多域特征融合的换脸视频检测算法
2023-01-05胡永健姚其森林育仪刘光尧刘琲贝
胡永健, 姚其森, 林育仪, 刘光尧, 刘琲贝
(1.华南理工大学 电子与信息学院,广东 广州 510640; 2.公安部物证鉴定中心,北京 100038)
0 引 言
近年来利用深度学习网络生成的Deepfake换脸视频在互联网上广泛传播。这类视频中的人脸区域被替换为他人的脸,从而实现身份篡改。若被恶意利用,将对社会舆论和国家安全造成极大的威胁和冲击。国内外研究机构迅速展开对换脸视频检测方法的研究,从不同角度出发,设计自动识别算法,判断一段视频是否为换脸视频。
换脸视频检测按技术路线大致可分为两大类:第1类基于传统手工特征,主要利用图像处理和机器学习方法提取换脸视频中的低级(也称像素级)伪造痕迹后再利用模式分类器进行分类;第2类基于深度学习,借助神经网络挖掘换脸视频的篡改特征。一般而言,基于第1类方法存在特征提取不充分的缺陷,其检测效果与第2类方法相比较差。
本文研究第2类方法。关于基于深度学习的换脸视频检测方法,文献[1]指出视频压缩使噪声衰减,难以通过单独分析噪声检测伪造人脸痕迹,故提出2个浅层面部视频伪造检测网络;文献[2]认为诸如AlexNet的经典卷积神经网络从训练数据上学习到的特征是表征图像内容而非篡改检测所需要的篡改痕迹,为了更好地学习篡改痕迹特征并削弱图像内容信息,定义了一种新的卷积层,称为受约束卷积层;文献[3]基于人脸反欺诈检测思想,利用注意力机制处理和改善特征图,除了实现二分类判断外还可定位篡改区域;文献[4]认为目前的Deepfake技术由于算力和生成时间的限制,只能合成固定尺寸的脸部,换脸必须经过仿射形变来匹配源脸,导致形变脸与其周边区域的上下文在分辨率上存在不一致,且修边的后处理也会留下明显操作痕迹,因此提出只需训练模型检测是否存在上述形变和修边噪声即可分辨真假脸,可极大减少训练时所需的负样本数量;文献[5]提出双支路结构,其中一条支路传播原始图像信息,另一条支路压制图像内容,放大利用高斯-拉普拉斯(Laplacian of Gaussian,LoG)算子得到的多频段信息;文献[6]采取多实例学习(multiple instance learning,MIL)的方式检测多人脸视频中的部分人脸置换问题;文献[7]认为在换脸视频检测中局部纹理特征比高阶语义信息更有用,提出结合空域图像和相位频谱来捕捉换脸视频的上采样伪影。文献[8]认为由Softmax损失函数监督学习得到的特征有分离能力但区分度不够大,同时固定的滤波器和手工特征无法从多样的输入人脸提取足够的频率特征,因此提出单一中心损失函数,旨在压缩类内自然人脸的不同,并在嵌入域增强类间差异,此外还提出一个自适应频率特征生成模块,以更全面的方式挖掘频率线索;文献[9]认为现有换脸方法还未充分考虑嘴型的匹配问题,提出利用唇读来检测是否发生换脸;文献[10]认为现有方法把真假脸视频检测模型化为基于全局特征的二分类问题,无法学习篡改一般性特征,同时也容易过拟合,因此提出先对人脸图像进行划分,通过学习各局部区域的相关性来提高泛化性和鲁棒性。
概括起来,文献[1-4]强调换脸残留的空域痕迹,文献[5-8]在利用空域特征的基础上还利用了频域或者时域特征,文献[9]利用了面部生理特征而文献[10]利用了图像内容的局部相关性。上述方法检测结果各有优劣,检测途径并无定论,然而都有一个特点:库内检测效果好但跨库测试性能下降显著,检测器存在泛化性能不足或过拟合问题。为此,本文提出一种基于多域特征融合的换脸视频检测算法,融合空域、频域和时域3个方面信息来解决这个问题。
1 多域特征提取、融合及分类网络
本文算法采取传统手工和神经网络结合的方式,将手工提取的RGB(红、绿、蓝)图像、离散傅里叶变换(discrete Fourier transform,DFT)频谱图和光流图输入多路卷积神经网络,借助其优异的特征提取能力更好地捕捉换脸视频在空域、频域和时域上的篡改痕迹。
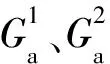
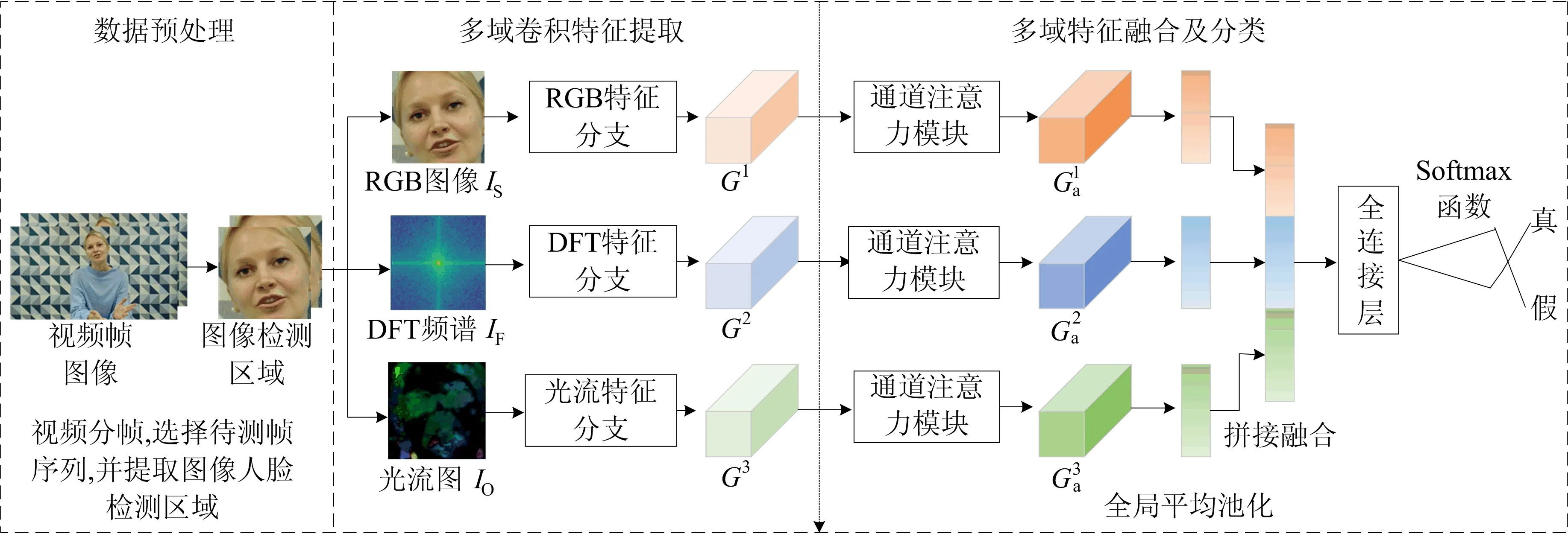
图1 基于多域特征融合的换脸视频篡改检测算法框架
1.1 数据预处理
用OpenCV对视频分帧,逐帧保存成视频帧图像,得到视频帧序列{f0,f1,…,fN-1},其中N表示单个视频分帧后的总帧数。为便于计算光流特征,首帧图像f0不作为检测对象,即待测视频帧序列为{f1,…,fN-1}。用Dlib工具库逐帧提取人脸矩形框作为检测区域。
1.2 多域卷积特征提取
提取各帧人脸的多域特征图像,具体过程包括:
(1)将各帧检测区域统一调整成224×224×3大小,作为空域RGB图像IS。
(2)通过二维离散傅里叶变换获取检测区域频谱信息,并进行中心化和对数变换以增加频谱细节,再将频谱图调整成128×128×1大小,作为DFT频谱图IF。
(3)采用Gunnar Farneback算法[12]对连续两帧的检测区域计算稠密光流场,可视化成224×224×3的光流图,作为时域光流图IO。
为提取上述图像深层卷积特征,构建多路卷积特征提取模块,包含如下3个分支:
(1)RGB分支,将RGB图像IS输入Xception[13]网络提取空域卷积特征G1。
(2)DFT特征分支,将DFT频谱图G2输入Xception网络提取频域卷积特征G3。
(3)光流特征分支,将光流图IO。输入ResNet50[14]网络提取时域卷积特征G3。
需要说明的是,在使用Xception和ResNet50网络进行特征提取时,本文对原网络进行了改造,去掉了用于特征分类的全局平均池化层和全连接层。
1.3 多域特征融合及分类
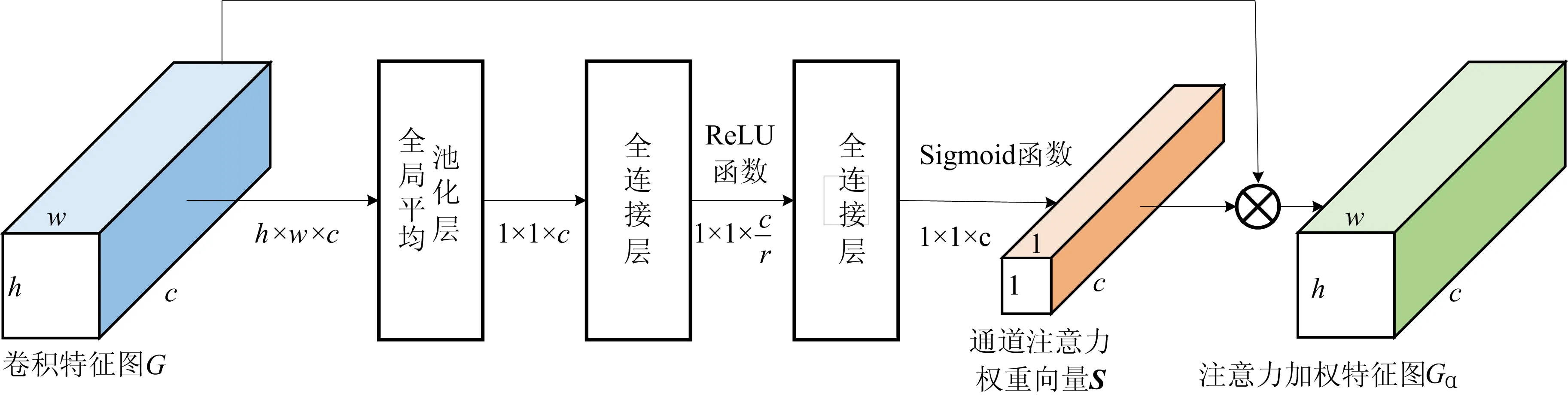
图2 通道注意力模块网络结构示意图
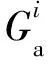
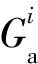
2 换脸视频检测流程
2.1 训练流程
(1)对视频数据进行预处理。将数据集的视频进行分帧,选择待测帧序列,并提取各帧图像的人脸检测区域。
(2)提取空域、频域和时域特征图像。提取各帧图像检测区域的RGB图像IS,并计算DFT频谱图IF和光流图IO,将IS、IF和IO归一化到[0, 1]区间,作为网络的输入。
(3)构建多路卷积神经网络,用于多域卷积特征的提取和融合。采用Adam优化器,初始学习率设置为1×10-4,批次大小(batch-size)设置为16,使用交叉熵损失函数作为模型训练损失函数。
(4)训练所述网络。计算损失并反向传播更新网络权重系数,采取提前停止策略避免模型过拟合,保存最小损失值对应的权重作为模型权重。
2.2 测试流程
对待测数据进行预处理,提取多域特征图像,归一化到[0, 1],输入训练完成的网络,输出测试样本被判决为真脸和假脸的概率。
3 实验讨论与结果分析
为了验证算法性能,在4个公开换脸视频数据集上进行了库内及跨库测试,使用半总错误率(half total error rate,HTER)、接收机操作特征曲线下方的面积(area under ROC curve,AUC)等指标对算法进行分析和评价。
3.1 实验数据库与环境
实验采用TIMIT、Fake Faces in the Wild(FFW)、FaceForensics++(FF++)[15]以及Deep Fake Detection(DFD)等近年公开的4个换脸视频数据库。其中FFW数据库只提供了换脸视频,为保证真假样本平衡,在视频来源相同的FF++数据库中选取了50段真实视频作为补充。FF++和DFD数据库包含多种压缩率的视频,取常用的C0和C23压缩率视频进行测试。基于文献[16]的研究结论,按照7∶2∶1的比例将数据库按人划分为训练集、验证集和测试集,并在不采取数据增广的条件下进行实验。
实验主要基于深度学习框架Keras实现,所用显卡为TITAN XP,系统为Ubuntu16.04,CUDA版本为9.0.176,Keras版本为2.2.4,OpenCV版本为4.1.2。
3.2 网络结构有效性验证
(1)注意力机制。注意力机制通过学习一个特征权重分布,并将特征权重与原始特征进行加权求和,以此突显重要的区域。根据注意力机制施加位置的不同,可分为空间注意力机制、通道注意力机制以及空间和通道结合的注意力机制等实现形式。
为研究不同注意力机制对算法性能的影响,将本文算法的通道注意力模块分别替换为ECA[17]、CBAM[18]、Triplet Attention[19]3种注意力机制,与本文采用的SE注意力机制进行对比实验。其中,ECA和SE属于通道注意力机制,CBAM和Triplet属于空间和通道结合的注意力机制。DFD(C23)训练数据库下不同注意力机制对比结果见表1所列。
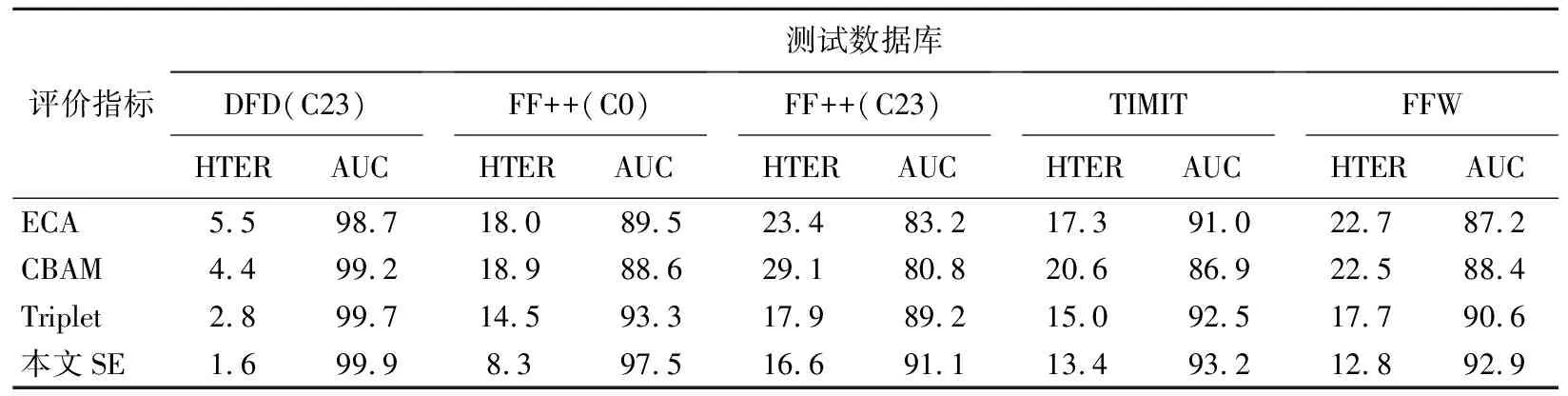
表1 不同注意力机制对比结果 %
由表1可知:采用ECA、CBAM和Triplet注意力模块的模型在库内和跨库测试时表现均不及本文算法的检测效果;本文的SE通道注意力机制优化了特征学习,使得HTER更小,AUC值更大,对各支路篡改特征的提取能力更强。
(2)特征融合方式。特征通道拼接、特征逐元素相加和决策层融合是3种常见的特征融合实现方式。为研究不同特征融合方式对算法性能的影响,本文设计了E1和E22组对比实验。E1采取特征逐元素相加的方式,将各支路输出的卷积特征经过全局平均池化,得到3个1×2×2 048维的特征向量,然后利用Softmax计算获取3个特征向量在各通道维度的权重,再逐通道加权求和得到1×2×2 048维的特征向量输入全连接层分类。E2采取决策层融合的方式,将各支路输出的卷积特征分别进行全局平均池化,并输入2通道的全连接层得到3个2维预测向量,最后利用Softmax计算对预测向量加权求和,作为最终的模型预测输出。
E1、E2与本文采用的特征通道拼接方式进行对比,DFD(C23)训练数据库下不同特征融合方式对比结果见表2所列,网络结构如图3所示。
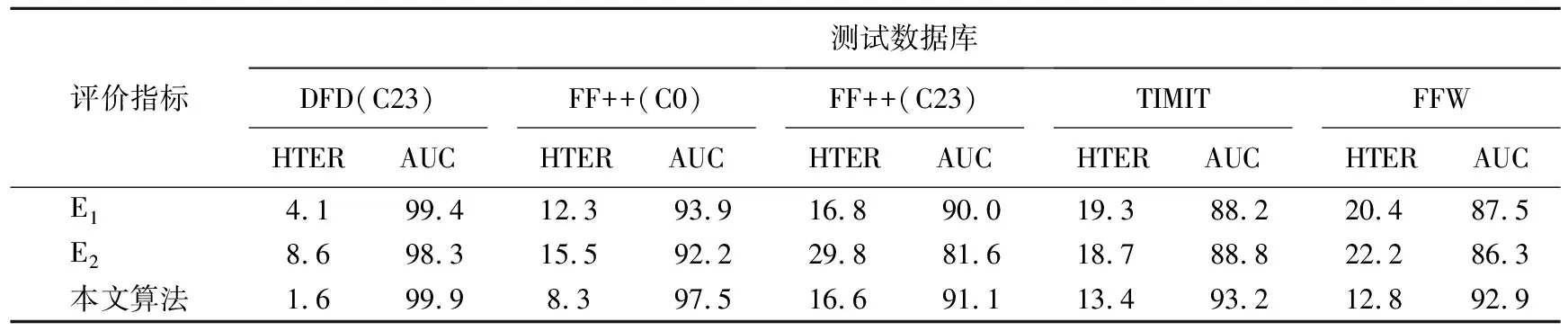
表2 不同特征融合方式对比结果 %
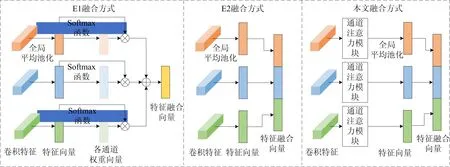
图3 特征通道拼接方式对比图
从实验结果可知,无论是特征逐元素相加模型E1还是决策层融合模型E2,其在库内及跨库测试的表现均差于本文采取的特征通道拼接融合模型。分析其原因有如下2点:① 特征逐元素相加需满足各个特征向量语义相似的先验条件,而本文算法提取的空域、频域和时域特征在特征语义上存在一定差异,DFT频谱丢失了位置信息,而光流图是反映运动信息;② 决策层融合方式往往在多个分类器性能相当的情况下表现较好,但本文的DFT分支和光流分支信息不全面,独立检测性能弱于RGB分支。另外,特征通道拼接方式可以最大程度地保留多域篡改信息,得到信息更丰富、鲁棒性更强的分类特征,因此模型的库内和跨库性能均得到改善。
3.3 与其他算法的对比与分析
为了对本文算法进行全面评估,选取近年来发表的6个国内外篡改检测算法[1-3,6,13,20]进行对比,其中文献[20]针对GANs(生成式对抗网络)假脸检测提出了3个轻量级网络,本文选用ShallowNetV1用于换脸检测。选用ShallowNetV1而非V2、V3是为了避免网络过浅导致无法提取稳定的检测特征。
(1)HTER比较。不同算法在DFD(C23)数据库和FF++(C0&C23)数据库训练模型的库内及跨库测试结果分别见表3、表4所列。表3中,本文算法在库内测试达到最优,HTER为1.6%。在跨FF++(C0)、FF++(C23)、TIMIT和FFW库测试时,除了MISLnet[2],本文算法的表现均优于其他算法,虽然MISLnet在FF++(C0)和FF++(C23)数据库上表现略优于本文算法,但在其他测试条件下HTER性能均不如本文算法。
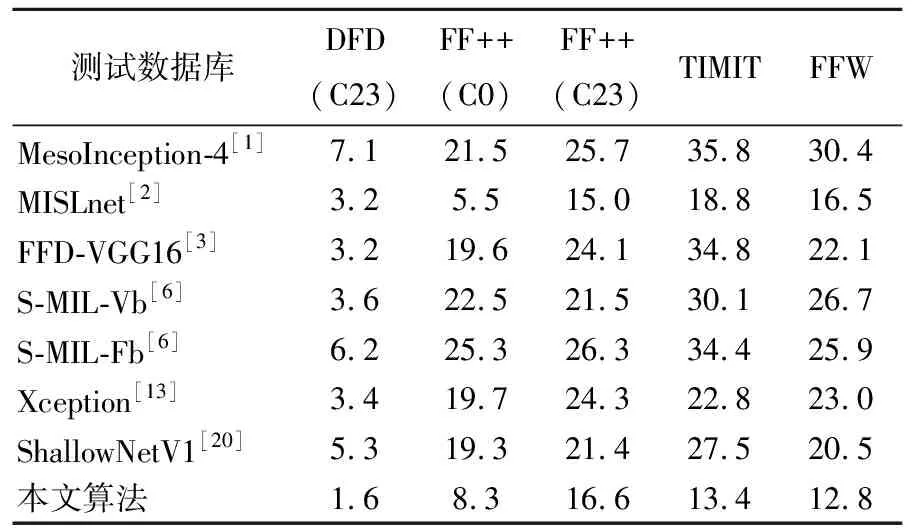
表3 不同算法在DFD(C23)数据库训练模型的HTER %
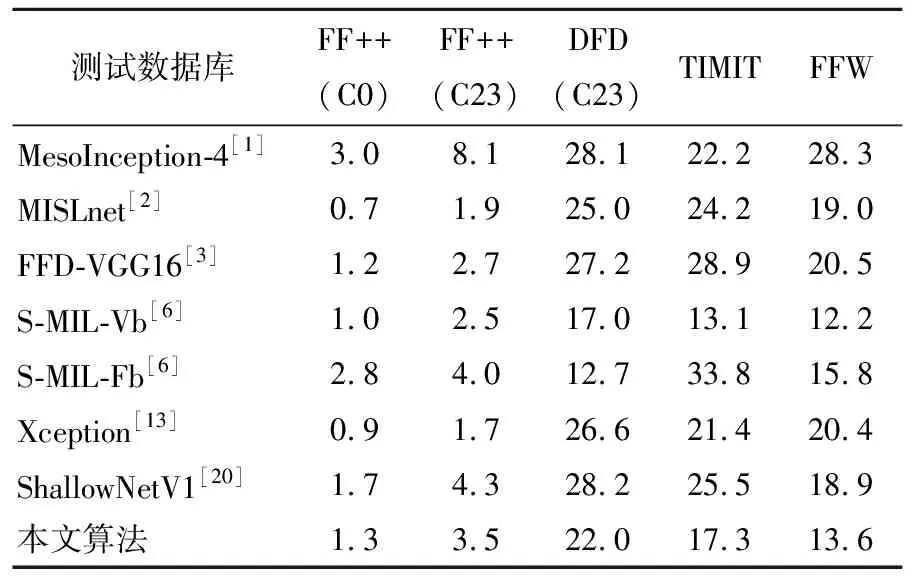
表4 不同算法在FF++(C0&C23)数据库训练模型的HTER %
在表4中,无论是库内还是跨库,本文算法的HTER值一直位于较低的水平,说明其误差小,总体表现稳定。其他所有算法在库内和跨库的HTER值均起落剧烈,说明它们的检测特征随库的不同变化大,检测误差不够稳定,泛化性能不好。
(2)AUC比较。不同算法在DFD(C23)数据库和FF++(C0&C23)数据库训练模型的库内及跨库测试AUC柱形图分别如图4、图5所示。与其他算法相比,本文算法在库内及跨库测试时达到最高或接近最高的AUC值,且在2个不同数据库训练的模型跨库测试表现更为稳定,与上述HTER指标比较结果一致,验证了本文算法性能优良且跨库稳定性好。
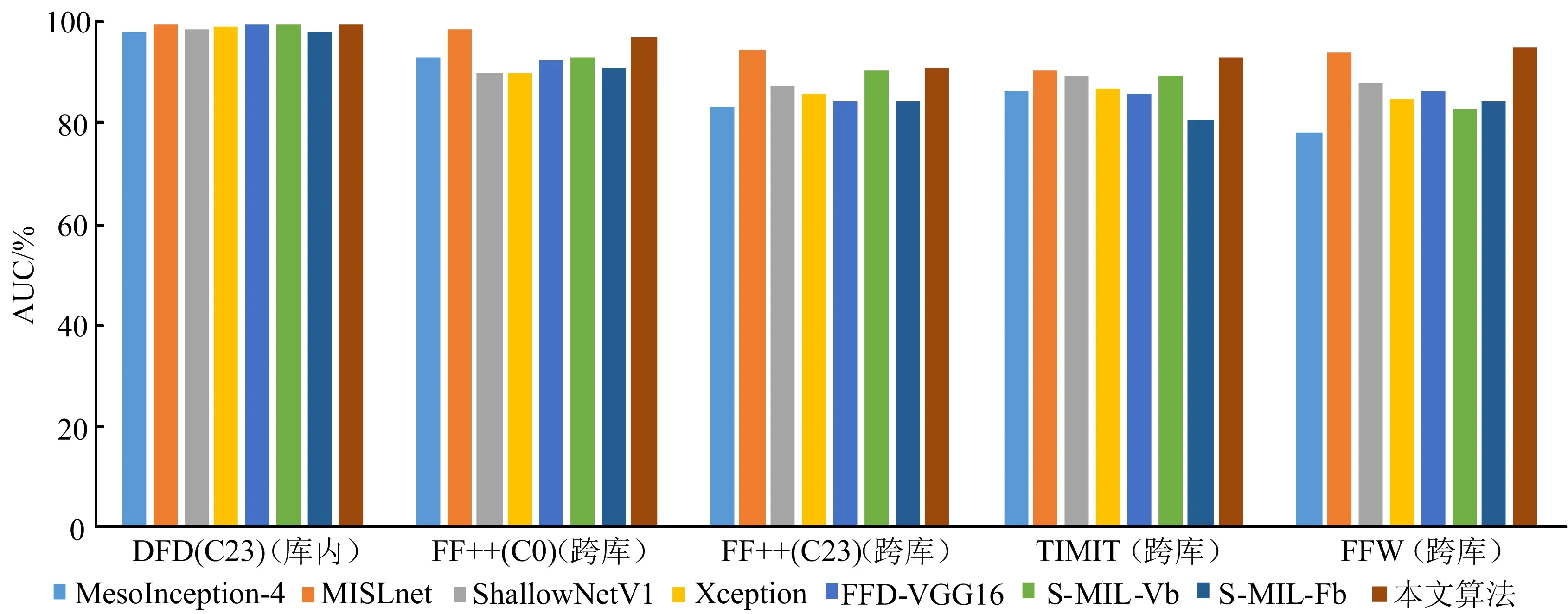
图4 不同算法在DFD(C23)数据库训练模型的AUC柱形图
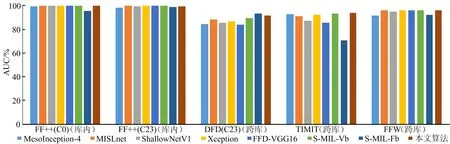
图5 不同算法在FF++(C0&C23)数据库训练模型的AUC柱形图
(3)复杂度比较。本文在相同的实验环境下,选取浮点运算次数(floating-point operations,FLOPs)和平均帧检测时间来评估算法的复杂度,见表5所列,其中FLOPs以百万(M)为单位,平均帧检测时间以ms(毫秒)为单位。具体选取FF++数据库中100段平均时长15 s的视频进行测试,并计算模型测试总时长,主要包括特征图像提取和结果判决2个步骤,最后根据测试总时长和测试总帧数计算平均帧检测时间。
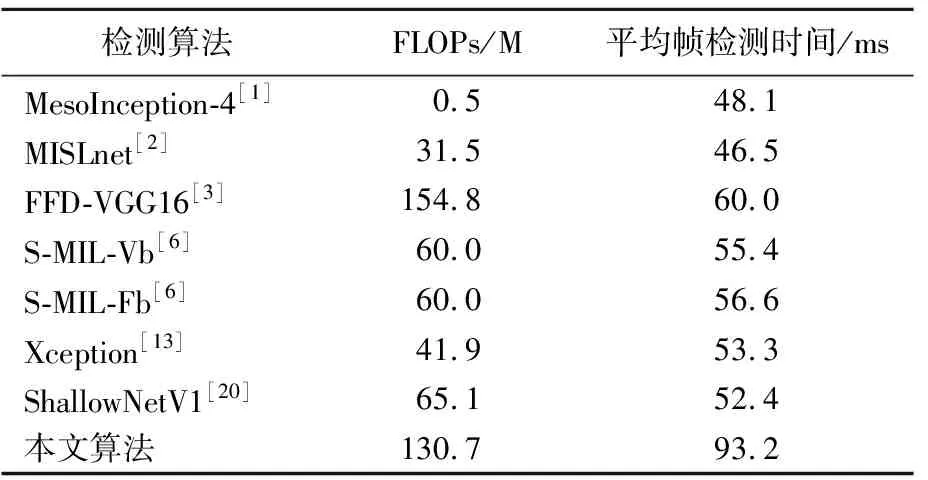
表5 不同算法的复杂度
与其他算法相比,本文算法因使用了多路卷积神经网络提取多域卷积特征,FLOPs相对有所增加,但少于FFD-VGG16[3]。同时由于本文算法需要额外计算DFT频谱图和光流图作为网络输入,平均帧检测时间相对较长。但从HTER和AUC指标比较看,本文算法的泛化性能更为稳定。牺牲部分FLOPs和检测时间来提高模型的检测精度及稳定性,在实际应用场景中有一定意义。
3.4 消融实验
本文用消融实验(C1、C2、C3、C4、Full)来验证算法各组成部分的有效性。消融实验C1使用了RGB分支,将RGB图像输入Xception网络进行训练;消融实验C2在C1的基础上添加了DFT特征分支构建双流网络进行训练;消融实验C3在C1的基础上添加了光流特征分支构建双流网络进行训练;消融实验C4利用3个特征分支构建多路卷积神经网络进行训练;消融实验Full在C4的基础上,在各支路添加了通道注意力模块进行训练,即本文算法模型,具体设置见表6所列。实验均采取特征通道拼接的方式实现各支路特征融合,DFD(23)训练数据库下消融实验结果见表7所列。
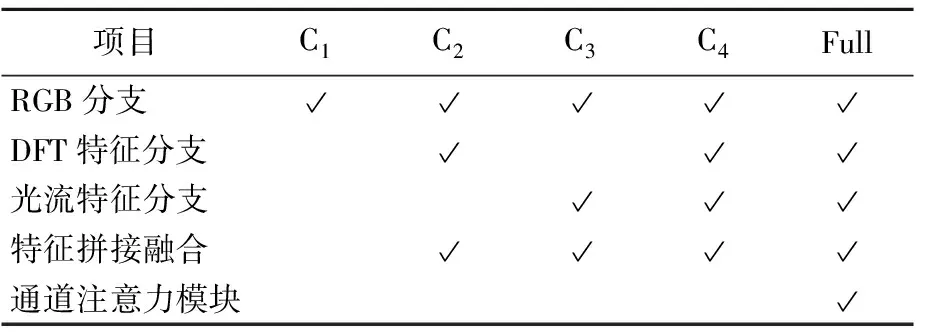
表6 消融实验设置
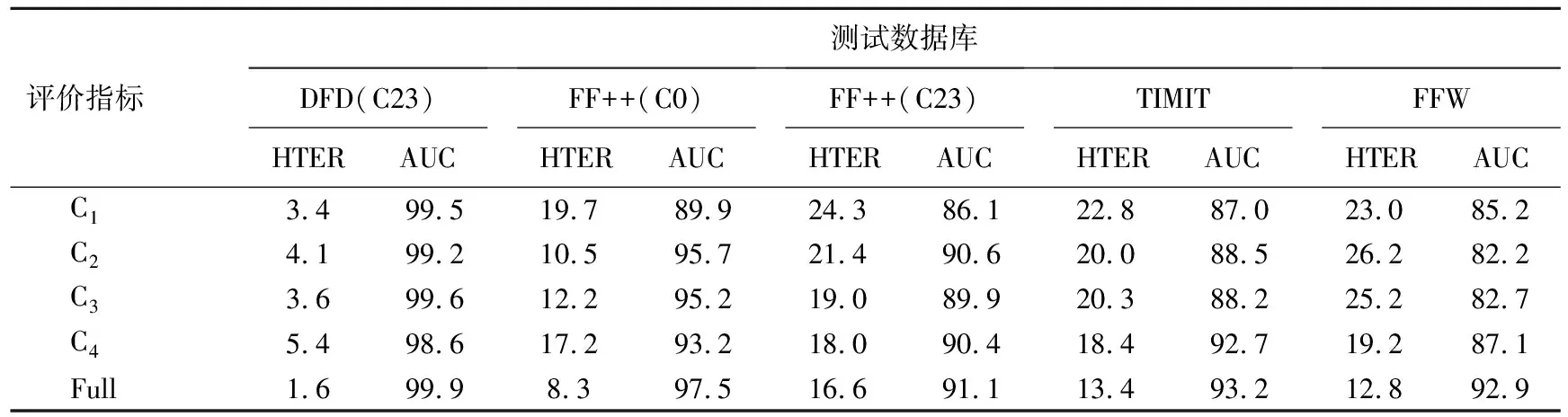
表7 消融实验结果 %
表7中,由C1、C2、C3的实验结果可知,在RGB分支的基础上,添加了DFT特征分支和光流特征分支的模型在FF++(C0)数据库、FF++(C23)数据库和TIMIT数据库的跨库测试HTER均有不同程度的降低,表明DFT特征和光流特征的引入对提高模型的跨库检测性能具有积极作用。
由C2、C3、C4的实验结果可知,消融实验C4通过多域特征拼接融合的方式,有效降低了模型在FF++(C23)数据库、TIMIT数据库和FFW数据库的跨库HTER,验证了多域特征融合的有效性,但在库内和FF++(C0)跨库测试中HTER有所升高,可能的原因是直接将多域特征拼接融合存在语义特征不一致的问题而影响融合后分类特征的鲁棒性。
对比消融实验C4和Full的实验结果,Full通过添加通道注意力模块进一步降低了模型的库内及跨库测试HTER,表明引入SE通道注意力机制有效提高了模型对多域篡改信息的提取能力,从而保证了融合后分类特征的鲁棒性。
本文算法在DFD(C23)数据库训练模型的库内及跨库测试ROC曲线如图6所示。
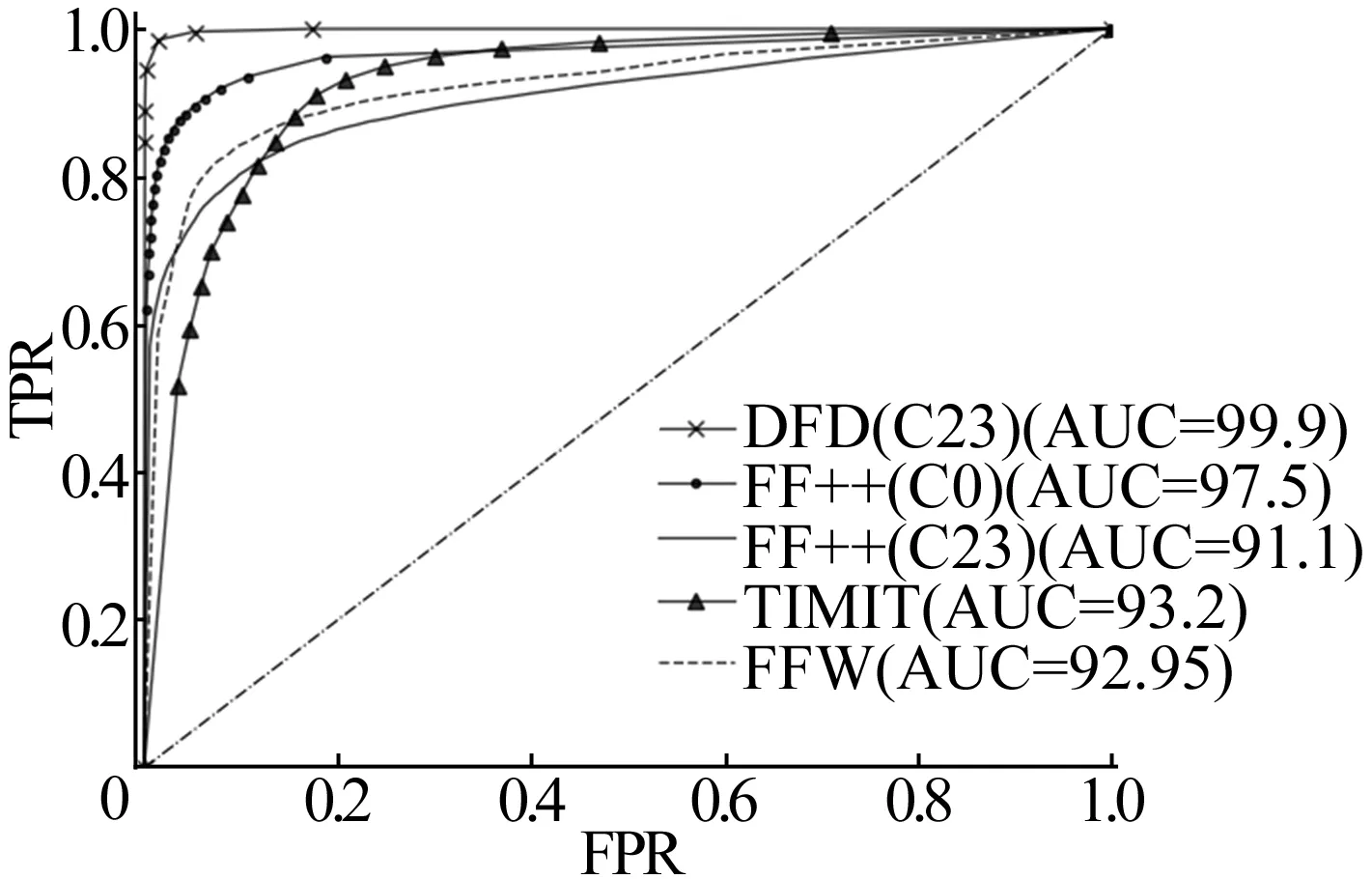
图6 本文算法在DFD(C23)数据库训练模型的ROC曲线
库内测试性能很好,AUC高达99.9%,同时在对多个数据库进行跨库测试时,ROC曲线分布相近且较接近左上角,验证了算法泛化性能良好。
4 结 论
本文基于多特征融合的思想,提出了一种基于多域特征融合的换脸视频检测算法,通过融合从空域、频域和时域分别提取的特征来丰富特征表示,使分类的鲁棒性更强。与其他同类方法相比,在保持良好库内检测性能的同时,有效提升了模型的泛化性能及稳定性。本文算法探索了将手工提取特征与深度学习网络有效结合的方式,实验结果验证了拓宽特征来源、扩大特征表征范围是解决换脸视频检测算法泛化性能瓶颈的有效技术路径。后续研究可基于本文算法框架,进一步筛选和引入区分度更强的篡改检测特征支路,同时也可对各支路特征提取网络进行优化。
