基于改进NSGA Ⅱ的时变路网污染路径问题多目标优化
2023-01-03郭运聪韩晓龙
郭运聪, 韩晓龙
(上海海事大学物流科学与工程研究院,上海 201306)
0 引 言
近年来,世界各国密切关注节能减排问题。在2020年第75届联合国大会中,国家主席习近平提到:“中国将提高国家自主贡献力度,采取更加有力的政策和措施,二氧化碳排放力争于2030年前达到峰值,努力争取2060年前实现碳中和。”据统计,交通运输行业的碳排放量占全球碳排放量的22%,其中70%以上的碳排放量来源于公路运输。随着我国城市化进程的加快,交通拥堵问题愈发严重且具有很强的规律性。在拥堵时车辆行驶速度较低,频繁的加速或减速造成油耗和二氧化碳排放量急剧增加,因此降低公路运输能耗、减少碳排放量的关键在于合理规划运输车辆出发时间和路径,在完成配送任务的同时减少碳排放量。
近年来,以节能减排为目标的污染路径问题引起了学术界的关注,该问题是带时间窗车辆路径问题(vehicle routing problem with time windows,VRPTW)的延伸,主要研究考虑碳排放量的车辆路径问题。BEKTA等[1]在2011年首次提出该问题,研究在最小油耗和最低驾驶员成本的综合目标函数下,每条弧(i,j)的最优行驶速度。DEMIR等[2]研究最小油耗和最短配送时间的双目标污染路径问题,并采用自适应大邻域搜索算法求解。DEMIR等[3]和SUZUKI[4]研究发现车速、载重、道路坡度和交通拥堵是影响油耗最重要的因素。MADEN等[5]发现随着拥堵程度的增加,车辆的油耗和碳排放量将显著增加。秦进等[6]提出基于节点时间窗变换以及速度和出发时间优化的两阶段算法,解决考虑拥堵情形的污染路径问题。葛显龙等[7]建立以最低成本和最短配送时间为目标的时间窗指派污染路径问题优化模型,并设计混合遗传禁忌搜索算法求解模型。
由于城市存在早晚交通高峰、路段限速、交通管制和意外事故等原因,城市交通路网具有时变特性,部分学者提出时变路网污染路径问题,也称时间依赖型污染路径问题(time-dependent pollution routing problem,TDPRP),该问题中大部分变量都随道路交通信息的变化而改变,例如交通流状况的改变会影响2个节点间的行驶速度和运输车辆状态。KUO[8]研究表明在时变路网情况下道路拥堵导致车辆缓慢行驶,对车辆的油耗和碳排放量产生重要影响。FRANCESCHETTI等[9]建立TDPRP的整数线性规划模型,在固定行驶路线后再优化车辆出发时刻和行驶速度。赵志学等[10]将时间划分为不同时段,用平均速度作为较短路段内的行驶速度,进而计算行驶时间。刘长石等[11]依据“先进先出”准则设计时间计算方法,引入交通拥堵指数,设计改进蚁群算法,有效避免交通拥堵。
综上所述,国内外关于污染路径问题已经产生一定的研究成果,为研究考虑交通拥堵的TDPRP提供了良好的基础,但也存在一定的局限性,主要体现在以下4个方面:(1)已有的关于污染路径问题的研究大多假设车辆行驶速度恒定,考虑交通拥堵的研究文献较少;(2)已有的关于污染路径问题的研究大多假设所有配送车辆在同一时刻从物流中心出发,关于车辆可以根据顾客需求和交通流量差异等情况在不同时刻出发的研究文献较少;(3)已有的污染路径问题研究普遍为车辆不停靠,采用车辆在配送过程中熄火停车等待作为拥堵规避策略的研究文献较少;(4)传统污染路径问题的初始种群选择通常随机生成,在面对较大的种群规模时,种群质量极其不稳定,采用算法优化初始种群的研究文献较少。
为克服上述局限性,本文考虑交通拥堵和不同时刻的交通流量状况,车辆在配送过程中可熄火停车等待,以规避交通拥堵;同时以最低碳排放量和最短配送时间为双目标,结合多目标优化理论,建立TDPRP多目标优化模型,并改进带精英策略的非支配排序遗传算法(elitist non-dominated sorting genetic algorithm,NSGA Ⅱ)进行求解;最后采用Solomon数据库算例验证模型和算法的有效性。
1 问题描述和假设
一个配送中心为城市不同区域的顾客配送货物,其中顾客位置、需求量和时间窗均已知,不同时段城市道路交通拥堵状况可从交通部门获得。交通路网流量具有实时变化的特征,配送车辆的行驶速度根据道路交通状况变化而改变。配送车辆可以根据顾客时间窗在不同时刻从配送中心出发,完成任务后返回配送中心。
为便于分析和研究,假设:(1)顾客位置、需求量和时间窗均已知,且不超过配送中心服务范围和车辆的最大负载能力;(2)任意2个顾客点之间的最短路线均已知,且配送路线在配送过程中不能改变;(3)当配送车辆在行驶过程中遇到严重交通拥堵时,可在配送途中熄火停车等待,以规避交通拥堵;(4)车辆在行驶过程中产生碳排放量,在停靠时间内发动机关闭,不产生碳排放量;(5)城市道路平整,不考虑道路坡度。
2 数学模型
2.1 拥堵规避策略
已有的污染路径问题研究普遍为车辆不停靠,即车辆在从节点i行驶到节点j的过程中没有等待或空闲,无论遇到什么情况,车辆都处于行驶状态。当目标函数是最低碳排放量时,在交通拥堵时车辆低速行驶会对目标函数产生消极影响,故引入拥堵规避策略,规避交通拥堵,以降低车辆行驶过程中的碳排放量。图1为车辆在3个相邻时段的行驶速度分布,其中:时段1为中速时段,此时车辆行驶速度略低;时段2为低速时段,此时道路发生拥堵,车辆行驶速度最低;时段3为高速时段,此时车辆行驶速度只受道路最高速度限制。为达到最低碳排放量,设置高速时段的速度为最佳经济速度。
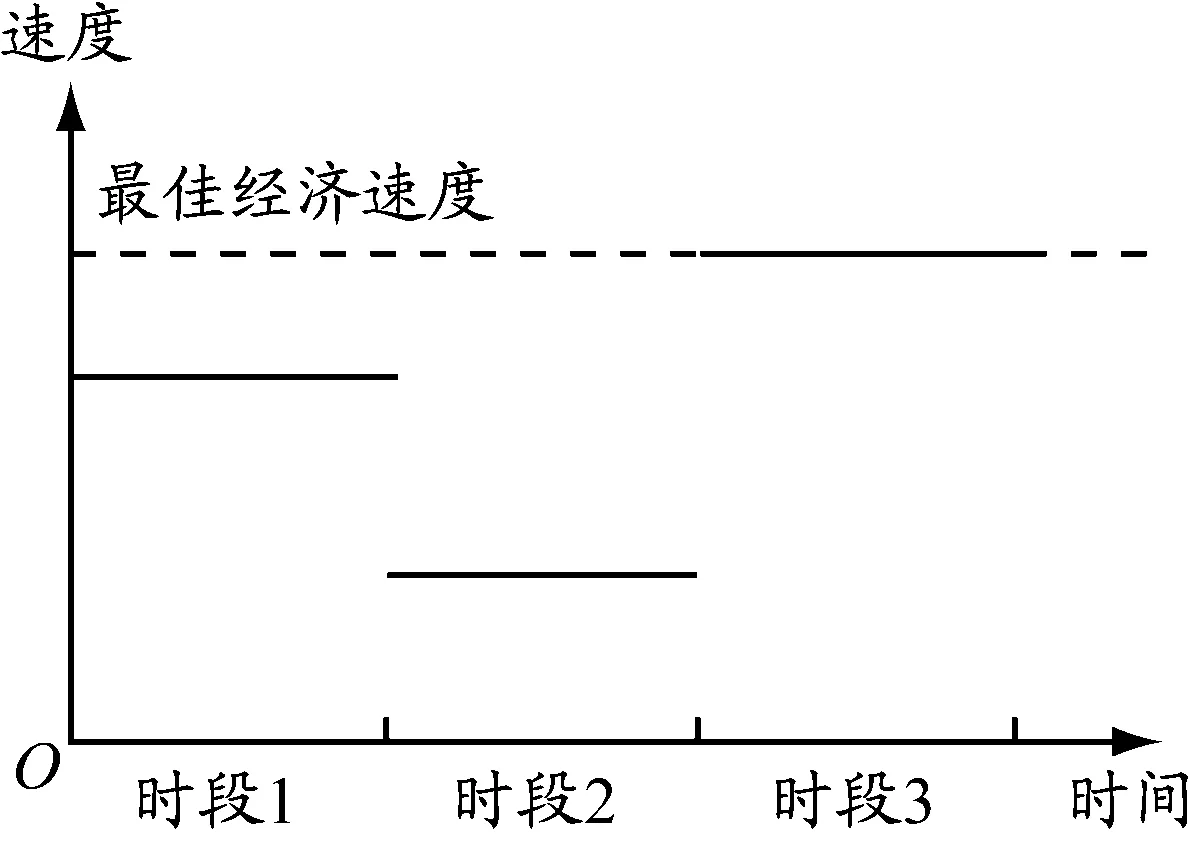
图1 时变路网车辆速度
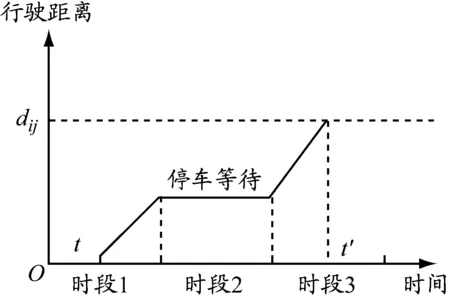
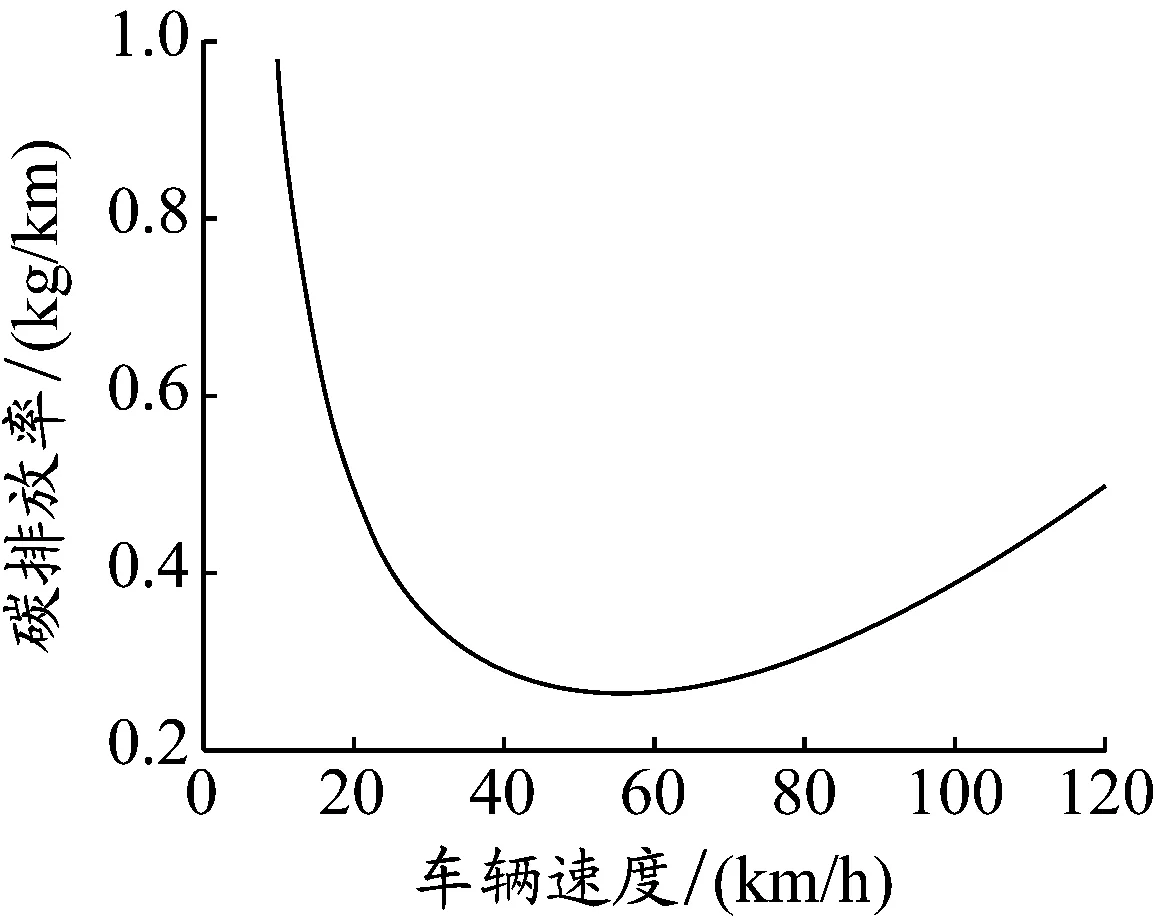
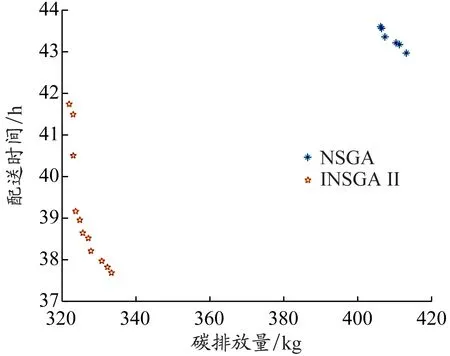
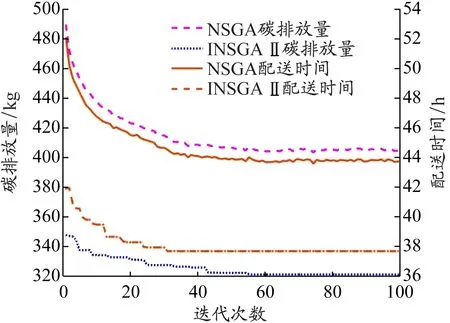
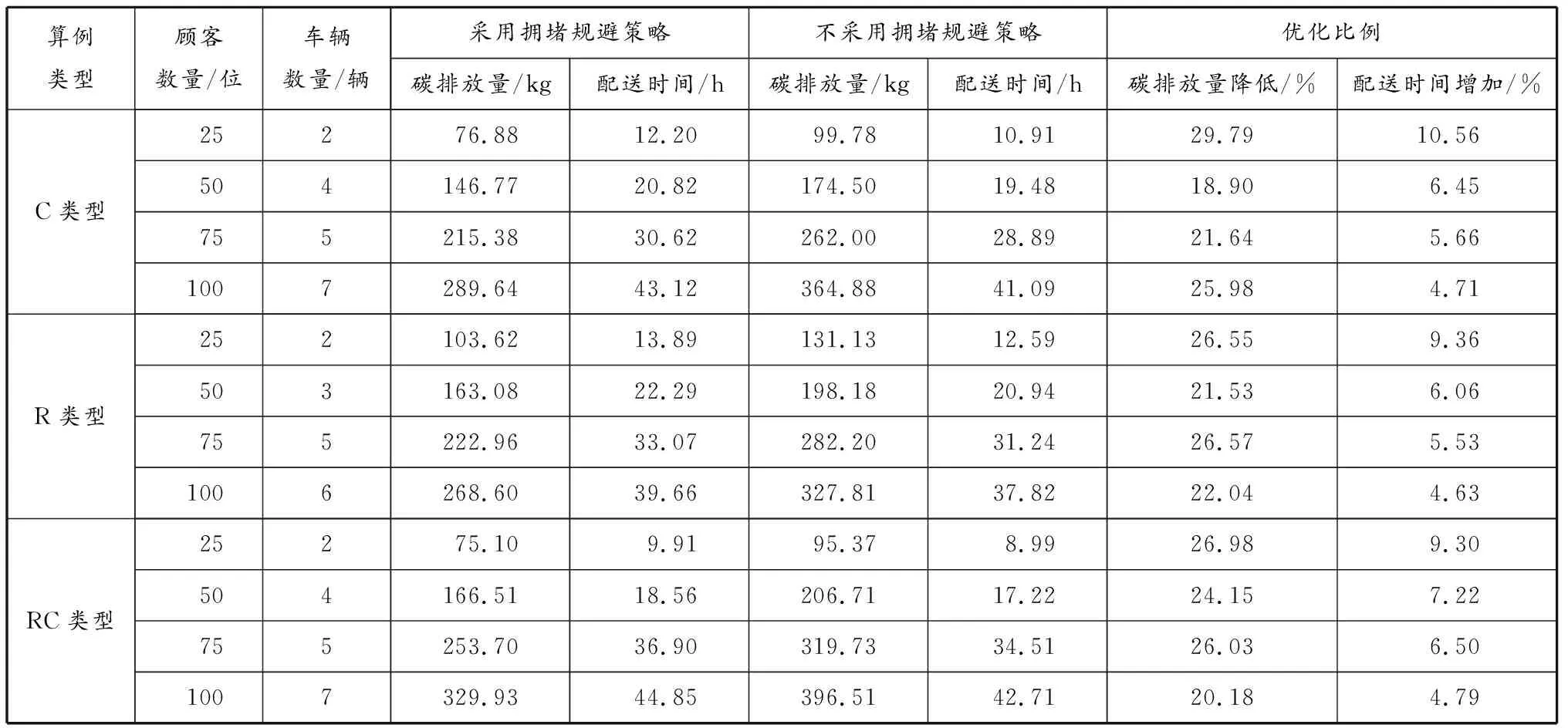
车辆从节点i行驶到节点j的过程中,假设从时段1中的时刻t开始,假设车辆k无法在时段1剩下的时间内完成整段路程dij,并且必须在接下来几个时段完成整段路程。图2为车辆不采用拥堵规避策略时(A方案)的行驶距离与时间关系图,在时刻t″到达节点j。图3为车辆采用拥堵规避策略(B方案),即在时段2停车等待,然后在时段3行驶,最终在时刻t′到达节点j。显然,A方案中的车辆配送时间比B方案的短,即t″ 图2 不采用拥堵规避策略的行驶距离与时间关系图 图3 采用拥堵规避策略的行驶距离与时间关系图 根据由DEMIR等[3]和FRANCESCHETTI等[9]提出的车辆油耗函数计算车辆在不同速度和负载下的碳排放量。车辆油耗函数为 F(v,f)=αv-1+βv2+γ+φf (1) 式中:系数α、β、γ和φ与车辆参数有关;v表示车辆行驶速度;f表示车辆的负载;αv-1+βv2+γ表示车辆在空载行驶过程中产生的油耗;φf表示车辆负载行驶额外产生的油耗。以BARTH等[12]提出的柴油卡车为例,车辆的最大负载为10 t,为接近现实生活,车辆受到150 kg燃油容量的限制。图4表示车辆在空载行驶时不同速度下的碳排放率。F(v,f)具体形式为 (2) 图4 车辆在空载行驶时不同速度下的碳排放率 模型参数:{0}∪N为节点集合,0为配送中心N={1,2,…,n}为顾客集合;K为车辆集合,k∈K;H为时段集合,h∈H;fi为节点i的需求,i∈N;fijk为车辆k从节点i到节点j时的负载;fmax为车辆最大负载限制;dij为从节点i到节点j的距离;vijh为时段h车辆从节点i到节点j的速度;tijk为车辆k从节点i到节点j的配送时间;tijk,1为车辆k从节点i到节点j的行驶时间;tijk,2为车辆k从节点i到节点j的等待时间;c为燃油到CO2的转化率;[TS,i,TE,i]为节点i的服务时间窗;[Tb,h,Te,h]为时段h的开始和结束时间;ts,i为节点i的服务时间;Ta,i为到达节点i的时刻;Tl,i为离开节点i的时刻。 决策变量:xijk为0-1变量,当车辆k从节点i到节点j时其值为1,否则为0;xijkh为0-1变量,当在时段h车辆k从节点i到节点j时其值为1,否则为0;yik为0-1变量,当节点i由车辆k服务时其值为1,否则为0。 以最低碳排放量和最短配送时间为目标构建TDPRP数学模型如下: 式(3)表示所有车辆的最低碳排放量;式(4)表示最短配送时间;式(5)表示每位顾客只能被服务1次;式(6)表示每辆车只能使用1次;式(7)表示车辆到达和离开的是同一顾客点;式(8)表示车辆必须从配送中心出发并返回配送中心;式(9)表示车辆不能超过其最大负载限制;式(10)表示在时段h车辆k从节点i到节点j的行驶时间;式(11)表示车辆k从节点i到节点j的配送时间;式(12)表示车辆到达节点i并服务之后才离开;式(13)表示配送车辆必须在顾客要求的时间窗内到达并服务顾客。 求解单目标问题时,可以求出唯一最优解,但求解多个目标函数时,由于目标矛盾,大多情况下并不存在唯一的最优解。DEB等[13]在2002年提出NSGA Ⅱ,克服NSGA的许多缺陷,例如:提出快速非支配排序(non-dominated sorting,NS)法,降低运算的复杂度;引入拥挤度计算,让解的分布更加均匀;引入精英保留策略,提高种群多样性。与传统的多目标算法相比,NSGA Ⅱ在算法精度和计算效率方面均有所提高。经过十多年的实践和应用,NSGA Ⅱ已成为人工智能领域的经典算法。 传统污染路径问题通常随机产生初始种群,而当种群规模较大时,遗传迭代的解的质量极其不稳定。XIAO等[14]研究表明初始种群的质量不仅影响算法迭代收敛速度,还会影响迭代最终解。种群个体聚集程度也会影响最终的优化结果,因此采用节约算法来生成初始种群。 采用自然数编码方式为配送中心0和n位顾客进行编码,顾客点用1,2,3,…,n表示,采用节约算法生成初始种群的步骤如下: (1)为每位顾客分配1辆配送车辆。 (2)依次计算融合每2位顾客的距离节约值并降序排序,按照距离节约值排序依次判断融合的2条路径是否满足时间窗约束和车辆负载约束。 (3)将满足约束条件的距离节约值最大的2条路径融合,重复上述操作生成初始种群。 NS首先需要确定个体的Pareto等级和个体之间的支配关系。2个目标函数分别为f1(x)和f2(x),首先计算所有个体的Pareto支配关系。Pareto支配关系是对于2个目标函数fi(x),i=1,2,任意给定2个个体xa和xb,如果同时满足①对于∀i∈{1,2}都有fi(xa)≤fi(xb),②∃i∈{1,2}使得fi(xa) (1)在初始种群中找出非支配解,并将其Pareto等级定义为1。 (2)将Pareto等级定义为1的解从种群中删除,剩下的种群中非支配解的Pareto等级定义为2。 (3)重复上述步骤可以得到该种群中所有个体的Pareto等级。 拥挤度是NSGA Ⅱ中非常重要的概念,用于计算某一特定个体周围的种群密度,根据拥挤度可以有效调整种群多样性。数值可以看作某特定个体i两侧相邻个体作为对角线两顶点形成的长方形的周长,表示为 (14) 由上式可知:个体i与相邻个体越分散,该个体与相邻个体的差异性越大,拥挤度越大;个体i与相邻个体越密集,该个体与相邻个体的相似性越高,拥挤度越小。对于Pareto等级相同、位于边缘的个体,拥挤度定义为正无穷。位于内部的个体,拥挤度越大,表示该个体与相邻个体的目标函数值的差异越大,即个体的多样性越好。因此,NSGA Ⅱ在合并种群后的筛选过程中在Pareto等级相同的情况下,优先选择拥挤度更大的个体有利于保护种群多样性,防止出现局部最优解。 将精英保留策略引入NSGA,扩大种群规模,组合父代种群和子代种群,共同竞争产生下一代父代种群,有利于保留父代中的优良个体,并在迭代中扩大种群规模。精英保留策略的步骤如下: (1)将父代种群Pi和子代种群Qi合成种群Ri。 (2)将合成后的种群Ri进行非支配排序,按照Pareto等级从低到高的顺序将种群放入新的父代种群Pi+1,直到某一等级的个体不能全部放入新的父代种群Pi+1。 (3)将该等级的个体根据拥挤度从大到小的顺序排列,依次放入新的父代种群Pi+1,直到新的父代种群Pi+1被填满。 该精英保留策略的优点在于最佳个体不会丢失,可以迅速提高种群水平并且在演化过程有更多的候选解,使得种群具有更佳的多样性。 在NSGA Ⅱ中,种群中个体的主要差异在于其所属的Pareto等级。自适应交叉变异机制用来增加优秀个体的进化机会,提高算法的搜索能力。自适应交叉概率为 (15) 式中:pc,i表示个体i的自适应交叉概率;pc表示预设交叉概率;n表示种群数量;ri表示交叉个体的Pareto等级。 计算交叉概率使得Pareto等级越低的个体发生交叉的概率越高,使得种群有更高的进化概率。为避免交叉过程中产生超出车辆负载限制或者与顾客时间窗有冲突的子代,提高算法的收敛效果并保留优良基因,本文采用的交叉方法步骤(见图5)如下:(1)选出参与交叉的父代1和父代2,从父代1中随机选出不包含配送中心的路段作为交叉段;(2)找出父代2中对应父代1交叉片段的编号顺序,作为父代2的交叉段;(3)将父代1的交叉段和父代2的交叉段进行互换,生成子代1和子代2。 图5 交叉操作示意 个体i的自适应变异概率为 (16) 式中:pm表示预设交叉概率;n表示种群数量。 自然数编码下基因代表顾客点,变异操作指该顾客点被替换成其他顾客点。采用交换变异,即在染色体上任意选择2个不为0的基因位置,然后进行互换操作,互换后产生新的个体。具体变异方式见图6。 图6 变异操作示意 由于目前没有TDPRP的标准测试数据库,案例数据采用国外著名学者Solomon的VRPTW数据库中的算例。该算例分为3种类型:C类型(集中分布)、R类型(随机分布)和RC类型(混合分布)。本文使用3种类型算例中顾客的坐标、需求量、时间窗和服务时间等数据作为测试数据。每个算例都有100位顾客和1个配送中心,每位顾客的服务时间为10 min。为符合测试要求,补充如下数据: (1)设定配送中心的总工作时间为960 min,将工作时间分为16个时段,每个时段为60 min。最早工作时间为06:00,最晚工作时间为22:00。 (2)根据上海市交通出行网(http://www.jtcx.sh.cn/)历史数据分析可得,工作日上海市市区内交通拥堵时刻普遍集中于08:00—10:00和18:00—20:00,将此时段规定为低速时段。将车辆速度按照早晚高峰时段划分为高速、中速、低速等3个等级,高速设置为(50,75]km/h,中速设置为(25,50]km/h,低速设置为[10,25]km/h,具体的行驶速度在区间内随机产生。 算法采用MATLAB R2018b编程,在CPU为AMD Ryzen 5 3600 3.6 GHz、内存为16 GB的计算机上运行,程序参数参考文献[15]中所给出的最佳参数设置(种群规模为250、迭代次数为100、交叉概率为0.8、变异概率为0.1)。 4.2.1 算法有效性检验 为验证算法的有效性,将改进的NSGA Ⅱ(记为INSGA Ⅱ)与NSGA进行比较。NSGA不采用精英保留策略和不进行拥挤度计算,初始种群随机生成,交叉变异概率与NSGA Ⅱ的相同但在遗传迭代中不进行自适应变化,并且所有车辆出发时刻均为0。选取算例RC208进行实验,Pareto解集和每代种群最优的碳排放量和配送时间见图7、图8和表1。 图7 Pareto解集前沿分布情况 图8 每代种群最优的碳排放量和配送时间 表1 算法有效性检验 (1)与NSGA随机生成初始种群相比,INSGA Ⅱ运用节约算法生成初始种群,其平均碳排放量降低40.51%,配送时间减少24.29%,说明在顾客规模较大的情况下,采用节约算法生成的初始种群更贴合实际,有利于提高遗传算法迭代寻优的效率,加快算法收敛。 (2)由图7可知,INSGA Ⅱ生成11个分布较为分散的Pareto解,NSGA生成6个分布较为集中的Pareto解,这说明算法中加入拥挤度计算有利于保护种群多样性,防止出现局部最优解。 (3)INSGA Ⅱ较NSGA碳排放量降低25.40%,配送时间减少8.26%。由图8可知INSGA Ⅱ在迭代到40次左右就已经收敛,说明精英保留策略和自适应选择策略可以增强算法的局部搜索能力和全局寻优能力。 (4)INSGA Ⅱ运行1次的平均时间为42.29 s,说明INSGA Ⅱ可以为物流企业在较短时间内给出决策者满意解。 4.2.2 拥堵规避策略结果分析 为验证拥堵规避策略的有效性,采用的算例具有3种不同的分布类型和4种不同规模的顾客数量。计算结果见表2,其中:碳排放量指Pareto解集中所有解的碳排放量平均值;配送时间包含等待时间和行驶时间;优化比例是采用拥堵规避策略相对于不采用拥堵规避策略的结果。分析表2可知: (1)不采用拥堵规避策略的车辆配送时间略低于采用拥堵规避策略的车辆配送时间,但是采用拥堵规避策略的碳排放量的优化效果更为明显,碳排放量最多降低29.79%,最少降低18.90%,平均降低24.19%,由此可知本文提出的拥堵规避策略可以有效降低物流企业车辆的碳排放量。 (2)顾客数量越多,采用拥堵规避策略的优化效果越明显。针对3种类型算例,拥堵规避策略都可以有效降低车辆碳排放量。随着顾客数量的增加,平均配送时间增长率逐渐降低,3种分布模式下25位顾客平均配送时间增加10.80%,100位顾客平均配送时间增加4.94%,即顾客数量越多,拥堵规避策略对车辆平均配送时间的影响越小。因此,提出的拥堵规避策略更适合服务顾客数量较多的大型物流企业的物流配送。 4.2.3 车辆路径算例分析 为验证INSGA Ⅱ的稳定性,选取算例RC208进行验证,运行10次,平均运行时间为42 s,说明算法能够在较短的时间内得到车辆路径规划方案。随机取Pareto解集中的1个解,进行车辆路径分析,数据见表3。 分析表3可知: (1)共使用7辆配送车辆,各车辆的配送任务有所差异,车辆2要服务18位顾客,配送任务最少的车辆3要服务10位顾客,其他车辆要服务15位顾客左右,这是因为车辆路径规划需要考虑顾客的需求、地理分布和时间窗要求以及车辆负载限制、时变路网、服务时间等。 表2 有无采用拥堵规避策略的结果比较 表3 RC208车辆路径分析 (2)由表3出发时段可知,车辆2和车辆5在时段6出发,其他车辆都在时段1第0时刻从配送中心出发。如果所有车辆都在同一时刻从配送中心出发,则必然增加部分车辆等待时间,延长车辆的使用时间。因此,本文算法可以根据顾客需求合理规划车辆出发时间,有效减少车辆等待时间和车辆使用时间,降低成本。 (3)物流企业应根据时变路网状况和顾客时间窗要求等实际情况合理安排车辆出发时间,以降低车辆碳排放量和配送成本。 本文研究时变路网交通拥堵条件下的污染路径问题,考虑实际物流过程中出现交通拥堵等情况,首先提出拥堵规避策略,然后引入基于时段划分的路段行驶时间计算方法和车辆油耗函数。在此基础上建立最低碳排放量和最短配送时间的双目标污染路径问题模型,并使用改进的NSGA Ⅱ进行求解,最后结合算例分析,得出以下结论:(1)拥堵规避策略可以有效降低车辆碳排放量并缩短车辆的行驶时间,但是会在较小程度上增加车辆使用时间。(2)改进的NSGA Ⅱ和本文提出的拥堵规避策略更适合顾客数量较多的大型物流企业的车辆路径优化。(3)在调度配送车辆的过程中,物流企业应充分考虑时变路网信息、顾客时间窗、交通流量等实际情况,合理安排出发时间规避拥堵时段和规划路线,从而降低碳排放量和配送成本。(4)物流企业在节能减排的同时会增加一定的配送成本,为促进绿色物流、保护环境,政府相关部门应该制定相应的绿色物流引导政策。 本文研究考虑的是规律性的交通拥堵情况,在未来会继续研究偶发性的交通拥堵情况下的车辆实时调度问题及模糊需求和模糊时间窗对时变路网污染路径问题的影响。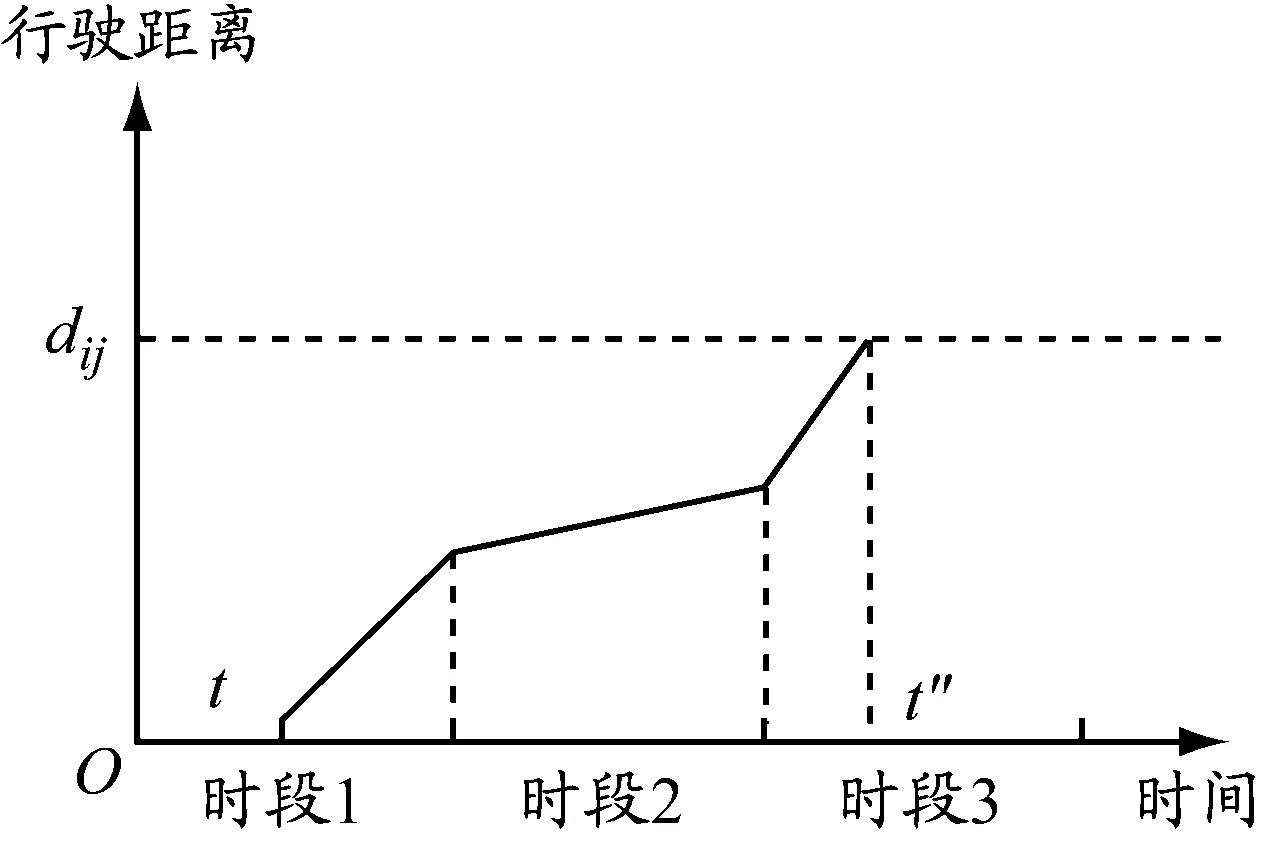
2.2 计算碳排放量
2.3 符号和变量
2.4 TDPRP模型建立
3 改进的NSGA Ⅱ
3.1 种群初始化
3.2 NS
3.3 拥挤度计算
3.4 精英保留策略
3.5 自适应交叉算子
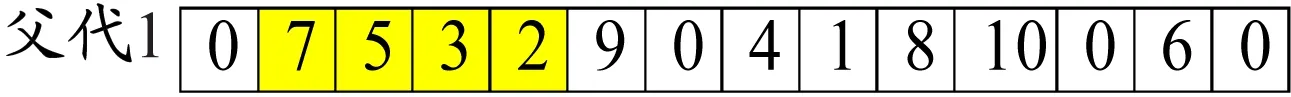



3.6 自适应变异算子


4 实验设置和结果分析
4.1 实验设置
4.2 实验结果分析
5 结 论
