基于改进RetinaFace和YOLOv4的船舶驾驶员吸烟和打电话行为检测
2023-01-03王鹏尹勇宋策
王鹏, 尹勇, 宋策
(大连海事大学航海动态仿真和控制交通行业重点实验室, 辽宁 大连 116026)
0 引 言
我国是一个航运大国,海上交通运输行业的发展非常迅速。随着现代科技和造船技术的快速发展,船舶逐渐向大型化、自动化和智能化发展,由此导致的海上安全事故也显著增加[1]。据统计,80%的海上安全事故与人的因素有关,其中驾驶员异常行为导致的海上事故占相当大的比例[2]。
值班驾驶员吸烟和打电话行为是威胁船舶航行安全的主要因素,尤其是当船舶航行在近岸和港区水域时,由于这些水域船舶密度大、通航环境复杂,一旦值班驾驶员注意力分散,发生航行安全事故的概率将会大大增加。为保证船舶航行安全,最大程度地降低海上安全事故发生的概率,设计一种实时性强、误检率低的船舶驾驶员吸烟和打电话行为检测系统显得尤为重要。
目前,针对驾驶员吸烟和打电话行为的检测方法主要包括传统方法和计算机视觉。传统方法使用烟雾传感器[3]检测香烟烟雾,进而识别吸烟行为;通过检测手机收发信号的波动来识别打电话行为[4]。随着计算机视觉和深度学习的快速发展,越来越多的基于目标检测的吸烟和打电话行为识别算法被提出。在吸烟检测方面:文献[5-6]通过检测烟雾特征来识别吸烟行为,该方法相较于烟雾传感器的检测效果有所提升,但也存在烟雾浓度低、易扩散导致检测不稳定的问题[7];文献[8-10]使用手势传感器或机器学习的方法提取吸烟手势来判断是否存在吸烟行为,但吸烟手势复杂、肤色多样、相机角度等问题使得识别手势存在差异,误检率较大;李倩[11]将检测到的人脸图像作为烟支检测候选区域,从而大幅缩小目标检测区域,并使用更快速区域卷积神经网络(faster region-based convolution neural networks,Faster R-CNN)对香烟目标进行检测以此来降低误检率;程淑红等[12]使用级联多个卷积神经网络的方式来实现嘴部敏感区域的定位,利用残差网络对感兴趣区域(region of interest,ROI)内的目标进行检测和状态识别;韩贵金等[13]利用人脸检测来缩小目标检测区域,在HSV(hue, saturation, value)颜色空间下使用腐蚀膨胀操作进行烟支初检,最后利用Faster R-CNN进行烟支细检。在打电话检测方面:魏民国[14]通过Adaboost算法检测人脸后,提取耳部ROI,计算梯度直方图,再通过支持向量机判断是否存在打电话行为;王丹[15]将驾驶员打电话行为分解为一系列满足一定时序关系的子动作,通过统计解析的方法在视频中检测驾驶员打电话行为;骆文婕[16]采用Haar特征及核化相关滤波器跟踪算法(kernelized correlation filters,KCF)实时获取人脸位置,针对耳部ROI进行Canny边缘检测,以此判断是否存在打电话行为;王尽如[17]提出一种基于支持向量机的驾驶员打电话行为检测算法;吴晨谋等[18]基于人体姿态估计的方法,估计人体上半身8个骨骼节点的三维坐标,以此判断驾驶员是否接打电话。
上述算法能在一定程度上提升吸烟和打电话行为检测的精度,但实际场景中由于目标过于微小,网络提取的特征不明显,容易将白色条状物误检为香烟,将鼠标、充电宝等误检为手机。为解决这个问题,本文提出一种两阶段的吸烟和打电话行为检测算法,首先使用改进的RetinaFace网络[19]提取人脸ROI,再使用改进的YOLOv4[20]目标检测算法来检测该区域内是否存在香烟或手机,从而识别船舶驾驶员的吸烟和打电话行为。
本文贡献主要有以下2个方面:
(1)提出一种两阶段的吸烟和打电话行为检测算法,首先放大检测到的人脸区域得到头部区域图像,在头部区域进行目标检测,提高目标检测的效率,同时也可以避免复杂背景的干扰;使用轻量级网络模型替换RetinaFace和YOLOv4的主干网络,利用深度可分离卷积改进YOLOv4目标检测模型中的路径聚合网络(path aggregation network,PANet),在检测精度下降不太多的情况下提升检测速度。
(2)将疑似香烟和疑似手机的目标作为负样本进行训练,降低算法的误检率;使用复制粘贴数据增强手段,将香烟、手机等小目标随机粘贴在图像上,扩充目标数量,增强目标检测模型的泛化能力。
1 基于改进RetinaFace网络的人脸检测算法
1.1 RetinaFace网络
RetinaFace是InsightFace团队提出的一种鲁棒的单阶段人脸检测网络,其检测模型见图1。它利用额外监督与自监督结合的多任务学习,对不同尺寸的人脸进行像素级定位,使用的多任务损失函数由人脸分类损失Lcls、人脸框回归损失Lbox、人脸关键点回归损失Lpts和密集人脸回归损失Lpixel组成,在WIDER FACE数据集上有着非常好的表现。
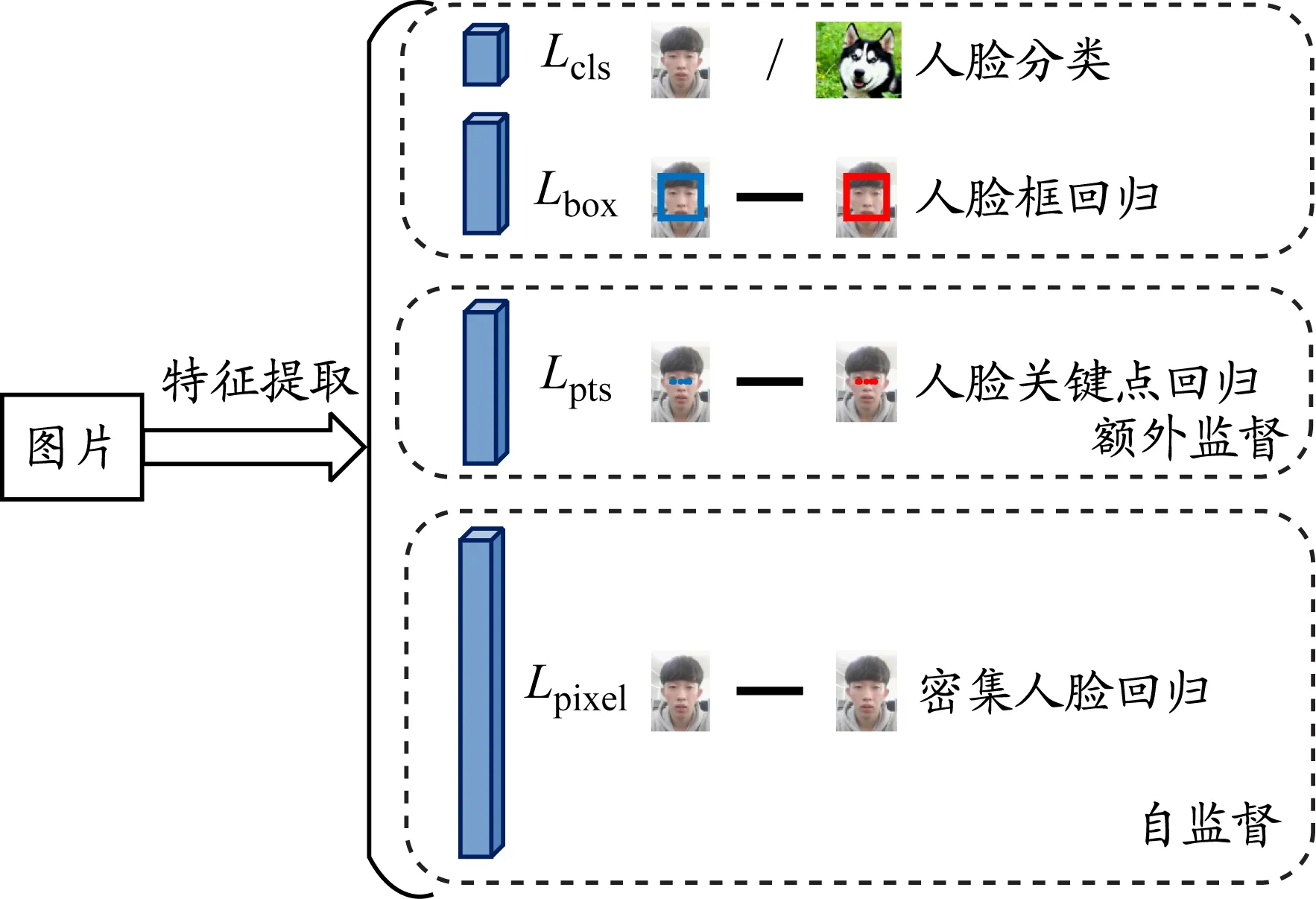
图1 RetinaFace人脸检测网络模型
1.2 改进的RetinaFace网络
为满足检测的实时性要求,采取优化网络结构的思想,在检测精度下降不太多的情况下,为尽可能地减少计算量,采用轻量级的卷积神经网络MobileNet[21]对RetinaFace的主干特征提取网络ResNet50[22]进行替换。MobileNet的核心思想是用深度可分离卷积代替普通卷积,见图2。
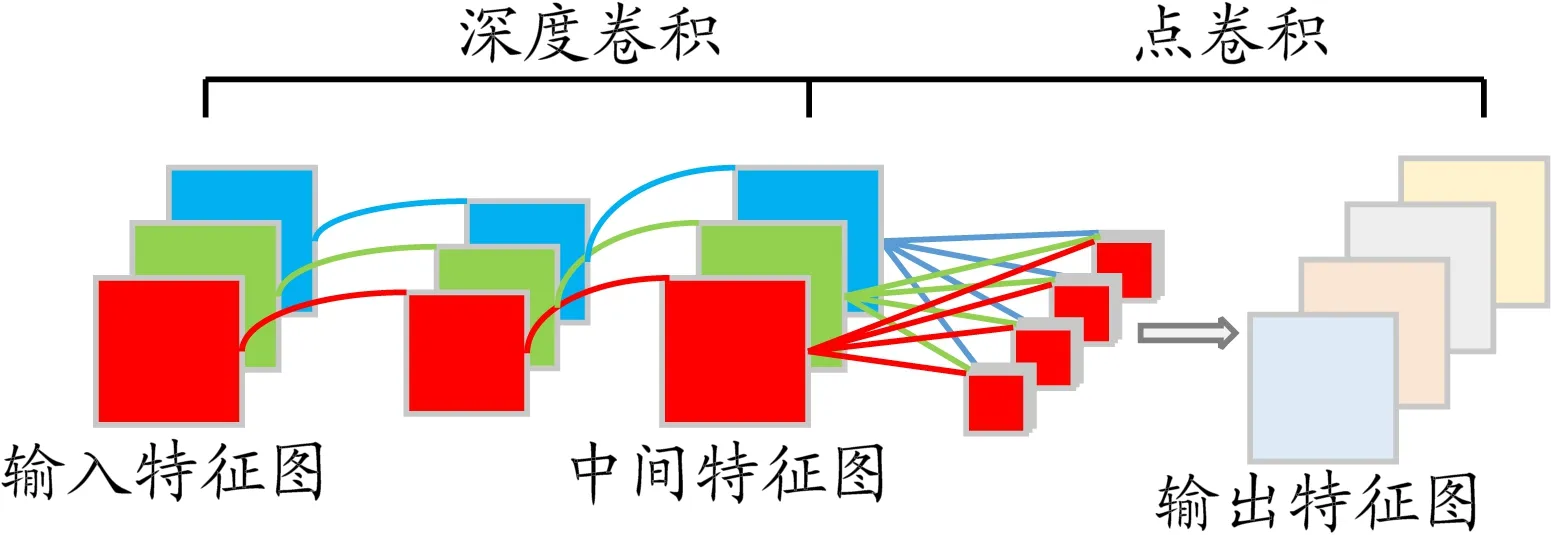
图2 深度可分离卷积示意
用深度可分离卷积代替普通卷积可显著减少模型的参数量和计算量。假设输入特征图的宽、高、通道数分别为Dk、Dk、M,卷积核的宽、高、通道数分别为DF、DF、M,卷积核的数量为N,则普通卷积的计算量为DkDkDFDFMN,深度可分离卷积的计算量为DkDkDFDFM+MNDkDk。
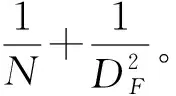
改进的RetinaFace网络使用标注好的人脸数据集WIDER FACE[23]进行训练,该数据集共有32 203张图像和393 703个人脸框。人脸在尺度、姿态、遮挡、表情、装扮、光照等方面都有很大差异,人脸特征具有多样性。训练模型时,在61个场景分类中随机采样,WIDER FACE数据集被分为3个子集,其中40%用于模型训练,50%作为测试集,其余的为验证集。训练模型正负样本的处理参考传统RetinaFace网络的训练方法。
为更好地显示改进效果,分别使用传统的和改进的RetinaFace网络检测同一段视频,结果见图3,改进前后模型的检测帧率分别是9.46和22.73帧/s,改进后模型的检测速度明显增加。使用的深度学习框架为PyTorch,测试硬件环境为Nvidia GTX950M GPU,测试软件为PyCharm 2020。

a)改进前

b)改进后
2 基于改进YOLOv4的吸烟和打电话行为检测
2.1 人脸区域图片裁剪
考虑打电话行为检测的ROI主要是耳朵所在的区域,而RetinaFace网络检测的人脸框并不包含耳朵,因此需要对人脸框进行一定程度的放大。由于检测到的人脸大小不一,采用一种自适应方法进行人脸图片的裁剪,即根据RetinaFace网络检测到的人脸框的大小来确定裁剪图片的尺寸,具体计算方法见式(1),其中,wf和hf分别为人脸框的宽和高,w和h分别为裁剪的人脸图片的宽和高。人脸图片的裁剪过程见图4。

图4 人脸图片裁剪示意
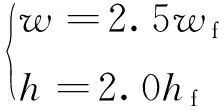
(1)
2.2 改进的YOLOv4目标检测模型
YOLOv4是一种实时、高精度的目标检测模型。当输入特征图的宽、高、通道数分别为416、416、32,批量大小为B时,YOLOv4目标检测模型的网络结构见图5,YOLOv4目标检测模型的网络结构由CSPDarknet53主干特征提取网络、空间金字塔池化(spatial pyramid pooling,SPP)、PANet和YOLOv3-Head检测头组成。CSPDarknet53使得网络在轻量化的同时保持准确性;SPP和PANet将具有不同空间分辨率的特征图生成层次结构,有效增强感受野,使细粒度的局部信息可用于顶层,大大丰富输入检测头的信息。除此之外,YOLOv4目标检测模型还使用Mosaic数据增强、标签平滑、CIOU(complete intersection over union)损失、学习率余弦退火衰减等小技巧。经比较可知,YOLOv4目标检测模型的推理速度比与其性能相当的EfficientDet模型的快2倍,平均精度(average precision,AP)和帧率较YOLOv3的分别提高10%和12%。
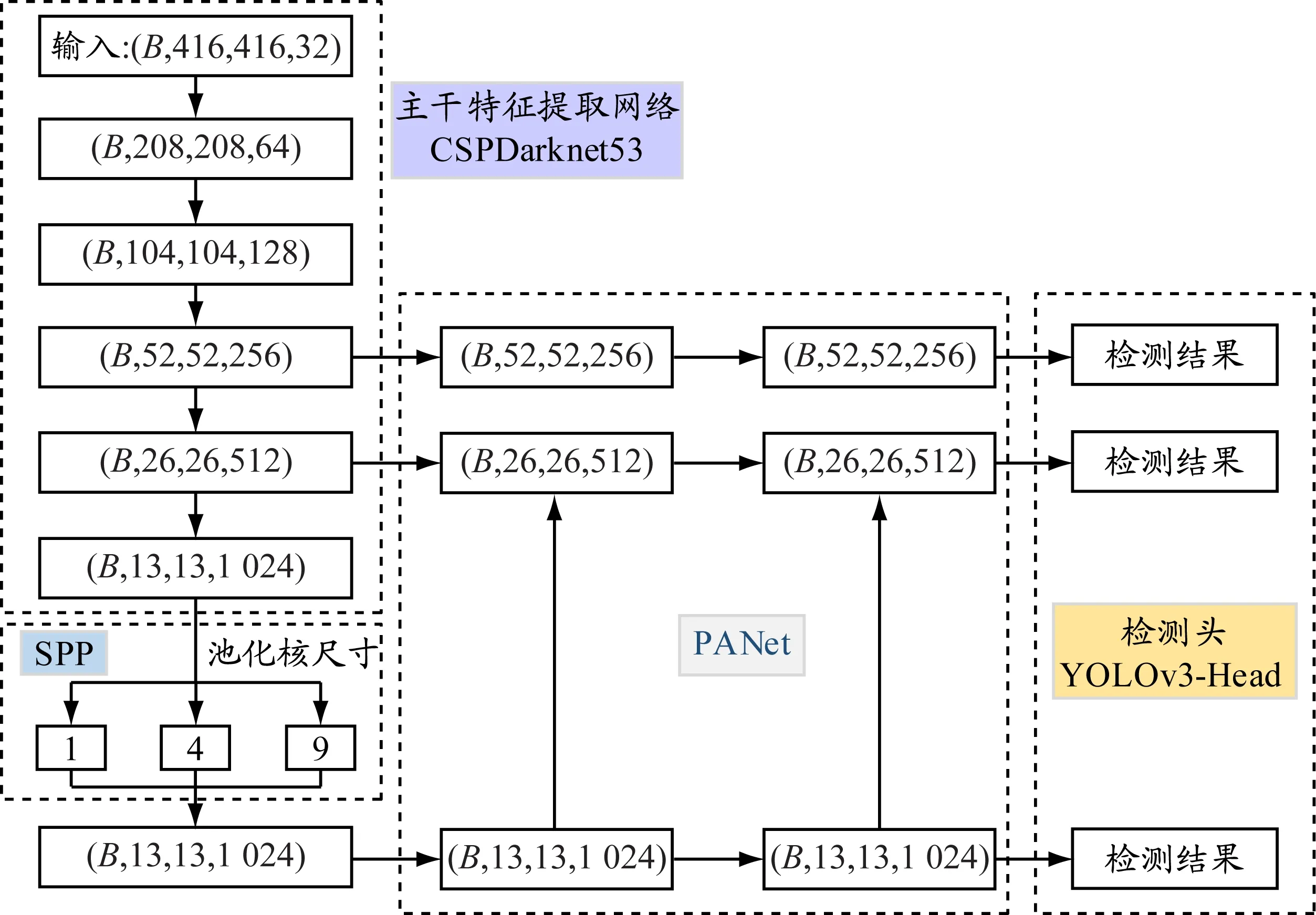
图5 YOLOv4目标检测模型网络结构示意
为让提出的吸烟和打电话行为检测算法在低算力设备上也有较好的表现,需要对YOLOv4目标检测模型进行一定的改进。改进的主要策略是用一个轻量级的网络模型替换原有的CSPDarknet53,在网络的颈部PANet部分使用深度可分离卷积代替普通卷积,以降低参数量。
使用MobileNetv3[24]对YOLOv4目标检测模型进行改进。MobileNetv3是MobileNet系列网络的最新版(见图6),综合MobileNetv1的深度可分离卷积DConv和MobileNetv2的逆残差结构,使用普通卷积Conv进行升降维,在此基础上加入通道注意力机制(squeeze and excitation,SE),使用h-swish激活函数代替swish函数。MobileNetv3在分类、目标检测以及语义分割任务中都取得了优异的成绩。
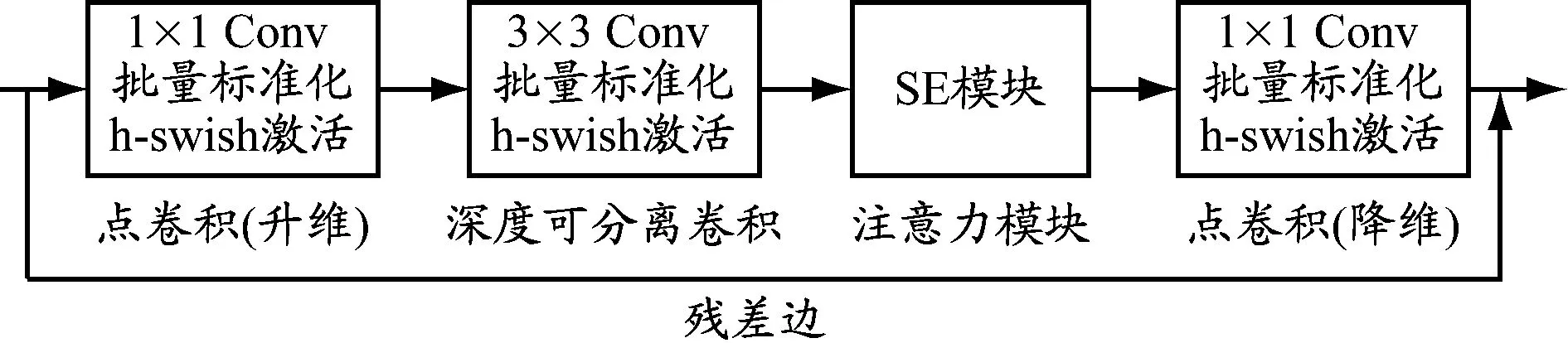
图6 MobileNetv3基本卷积模块
为对比改进前后模型的参数量变化,使用一张416×416像素的图片测试YOLOv4、YOLOv4-tiny和YOLOv4-MobileNetv3目标检测模型的参数量,结果见表1。使用3种目标检测模型在自建吸烟和打电话行为检测数据集上进行训练,模型的检测精度和速度见图8。图8中,类平均精度指所有类别的平均精度。

表1 YOLOv4与其改进模型参数量对比
综上,改进的YOLOv4目标检测模型在检测精度和速度上取得一个较好的折中:与YOLOv4目标检测模型相比,改进的YOLOv4目标检测模型总参数量仅为原来的1/5,在检测精度下降1.3%的情况下,检测速度提升近1倍;与官方推出的YOLOv4-tiny相比,改进的YOLOv4目标检测模型在牺牲一定检测速度的情况下,将检测精度维持在较高的水平。
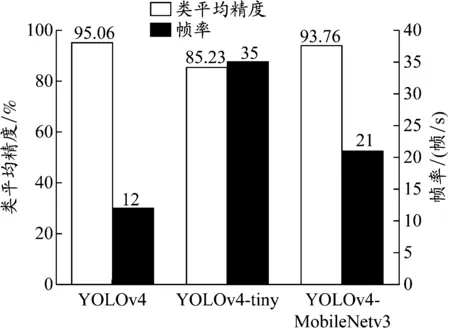
图8 YOLOv4与其改进模型检测性能对比
3 实验设计和结果分析
3.1 数据集和数据增强
使用的实验数据集是自建吸烟和打电话行为检测数据集,共有10 000张图片,全部截自航海模拟器驾驶台中存储的视频片段。针对实际场景中香烟、手机目标过于微小容易误检的问题,在数据集中加入白色的笔、充电宝、鼠标等疑似香烟或手机的目标作为负样本,整个数据集共有香烟目标4 594个,手机目标4 341个,疑似香烟目标2 372个,疑似手机目标2 187个,正负样本比例约为2∶1。使用labelimg工具将所有样本标注为VOC2007格式的数据集。
由于数据采集的环境光照不同以及设备的性能优劣等,手动采集的数据存在对比度不够、有噪声等缺点,在模型训练前对数据集进行预处理和图像增强。除此之外,还使用复制粘贴[25]数据增强手段对数据集进行扩充,即裁剪样本中的一些小目标,并随机粘贴到每一张图片上,编写脚本自动生成对应标注,通过增加每一张图片上的目标数来增强目标检测网络的泛化能力,改善小目标的检测效果。经复制粘贴数据增强后的样本见图8。

图8 复制粘贴数据增强后的样本
3.2 模型训练
实验所用环境为Windows 10、Inter Core i7-6700CPU、Nvidia GTX1050Ti GPU,使用的深度学习框架为PyTorch。采用迁移学习的思想分2步进行训练:首先利用在ImageNet[26]分类任务上训练好的MobileNetv3模型权重对改进的YOLOv4目标检测模型进行初始化,冻结此部分权重,设置批量大小为16,学习率为0.001,采用自适应矩估计(adaptive moment estimation,Adam)的优化方法训练50个世代;然后解冻所有网络权重,设置批量大小为8,学习率为0.000 1,采用同样的优化器再训练50个世代。
整个训练过程耗时14.3 h,模型验证损失曲线见图9。可以看出,使用MobileNetv3预训练权重的模型损失在训练开始后迅速下降,并在训练35轮后逐渐收敛到较低的水平。在解冻所有网络权重后,模型的训练损失进一步下降,在训练85轮后收敛到1.5左右。

a)训练50轮

b)训练100轮
3.3 实验和结果分析
利用测试集中的1 000张图片对模型进行评估,选取精确率P(Precision)、召回率R(Recall)、F1(P和R的调和平均数)、平均精度εAP和类平均精度εMAP作为主要指标来评价模型的性能。
(2)
式中:NTP为模型将正例识别为正例的图片数量;NTN为模型将负例识别为负例的图片数量;NFP为模型将负例识别为正例的图片数量;NFN为模型将正例识别为负例的图片数量;N为类别的个数。将检测框的阈值设为0.5,模型精确率-召回率曲线见图10。
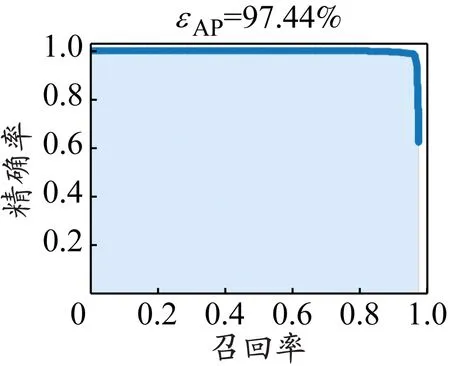
a)吸烟
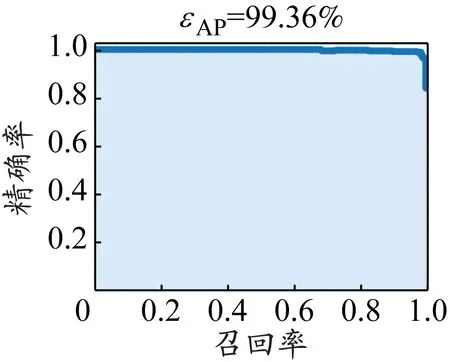
b)打电话
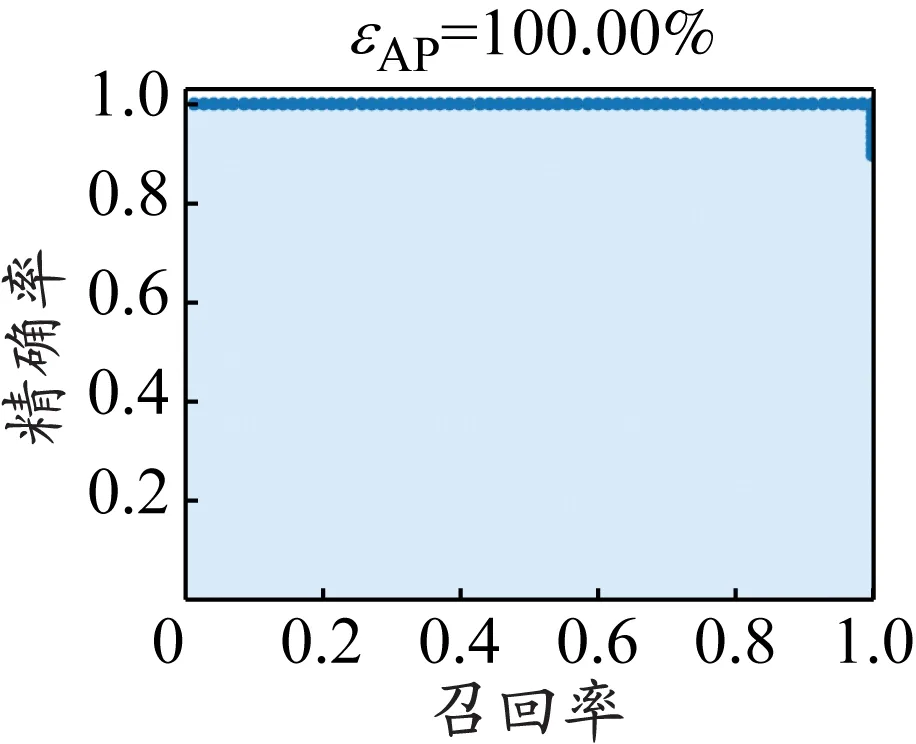
c)疑似吸烟
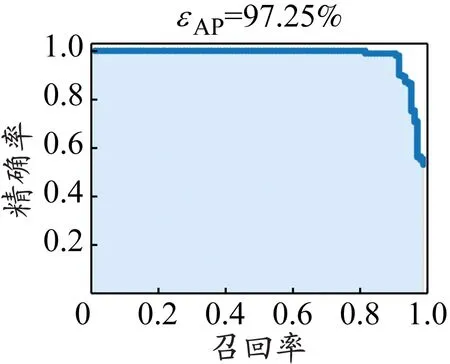
d)疑似打电话
表2展示了不同类别的主要评价指标,经过计算知,本文模型的εMAP为98.51%。
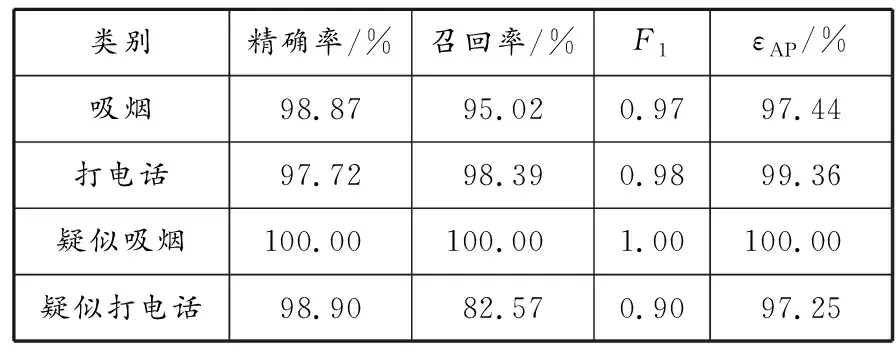
表2 不同类别的主要评价指标
为进一步验证本文模型检测吸烟和打电话行为的性能,使用Faster R-CNN[27]、SSD[28]和RetinaNet[29]模型在自建数据集上进行对比实验,结果见表3。从实验结果可以看出,本文模型的εMAP明显优于其他3种模型,检测速度与最快的SSD模型的相当,有着良好的准确性和实时性。
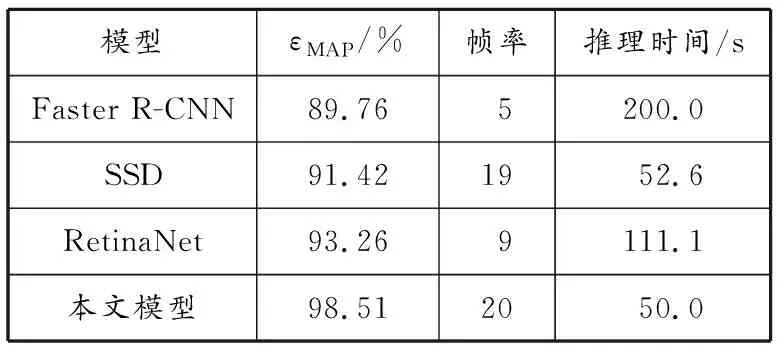
表3 不同模型实验结果对比
为验证加入负样本对模型误检问题的改善以及数据增强对模型泛化能力的提升,还做了一组消融实验,见表4。实验结果表明:在数据集中加入疑似吸烟和疑似打电话的负样本后,模型的误检率显著下降,由原来的7.9%降为4.6%;数据增强后,模型的检测能力有一定的提升,尤其是针对小目标检测的泛化能力,εMAP由95.28%提高到98.51%。本次消融实验更好地说明在数据集中加入负样本和数据增强的有效性,体现本文的创新意义。

表4 消融实验结果
将系统各部分模块进行整合,使用PyQt结合QtDesigner对系统界面进行设计和开发。系统可以接入摄像头进行实时检测,也可以读取本地的视频文件进行检测,支持MP4、AVI等主流视频格式;界面右侧可以控制检测的开始和结束,显示检测结果;使用多线程技术将视频读取、视频处理和主线程独立开来,避免系统使用卡顿,显著提高视频处理的效率。在航海模拟器中的检测效果见图11。
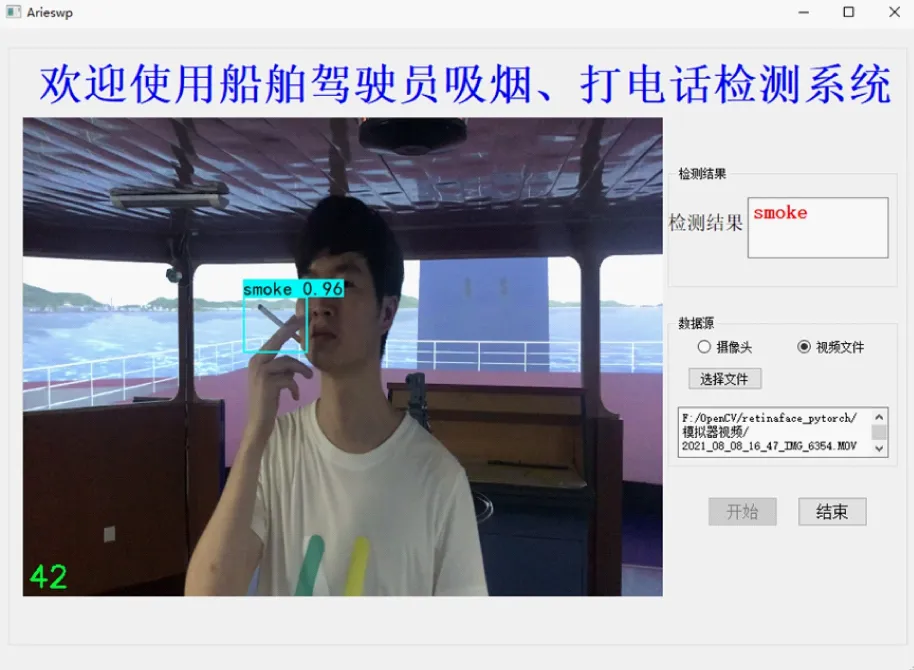
a)白天吸烟
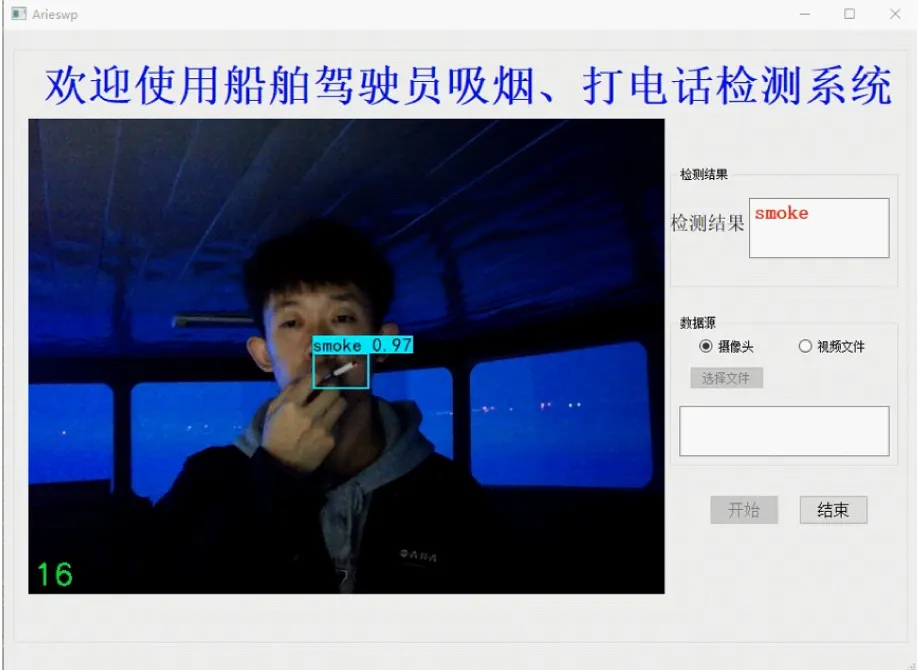
b)夜间吸烟
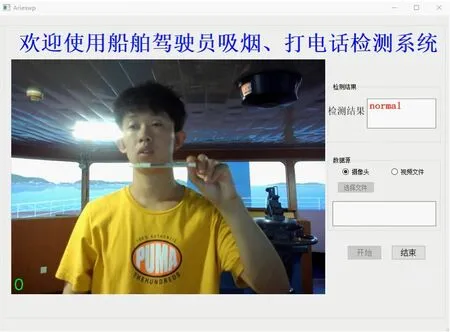
c)白天疑似吸烟
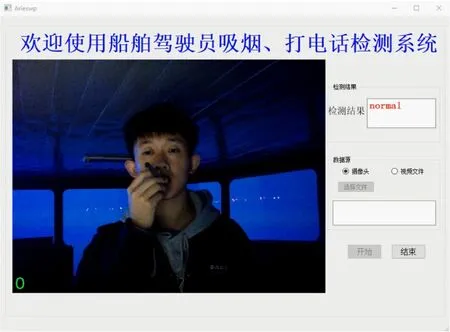
d)夜间疑似吸烟

e)白天打电话
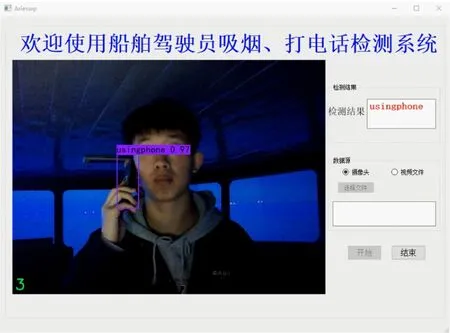
f)夜间打电话
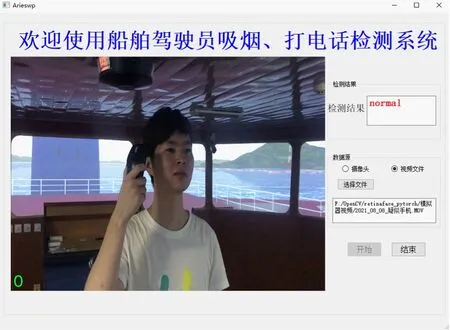
g)白天疑似打电话
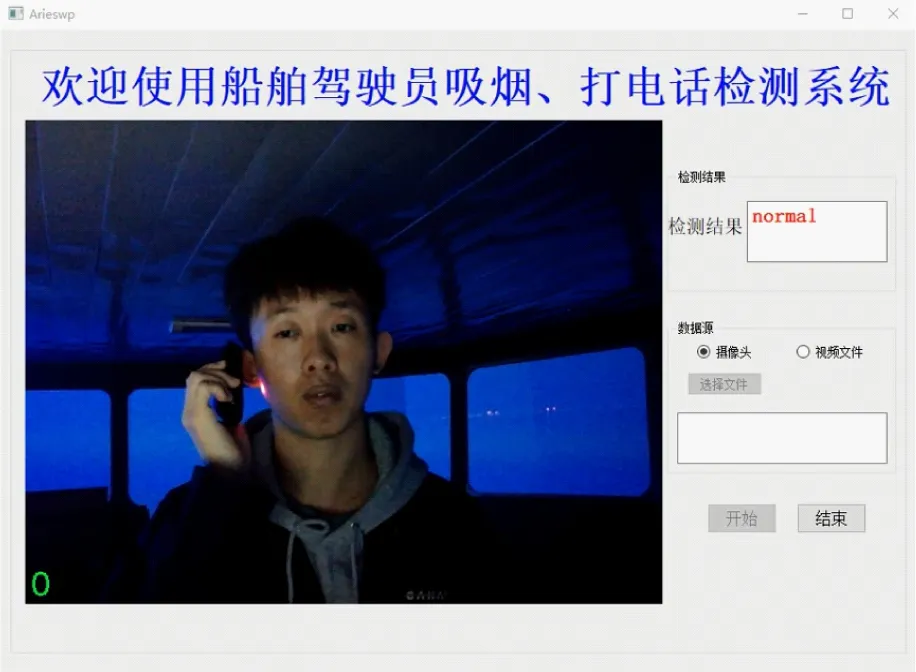
h)夜间疑似打电话
由图11不难看出,提出的吸烟和打电话行为检测算法可以较为准确地检测出驾驶员的吸烟和打电话行为,对不同环境光照、疑似吸烟、疑似打电话等干扰因素具有较强的鲁棒性,能够较好地适应船舶驾驶台的复杂环境,误检率较低,基本满足实时检测的要求。当检测出驾驶员吸烟或打电话行为的持续时间超过一定的阈值时,立即发出警报,提醒驾驶员集中精力操纵船舶,该阈值默认设置为60 s,可根据航行水域、天气海况等因素进行调整。
4 结 论
本文提出一种两阶段的船舶驾驶员吸烟和打电话行为检测算法,首先使用改进的RetinaFace网络提取人脸感兴趣区域,再使用改进的YOLOv4目标检测模型来检测该区域内是否存在香烟或手机,从而识别船舶驾驶员的吸烟和打电话行为。实验结果表明:本文改进RetinaFace人脸检测网络和YOLOv4目标检测模型可有效提高模型的检测速度;在数据集中加入负样本可显著降低模型的误检率;使用复制粘贴数据增强手段可明显提升模型的泛化能力;使用PyQt开发的图像界面程序在模拟驾驶环境中可以较为准确地检测出驾驶员的吸烟和打电话行为,对不同环境光照等干扰因素具有较强的鲁棒性,能够较好地适应船舶驾驶台的复杂环境,同时满足实时检测的要求。在后续工作中,尝试继续改进算法提高复杂环境下算法的可靠性。
