水电厂跨区数据融合安全策略及方法研究
2022-12-26张洪涛张军华宋美艳张会军仝亮张冰
张洪涛,张军华,宋美艳,张会军,仝亮,张冰
(1.华能澜沧江水电股份有限公司,云南昆明 650214;2.南京南瑞继保工程技术有限公司,江苏南京 211002;3.西安热工研究院有限公司,陕西西安 710054)
0 引言
水电厂多采用非线性传感器输出,加上现场环境温度、湿度、电源波动等因素,存在很大的输出信号波动,监测困难,难以及时反映被测物理量。而且机组受到不稳定和不精准数据影响,容易出现停机故障,经常进入检修状态。随着水电厂规模不断扩大,需要的工业技术也在不断更新,水电厂控制系统日趋复杂,这对水电厂生产过程控制系统提出了更高的技术要求。由于系统无需对每一个生产环节在精准时间上进行控制,从而使模糊逻辑控制能够应用于生产过程。将控制系统中熟练的操作经验转化为模糊规则,使用该方法之前,系统的维护状态完全取决于现场人员的调试,在许多情况下,没有得到适当的维护或维修。为此,对跨区数据安全融合是具有必要性的。陈泗贞等[1]使用了一种在COMTRADE 模型支持下应用的多源故障数据融合方法,利用集对分析理论,分析多源故障数据,并整合相同故障事件数据。以COMTRADE 文件格式为基础,结合BF 算法对齐故障事件整合时间,实现数据融合;田明明等[2]提出了一种在复杂环境下,利用多传感器融合数据的方法,该方法通过使用多传感器采集故障数据,通过当前节点传输程度,引入支持度来修正传输信任度,并在数据融合阶段,不断重复上述过程,直到融合收敛为止,完成数据融合。尽管上述两种方法能够融合数据,但不能保证数据融合的安全性。为解决该问题,提出了水电厂跨区数据融合安全策略及方法。
1 水电厂跨区多元异构冗余数据滤波处理
在实际跨区数据传输环境中,传感器节点受到输电线路的电磁影响,信号在传输过程中受到噪声干扰,导致数据传输质量较低。当相同类型的多个传感器不断地监视相同的设备状态时,产生大量冗余数据。在数据传输过程中,海量冗余数据的传输,浪费了通信网络的带宽资源,甚至导致网络拥塞。被噪声干扰的监测数据传送到控制中心,也会对设备状态的准确评价产生不可忽视的影响。在电力设备多源数据中,存在着数据冗余和“真假”值筛选的矛盾。根据电力设备多源数据的特点和存在的问题,提出一种事件驱动的多源冗余数据融合方法[3],降低了节点间通信量的冗余数据传输,提高区域间多个异构数据融合的效率。
1.1 基于需求协方差的干扰事件判定
选择需求协方差来描述融合误差与事件之间的关系,由于更新值与真实值之间的差异,需求协方差是稳定的,所以干扰事件判定策略由需求协方差定义。其基本思想如下所示:

式中:给定的协方差阈值β是一个重要参数,其决定了在t时刻节点i与其他节点之间的通信频率。该参数的选择也与判定环境有关,如果未触发干扰事件,则=0,说明在t时刻节点i不与其他节点之间通信,也就不会进行跨区数据交换;如果触发干扰事件,则=1,说明在t时刻节点i与其他节点之间通信,需要进行跨区数据交换。
1.2 基于事件驱动的滤波处理
为了减少冗余事件的传输,结合基于需求协方差的干扰事件判定策略,提出了基于事件驱动的滤波处理流程,主要有四个步骤:目标状态监测、事件监测、融合和状态估计。
首先,在每次滤波循环期间,更新邻节点估计值,公式为:

然后,事件监听器策略就会根据事件来判断事件是否发生,如果发生了,则为邻居节点范围内的节点数据通信交换和邻居节点范围通信;若未出现最佳融合误差,借助卡尔曼滤波算法处理相关数据,无需与邻居节点通信,减少冗余数据的传输[4]。
最后,在t时刻节点i的测量值和相邻节点间通信的估计值基础上,通过公式(4)得到节点最优估计值。

2 基于改进粗糙集的水电厂跨区安全数据融合
根据上述获取的节点最优估计值,利用改进粗糙集搜索待融合数据,并使用物化视图和触发器捕捉方式,完成水电厂跨区安全数据融合。
2.1 基于改进粗糙集的待融合数据搜索
为缩短数据融合时间,使用双向同时搜索和协作模式,检索待融合数据表中的条件属性,并将其组合,等待再次搜索。基于此,设计的基于改进粗糙集的待融合数据搜索流程,如图1所示。
由图1可知,在三维阵列S中,定义条件属性为Cori,决策属性为Dori。为了减少数据计算结果冗余度,设计的基于改进粗糙集数据融合流程详细步骤如下:

图1 基于改进粗糙集的待融合数据搜索流程Fig.1 Search process of data to be fused based on improved rough set
步骤1:对一个预处理属性得到所有不重复的条件属性集C和决策属性集D,再用相应编号属性对S进行分割,得到了U/C和U/D值。用该方法进行U/D交叉运算,如果所得到的运算集合小于原U/C中的非空集,就说明U/C不能正确区分U/D[5]。
步骤2:该组合包含了所有m个非core 条件属性,而相邻位置标记f_stop、R_stop 和NEAR_flag,所有m的非核心条件属性集都被组合起来C'(f_stop 表示正向搜索停止、r_stop 表示逆向搜索停止、near_flag 表示当正向约减的非核实属性数目和逆向约减的非核实属性数目邻近时,标志为1)[6]。
步骤3:从m个非核心条件属性集中选取一个属性的组合,可以对m个非核心条件属性集进行约简,逐渐增加属性数量,增加的个数可表示为i_f,并结合属性进行了分类,确定了分类结果。逆向恢复过程如下:在m个非核心条件属性集中选取m个属性的组合,属性的数量逐渐减少。简化后的数字可表示为i_r,结合核可判断分类结果(i_f表示正向约减的非核实属性数目,i_r表示逆向约减的非核实属性数目)。
步骤4:当增加的个数组合和减少的个数组合不相邻时,near_flag值为0,并保持不变,约减步骤为:
步骤4.1:如果在过程中可以区分U/D属性组合,则逆向还原停止标志不为1 时,当前反推器的未校验属性数目和组合的编号位置应及时记录,然后进入下一个周期组合;
步骤4.2:当逆向约减时,如果对当前逆向约减的非核属性数目和逆向搜索停止属性数目进行遍历组合后找不到可以区分U/D的属性组合时,当前逆向约减标记被设为1时,暂停当前逆向约减法;
步骤4.3:逆向恢复停止标志为1 时,如果恢复期间出现可区分U/D的属性组合,目前的正向压缩过程应该立即暂停,并且记录未验证的属性的当前正向压缩的数量以及相应的组合数目no_f。与此同时,逆向约减停止标志为1,以停止逆向约减过程。(no_f表示正向搜索属性下的验证组合编号)[7]。
步骤5:当增加的个数组合和减少的个数组合相邻时,near_flag值为1,并保持不变,约减步骤为:
步骤5.1:在逆向恢复期间,r_stop 停止标志为0,正向恢复停止标志为1。在该期间,如果出现属性组合U/D 时,就应立刻记录该组合,并向R_RED集合中添加相关属性。延续目前的逆向恢复过程,直到遍历全部属性,或者r_stop 停止标志变为1 为止(R_RED表示存放逆向约减过程中搜索到的非空集合);
步骤5.2:在遍历之后,R_RED 不是空集,需判断逆向约减等待过程标志是否为1。如果等待过程标志为1,说明在正向约减过程中,缺少相关属性添加到R_RED 集合中,此时,f_stop 被设置为1,而这个集合就是非空集合。r_stop停止标志为1,则应立刻停止逆向约减,直到出现符合条件的组合为止;如果等待过程标志为0,说明正向约减过程中出现了属性组合,并添加到R_RED集合中,此时逆向约减过程逐渐向正向约减过程过渡。
步骤5.3:在逆向约减过程中,如果r_stop停止标志是0而不是1时,遍历全部属性组合后,仍然无法获取能够区分U/D属性的组合,应减少属性组合编号。这样,在最后一次搜索之后,重新记录逆向约减过程中的所有编号,此时的f_stop标志为1。
步骤5.4:在重新编号后,判断逆向约减过程中r_stop 停止标志,如果该标志为0,则说明正在进行正向约减过程,而正向约减过程的r_stop 停止标志为1 时,说明完成了约减过程,并未发现最小约减。如果r_stop停止标志为1,则说明正在进行逆向恢复过程,立刻记录i_r 和no_r 编号(no_r 表示逆向搜索属性下的验证组合编号);
步骤5.5:如果可以完全区分U/D 属性的组合,并且停止标志f_stop 不是1,那么它就可以被完全区分,如果可以完全区分U/D 属性的组合,并且停止标志f_stop 不是1,那么它就可以被完全区分,
步骤5.6:如果遍历当前条件属性组合,没有发现完全区分U/D的属性,则保证约减标记f_stop 不是1,就可以将等待标志设置为1,由此完成基于改进粗糙集的待融合数据搜索[8]。
2.2 跨区数据安全融合
在搜索到基于改进粗糙集的待融合数据后,构建水电厂跨区数据安全融合体系,如图2所示。

图2 水电厂跨区数据安全融合体系Fig.2 Cross-district data fusion system in hydropower plants
由图2可知,水电厂跨区除了需要实时传输海量数据之外,还需在水电厂安全Ⅰ、Ⅱ、Ⅲ区之间同步传输频率较低、数据一致性高的历史数据。尤其是Ⅲ区,对于历史数据中的综合业务数据极为敏感,该方法要求数据具有高度一致性,且不能出现数据丢失现象,为此,需要使用比使用总线实时传输数据更加可靠的安全传输方式,即在保证跨区数据安全融合前提下再进行数据传输。
2.2.1 基于物化视图的安全I、Ⅱ区数据安全融合策略
智能水电厂安全I、Ⅱ区之间有防火墙,通过安全I 区历史数据库服务器节点与安全Ⅱ区的历史数据库服务器节点之间的物理通道,利用物化视图法实现从I 区安全历史数据库到II区历史数据库的单向数据同步。通过物化视图法预测数据存储结果,这样在表连接或聚合过程中就可以避免查询过于耗时问题的出现,并能迅速得到结果,由此能够形成更加稳定可靠的跨区数据安全融合通道。
构建的基于物化视图的跨区数据安全融合通道,如图3所示。
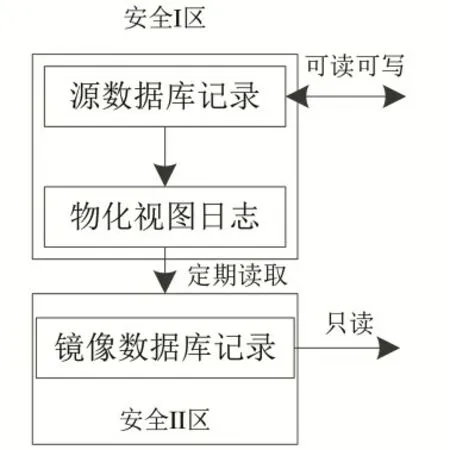
图3 基于物化视图的跨区数据安全融合通道Fig.3 Cross-district data security fusion channel based on materialized view
由图3 可知,利用数据库物化视图实现多个区之间数据安全融合,详细步骤为:
步骤一:为源服务器上现有基础表创建一个实体化视图日志,在该日志中存储有关数据库软件自动更新的所有数据;
步骤二:创建目标服务器上的镜像,当镜像创建完成时,指定一个区域,这样就可以在同步刷新过程中确定数据源的位置;
步骤三:对目标服务器执行完整更新,以便与源数据库中的基表以及目标数据库中镜像表内容进行匹配。
步骤四:定期更新源服务器日志,获取在目标服务器上配置计划的数据库任务。通过物化视图将安全I区历史数据同步到安全Ⅱ区,以确保数据的可靠性和完整性。但安全Ⅱ区中的历史数据只能读取,不能修改。按照预设的时间间隔来及时更新资源任务,并将更新结果记录到目标服务器映像表中,由此完成跨区数据安全融合操作。
2.2.2 基于触发器方式捕捉的安全Ⅱ、Ⅲ区数据安全融合策略
安全Ⅱ、Ⅲ区历史数据库是物理隔离的,通过使用数据库触发模式,可以有效地捕获数据表中记录的所有更改内容,并能够定期地和其他安全区域同步。基于触发器方式捕捉的数据融合原理,如图4所示。
由图4可知,该模式用于捕捉数据的变化,开发安全隔离程序,在Ⅱ、Ⅲ区实现数据融合,详细步骤为:

图4 基于触发器方式捕捉的数据融合原理Fig.4 Data fusion principle based on flip-flop capture
步骤一:利用单片机平台的安全隔离软件组态界面,对安全Ⅱ区数据库中需要传输数据的基表设置触发器,捕捉该表中添加、删除、变更操作的数据,并将这些更改保存到I 区临时数据表中。根据不同应用,选择传输的数据表。安全Ⅱ区数据库配置的基表中,任何数据的增加、删除、更改和操作时间都将记录在临时数据表中。
步骤二:安全Ⅱ区网关服务器的安全隔离客户端软件定期对临时数据表进行扫描,将数据按指定格式形成文件,存储在独立且指定的文件位置。安全性隔离装置将这些文件传送到安全Ⅲ区网关的指定文件夹中。与此同时,清除临时数据表中冗余数据。
步骤三:定时扫描安全Ⅲ区网关指定文件夹,当安全隔离服务器软件检测到更新文件后,根据安全Ⅲ区数据库中的文件内容及时更新,完成数据融合。
3 结语
智能化水电厂集成平台数据库是整个系统运行的基础,数据的一致性和准确性直接影响到各种应用的可靠性。利用跨区域数据融合功能,实现各个安全区数据的实时性、一致性。通过基于物化视图的跨区数据安全融合通道和触发器捕捉方式,实现水电厂跨区数据安全融合。该方法对于大数据集尤其有效,而现阶段水电行业已积累了大量各类数据,使用该方法能够获取更多有意义、有价值的数据,提高水电行业的管理水平。
然而,现有方法仍存在不足,主要是对某一数据集来说搜索速度不够快。因此,改进应集中在提高搜索能力和自动优化搜索位置方面。
