基于随机森林算法的WANO机组能力因子分类
2022-12-26侯秦脉吴彦农张泽宇王娅琦
朱 伟,侯秦脉,吴彦农,张泽宇,王娅琦,胡 江
(1.生态环境部核与辐射安全中心,北京 100082;2.中核战略规划研究总院有限公司,北京 100048;3.建信金融租赁有限公司,北京 100031)
1 研究背景
自中国加入国际原子能机构(International Atomic Energy Agenc, IAEA)以来,中国政府高度重视核安全,在发展核能事业中始终贯彻“安全第一”的方针,根据《核安全公约》和《核安全公约国家报告指南》的要求,于1998年中国政府编制了第一次《中华人民共和国核安全公约国家报告》(以下简称《国家报告》),全面介绍了中国履行《核安全公约》义务的情况,发布了3年我国运行核电厂的世界核电厂营运者联合会(The World Association of Nuclear Operators, WANO)性能指标(1996 至1998年),这些数据用于展示这3年间WANO 性能指标总体趋势。截至2019年,中国共发布八次《国家报告》[1],目前已启动第九次《国家报告》的编写工作。
WANO 业绩指标以定量化的方式评估电站在电站安全性和可靠性以及人员安全性方面的业绩。WANO 业绩指标主要用于监测电站的业绩,设定具有挑战性的改进目标,更方便与其他电站进行业绩比较,以及评估为改进总体业绩是否需要调整优先次序和资源[2]。此领域研究目前多为数据采集和一般的管理性描述和研究。林传清[3]分析了技术管理对核电厂运营管理的重要性,指出WANO 业绩指标中机组能力因子是最重要的指标之一,能够反映出优化计划和非计划停堆或停机活动的有效性,提高核电厂的竞争力;郑龙[4]研究建立WANO 人因数据采集与处理系统框架,结合SQL 和NET 框架平台设计实现了一个集数据收集,维护,准备,应用等功能于一身的WANO 人误统计分析系统;吴博[5]选取了Apriori 关联规则算法,建立WANO 人因数据采集与处理系统框架;庞瑞等[6]总结了红沿河WANO 指标的执行情况,提出提高发电能力,减少非计划能量损失的管理改进建议,从安全系统高性能、燃料可靠性、化学指标夯实核安全基础。吴爱民[7]使用业务流程重组方法(BPR)分析和优化核心业务工作流程,实现WANO 性能指标的提升。
WANO 机组能力因子分类涉及二分类问题,可以通过Logistic 回归(logistic regression)和随机森林(random forest,RF)解决。Logistic 回归是一种广义的线性回归分析模型[8],而RF 基于的决策树模型[9],两种方法常用于数据挖掘领域,都能够有效处理非线性的二分类问题。RF 能够处理高维问题,克服传统模型处理复杂交互不足,提供变量的重要性度量等有用信息,具有分类效果好、准确率高和性能稳定等优点[10]。建立一种快速、准确区分能力因子的分类方法,对于定性掌握我国核电机组发电状况及行业内机组所处状况判定具有重要的应用价值。正是基于此,本文以第一至第八次《中华人民共和国核安全公约国家报告》中世界核电营运者协会(WANO)性能指标为研究对象,提出一种基于RF 的机组能力因子分类方法,与Logistic 回归进行对比。
2 数据预处理与精度评价
2.1 数据说明
本文利用获取1996 至2019年8 次《国家报告》中WANO 业绩指标,以机组和年为维度共提供295组截面数据,每组数据包括机组能力因子(UCF)、临界7 000 h 非计划自动停堆数(UA7)、高压安注系统(SP1)、辅助给水系统(SP2)、应急交流供电系统(SP5)、燃料可靠性(FRI)、化学性能(CPI)、集体辐照剂量(CRE)、工业安全事故率(ISA),变量定义见表1 所示。其中,UCF 反映电站是否能有效实施相关的大纲和实践以尽量增加可用发电量,而且能总体反映电站的运维情况。UA7反映电站是否能通过减少需要紧急停堆造成不必要和非计划热工水力和反应性瞬变次数而成功改善电站安全性的情况,此外也能反映电站的运维情况。SP1、SP2、SP5 此3 类系统对于防止堆芯受损或延长停堆大修具有重要意义,所以选择此类系统考核安全系统性能指标(safety system performance index,SSPI)。FRI 培养业内人士重视燃料完整性的健康态度,存在破损燃料会导致防止站外释放裂解产物的初始屏障失败,破损燃料也会对运营成本和业绩产生不利的影响,并增加电站工作人员的辐射风险。CPI 按照反应堆和蒸汽发生器类型和化学条件根据电站需监测系统中的重要杂质和腐蚀产物浓度计算得出,化学指标将多项关键化学参数综合为一项能纵观电站运行化学控制相对有效性的指标。CRE 用于衡量尽量减少电站工作人员所接受辐照剂量的辐射防护大纲有效性。ISA 是更重要的人员安全指标,原因是其准则明确,核电公司现时有收集此类数据,且数据的主观性最低。WANO 业绩指标变量定义见表1 所示。

表1 WANO 业绩指标变量定义
2.2 数据准备
我国WANO 业绩指标描述性统计分析如表2所示,1996 至2018年机组能力因子的平均值为87.79%,依据平均值区分机组能力因子高低,定义虚拟值“1”和“2”分别代表“低”和“高”,其中低于均值129 组,高于均值166 组。本研究将UA7、SP1、SP2、SP5、FRI、CPI、CRE、ISA 作为模型的输入变量,UCF 作为模型的目标输出变量,确定建立容量9×295 的样本集用于机组能力因子分类预测的随机森林模型,其中数据按照7:3 的比例分割为206 个训练数据样本和88 个无缺失项测试数据样本。

表2 WANO 业绩指标描述性统计分析
2.3 精度评价
二分类问题通常通过混淆矩阵列出预测分类与实际分类的结果,便于进行准确性和可靠性的评价。在精度评价方面提取混淆矩阵信息得到总体精度、Kappa 分析、生产者精度、使用者精度等4 个指标:总体精度是对每一个随机样本,所分类的结果与对应区域的实际类型相一致的概率;Kappa 分析是一种测定实际与预测分类之间吻合或精度的指标,系数结果为-1 至1,越接近1 表示精度越高;使用者精度是分类结果中任选一个样本,其与实际业绩指标相一致的概率;生产者精度是实际业绩指标任选一个样本,其与分类结果相同的概率[11]。本文通过公式(1)~(4)对WANO 业绩指标混淆矩阵分类结果提取上述4 个指标来进行精度评价。
生产者精度:

使用者精度:

总体精度:

Kappa 系数:

上式中,N为性能指标样本总量;xij为实际指标数据第i类和分类结果第j类对应的样本数;xi+为实际指标数据第i类的总和;x+j为分类结果第j类的总和。
3 参数选择及分类可视化结果
3.1 参数选择
本研究基于R 4.3.1 语言和randomForest 4.7-1构建随机森林的机组能力因子分类模型。在训练过程中,参数选择对最终分类的精度有极其重要的影响[12],有必要选择RF 算法中最重要的两个参数:决策树数量(n_tree)和内部节点再划分所需要的最小样本数(m_try)[13-14]。
m_try 采用caret 的机器学习模型调参的工具,使用trainControl 函数对调参过程进行设置,指定了调参方式为10 折交叉验证(CV)[15],并指定调参顺序为grid,设定m_try 的范围是1 ~10。调优结果在默认情况下,RMSE 和R 方用于回归,准确率(Accuracy)和Kappa 系数用于分类[16]。本分类研究根据Accuracy 和Kappa 系数来判断参数的好坏,十折交叉验证下m_try 调优结果如表3 所示,可以看出m_try=2 在十折交叉验证下精确度为0.714 3 和Kappa 系数0.419 6 同为最大,m_try=2 可作为预测模型的最优超参数。
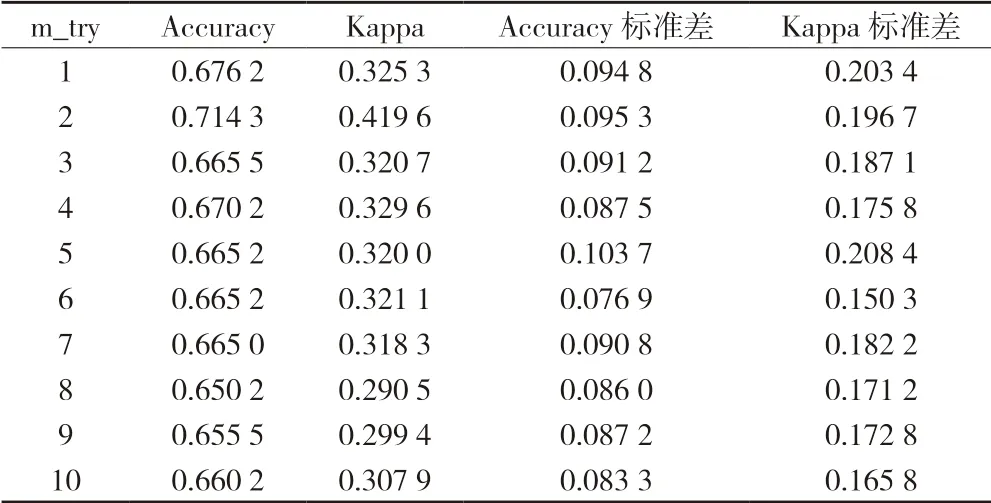
表3 十折交叉验证下m_try 调优结果
n_tree 的选择将影响随机森林的运算速度以及其分类的效果,较多的子数可以让模型有更好的性能[17]。n_tree 取值小时无法很好地刻画非线性关系,一开始袋外分类误差将明显下降,随着训练增加在临界值处模型拟合充分,袋外分类误差将趋于稳定,继续训练并不能显著提高模型的性能,所以需要在可模型接受范围内寻找袋外分类误差临界值使机组能力因子分类精度最高[18]。
在m_try 等参数固定不变的条件下,分析n_tree对机组能力因子分类精度的影响,袋外分类误差(out-of-bag error,OOB error)随决策树n_tree 的变化见图1 所示。从图1 可以看出n_tree 在500 以内,在n_tree=20 之后袋外分类误差趋于稳定,在n_tree=32 处得到最小值0.296,考虑准确率和运行效率,模型决策树数量选定为32,在图1 中用虚线表示。

图1 决策树数量对袋外分类误差的影响
3.2 UCF 分类的可视化结果
多维尺度变换(multidimensional scaling, MDS)由n个对象之间的相似性给定,确定这些对象在低维空间中的表示,并使其尽可能与原先的相似性大致匹配,保证调参的模型分类准确度[19]。高维空间中每一个点代表一个对象,因此点与点之间的距离和对象之间的相似度高度相关。通过MDS 对RF$proximity 相似度矩阵进行降维,得到UCF 分类的可视化结果见图2,从图2 可知UCF 总体上得到了有效区分,右侧椭圆中主要分布的是由三角形代表“高”,以圆形代表“低”集中分布在左下角椭圆中,总的来看调参后的模型达到了分类准确度。
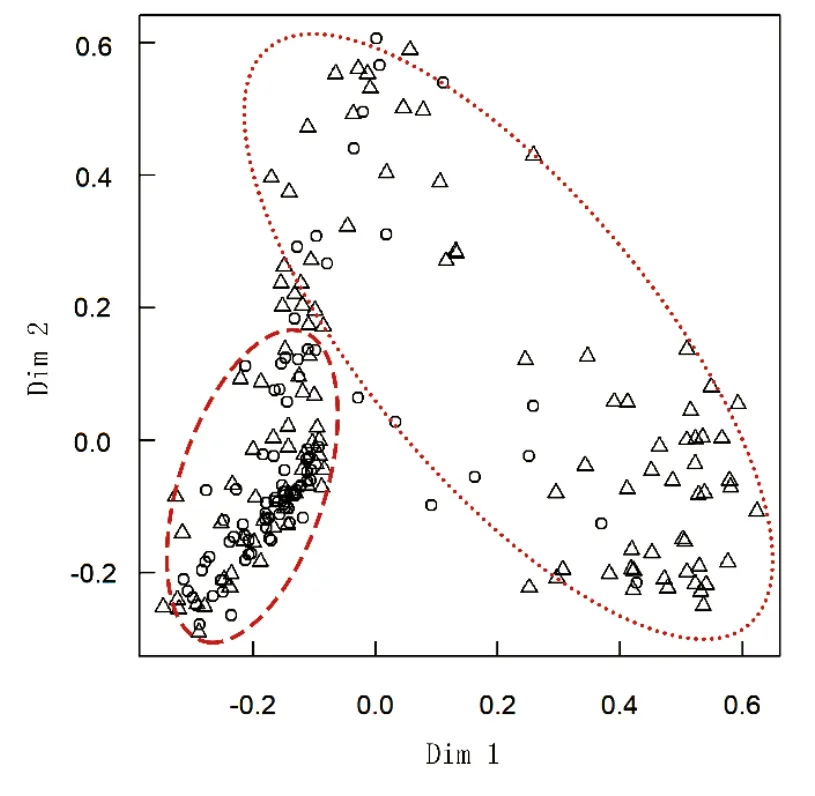
图2 UCF 分类的随机森林MDS 图
4 结果分析与精度验证
4.1 特征重要性分析
衡量机组能力因子分类RF 模型的8 种特征重要程度通过改变WANO 变量顺序得到袋外分类误差来实现。基于节点不纯度的平均减少值,Gini 值平均降低量(mean decrease gini)可以得到对所有树每个节点上观测值的异质性的影响,作为度量变量重要性的指标[20],该值越大表示该变量重要性越大,自变量对UCF 选择的重要性见图3 所示。
从图3 横坐标重要性的平均减少值可知,对机组能力因子分类影响较大的3 个重要变量依次是:集体辐照剂量、临界7 000 h 非计划自动停堆数、应急交流供电系统;此外,与防止堆芯受损及延长停堆大修的安全系统性能指标(SSPI)相关的特征变量SP1、SP2、SP5 对于UCF 的影响略有差异,应急交流供电系统SP5 重要程度明显高于高压安注系统SP1、辅助给水系统SP2,其中SP2 略低于SP1;化学性能CPI 及燃料可靠性FRI 的重要程度与SSPI 差异不大;代表工业安全业绩的工业安全事故率ISA对UCF 重要程度略低。
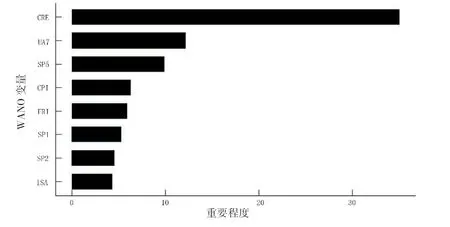
图3 自变量对UCF 分类的重要程度
RF 处理高维数据能力能够较好地进行分类和变量筛选,通过分类评价变量的重要程度,有利于在复杂的核电厂大量数据中获取重要特征信息。经过RF 分类特征重要程度,依据重要程度调配公司资源,对提高机组能力因子具有重要的应用价值。
4.2 精度验证
为进一步验证所建模型的准确性,利用测试集进行验证,RF 的UCF 分类结果基于分类对象的混淆矩阵实现,分类结果见表4 所示。由表4 可计算得到UCF 预测分类与实际分类一致的数量达到68,则UCF 的分类预测结果达到实际的77.27%,表明不同的核电厂的UCF 混合样本,RF 模型能够有效地分类。

表4 RF 混淆矩阵分类结果
为了验证RF 的UCF 分类的能力,在训练集和测试集保持相同的前提下,应用Logistic 回归进行对比研究[21]。精度验证采用基于分类对象的混淆矩阵实现[22],计算得到了两模型分类的UCF 的总体精度、Kappa 系数、生产者精度和使用者精度,UCF分类精度表见表5 所示。

表5 UCF 分类精度
从表5 可以看出,RF 的总体精度为77.27%和Kappa 系数为0.705 3,符合Kappa 高度一致性检验标准(0.61 ~0.80)的区间。Logistic 回归的总体精度为51.14,Kappa 系数为0.110 1,Kappa 系数显示为极低的一致性。RF 的两类UCF 预测的生产者精度和使用者精度在(72.09%,82.22%)之间,分类的预测表现稳健,而Logistic 回归的预测的生产者精度和使用者精度在(13.95%,100%)之间,由此可见,具有学习能力和泛化能力的RF 模型在分类能力和准确性上明显强于传统的Logistic 回归,RF 相对于Logistic 回归有更好的分类结果。
5 结论
机组能力因子分类是WANO 业绩指标领域一个重要的研究方向,准确的分类对定性掌握我国核电机组发电状况及行业内机组所处状况有极其重要的意义。本文利用随机森林对我国1996 至2018年WANO 业绩指标中机组能力因子UCF 进行快速分类,通过调整随机森林模型决策树的棵树、内部节点再划分所需要的最小样本数,得到最优的随机森林分类模型,成功实现了对测试组的准确分类和区分。结果表明:(1)RF 算法相较Logistic 回归具有分类效果好、准确率高和性能稳定等优点,克服了基于均值对比的传统方法难以在高维数据中获得特征变量的不足,以及Logistic 回归处理高维数据的局限性,为准确挖掘特征变量提供了一种可靠和高效的方法;(2)通过分类效果评估解释变量的重要性,在发电、设备性能、燃料可靠性、化学、辐射防护和人员安全等特征中,反映集体辐照剂量、临界7 000 h 非计划自动停堆数、应急交流供电系统在UCF 分类的研究中极具应用价值,为UCF 等重要WANO 指标的深入研究提供了一种新的分析手段。
