基于混合神经网络模型的企业行业分类
2022-12-23陈钢
陈钢
(长三角信息智能创新研究院,安徽芜湖 241000)
我国目前已有数千万家企业,并且每年都有大量新企业设立。市场监督管理部门在企业注册时都会强制要求其注明经营范围,但是从分散的经营范围中并不能直观地得出该企业的行业归属[1]。除了上市公司会在网上公开自己的行业类别以外,其他大部分企业的行业类别都是未公开的。企业所属行业由其经营范围描述而得,经营范围描述往往涉及到多个行业的描述,在现如今庞大的行业规模下人工进行行业分类存在效率低下、准确性不高等问题[2]。
行业分类自动化的一般过程是从企业的经营范围文本中提取特征,然后使用分类器完成预测。企业经营范围文本需要向量化后才能作为分类模型的标准输入。Word2vec、glove 等词向量模型可以通过将自然语言中的词转换为稠密的词向量嵌入到神经网络模型中,从而使神经网络模型可以获取更多、更精确的语义信息,以提升分类的准确率[3]。然而这类模型无法关注到上下文的关联信息,在出现存在歧义的特征词时可能无法正确表征,而包含大量先验知识的预训练语言模型可以有效解决这类问题[4]。门控循环单元(Gate Recurrent Unit,GRU)适合对文本建模、获取文本全局的结构信息[5]。注意力机制(Attention)可以为经营范围中重要的词赋予更高的权重,进而更好提取关键信息[6]。基于此,提出一种基于混合神经网络模型的企业行业分类方法,融合RoBERTa 预训练语言模型、GRU 网络和注意力机制构建候选集生成网络和外部知识嵌入网络。
1 相关研究
为解决企业行业分类问题,通常会借助自然语言处理和机器学习的手段对经营范围进行数据挖掘,从而自动完成行业分类。主流分类方法分有两种:基于机器学习的方法和基于深度学习的方法。基于机器学习的方法首先人工提取特征,然后将多个特征串联起来组成一个高维度的特征向量,之后便可以使用传统的机器学习的各种分类器,如朴素贝叶斯[7]、支持向量机、决策树等完成行业分类。这种方法需要做大量的特征工程,特征的选取和分析方式复杂,需要耗费较多的成本,并且这些特征都是针对常规文本分类问题提出的,不存在对具体问题的依赖,这就会造成前端特征与后端任务的脱节,导致前端花费大量精力构思出来的特征可能根本与指定的任务不相关。另一种是基于深度学习的方法,如卷积神经网络(Convolutional Neural Networks,CNN)[8]、循环神经网络(Recurrent Neural Network,RNN)[9]、基于长短期记忆的循环神经网络(Long Short Term Memory,LSTM)[10]完成自动的特征提取和分类任务。相比行业门类,属于不同行业小类的企业在经营范围描述上存在很多相似性,利用常规方法很难发现这种微小的差异,进而较难作出正确的判断。
使用深度学习方法虽然免去了一些人工特征提取的工作,但是由于经营范围的描述信息通常很分散,包含了多个行业的内容,单从经营范围无法确定哪些信息对判断行业类别是有效的。为克服上述行业分类方法的缺陷,提出一种基于混合神经网络的行业分类模型,首先将企业经营范围文本序列输入RoBERTa 预训练语言模型,并将输出的特征向量作为输入到下一层网络的语义表征向量;通过引入企业外部知识,结合双向门限循环神经网络(BiGRU)和注意力机制的外部知识嵌入网络,有效提高模型的理解层次,提升行业分类的准确性。同时,提出一种基于GRU 的候选集生成网络,通过GRU 生成分类候选集用于增强算法的分类能力,在此基础上引入跳层连接机制,以解决深度网络训练中的信息丢失和网络退化问题。
2 模型结构
行业分类模型主要由三个部分组成,如图1 所示。语义表征部分使用RoBERTa 模型作为基本模型,该模型相对BERT 模型进行了多项改进。为了使RoBERTa 模型适用于中文环境下的企业行业预测,使用RoBERTa-wwm-ext 作为文本特征提取模型,并将企业经营范围文本序列输入其中[11]。处理后的文本表征向量被送入到候选集生成网络,产生包含类别候选集的特征向量,外部知识作为补充信息,在使用BiGRU 向量化后与特征向量进行拼接,得到融合的特征向量,融合后的特征向量最终输入到分类器进行类别预测,以实现行业类别预测。

图1 模型结构
2.1 候选集生成网络
候选集是一种对企业行业类别可能判断的候选选项的集合,模型使用GRU 网络作为候选集的生成网络。GRU 使用门机制跟踪序列状态,重置门和更新门共同控制当前状态要更新的信息量。基于GRU的候选集生成网络结构如图2 所示。

图2 候选集生成网络结构
经过预训练模型编码后的语义向量结果xt构成集 合X={xt|t=1,2,…,n},将X与类别语义信息Cs={|i=1,2,…,m}作为模块的输入。更新门zt、重置门rt均由输入向量xt与上一步隐藏状态ht-1线性组合并经过sigmod 激活函数非线性化处理后得到。候选状态的计算方式与传统的RNN 类似,由重置门rt与隐藏状态ht-1的哈达玛积和输入向量xt线性组合后,经过tanh 激活函数非线性化处理得到。新的隐藏状态ht由更新门zt、隐藏状态ht-1和候选状态共同计算得到:

将不同时间节点隐藏状态ht构成集合H={ht|t=1,2,…,n,n+1,…,n+m},经由全连接层以及softmax 函数后得到候选集C={ci|i=1,2,…,m}。对候选集使用全连接层进行维度转换,输出与预训练语言模型同维度的结果VC={|t=1,2,…,n}。为了防止训练过程中网络层数加深后可能存在的信息丢失和网络退化问题,在候选集生成网络中添加跳层连接[12],其主要过程是通过将网络的输入部分与输出结果使用门控机制进行相加,得到最终网络输出结果Vout:

其中,f(X)是主干网络,它是由多个网络层组成的非线性变换得到的。
2.2 外部知识嵌入网络
完成候选集生成后,构建了基于企业描述信息的Query-Tag 预测模型。除了经营范围描述外,企业也包含大量其他存在相关性的标签,单纯利用某一类标签可能存在难以理解某些模糊描述的情况,理解层次偏低。通过引入企业外部知识,可以有效提高模型的理解层次,提升行业分类准确性。因此,将企业其他信息作为外部知识信息引入分类模型,以键值对形式构建出结构化外部知识。输入到模型中的结构化知识库表示为一个键值对列表:

其中,si表示企业信息对应类型(例如企业名称、注册资本),vi表示对应企业信息的具体内容(例如安徽某有限公司、100 万元人民币)。
在单向神经网络结构中,状态是从前向后输出的,难以抓取整个知识库中的上下文信息。然而在文本分类中,当前时刻的输出可能与前一时刻的状态和后一时刻的状态都存在相关性。因此,使用BiGRU 网络作为信息提取网络,为输出层提供输入序列中每一个点的完整上下文信息。注意力机制能选择性地对这些外部信息进行筛选并聚焦到有效信息上,因此在分类模型中还引入注意力机制来增强补充外部知识后的预测效果。外部知识嵌入网络主要包括结构化知识库(Structured KB)、BiGRU 网络和Attention 机制,外部知识嵌入网络如图3 所示。

图3 外部知识嵌入网络
将L经过Embedding 得到向量L=[I1,I2,…,In]。向量L中的元素Ii分别输入前向GRU 和反向GRU,得到前向隐藏状态和反向隐藏状态,拼接前向和反向隐藏状态得到BiGRU 的隐藏状态对BiGRU 的隐藏状态hi应用注意力机制,并引入知识库上下文向量u来衡量知识的重要性,从而得到有助于增强行业分类的外部知识向量V。最后,通过全连接网络将外部知识向量V的维度转换为与主干网络相同维度的结果向量。
2.3 预测网络

使用正确类别的负对数似然作为训练的损失函数:

其中,j是企业E的分类类别。
3 实验结果分析
3.1 实验环境
使用基于CUDA 9.0 的深度学习框架PyTorch 1.1.0 搭建网络模型,实验操作系统为Ubuntu 18.04,内存32 GB,Intel(R)Core(TM)i7-7700CPU@3.60GHz,GeForce GTX 1080 Ti GPU。
3.2 数据集
为评估行业分类模型的有效性,构建了由企业数据组成的数据集。数据集中的信息包括企业名称、注册资本、成立时间、经营范围、行业类别、行政许可、产品信息等。数据集中有60 000 条数据,随机选取了其中50 000 条数据作为训练集,5 000 条数据作为验证集,5 000 条数据作为测试集。
3.3 实验设置
在超参数设置上,RoBERTa 模型的嵌入维度为768维,多头注意力机制的设置为12 个注意力头,隐藏层维度同样设置为768维,隐藏层层数设置为12,词汇表大小为21 128字,GRU 的隐藏层维度设置为128。在训练设置上,批处理大小设置为16,批处理以token 为单位,每个输入文本的token 个数设置为200。同时,模型使用学习率为1e-5 的Adam 优化器。训练轮数设置为10 轮(epoch=10),并且使用学习率优化策略,每两个epoch 学习率下降为原来的80%。为了更好地说明模型的分类性能,采用准确率(acc)和F1 值作为评价指标。
3.4 基线模型对比
在数据集上与多种基线分类方法进行了对比,对比结果如表1 所示。

表1 对比实验结果
1)机器学习方法
使用TF-IDF 和N-grams 作为特征提取方法,分别以机器学习方法MultinomialNB、SGD 和SVM 作为分类器对特征进行分类。
2)深度学习方法
TextCNN[13]:使用卷积核窗口大小分别为2、3、4的三个卷积层和相应的池化层提取特征并进行拼接,以此来获得更丰富、不同粒度的特征信息。
TextRNN[14]:使用经过词嵌入之后的词向量作为输入,经过RNN 网络和池化层进行分类。
HAN[15]:使用基于单词层面注意力机制的BiGRU模型和基于句子层面注意力机制的BiGRU 模型提取文本多层面的特征进行文本分类。
XLNet-linear:采用预训练语言模型XLNet模型[16]提取特征,并使用linear 分类器进行行业分类。
RoBERTa-linear:采用预训练语言模型RoBERTa模型提取特征,并使用linear 分类器进行行业分类。
可以看出,RoBERTa-GRU-EKB 模型在两个数据集上均取得了比其他基线模型更好的分类效果。在RoBERTa 的基础上增加候选集生成网络和外部知识嵌入网络,能够有效提升行业分类性能。
3.5 消融实验
为说明候选集生成网络和外部知识嵌入网络的有效性,定量地比较了是否使用候选集生成网络和外部知识嵌入网络的实验结果。将未使用候选集生成网络的结果命名为RoBERTa-EKB,将未使用外部知识嵌入网络的结果命名为RoBERTa-GRU,对比结果如表2 所示。

表2 消融实验结果
由表2 可见,RoBERTa-GRU-EKB 模型在两个数据集上的分类效果总是优于RoBERTa-EKB 模型和RoBERTa-GRU 模型。图4 展示了候选集生成网络消融实验性能对比。图4(a)中曲线②几乎总是在曲线①之下,曲线④几乎总是在曲线③之下;图4(b)中曲线②几乎总是在曲线①上方,曲线④几乎总是在曲线③上方,这表明模型加入了候选集生成网络后,其损失值和准确率均优于未加入候选集生成网络的模型。因此,基于GRU 的候选集生成网络可以有效提升分类准确率。
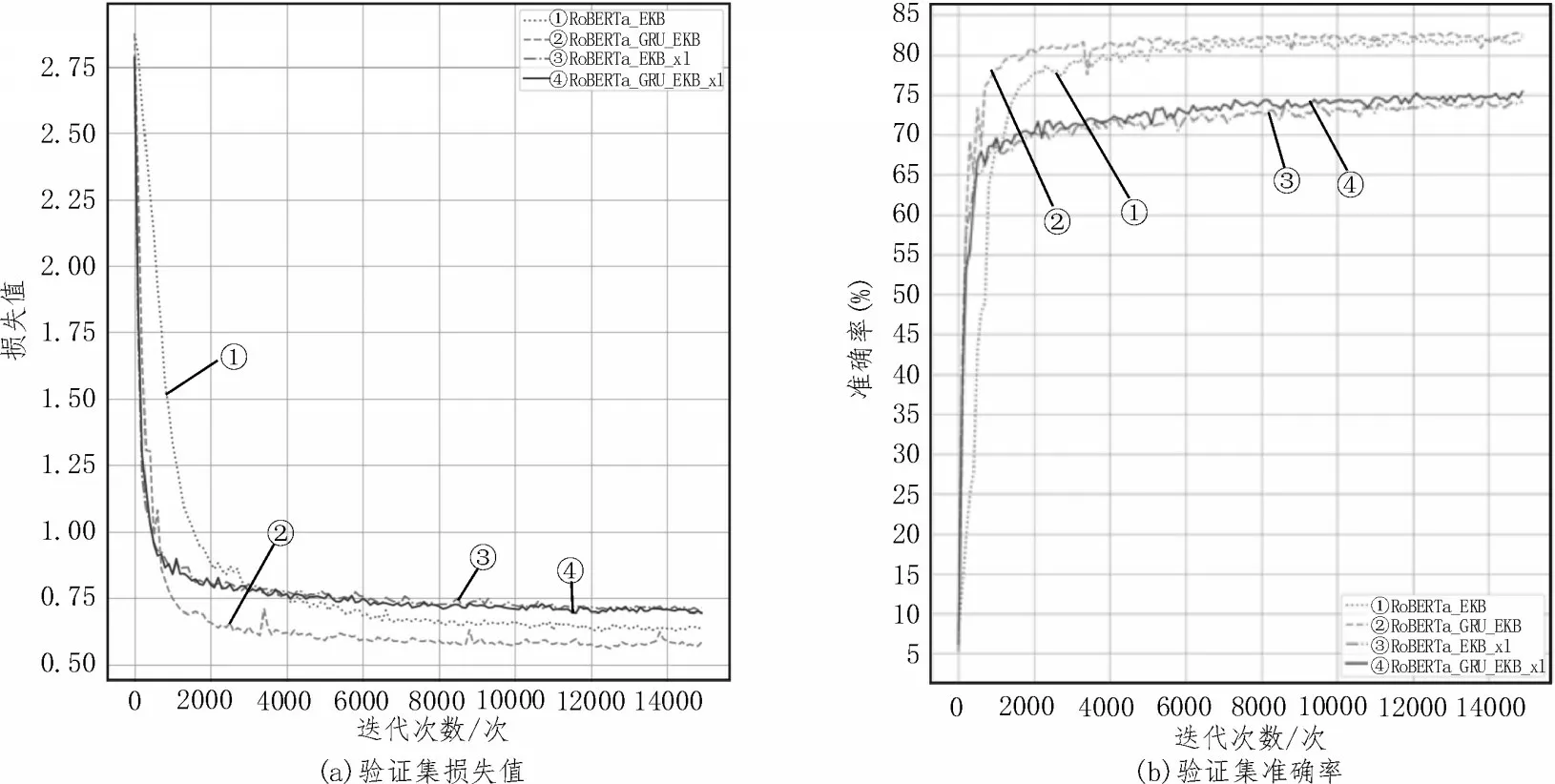
图4 候选集生成网络消融实验性能对比
图5 展示了候选集生成网络消融实验性能对比。图5(a)中曲线②几乎总是在曲线①之下,曲线④总是在曲线③之下;图5(b)中曲线②几乎总是在曲线①上方,曲线④总是在曲线③上方,这表明模型加入了外部知识嵌入网络后,其损失值和准确率均优于未加入外部知识嵌入网络的模型。因此,外部知识嵌入网络可以有效提升分类效果。

图5 外部知识嵌入网络消融实验性能对比
3.6 混淆矩阵和类别准确率
为更加直观有效地展示行业分类效果,在实验部分给出了RoBERTa-GRU-EKB 模型测试结果的混淆矩阵热力图,如图6 所示,图6 中给出了部分类别预测准确率各模型对比直方图(其中A、B、C 等代表某个特定行业类别),图中方格颜色深浅表示预测率大小,从图6 可知对角线上的方格颜色较深,这表明RoBERTa-GRU-EKB 模型在每个类别上的分类性能均较好。

图6 混淆矩阵热力图
4 结论
该文提出了一种用于企业行业分类的混合神经网络模型,该模型采用RoBERTa 预训练语言模型提取企业经营范围的文本特征,使用候选集生成网络与跳层连接模块增强分类性能。此外,还利用BiGRU 与注意力机制实现了结构化的知识库嵌入,通过引入企业外部知识金额提升行业类别预测准确性。实验结果表明,该文提出的行业分类模型相较于其他几种基线模型都取得了最好的分类效果。
