一种基于网络评论小样本数据的群体情绪量化方法
2022-12-23龚莉萍刘汉涛李文藻
王,龚莉萍,刘汉涛,李文藻,3
(1.四川省教育信息化与大数据中心,四川 成都 610000;2.成都体育学院,四川 成都 610000;3.成都信息工程大学,四川 成都 610000)
0 引 言
在新一代通信技术的高速发展下,评论参与、评论转发或者信息报道更加简便[1]。而在网络购物已经成为生活常态的今天,用户对于商品的感受评论以及改进建议对商品发展具有强大的推动作用,甚至决定着商品的研发方向。商家从大量褒贬不一、非结构化的评论中准确获知用户群体对商品的态度和意见,对产品改进及经营决策至关重要。特别是在用户追求商品质量的相关领域,比如更新换代快的智能产品领域,网络评论关注群体多、用户参与感强、媒体关注度高等特征明显。这些特征会使网络评论的用户群体情绪认同感强,事后处理成本高,扩散和影响持续周期长,商品的研发或者经营可能遭受损失。
目前,国内外学者对用户群体评论情绪的分析主要通过机器学习[2]、情感词提取[3]等方法,围绕用户体验感知、用户情感等视角展开多范畴研究。虽然出现了基于人工智能等方式的网络评论群体情绪监测分析技术[4],但基于神经网络的网络评论群体情绪分析存在两方面的挑战,首先,由于语义理解的偏差,对评论中的信息理解感知结果相对较差;其次,采用基于神经网络的方式时需要大量商品评论数据作为神经网络的训练样本。而通过情感词提取的方法识别群体情绪时,情感分析的结果好坏对情感词的构建是否完善依赖程度高。
基于以上研究方式的一些不足之处,笔者提出了一种基于网络评论小样本数据的群体情绪量化方法,通过k-means聚类算法对数据进行分类。该方法在网络评论群体情绪出现初期,仅有少量样本数据的条件下,对网络评论的群体情绪进行识别分析。k-means聚类算法因为其较好的稳定性和聚类效果,也被广泛用于文本挖掘[5]、风险评估[6]等各项研究,也有学者将之用于基于文本挖掘的网络评论情绪分类研究[7]。
1 评论量化模型与评论群体情绪分析算法
网络商品评论的生态环境具有复杂性特征,网民的评论数据往往也包含如时间维度、情感及关注程度等方面的信息。聚类分析是群体情绪分析中获取群体情绪特征的主要手段。通过聚类后的结果分析我们可以发现一些潜在的隐性知识[5],客观揭示了研究对象间的相似程度,从而发现隐含的客观规律[6]。传统的文本建模方法是基于词空间的建模方法,一方面,这种建模方法语义识别困难,存在一词多义(多义词)和多词一义(同义词)的问题;另一方面,随着语料库规模的增加,基于词空间的建模方法会面临维数过高、数据稀疏等问题[7]。此外,各种商品评论本身一般含有较多的专业名词,进行对比分析存在一定难度。因此,笔者决定采用客观的评论字数及带有明显情绪的标点符号(如“!”“?”等)作为评论的特征数据,构建网络评论群体情绪分析算法,既规避语义识别、语料库规模增加的问题,同时又促进评论的群体情绪自动化定位。在提出的算法中,表情符号和标点符号都属于情绪因子:在网络交流过程中,表情符号非常流行,它以简单图形或彩色图像甚至动画等表情达意,通俗易懂,与语言中的体态语相类似,形成了一种显式的、固定的情绪表达方式;标点符号在网络评论群体情绪分析中同样起到关键作用,标点符号的使用会导致评论表达情绪出现差别,也是理解和判断网络评论表达情绪的重要手段[8]。基于网络评论小样本数据的群体情绪量化流程如图1所示。

图1 基于网络评论小样本数据的群体情绪量化流程
针对商品对象网络评论群体情绪的量化分为数据预处理与评论群体情绪量化算法两部分。第一阶段为数据预处理阶段,该阶段需要通过一种量化模型,对所有的评论数据进行客观量化处理。本模型选择评论字数因子γ,情绪ε作为评论数据的特征因子[9]。
在评论数据样本集ϑ中,对γ进行归一化处理。这里采取最小-最大规范化实现线性变换,使得γ∈(0,1]。

式中:γi为评论数据i的字数;max(γϑ)为取样评论数据集中的数据最大值。通过公式(1)可以将评论数据的字数信息量化映射至对应区间。
情绪因子ε因为样本数量不多,采取人工辨别的方式对评论表现的情绪进行判定。如“!”在负面评论中常用于突出强调不满情绪;而“?”表示疑问语气,常用于质疑和怀疑;按照网络评论常用的消极表情(如“[泪]”“[怒]”“[弱]”等),以及情绪标点符号(如“!”“?”等),将评论表达的情绪分为平缓、较激烈、激烈。情绪判定标准为:小于2个消极表情和情绪标点符号的评论判定为平缓;包含2个消极表情和情绪标点符号的评论判定为较激烈;大于2个消极表情和情绪标点符号的评论判定为激烈。我们经过多次实验及分析推论,将平缓定为0.2(2个以下标点符号),较激烈定为0.5(2个标点符号),激烈定为0.8(3个及以上标点符号)。
在通过评论字数因子γ,情绪因子ε的量化后,为每条评论附加了2个维度的特征向量。在特征向量的基础上,每条评论能够在二维笛卡尔坐标中表达具体的位置。依据以上量化方法,每条评论的数据将会出现在坐标系中的第一象限。由于评论在一定程度上反映了商品的关注度以及用户的使用感受,容易在量化后出现聚集特征[10-11]。因此,第二阶段中,采用k-means聚类算法对以上量化数据进行聚类分析时,有利于统计样本数据中商品受关注程度及用户群体对商品的感受程度。基于评论数据量化后的k-means聚类算法处理流程如下:
基于评论数据量化后的k-means聚类算法
(1)随机选取k个点为初始聚集簇心(样本点选择);
(2)分别计算每个样本点到k个簇心的距离(D);
(3)选择每个点至簇心的最短距离mix(D),归属该簇;
(4)计算每簇的质心(平均距离中心),以作为新分簇的簇心;
(5)迭代步骤(2)~(5),在ω次后退出循环。
通过k-means算法处理后,坐标系中量化后的评论数据将会归属于不同的簇分类。通过聚类算法,我们基本将评论的小样本数据进行了相应分类,使评论数据实现聚焦的功能。由于算法特征较好,该类无监督学习方法也可用于行为画像等领域。
2 实验结果与分析
基于以上方法,本文选择取样了近期“****小米手机”商品的评论,进行相应实验及讨论分析。我们随机选取近期新品发布后短时段内用户的消极评论50条数据,进行以上算法处理,具体见表1所列。

表1 “****马拉松事故”网友评论抽样事例
其中,k-means聚类算法中k值选择为2与3,ω取值1 000,其结果如图2、图3所示。

图2 k=2时评论数据分类
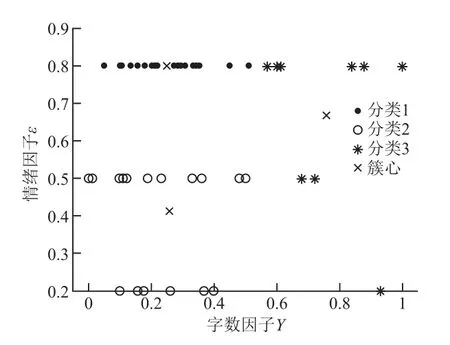
图3 k=3时评论数据分类
通过算法结果图2、图3可以看到,评论数据量化后均分布于坐标系第一象限。我们对量化后评论数据进行聚类处理,算法很好地将数据进行了分簇。针对图2中的结果,可以观察到分类2靠近(0,0)点,分析数据后得出分类1数据占比为56%,分类2数据占比为44%。图3中k值为3的情况下,分类1占比为26%,分类2占比为38%,分类3占比为36%。基于评论数据的量化方式,我们依据字数因子γ、情绪ε可知,一定程度上特征因子的值越大,网络评论群体情绪扩散的可能性也越大。所以分簇占比中比例靠近(1,1)点的比例,一定程度上能够反映网络评论群体情绪扩散的可能性。同时我们观察到:在实际应用中,簇心K=3相比于K=2时,评论种类划分更细,但是不一定有利于数据分析。在目前取样的数据集中,超过半数的评论数据分簇后划分在靠近(1,1)点,所以聚类比例可以作为商品网络评论中用户群体不满情绪较大的分析依据。
3 结 语
本文提出了一种网络评论群体情绪量化模型与采用k-means聚类算法对量化后的网络评论数据进行聚类的方法。该方法在基于网络评论小样本数据的基础上进行了完整的实验,为后期网络评论群体情绪分析中的机器学习提出了一种新的网络评论群体情绪量化前置处理方法。量化后的评论数据随着分簇数量动态变化,可以实时监测评论群体的情绪程度,帮助商家做出相应的经营决策,帮助买家了解商品。而对情绪的具体分类比例阈值的确定,本文中没有详细研究,这将是未来研究工作中的重点。
