基于样本相似度的三支聚类算法
2022-12-29李刘万王平心
李刘万, 朱 金, 王平心
(江苏科技大学a. 计算机学院; b. 理学院, 江苏 镇江 212003)
聚类是数据挖掘算法中常用的方法,它可以有效发现事物之间的内在联系,将隐含在数据集内部的结构特征描述出来.聚类的目的就是将给定数据集划分成不同的类簇,使相同簇中的样本相似度较高, 不同簇中的样本相似度较低.多年来,聚类已在目标检索[1]、数据挖掘[2]、生物医学[3]等研究领域得到广泛应用.聚类集成的基本思想是用多个独立的基聚类器分别对原始数据集进行聚类, 然后设计有效的一致性函数对基聚类成员进行集成, 最后得到统一的数据划分.与单一的聚类算法相比, 聚类集成算法具有更高的鲁棒性、稳定性和聚类质量.聚类集成技术已被有效地用于处理许多聚类任务, 如分类数据[4]、高维数据[5]、噪声数据[6]、时间数据[7]、特征选择[8]等.
传统聚类算法属于硬聚类, 即二支聚类, 该种聚类要求类簇之间边界清晰,但在实际聚类过程中常常遇到信息不充分的情况, 如果将数据对象强行划分到某一类簇, 会增加误分类的概率,导致聚类精度降低.针对传统聚类方法的不足,许多软聚类方法应运而生.三支决策理论的核心思想是将研究对象分为正域、负域、边界域,分别对应接受、拒绝以及不承诺三种决策规则.Yu等[9]将三支决策的理论应用到聚类中, 提出了三支聚类理论.基于这一理论, Wang等[10]将数学形态的侵蚀和膨胀思想引入聚类中, 提出了CE3框架.与二支聚类算法相比, 三支聚类引入了边界区域的概念, 可有效解决传统二支聚类算法中因信息不完整或数据不足导致的分区不准确问题.
聚类结果主要受聚类数量和阈值的影响.在现有的工作中,人们通常根据专家选择合适的类簇数目, 并在聚类的迭代过程中为所有数据选择相同的阈值.然而这种固定阈值和类簇数量的选择并不能很好地表明类簇与数据集之间的差异, 尤其是对于不同大小和密度的数据集.本文将三支聚类的思想和聚类集成思想相结合, 提出一种基于样本相似度的三支聚类算法.该算法首先通过随机选择样本部分特征的方法生成一组基聚类成员,以此构造样本相似度.然后利用样本相似度定义划分有效性指标, 用以自动计算最优阈值.最后, 使用投票法对基聚类成员集成得到初步的聚类结果, 再利用最优阈值对其进行划分, 得到最终的核心域集合和边界域集合.
1 基于样本相似度的三支聚类方法
1.1 阈值的自适应选择

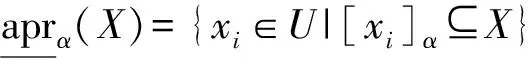

在三支聚类问题中,倾向于得到一个分类误差较低的分区, 并将不确定性样本放在边界域以延迟决策,因此在增加边界域的同时也增加了粗糙度,可通过最小化粗糙度限制边界域.无论边界域最大化还是粗糙度最小化,划分有效性指标值均趋于0, 故选择最大PVI的值作为粗糙度和边界域取值的平衡点, 以达到更好的聚类效果.其最大PVI(X)由最优阈值α决定.
为获得α最优值, 设置适当步长遍历所有候选阈值.在该算法中, 首先计算样本相似度.步长为0.01的样本相似度最小值Smin和最大值Smax构成候选阈值空间.对于每个候选阈值, 计算目标子集X对应的核心域和边界域,得到当前的划分有效性指标.最后, 输出当前达到最大PVI值的阈值作为最优阈值.图1为阈值的自适应选择方法的流程图.

图1 阈值的自适应选择方法的流程图Fig.1 The flowchart of an adaptive selection method for thresholds
1.2 基于样本相似度的三支聚类
聚类集成首先要获得一组基聚类结果, 现有的聚类集成方法常使用不同的聚类算法生成不同的基聚类结果, 而本文算法使用样本的部分特征获得基聚类结果.对于一个具有m个特征的数据集, 随机抽取部分特征, 使用传统的聚类算法得到聚类结果.不同的特征会导致不同的聚类结果.重复上述过程L次, 得到基聚类成员C′1,C′2,…,C′L.


图2 基于样本相似度的三支聚类方法的流程图Fig.2 The flowchart of three-way clustering selection method based on sample similarity
2 聚类性能评价指标
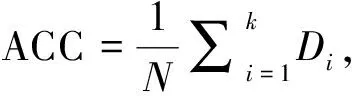
3 实验结果
为测试基于样本相似度的三支聚类算法的有效性, 本文选取8组常见的UCI(University of California Irvine)标准测试数据集, 使用核心域的结果计算ACC、NMI和ARI的值, 并与k-means算法、FCM算法和一种基于k-means的自动三支聚类算法TWC[14]进行比较.每组数据集进行50次聚类集成,每次聚类时随机提取特征的百分比设置为70%,实验结果如表1所示.由表1可知,与其他3种算法相比,本文算法的ACC、NMI和ARI值具有明显的优势.说明本文算法能有效提高聚类精度,更好地显示聚类结果.
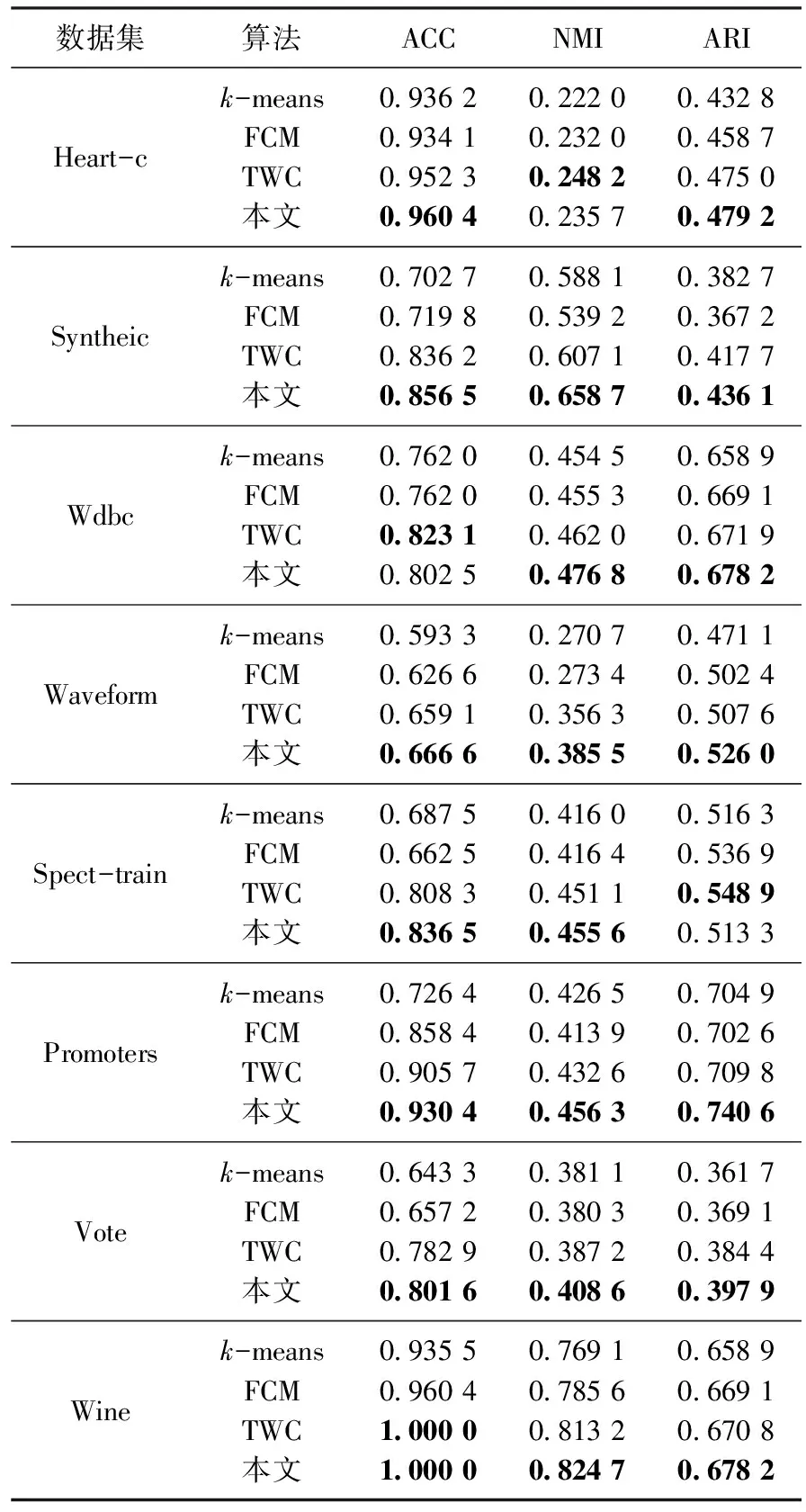
表1 UCI数据集上的结果
