复杂工地环境下的安全帽视频AI监测算法的研究
2022-12-30佘宏彦安长智高佰灵梁理
佘宏彦 安长智 高佰灵 梁理
(1.湖南华菱湘潭钢铁有限公司,湖南 湘潭 411101;2.北京中泰创安科技有限公司,北京 100085;3.华菱涟源钢铁有限公司安全环保部,湖南 娄底 417000)
0 引言
在中国经济快速发展和新型城镇化的大力推进下,中国建筑行业正逐步出现规模化、结构功能多元化、生产流程复杂化、施工现场管理的新特点。以往粗放的管理方式,存在着人员频繁调动,施工管理混乱,资金利用率低,重大安全事故频发等问题,已经不适应安全管理的整体要求。如何提高对工程建设工地安全风险的监测、重特事故的发生、“三违”的防治,是当前安全管理的难题。于是,“智慧工地”应运而生,利用智能化的监管方式,通过对施工现场的安全巡查,及时发现安全隐患,时刻绷紧安全生产的生命底线。
在安全生产中,人是最重要的,也是最灵活的、最具活力的因素。智能工地要解决的问题有:如何利用智能化的方式有效、准确地掌控施工人员的安全状况,这也是施工现场安全管理的关键所在。而在工地上,设置了电子警示线,工人们穿上了安全帽和制服,就可以在一定程度上保障他们的人身安全,减少他们的安全隐患。因此,本论文重点研究了智能楼宇中的人员关联监测算法,以确保安全生产。通过人工智能对监控视频进行分析,利用深度学习技术对施工工地施工人员进行实时抓拍,24 h实时监测、预警施工人员站位不合理、未佩戴安全帽、未穿戴工作服等危险行为,实现规范施工管理、减少安全隐患、节省人力投入,为建筑施工安全生产保驾护航。1安全帽监测算法
1.1 Faster-RCNN算法
REN S等[1]于2015年提出了Faster-RCNN算法,该方法基于RPN候选框生成算法,在此基础上大大加快了对目标任务的监测。在Faster-RCNN模式下,头盔的配戴判定过程如下:输入头盔的试验图片,将整幅图片录入CNN,进行特征提取,再通过RPN进行编辑,生成一组Anchor box,再对其进行裁剪、筛选,最终判定anchors是前景,还是基础,即对象、非对象,因此,这是一个二分类;同时,另一条“bounding box regression”会对anchor box进行修改,以产生更加精确的proposal(注:更精确的是,在所有连接层中,同样的box regression),并将推荐窗口映射到CNN的上一个卷积feature map;然后,RoI pooling层中的每一RoI[2]生成一个固定尺寸的feature映射;最后,对分类概率和边界回归(SmoothL1 Loss)进行联合训练(Softmax Loss,SmoothL1 Loss)。Faster-RCNN的具体描述见图1、图2。
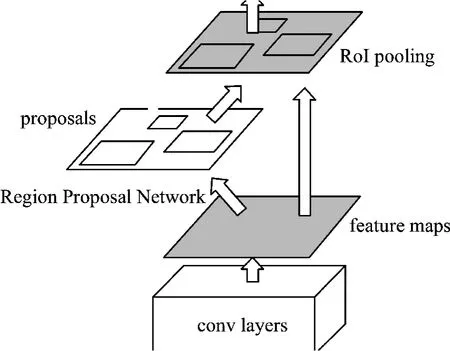
图1 Faster-RCNN结构详解
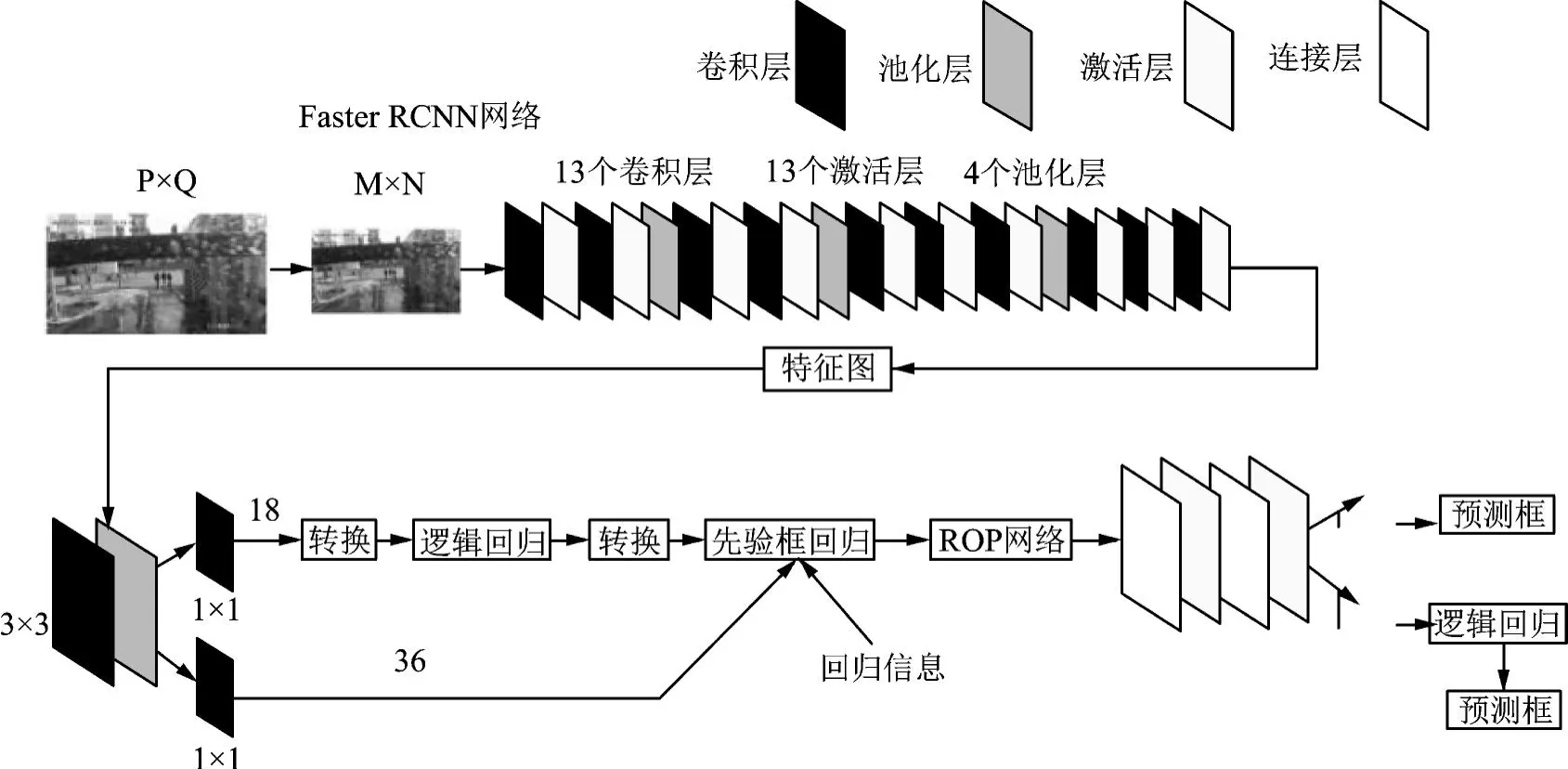
图2 Faster-RCNN网络组成
从上面的两张图[1]可以看出,Faster-RCNN由下面几部分组成:
1)数据集,image input;
2)基于卷积层的CNN等基本网络,从特征中抽取特征,得到feature map;
3)在RPN层中,通过卷积层提取的featuremap上用3×3的slide window遍历整个feature map,在遍历的过程中,每个window中心都会根据rate,scale(1∶2,1∶1,2∶1)产生9个anchors,然后将所有anchors进行二次划分(前景或背景),并输出300个更准确的ROIs。然后,用ROI pooling将通过卷积层feature映射的全部连接层的输入维度进行固定;
4)通过RPN的输出rois映射到ROIpooling[3]的feature map上进行bbox回归并对其进行分类。
1.2 YOLO算法
YOLO有最小的网络,最小的速率和最精确的AP。不过,如果是以大数据量的目标来测试,YOLO在执行速率上表现得更为出色,YOLO的模型只有十几兆左右,而且速度很快,在线上环境中运行也能起到很好的作用,能实现低延迟、实时监测的效果。
首先,进行Mosaic数据增强(9),先读出4个图像,再对4个图像进行翻转、缩放、色域变化等,再沿4个方向进行排列,最终完成图像和方块的拼接。YOLO算法中,在不同的数据集上,都会有一个固定长宽的框架。在网络训练中,通过对原始锚框的分析,将预测框和实际框groundtruth进行对比,得到不同的结果,再进行反向更新,对网络参数进行迭代。将原来的608×608×3的图象录入Focus结构,再将其分割为304×304×12的特征图,再对32个卷积核进行卷积,最终生成304×304×32的特征图。接着,采用FPN+PAN(PAN)的方法,将上层的特征进行上采样,进行数据的传递和融合,得到相应的预报结果。在YOLO中,利用CIOU_Loss来预测目标Bounding box的损耗。
1.3 SSD算法
本文在安全帽监测试验中引入了SSD算法[4],见图3。首先将头盔监测图象(像素大小为300×300)输入,并在VGG16网络中加入相应的特征映射;接着,将VGG16的FC6和FC7分别转化为卷积,并将其与Conv6、Conv7相对应;移除所有Dropout和FC8;添加Atrous(hole)算法;将Pool5的变换从2×2-S2到3×3-S1;接着,从Conv4_3、Conv7、Conv8_2、Conv10_2、conv11_2层中的featuremap,在各个点上分别构建6个bbox,并分别对bbox进行监测和分类;利用不同feature映射的bbox,利用NMS(NMS)对bbox进行抑制,生成最终bbox集,也就是最终bbox集。
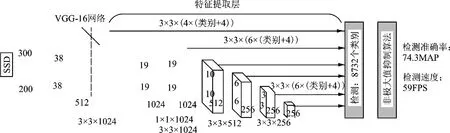
图3 SSD模型
SSD算法采用了多尺度特性映射(maps),SSD算法采用了conv4_3、conv_7、conv8_2、conv8_2、conv9_2、conv10_2、conv11_2等多种feature maps。由于底层feature map的感知范围较小,而上层的感知范围较大,因此使用不同的feature map可以实现多尺度的目标,而SSD中的Defalut box[1]与Fasterrcnn中的anchor机理类似。就是预设一些目标预选框,后续通过softmax分类+bounding box regression[5]获得真实目标的位置。不同规模的feature映射使用了不同的Default boxes。我们选择了38×38×512,19×19×1024,10×10×512,5×5×256,3×3×256,1×1×256,在conv4_3后面的feature map默认box为4,我们得到了38×38×4=5 776个box;同样地,我们也可以把每台机器人的数目设置为6、6、6、4、4,这样我们就能得到832个盒子,并把它们放进NMS组件[6],得到最后的监测结果。
2 实验结果对比
针对安全帽监测,我们通过现场实时监控系统采集的影像,构建了1 500张图片的数据集,对1 500幅图像进行了标记、训练,最后对100幅图像进行了安全帽监测实验。基于所构建的图片数据集,我们分别利用上述3种算法进行了实验,得出训练模型,并利用100张相同的图像进行模型的测试,具体实验结果如表1。如表所示,通过性能对比,我们可以看到,针对安全帽监测数据集,SSD具有最高的mAP(mean Average Precision)和精确率(Precision),Faster-RCNN具有最高的召回率(Recall)。此外,利用YOLOv5算法得出的模型可以达到21帧/s的速率,基本满足实时监测的需要。

表1 YOLOv5、SSD、Faster-RCNN算法性能对比
图4—图6是安全帽监测的实际测试样图。

图4 SSD测试样图

图5 Faster-RNN测试样图

图6 YOLOv5测试样图
从图中可以看到,针对实际场景下的安全帽监测,上述3种算法均正确监测出了安全帽的佩戴情况,将未正确佩戴安全帽的标记为不同的颜色。参照表1提供的对比性能,我们发现Faster-RCNN的精准度虽然是最高的,但是算法执行速度比较慢,不能满足视频实时监测的效果,YOLOv5正好相反,速度比较快但是监测精准度略低于其他两种方法,SSD结合了两者之长。从理论上讲,SSD借鉴了YOLO将探测转换为regression的原理,并参考了Faster-RCNN中的anchor,但其anchor并没有像YOLO那样对每一个点进行细化,而是使用了栅格,生成了一个anchor。SSD采用多层次特性,使得每个层次的anchor都有差异,从而产生了更多的超参数,从而提高了训练的难度。
3 结语
本文对复杂工地环境下的安全帽视频AI监测算法进行了研究,详细介绍了现有的3种经典目标监测算法Faster-RCNN,SSD和YOLO的相关网络结构,构建了实际场景下的安全帽图片数据训练集和测试集,并利用实验的方式对3种算法的性能进行了比较。综合考虑安全帽现场监测的精度和算法执行速度,可以得出YOLOv5更适合复杂工地环境中的安全帽实时监测。
