面向高分辨率遥感影像车辆检测的深度学习模型综述及适应性研究
2022-12-24吕雅楠朱红孟健崔成玲宋其淇
吕雅楠, 朱红, 孟健, 崔成玲, 宋其淇
(1.防灾科技学院生态环境学院,廊坊 065201; 2.防灾科技学院地球科学学院,廊坊 065201;3.北京吉威空间信息股份有限公司,北京 100043)
0 引言
随着我国社会经济的快速发展,智慧城市建设已成为高科技发展的前沿领域,而智能交通建设是智慧城市信息化建设的关键。城镇化推动人口大规模地向城市地区聚拢,社会城市化进程不断加快,智慧出行成为当今各大城市所面临的热点问题。如何在“互联网+”时代基于遥感大数据实现全民智能出行,解决复杂多变的交通状况、交通普查以及交通安全是目前所面临的难点问题[1]。其中,车辆检测作为智能出行的基础与核心,在目标跟踪与事件检测等更高层次的视觉任务中具有重要的现实意义。遥感影像具有地面覆盖范围广、适合大范围车辆检测的优势,在智能出行道路车辆信息获取方面可以克服设备成本高、安装工作量大且安装复杂等缺陷[2-4]。然而,传统目标检测方法是基于滑动窗口搜索或特征提取算法,存在繁杂的计算成本及特征表征能力受限的问题。近年来,人工智能的快速发展掀起了深度学习研究的新浪潮,深度学习算法在图像处理领域取得了显著成果。利用深度卷积神经网络自主学习图像特征,在图像目标检测方面的效果明显优于传统方法。通过搭建深度学习网络模型,可充分挖掘图像数据间的特征与关联,利用学习到的参数,实现目标检测[5]。深度学习方法在自然场景检测方面已经取得重大突破,但直接迁移到遥感影像的小目标检测还存在许多问题,检测方法需进一步优化[6]。
目前,深度学习模型应用于复杂背景下大幅面遥感影像车辆目标检测仍存在以下亟待解决的难点问题: ①现有的深度学习方法多侧重于近景影像研究,而对遥感影像特征提取方面涉及相对较少,深度卷积神经网络图像特征提取与信息表达尚不清晰,不能有效利用遥感影像自身的先验信息,很难实现具有针对性的面向对象优化; ②目前所获取的遥感影像空间分辨率虽然较高,但以车辆为代表的小尺寸目标依然无法获取到信息量丰富的视觉特征,致使车辆等小尺寸目标检测精度受限; ③遥感影像下小尺寸目标特征不明显、密集车辆目标检测效果较差,难以对具有存在旋转角度的车辆目标进行准确检测。综上所述,现有深度卷积神经网络难以实现“一对一”的车辆目标检测,在遥感影像智慧出行中这一问题尤显突出。
本文主要面向高分辨率遥感影像车辆检测的深度学习模型进行综述并对其适应性开展研究,对目标检测领域的主流算法进行分类,阐述并分析现有深度学习模型应用于遥感影像车辆检测中的优缺点; 其次,基于公开数据集,利用主流深度学习模型对遥感影像进行训练,并评估其车辆检测性能; 最后,为大幅面、复杂背景环境的小目标车辆检测提供新的解决途径及发展方向。
1 基于遥感影像的双阶段目标检测算法
双阶段目标检测算法是在生成候选区域的基础上,对候选区域进行分类与回归,从而得到检测结果。目前,此类算法主要以区域卷积神经网络(region-based convolutional neural network, R-CNN)[7]系列为主,其特点是检测精度较高,但检测速度略显不足。R-CNN首次将卷积神经网络引入目标检测,结合选择性搜索算法生成候选区域,利用深度卷积神经网络进行特征提取[8-9],在PASCAL VOC2007数据集上的目标检测精度为58.5%。Girshick[10]针对R-CNN存在重复计算、检测速度慢的问题提出了Fast-RCNN算法,加入感兴趣区域池化模块,使图像输入尺寸不受限制,利用多任务损失函数统一目标分类和候选框回归任务,提高检测的速度。此后,Faster-RCNN利用区域生成网络代替Fast-RCNN中选择性搜索方法,使得候选框数目从原有的约2 000个减少为300个,提高了检测速度,实现了端到端的目标检测[11]。近几年,遥感领域基于双阶段目标检测算法也开展了系列研究工作,本文将遥感领域双阶段目标检测研究成果的优缺点及检测精度进行总结,如表1所示。总结发现,遥感影像目标检测仍存在目标过小、分布密集、角度多样化以及检测背景复杂4个难点问题,本文基于遥感影像双阶段车辆检测算法存在的难点问题开展了分析与讨论。
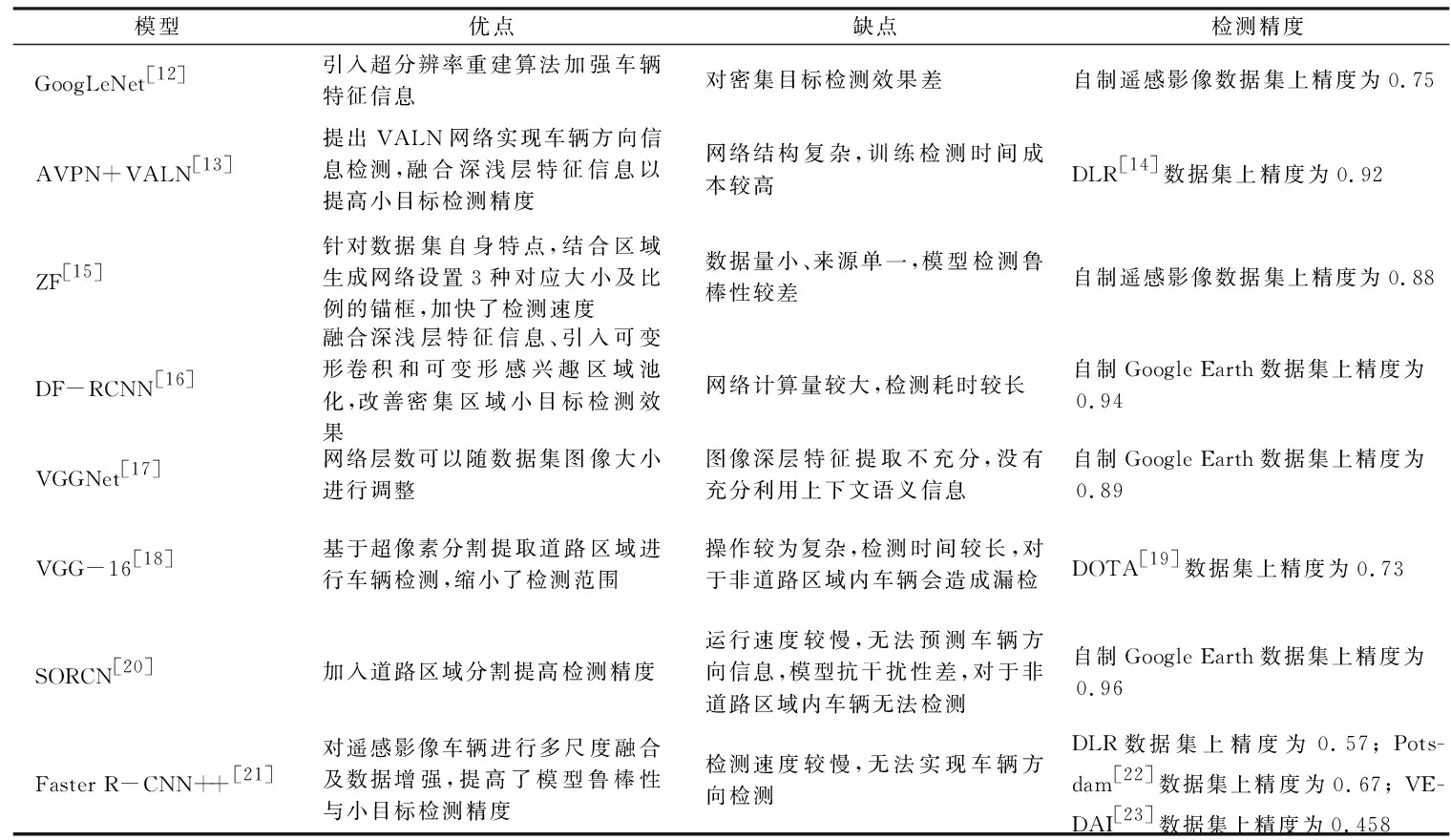
表1 双阶段遥感影像车辆目标检测对比Tab.1 Comparison of two-stage remote sensing image vehicle target detection
1)基于遥感影像的小目标检测。鉴于遥感影像中车辆目标尺寸较小,多次卷积将导致特征信息丢失严重,造成较大程度的漏检问题,其主要改进思路有: 区域预提取、优化锚框策略和改进网络结构等。对遥感影像进行道路区域预提取,再将道路区域输入卷积神经网络识别车辆目标,可提高车辆目标的检测率[18],该算法区域预提取阶段使用的是传统方法,道路区域提取的自动化能力不足,对非道路车辆信息无法进行检测。SORCN(small object reco-gnition convolutional network)[20]是一种基于分割[24]的小物体识别网络,该模型通过分割图像车辆目标,进一步提高小目标车辆检测效果。该方法可以减小待检测区域、提高车辆小目标检测精度,但流程较为复杂,需要牺牲检测速度提高检测精度。基于锚框的目标检测算法,锚框大小及比例选取直接影响待检测目标的召回率与检测精度。利用聚类分析方法计算出适合训练集的锚框尺寸,降低目标定位难度,提高小目标检测精度[15]。但该方法泛化能力较弱,难以应用于差异较大的数据集。关于网络结构的优化[17,25],顾及小目标特征信息丢失问题,主要通过减少网络下采样次数增加特征图尺寸,但会引入深层高级语义特征信息提取不足的问题。
2)基于遥感影像的多角度小目标检测。遥感影像具有多角度、多传感器、多分辨率的特点,车辆目标方向往往具有不确定性,直接使用水平方向检测框,使得较多非目标干扰信息介入而影响检测精度。针对多角度小目标检测问题,可通过旋转扩充增强[26-27]、引入旋转区域生成网络来改善多角度小目标检测效果。旋转扩充增强检测到的角度信息有限,利用特定旋转区域建议网络生成预选框,可实现对任意角度信息的预测。R3-Net[28]和R2PN[29]均是基于区域建议网络融合生成旋转候选区域,实现车辆角度信息预测,但网络计算量也相应增加。对于遥感影像目标角度问题,目前主要通过引入旋转区域生成网络来进行角度预测,该方法可缓解角度问题对检测精度的影响,但网络会变得更加复杂,增加了目标检测时间。
3)基于遥感影像的密集型小目标检测。遥感影像中密集型车辆检测难点主要在于车辆目标尺寸太小并且具有旋转角度,导致密集型目标存在漏检现象,现有方法多通过提高小目标检测精度、增加角度预测模块来减小密集目标所带来的检测影响。DF-RCNN(Deformable Faster-RCNN)模型[16]融合深浅层特征信息提高密集型小目标的检测效果。PVANet模型引入角度检测模块,减少预测结果间重合度,以减少对密集排列目标的漏检,该方法对密集目标的定位效果较好,但难以解决单个车辆目标提取的问题[30]。
4)基于复杂背景的遥感影像小目标检测。遥感影像自身具有覆盖范围广、地物类别复杂多样、成像受到云层等因素干扰的特点,给车辆精准识别带来了挑战。鉴于遥感影像复杂背景下小目标检测的难点问题,现有研究成果主要从引入区域预提取与注意力机制模块这2个方面来解决。对图像进行去雾、除云等预处理操作,可减少干扰信息影响,但此类预处理操作会降低影像分辨率。通过超分辨率重建算法可增强遥感影像特征[12],在不损失影像分辨率前提下提高检测精度。但该方法会加大网络复杂程度及计算量,难以满足实时性需求。基于注意力机制的特征融合可以减弱背景信息的干扰,改善复杂背景下小目标的检测效果[31]。由此可见,采用区域预提取以及注意力机制可以减小背景信息的干扰,但区域预提取时间成本较大,注意力机制将是未来解决复杂背景及噪声干扰问题的重要研究方向。
综上所述,目标固有尺寸过小是限制遥感影像车辆检测算法性能的首要因素,集中解决目标检测中存在的小尺度、多角度、密集型以及复杂背景干扰等因素是当前遥感影像车辆检测的首要任务,需综合考虑各个问题之间存在的内在关联性,借鉴解决不同问题的优化策略,以期达到最终提高检测性能的目标。
2 基于遥感影像的单阶段目标检测算法
单阶段目标检测无需生成候选区域,隶属于基于回归分析思想的检测算法。主流单阶段目标检测算法有YOLO(you only look once),SSD(single shot multibox detector)[32]以及无锚框目标检测系列,此类算法的特点是检测速度较快,但检测精度相对于双阶段目标检测略有不足。
YOLO系列作为单阶段目标检测的主流算法,2016年Redmon等[33]首次提出YOLO模型,将检测转化为回归问题,直接对目标进行定位和类别预测。在此基础上,YOLOv2引入锚框机制及特征尺度融合模块,改善了定位精度以及小目标检测能力的不足[34]。YOLOv3利用Darknet-53骨干网络增强特征提取能力,设计3种不同尺度网络预测目标,多尺度目标检测能力更强[35]。YOLOv4使用CSPDarknet作为特征提取网络,融合SPP-Net和PANet提高检测精度和速度,使检测器在单个GPU上也能很好地完成训练[36]。YOLOv5与YOLOv4结构相似,网络模型更加轻量,训练速度远超YOLOv4,兼顾速度的同时保证了准确性。
SSD模型应用多尺度特征进行目标检测,借鉴Faster R-CNN中锚框的理念,设置不同尺度与长宽比的锚框,相对于YOLOv1检测效果有明显提升[37]。在SSD的基础上,DSSD[38]算法改用ResNet101作为特征提取网络,利用反卷积传递深层特征,融合深浅层特征信息,从而提高了对小目标的检测效果。
无锚框目标检测算法通过检测中心点或关键角点进行目标边界框的预测,无需设定锚框。FCOS(fully convolutional one-stage object detection)[39]是一种无锚框的单阶段全卷积目标检测算法,对特征图进行像素级回归,直接预测目标中心点、边框距中心点的距离来检测目标。无锚框的目标检测算法具有更灵活的解空间,不需要调优与锚框相关的超参数,极大减少了算法计算量,训练过程内存占用更低。
相比于双阶段目标检测算法,单阶段目标检测的精度较低,但速度较快。本文将遥感领域现有单阶段目标检测研究成果进行归纳总结,如表2所示。基于遥感影像的单阶段车辆检测算法研究较少,总结过程中也参考了一些相关研究文献,包括飞机、船舰等,并对遥感影像下目标小、密集排列等问题的优化及解决思路进行了归纳总结。

表2 单阶段遥感影像车辆目标检测对比Tab.2 Comparison of one-stage remote sensing image vehicle target detection
1)基于遥感影像的小目标检测。单阶段目标检测算法主要从优化锚框策略、融合不同层级特征信息和增加网络检测头3个方面提高检测精度。其中,优化锚框策略可以提高对多尺度目标的检测能力,是当前常见的优化方法[40,44],但过于依赖先验设计,难以应用于其他类型数据。融合不同层级特征,可以兼顾浅层特征的纹理、边缘等细节信息,优化网络结构的同时使得输出特征图的尺度更适合小目标检测,改善小目标检测能力[41,45],但融合浅层特征的目标检测精度提升有限,在小而密集的目标场景中会存在较多漏检现象。在深度学习目标检测模型中增加网络检测头,如在YOLOv3网络增加大小为104像素×104像素检测头[42],用于检测小尺度目标,可以提高小目标检测性能,但该方法会增加网络复杂程度、训练及检测时间。
清晨,天还没亮,妈妈便轻轻地摇醒玛丽和劳拉。在炉火和烛光下,妈妈帮她们洗脸、梳头,穿上暖和的衣服。在红色的法兰绒长内衣外,妈妈为她们穿上羊毛衬裙、羊毛套裙和羊毛长袜,最后又帮她们穿上外套,戴上兔皮风帽和红色的毛线手套。
2)基于遥感影像的多角度小目标检测。单阶段目标检测主要通过引入角度因子与优化损失函数2个方面来解决目标存在的角度问题。在算法预设锚框中加入角度因子[43,46],可对车辆位置与角度信息同时预测,但加入角度参数会增加网络计算复杂度[47]。R-YOLO模型引入新的损失函数和旋转交并比计算方式,实现了舰船目标任意角度预测[48]。上述方法均引入了额外的计算模块,算法复杂度有所增加,在牺牲算法效率的基础上,提高了对多角度小目标的检测能力。
3)基于遥感影像的密集型小目标检测。现有的解决思路包括简化网络结构、增加角度预测分支与改进损失函数。简化特征网络提取更多浅层特征,利用残差网络代替连续卷积减少梯度消失,可提高小目标检测能力,从而减少密集型车辆的漏检数量[49]。该方法未消除目标方向多样所带来的干扰,存在较多重叠检测而导致的目标漏检。在网络中加入角度回归分支,引入非对称卷积增强目标旋转不变性特征,可缓解目标角度对检测精度的影响[50]。损失函数对密集目标定位效果有着重要影响,基于YOLOv5算法,利用CIOU_LOSS损失函数代替GIOU_LOSS损失函数,可减少密集区域的小目标漏检[51]。
4)基于复杂背景的遥感影像小目标检测。针对遥感影像背景复杂及噪声干扰问题,主要解决思路有影像预处理、融合多源影像信息以及添加注意力机制3种。影像预处理,如引入基于暗通道先验的大气校正方法,减少大气吸收和散射对遥感影像的影响,可减弱噪声干扰对检测造成的影响[52],但此类方法会影响影像自身信息量。融合可见光、合成孔径雷达遥感影像等多源图像信息,充分利用多源图像各自的成像优势,在复杂背景下能获得更好的检测效果[48]。以上方法可一定程度提高模型的抗干扰性,但相对比较耗时,且对多种复杂的噪声干扰敏感性较弱。在特征融合阶段引入注意力机制能使网络提取更多重要特征信息,充分挖掘小目标的上下文语义特征信息,抑制无关信息的干扰[45]。注意力机制与网络结合方式多样,合理选择融入方式,能有效降低背景信息对检测精度的影响。
由此可见,现有遥感影像车辆检测算法已取得了一定的进步,但仍有较大的提升空间,距离实际工程化应用还尚有距离,有待后续持续的深入研究。
3 实验结果及分析
为分析主流深度学习模型在遥感数据集的车辆检测效果,实验分别选取双阶段的Faster-RCNN,单阶段的SSD,FCOS和YOLOv5进行测试,其中FCOS为无锚框目标检测算法。另外,针对小尺度、密集型、多角度、复杂背景和动态区域5种不同场景进行车辆检测测试,分析不同算法在不同场景下的目标检测性能。
3.1 数据集及实验设置
实验采用DOTA和DIOR[53]这2个数据集进行测试。其中,DOTA数据集共有2 806张遥感影像和188 282个标注实例,图像大小在800像素×800像素到4 000像素×4 000像素之间,空间分辨率为0.1~4.5 m,包含车辆、飞机、储油罐和游泳池等15种标注类别,本文展示的5张影像数据空间分辨率为0.1~0.2 m。DIOR数据集共有23 463张遥感影像和190 288个标注实例,图像大小为800像素×800像素,空间分辨率为0.5~30 m,包含车辆、飞机、机场和棒球场等20种目标,鉴于原DIOR数据集未注明每张影像空间分辨率信息,因此未列出本文展示影像数据的空间分辨率信息。
本实验硬件设备配置: 操作系统为Ubuntu16.04,GPU型号为GeForce1080 Ti(11 G),CPU型号为Intel core i9-9900K。FCOS,Faster-RCNN,SSD和YOLOv5特征提取网络分别选用ResNet50-FPN,ResNet50,MobileNet和CSP-Darknet53。实验模型进行100次迭代训练,初始学习率设置为0.01,批处理大小设置为8,在进行至80次训练后学习率调整为原学习率的10%,进行至90次训练后学习率调整为原学习率的1%,其他参数与模型的官方代码参数设置保持一致。
3.2 评价指标
本文通过定性和定量2种评价方式对各算法进行综合评定,定量评价使用交并比(intersection over union,IOU)、准确率、召回率、平均准确率(average precision, AP)作为单类别目标检测效果的评价指标,其中平均准确率是评价模型精度的最常用的指标,它是准确率-召回率(precision-recall, P-R)曲线下所围成的面积,通常AP值越高,模型检测效果越好。4个指标的计算公式分别为:
(1)
(2)
(3)

(4)
3.3 实验结果分析
1)小尺度车辆目标检测。从表3可以看出,在DOTA和DIOR数据集上YOLOv5对于车辆检测均展现了相对较高的性能,漏检目标较少。YOLOv5算法加入自适应锚框模块,根据不同数据类型计算最佳锚框大小,使锚框更适合待检测目标。FCOS和SSD算法目标检测精度相对较差,其中SSD漏检目标较多。Faster-RCNN和SSD算法使用预设锚框,对于待检测目标尺度大小的自适应性较差,同时FCOS和SSD算法的特征图感受野相对较大,致使车辆细节特征提取不足,造成大量漏检。结合2个数据集检测结果进行对比,DIOR数据集的检测精度整体低于DOTA数据集,其原因是DIOR数据集车辆目标小于5个像素,更加考验深度学习模型对小目标的检测性能。

表3 小尺度车辆目标检测结果对比Tab.3 Comparison of small scale vehicle target detection results
2)密集型小尺度车辆目标检测。实验针对静态场景下小而密集型车辆目标进行深度学习模型性能测试,如表4所示,在2个公开数据集上,YOLOv5算法的目标检测精度相对较好,但对于具有旋转角度的车辆目标,检测结果间存在较多重叠区域,无法准确定位目标位置。对于密集目标检测结果而言,检测锚框大小与比例的设置尤为重要。Faster-RCNN锚框相对较大,导致一个检测框内存在多个目标,经过非极大值抑制处理后车辆目标被滤除而产生漏检现象。FCOS算法对图像进行像素级预测,通过中心点回归目标真实大小,但其浅层特征提取不充分,导致大量车辆漏检。SSD算法感受野相对较大,检测锚框自适应性较差,相对于其他算法,漏检率相对较高。

表4 密集型小尺度车辆目标检测结果对比Tab.4 Comparison of intensive small scale vehicle target detection results
3)多角度小尺度车辆目标检测。由于遥感影像自身特点,车辆目标往往会呈现出多角度排列的状态,从表5中可以看出,4种深度学习模型均可以检测到多角度排列的车辆目标。由于使用水平检测框,无法准确显示角度信息。在车辆密集排列时,目标预测框间会出现不同程度的重叠情况,难以准确地进行单目标提取。特别是在DIOR数据集中,车辆尺寸进一步缩小时,算法性能下降更加严重。可见在目标密集排列且存在角度时,相邻目标的检测框易出现重叠现象,待检测目标越小,其重叠程度越高,影响了车辆检测精度。

表5 多角度小尺度车辆目标检测结果对比Tab.5 Comparison of multi-angle small scale vehicle target detection results
4)复杂背景下小尺度车辆目标检测。实验针对静态场景下复杂背景的遥感影像进行车辆检测,结果如表6所示,YOLOv5的目标检测效果优于其他算法。YOLOv5加入Mosaic数据增强,通过图像扰动、添加噪声和随机缩放裁剪等方式,使算法模型在复杂背景下可以表现出相对较好的检测性能,但依然无法彻底消除噪声干扰。另外3种算法仅对数据进行旋转和缩放处理,模型抗噪能力不足,在出现阴影遮挡时会出现较多目标漏检。

表6 复杂背景下小尺度车辆目标检测结果对比Tab.6 Comparison of small scale vehicle target detection results under complex background
5)移动小尺度车辆目标检测。相对于以上4组静态场景下的车辆检测结果,实验开展了移动场景下车辆检测对比实验,结果如表7所示,依然是YOLOv5算法的检测效果最好,其次为Faster-RCNN,FCOS和SSD算法由于小目标检测性能较差,车辆目标漏检较多。主要源于YOLOv5算法融合深浅层特征,可获得丰富的全局与局部细节特征信息,对移动场景下的目标检测具有较好的自适应性。在移动车辆场景中,车辆目标分布较为稀疏,拍摄视野更加广阔,车辆小目标特性更加突出,极大考验小目标检测性能。

表7 移动小尺度车辆目标检测结果对比Tab.7 Comparison of moving small scale vehicle target detection results
本文将不同算法在公开数据集上的检测精度及训练时间进行了统计,如表8所示,YOLOv5算法的检测精度最高,在DOTA和DIOR数据集的检测精度分别为0.695和0.566,SSD算法检测精度相对较低,分别为0.251和0.154。主要原因是车辆目标尺度过小且相对密集,该算法对于小尺度目标检测能力相对较差。4种算法中SSD算法训练时间最短,在DOTA和DIOR数据集上分别为31.245 h和21.135 h,Faster-RCNN算法训练时间最长,分别为96.617 h和129.617 h,可见单阶段目标检测训练速度优于双阶段目标检测算法。
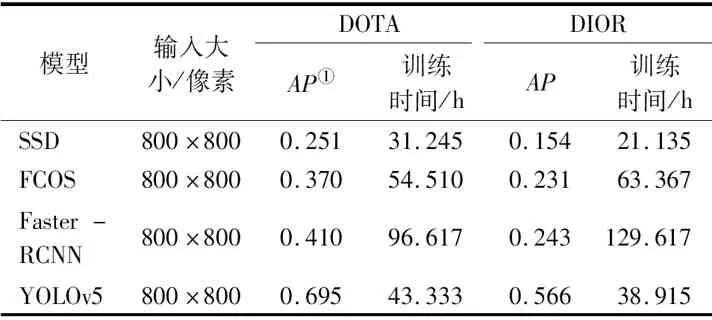
表8 不同算法在公开数据集的检测结果对比Tab.8 Comparison of detection results of different algorithms in public data sets
综上所述,YOLOv5在DOTA和DIOR数据集的检测效果优于Faster-RCNN,FCOS和SSD算法。主要原因在于: ①YOLOv5中加入了自适应锚框计算模块,可自动计算最佳锚框类型,提高算法的检测精度和召回率; ②YOLOv5融合不同层级特征,特征信息利用更加充分; ③YOLOv5引入了Mosaic数据增强,对图像进行随机缩放、随机裁剪和随机排布等处理,有效提高算法的抗干扰能力。YOLOv5算法检测速度快,适用于实时性要求较高的场景,但应用于遥感影像车辆检测领域还需要进一步优化,如在遥感影像车辆小而密集的场景下,可能会存在大量小目标车辆漏检,需根据遥感影像车辆目标特点优化网络结构; YOLOv5算法不具备角度信息检测能力,在车辆密集分布且存在一定角度时,会较大程度地影响其检测精度。
3.4 不同数据、模型适应性分析
1)对不同数据的适应性。从实验结果可知,目标检测算法对于DOTA数据集的检测精度高于DIOR数据集。进一步说明,目标检测算法性能不仅在于模型自身网络结构,也会受数据集大小和内容的影响。DOTA数据集中的车辆目标数量以及类型相对较多,数据样本较为丰富,所以训练出的模型的鲁棒性更强。因此,高质量、大规模的数据集可以有效提升遥感影像车辆检测效果。
2)对不同模型的适应性。Faster-RCNN与单阶段目标检测算法不同之处是检测目标时生成候选区域,再对候选区域进行多次分类与位置修正,相对于FCOS和SSD算法检测速度较慢,但精度较高。然而,Faster-RCNN锚框类型不适用于小尺度目标,当遥感影像中的车辆目标尺寸更小时,检测效果并不理想。SSD算法对不同层级选用不同尺寸与比例的锚框,整体精度相对较高,但对小尺度目标检测能力较差,主要原因是特征层非线性化程度不够,模型精度受限。YOLOv5加入自适应锚框计算与特征融合模块,特征提取能力相对更强,检测性能相对更好,但对于极小尺度的车辆目标,也会出现漏检现象。FCOS算法无须进行与锚框相关的复杂运算,是一种轻量的检测模型,直接进行逐像素点的回归预测,避免了正负样本不平衡的问题,但其特征图感受野相对较大,难以检测到小尺度车辆目标。
综上所述,对于高精度的车辆检测任务,宜优先使用双阶段的目标检测算法,对于实时性要求高的车辆检测任务,应优先选择单阶段的目标检测算法。现阶段的目标检测算法直接应用于遥感影像车辆检测还难以取得较为理想的效果,网络结构仍有待针对性的改进。
4 总结及展望
本文针对主流目标检测模型进行综述,通过DOTA和DIOR这2种数据集进行实验对比,分析不同场景下遥感影像车辆检测效果。对于静态场景而言,车辆排列密集、角度多样,检测结果容易出现预测框重叠现象。而对于动态场景而言,车辆分布相对稀疏,目标角度对于检测结果的影响较小。目前深度学习技术在遥感影像车辆检测任务中已取得了一些成果,但仍存在许多亟待解决的问题,目标过小、分布密集、角度多样以及背景复杂问题是制约遥感影像车辆检测性能的主要因素。因此,针对现存难点问题进行不断优化,是未来遥感影像车辆检测的研究重点,其发展趋势主要涉及以下几点:
1)加强弱监督学习与无监督学习研究。面向遥感影像大数据驱动下的深度学习算法应用中,数据量大,标注耗时长、成本高是数据处理现存的显在问题。如何在弱监督或无监督学习下通过少量标注样本及大量未标注数据进行学习,改善遥感影像标注数据量不足的缺陷,是后续研究亟待解决的问题之一。
2)结合自适应特征尺度融合与注意力机制。鉴于图像高低层特征信息的融合仅将不同分辨率的特征对齐相加,忽略了各特征层之间的关联信息。引入自适应特征融合机制,不同层级特征分配自适应权重参数,实现局部特征和全局特征的高效融合,以期提升车辆小目标检测性能; 或者引入注意力机制模块,筛选图像的关键信息,以减少干扰信息对目标检测的影响,进一步提升小目标检测精度。
3)探索无锚框的目标检测算法。现有研究成果大多是基于锚框进行目标检测,此类算法训练耗时长、运算量大。而无锚框的目标检测算法无须进行大量锚框参数相关的运算,其检测速度更具优势,深入研究将在遥感卫星军事监测及智能交通等领域发挥重要作用。
