLM_BNER模型),该模型使用大量未标注的医疗文本训练BERT和双向语言模型。BERT用于获取CEMR文本的字符向量,BiLM用于获取医疗文本的上下文语义特征向量。此外,引入医疗词典来构建CEMR文本的词典特征向量。为了充分利用未标注医疗语料中包含的语义信息,BiLM_BNER模型引入自举算法将未标注语料转换为高置信度的标注语料,通过模型的迭代训练来不断扩大标注语料的规模以提升模型的识别效果。
1 BiLM_BNER模型介绍
1.1 整体模型
图1为BiLM_BNER模型结构示意图,BiLM_BNER集成模型包含BERT模型、BiLM模型、词典特征、BiGRU-Attention-CRF及bootstrapping算法。BiLM_BNER模型训练的具体流程如下:1) 利用未标注医疗文本训练BERT和BiLM,学习医疗文本的字符向量表示和上下文特征向量表示;2) 给定中文医疗文本序列W=[w1,w2,…,wm],wt(t∈[1,…,m])表示一个中文字符,BERT模型将文本中的字符转化为向量表示hc=[hc1,hc2,…,hcm],hct(t∈[1,…,m])为字符的向量表示形式;BiLM获得字符在病历文本的上下文特征向量hf=[hf1,hf2,…,hfm]和hb=[hb1,hb2,…,hbm],hft、hbt(t∈[1,…,m])分别为表示正向语言模型和反向语言模型的输出结果;构建医疗词典,将词典结合双向最大匹配算法来标注训练文本中的医疗词汇,构建词典特征向量hw=[hw1,hw2,…,hwm],hwt(t∈[1,…,m])为字符对应的词典特征向量;3) 融合字符特征向量、上下文特征向量和词典特征向量,将融合结果输入BiGRU-Attention-CRF进行训练,训练好的模型通过预测未标注中文电子病历文本得到候选标注语料;4) bootstrapping算法设定最优阈值来筛选候选标注语料中置信度高的新标注语料,将其加入初始医疗标注数据集后继续训练NER模型;5) 重复步骤4,随着NER模型的迭代训练,初始标注数据规模不断扩大,模型的识别效果不断提升,迭代终止条件为设置的最大训练次数或模型的F1值达到最大值。
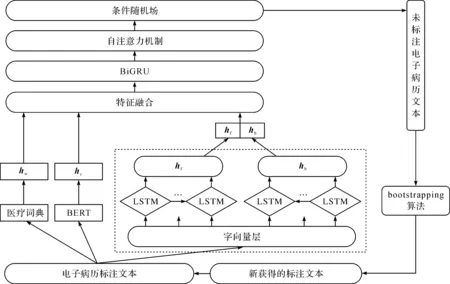
图1 BiLM_BNER模型结构示意图
1.2 双向语言模型
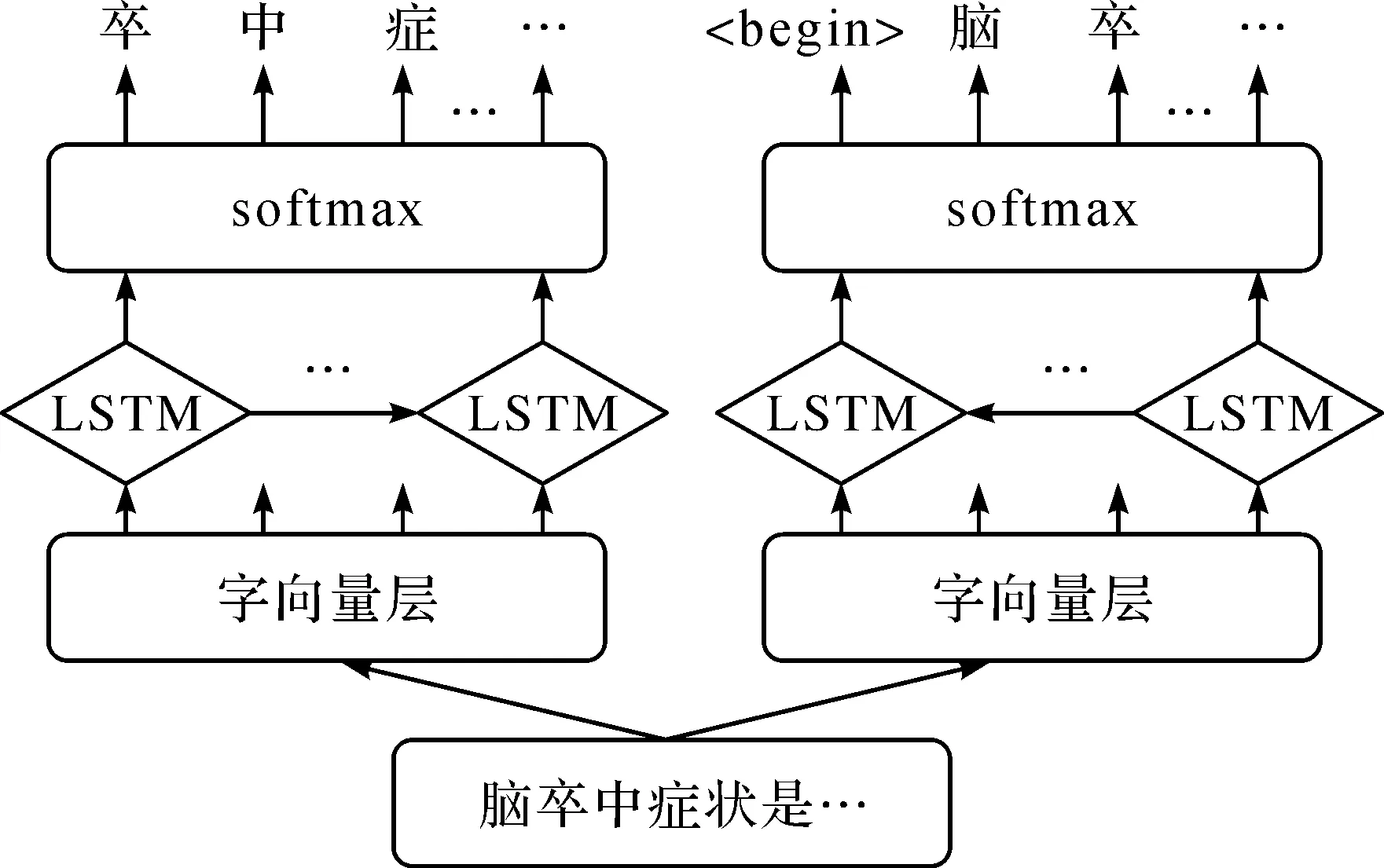
图2 双向语言模型结构示意图
语言模型(language model,LM)可以预测句子序列出现的概率,能够从大规模自然语言中学习到丰富的语义知识和内在的规律,目前被广泛应用于自然语言处理任务中[14]。双向语言模型由正向LM和反向LM组成,LM包含字向量层、LSTM层和softmax层。图2为双向语言模型的结构示意图。
BiLM的训练流程如下:1) 字向量层使用字转换向量模型(word to vector,word2vec)[15]技术将中文字符处理成向量表示形式,将字向量分别输入正向LSTM和反向LSTM中提取文本特征,正向LSTM能够根据历史信息预测当前字符wt的后一个字符为wt+1,反向LSTM能够根据未来的信息预测出其前一个字符为wt-1;2) 将正向LSTM和反向LSTM输出的特征向量分别输入softmax层中计算字符出现的概率。
以正向LM为例,输入文本序列表示一个中文字符,通过word2vec处理后得到中文字符的向量表示ct,将ct输入正向LSTM单元得到隐藏层的输出向量hf,t。
hf,t=LSTMf(ct,hf,(t-1);bf)。
(1)
式(1)中:hf,t为LSTM的隐藏层输出;ct为字向量;hf,(t-1)为上一时刻LSTM隐藏层的输出向量;bf为正向LSTM模型的参数。
LSTM的输出结果包含了每个标签的预测分值,将LSTM的输出向量输入softmax层,计算字典中各个字符在当前位置出现的概率
(2)
以句子“脑额叶损伤的表现”为例,正向LM输出结果为“额叶损伤的表现
我们使用大量的未标注医疗文本分别训练正向语言模型和反向语言模型,使得模型学习到医疗文本的语法和语义信息。在训练BiLM_BNER模型时,我们将正向语言模型和反向语言模型的softmax层去除,固定语言模型的权重,利用BiLM提取电子病历文本的上下文语义特征,将正向语言模型和反向语言模型对应位置的特征进行拼接。
1.3 中文医疗语料预训练的BERT模型
BERT模型将多层双向变压器(transformer)模型作为编码器,在训练时能更好地捕捉文本中上下文的语义信息,有效地解决了word2vec存在的一词多义问题。图3为BERT模型处理字向量过程示意图,BERT模型的输入由字向量、句向量和位置向量叠加生成,BERT模型通过查询字向量表将中文序列中的字符转换为字向量表示,句子向量用于区分不同的句子,位置向量用于区分句子中不同位置的字符,将三者进行拼接后输入多层transformer中提取文本特征,最终的输出向量作为字符特征向量。以“[CLS]头晕[SEP]脑梗死[SEP]”为例,用[CLS]标识句子的开始位置,用[SEP]标识句子的结束位置,E表示向量表达,Trm表示transformer模型。
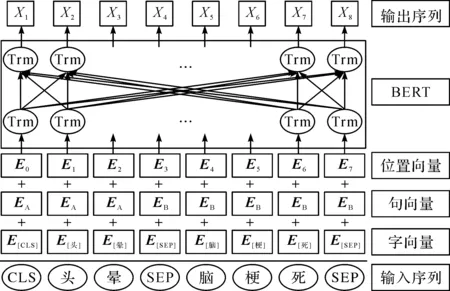
图3 BERT模型处理字向量过程示意图
Lee等[16]利用海量的英文生物医学语料库再次训练BERT模型,获得面向英文医疗领域的BioBERT模型。本研究使用中文医疗语料库训练BERT模型,使得BERT学到适合中文医疗文本的向量表达方式,将面向中文医疗领域的BERT模型命名为CbBERT模型,如何构建中文医疗训练语料库的过程将在2.1节做详细介绍。本研究参照BERT模型提出者的思路构建BERT模型并设置模型参数,将医疗txt文本处理成一个.tfrecord文件,调用run_pretraining.py进行预训练,训练完成后得到一个.ckpt格式的TensorFlow模型,最终利用转换脚本将.ckpt格式转换为.bin格式的PyTorch模型。
1.4 构建词典特征模块
医疗领域词典中包含丰富的词汇特征,本研究通过引入词汇特征帮助NER模型识别实体的边界,从而提升实体识别效果[17]。使用CCKS2017和CCKS2018电子病历数据集中标注的医疗实体构建一个包含症状描述、检查检验、疾病诊断、身体部位和治疗方案的医疗词典,并获取搜狗医疗词库等互联网中包含的医疗词汇来进一步扩充词汇量。此外,使用分词工具对CCKS发布的电子病历和医院真实脑血管电子病历文本进行分词和词性标注,对人工筛选分词结果中符合要求的名词,将其加入医疗词典中。去除医疗词典的重复名词和噪声词汇,得到最终的医疗领域词典统计表,具体见表1。

表1 医疗领域词典统计表
利用医疗词典和双向最大匹配算法[18](bi-direction maximum matching,BMM)标注测试集中的电子病历文本的词语。BMM算法以匹配词汇量多且词语长度宜长为原则,选取正向最大匹配法和反向最大匹配法的分词最优解。将匹配到的实体根据其类型进行标注,为了标注实体的边界信息,使用“B-”标注实体首字符,使用“I-”标注实体的其他字符,非实体则用None标注。以“因头痛伴心悸,检查心电图和颅脑CT”为例,实体类型标注结果为“None B-Symptom I-Symptom None B-Symptom I-Symptom None None None B-Check I-Check I-Check None B-Check I-Check I-Check I-Check”。将实体类型名称随机初始化成一个50维词典特征向量,并将当前字符对应的实体类型名称转化为词典特征向量。
1.5 BiGRU-Attention-CRF模型
BiGRU模型用于获取医疗文本的上下文语义特征,但BiGRU模型存在长距离依赖问题,其获取语义信息的能力会随着文本序列的增加而减弱,引入自注意力机制可有效解决此问题。自注意力机制能够忽略字词之间的距离,通过计算依赖关系来增大文本中重要字词的权重,从而解决BiGRU模型存在的长距离依赖问题。CRF模型训练过程中能自动地学习标签之间的约束关系,利用维特比算法解码生成最优标注序列。图4为BiGRU-Attention-CRF模型的序列标注过程示意图。
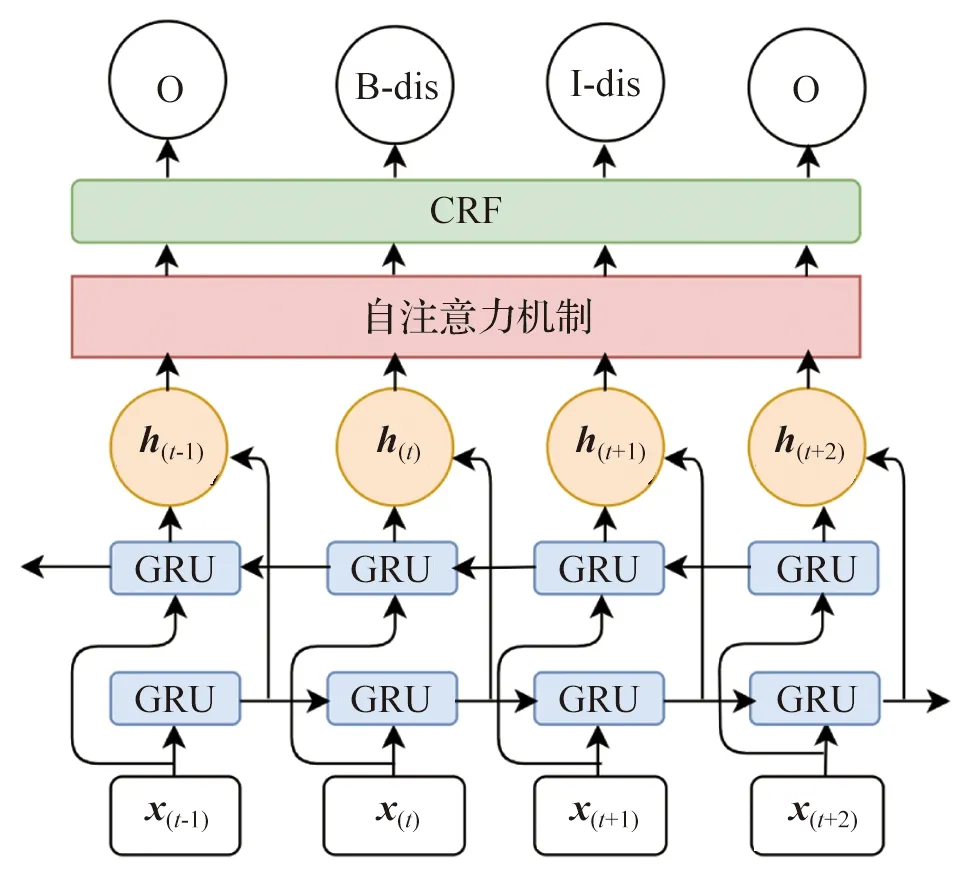
图4 BiGRU-Attention-CRF模型的序列标注过程示意图
1.6 bootstrapping算法
bootstrapping算法可以利用有限的样本资源进行多次重复抽样,从而建立起一个足以代表母体样本分布的新样本[19]。图5为bootstrapping算法训练流程示意图。bootstrapping算法的训练过程如下:1) 将一个数据规模较小的标注数据集作为初始数据集,NER模型在初始数据集上进行训练;2) 训练好的NER模型用于预测未标注医疗语料,得到候选标注语料,bootstrapping算法通过设置阈值来筛选候选标注语料中置信度较高的语料,将符合要求的候选标注语料合并到初始标注数据集中,再次训练NER模型;3) 重复步骤2,迭代训练NER模型,迭代终止的条件是达到设定的最大训练次数或者模型的识别效果不再提升。

图5 bootstrapping算法训练流程示意图
2 试验及分析
2.1 数据集
2.1.1 医疗领域未标注数据集
利用爬虫技术爬取:“疾病百科问药网”的疾病简介、症状描述、医治方案等文本,“寻医问药网”等在线咨询网站中的疾病信息和诊断依据文本,“中国公众健康网”中的疾病症状、诊断、治疗方案等医疗方案文本,以及CCKS比赛公开的无标注电子病历及我们从合作医院获得的中文电子病历。对上述医疗文本经过数据清洗,删除包含特殊字符、无关医疗的噪声句子,再经过分句后最终获得一个包含92 784个医疗句子、总计大小为1.5 GB的结构化医疗未标注数据集。
2.1.2 CCKS CNER医疗数据集
CCKS2017数据集包含已标注的400份病历文档,将其中300份作为训练集用于模型训练,100份作为测试集,数据集中标注了5类实体(症状体征、检查检验、疾病诊断、治疗方案、身体部位)。CCKS2018数据集包含一个训练集和一个测试集,分别包括600个医疗记录和400个医疗记录,标注了5类实体(解剖部位﹑症状描述﹑独立症状、药物、手术)。2个数据集的实体类型和数量统计分别见表2和表3。

表2 CCKS2017数据集的实体类型及数量统计

表3 CCKS2018数据集的实体类型及数量统计
2.1.3 自建脑血管疾病数据集
我们从合作医院提供的400份临床电子病历中提取现病状、既往史、入院诊断、住院经过等医疗文本,总计获得1 062个文本,按句号划分,总计获得4 920个句子。使用pkuseg分词工具对句子进行分词,并组织3名医学专业人员结合专家构建的医疗词表对分词结果进行标注,获得一个脑血管疾病标注数据集。将标注完的80%的句子作为训练集,剩下的20%用于测试集。考虑医疗文本特征和后续构建医疗知识图谱所需的实体类型,我们定义了4种实体类型:1) 身体部位,包含身体器官,如“冠状动脉”“小脑半球”“右侧上颌窦”;2) 症状体征,由患病导致的不适,如“意识障碍”“头晕”“行走不稳”;3) 疾病诊断,包含疾病名称、综合征,如“高血压”“脑梗死”“脑血栓”;4) 治疗方案,包括治疗过程中涉及到的手术名称和药物名称,如“冠脉造影术”“阿司匹林片”。
脑血管疾病数据集的实体类型及数量统计见表4。

表4 脑血管疾病数据集的实体类型及数量统计
2.2 试验基本设置
试验所用服务器配置如下:CPU为i7-8700,运行内存为16 GB,显卡为GeForce RTX 2080Ti。模型在Ubuntu操作系统下使用PyTorch 1.12进行训练。
BiLM_BNER模型的参数主要包含CbBERT模型、BiLM模型及BiGRU-Attention-CRF的参数。CbBERT使用BERT-base-Chinese-uncased模型参数进行初始化,所以两者参数相同,共计12层双向transformer,transformer的隐藏层的维度设置为768、注意力机制头数为12、模型参数数量为个。BiLM模型设置字向量维度为128,LSTM隐藏层的维度设置为128,句子的批处理大小为32句,最大训练次数为50,使用自适应时刻估计(adaptive moment estimation,Adam)算法优化模型参数,引入随机失活方法防止过拟合问题,BiLM的参数配置见表5。
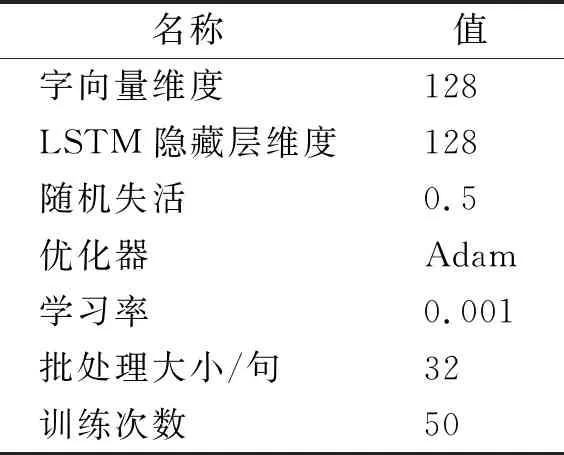
表5 BiLM的参数配置
BiGRU-Attention-CRF设置最大训练次数为100,批处理大小为32句,GRU隐藏层的维度设置为128,BiGRU-Attention-CRF的参数配置见表6。
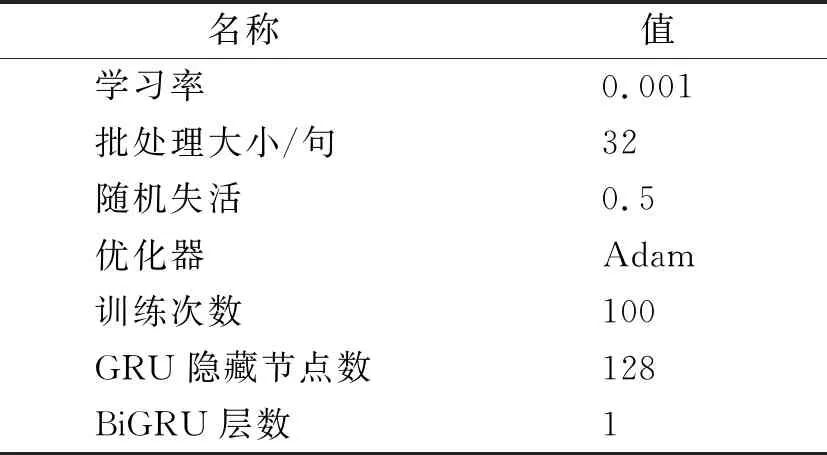
表6 BiGRU-Attention-CRF的参数配置
2.3 评价指标
NER任务中,通常采用准确率(precision,P)、召回率(recall,R)和F1值作为评价模型性能的指标,3个评价指标的计算公式如下:
(3)
式(3)中:TP为预测结果和实际结果均为正例的样例个数;FP为实际结果为反例且预测结果为正例的样例个数;FN为实际结果为正例而预测结果为负例的样例个数。
2.4 试验结果与分析
2.4.1 bootstrapping算法最优阈值试验
设计相邻阈值间隔为0.1,阈值区间为0.1和1.0的试验,探究bootstrapping算法在不同医疗数据集上的最优阈值。BiLM_BNER模型的F1值随阈值变化示意图如图6所示。
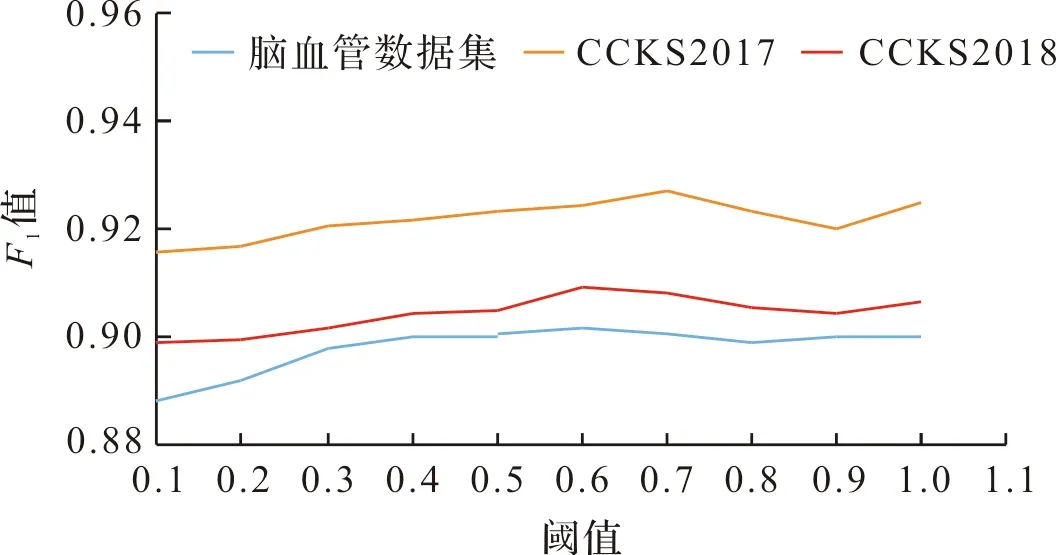
图6 BiLM_BNER模型的F1值随阈值变化示意图
当阈值为0.6时,BiLM_BNER模型在自建脑血管数据集和CCKS2018数据集的F1最高值分别为90.16%和90.93%。当阈值为0.7时,BiLM_BNER模型在CCKS2017数据集的F1值最高为92.72%。试验结果表明,最优阈值与标注数据集的数据规模和实体类型数量、未标注数据集的数据规模有关,当标注数据较少时,需要降低阈值才能获得更多的候选标注数据。
2.4.2 不同命名实体识别模型对比试验
设计对比试验来验证BiLM_BNER模型在中文电子病历实体识别任务的有效性,试验对照组包括通用领域NER模型、引入额外特征(包括部首特征和词典特征)的NER模型和基于预训练语言模型的NER模型。具体如下:1) 通用领域NER模型,如BiLSTM-CRF、BiGRU-CRF、BERT-CRF及Qiu等[20]提出的残差扩张卷积神经网络(RDCNN-CRF)模型。2) 引入额外特征的NER模型,如Li等[21]提出的融合医疗词典信息和汉字偏旁部首特征的中文医疗NER模型,Wang等[17]提出的结合领域字典和BiLSTM-CRF的NER模型。3) 基于预训练语言模型的NER模型,如Luo等[22]提出的基于笔画ELMO和多任务学习的电子病历NER模型,Tang等[10]提出的一种融合预训练双向语言模型和自注意力机制的NER模型。不同命名实体识别模型对比试验结果见表7。

表7 不同命名实体识别模型对比试验结果
试验结果表明,与通用领域NER模型相比,引入额外医疗特征(包括部首特征和词典特征)的NER模型和基于预训练语言模型的NER模型可有效地提升其识别精度。本研究提出的BiLM_BNER将字符特征、词典特征和上下文语义特征进行融合,提取电子病历文本的深层语义特征,将bootstrapping算法结合NER模型,利用小规模标注语料和大规模未标注语料进行迭代训练,筛选新的置信度高的标注语料添加到初始标注语料,不断扩大标注语料的规模,因此,BiLM_BNER在脑血管数据集及CCKS2017和CCKS2018医疗数据集的准确率、召回率和F1值上均优于对比试验中的其他NER模型,从而证明了本模型在中文电子病历NER任务中的优良表现。
2.4.3 消融试验
设计消融试验来分析和验证CbBERT、BiLM、词典特征和bootstrapping算法对提升NER效果的作用,试验结果见表8。
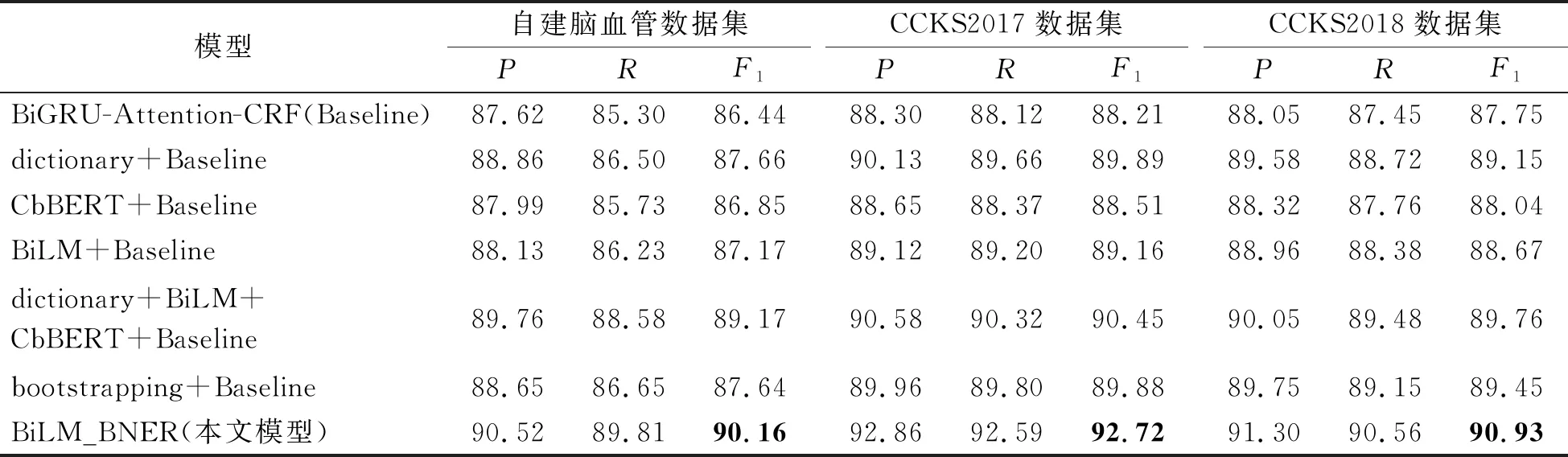
表8 消融试验结果
本试验将BiGRU-Attention-CRF作为基准模型,引入CbBERT、BiLM、词典特征、BiLM-CbBERT-词典特征进行试验。结果表明,引入CbBERT、BiLM、词典特征、BiLM-CbBERT-词典特征后,模型在脑血管数据集上的F1值分别提升0.41%、0.73%、1.22%和2.73%,在CCKS2017数据集上F1值分别提升0.3%、0.95%、1.68%和2.24%,在CCKS2018数据集上F1值分别提升0.29%、0.92%、1.4%和2.01%。试验结果表明引入额外医疗特征可以提升NER任务的识别效果,融合多个医疗特征可以实现多角度提取文本语义信息,提升效果更加显著。
将bootstrapping算法引入基准模型后,模型在脑血管数据集、CCKS2017数据集和CCKS2018数据集的F1值分别提升1.2%、1.67%和1.7%。将bootstrapping算法结合NER模型,利用小规模标注语料和大量易获得的未标注文本迭代训练模型,有效地提高了模型的识别精度。
3 结 语
本研究提出一种基于半监督学习的BiLM_BNER模型,通过构建中文电子病历文本的字符特征向量、上下文特征向量和词典特征向量,融合3个特征向量后输入BiGRU-Attention-CRF模型中进行序列标注,BiGRU-Attention-CRF可通过预测未标注语料得到候选标注数据。bootstrapping算法能筛选置信度高的候选标注语料,将其合并到初始标注语料进行迭代训练。BiLM_BNER模型在CCKS2017数据集、CCKS2018数据集和脑血管疾病数据集中均获得令人满意的实体识别效果。下一步我们将不断完善医疗词典,并尝试向模型引入词性特征、分词特征等,研究更高效的多特征融合方法,以提高模型的识别精度。
