基于Vision Transformer的光伏组件红外图像故障检测
2022-12-21张晓艳周丙涛刘洪笑段亚穷
张晓艳,向 勉,朱 黎,周丙涛,刘洪笑,段亚穷
(湖北民族大学智能科学与工程学院,湖北 恩施 445000)
太阳能作为一种清洁能源,比化石能源使用得更广泛[1]。光伏产业经过快速发展,装机容量一直在持续增长,已经成为我国可以参与国际竞争的新兴产业[2]。由于光伏组件长时间在室外进行工作,容易受到风雨的侵蚀,火灾的发生,沙土的覆盖,以及人影树影的遮挡等影响,无法避免出现一些故障[3]。这些故障如果没有被及时检测到,所产生的损失无法估量,对光伏产业的发展不利。因此,采用有效方法检测光伏故障并对其进行分类是十分有必要的。
本文设计的基于Vision Transformer 的光伏异常红外图像检测的方法,通过把原图划分成多个块(patch)展平成序列,然后将其输入进原始Transformer 模型的编码器Encoder 部分,最后接入一个全连接层,从而实现图片故障类型的分类。该方法对光伏组件故障类型进行8 种分类,包括电池故障、泵组故障、二极管故障、多级激光二极管故障、热点故障、多热点故障、脱机方式故障、遮蔽故障。其中数据集经增强后图片数量多达4 万多张,能够更好地训练模型,并且明显地提高了其检测的准确率。
1 基于Vision Transformer的故障检测模型
1.1 Vision Transformer模型的整体框架
Vision Transformer 整体可以分为3个部分,分别是:Linear Projection of Flattened Patches(Embedding层)、Transformer Encoder(Transformer Encoder编码器)、MLP Head(延时头),其中Transformer Encoder、Patches Position Embedding 层属于特征提取的部分,主要的作用是平均分块处理输入的图片,在划分图片块时是按照固定的区域大小进行划分的,再将这些已经划分好的图片块组合成序列,这一系列操作完成后,将其传入到Transformer Encoder 区域内进行特征提取,利用自注意力机制,从而检测每个图片块的重要程度。MLP Head 属于分类部分,在分类区Vision Transformer 的工作是利用特征提取区域所提取的特征进行分类,在序列中添加了一个额外的可学习的classification token,和其他所提取的特征进行特征交互,融合其他图片序列的特征,最后再进行全连接分类。Vision Transformer 模型的整体框架如图1所示。
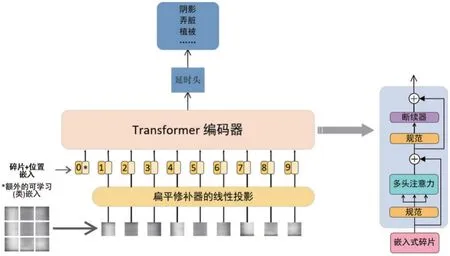
图1 Vision Tranformer的整体框架
1.2 Vision Transformer模型的Embedding层
本文所采用的模型是Vision Transformer_basepatch16,此模型的每个模块数据的形状是[16,16,3],通过映射得到一个向量,这个向量也就是卷积核个数token,其中token的长度是768。由图2可知,将一张光伏组件的图片按固定大小分成很多小的模块,把输入图片(224×224)按照卷积核16×16大小的模块进行划分,从而得到196个小模块。然后就是把这个特征层组合成为序列,模型以非常简单的方式进行组合,具体方式是用高宽维度来进行平铺,[14,14,768]在高宽维度平铺后,得到一个[196,768]的特征层。实验是直接通过一个卷积层来实现的。通过卷积[224,224,3]→[14,14,768],进而把H和W两个维度展开铺平,[14,14,768]→[196,768],这个时候刚好变成了一个二维矩阵,这个二维矩阵适用于Vision Transformer 模型。最后,在输入到Transformer Encoder 之前,已经得到了具有图片信息、位置信息以及分类信息的特征。
1.3 Vision Transformer模型的Encoder层
在经过Embedding 层时得到shapeEmbedding 层是[197,768]之后,模型再把序列信息传到Transformer Encoder 中进行特征提取,这是Transformer模型不同于其他模型的Multi-head Self-attention 结构,利用自注意力机制,可以计算输入图片特征各部分的不同重要程度,也就是图片各个部分的特征,所以在经过Encoder 层之后除了卷积本身得到的一些特征,其中还包含一些Attention 的信息。其中使用缩放点积注意力机制的公式计算相似度,计算公式如式(1):
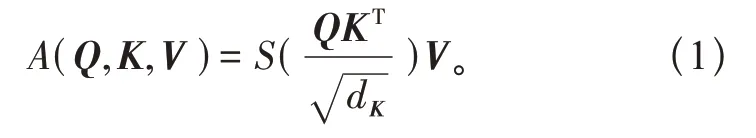
式中:A为注意力机制(Attention);S为softmax 函数;Q为一组Query 集合组成的矩阵(查询);K为一组Key 集合组成的矩阵(索引);V为一组Value集合组成的矩阵(内容),具体的计算步骤:首先是计算不同输入向量之间的得分,其次是把梯度稳定性的分数进行标准化,然后再使用softmax函数把分数转化成概率,继而计算加权矩阵,最后把全部计算过程统一整理成一个函数即为上式。
多头注意力机制是Transformer的非常重要的组成部分,将多个单头注意力机制连接起来即为多头注意力机制,计算公式如式(2):

式中:H为head(头);M为Multi-Head(多头);C为Concat(联结);W为线性变化时的参数矩阵。具体的计算步骤:首先把Q、K、V3个参数进行多次拆分,每组拆分的参数用于高维空间的不同的子空间中从而计算注意力权重。然后再进行多次并行计算,最后统一整理所有子空间中关于注意力的信息。
构建Transformer 的MLP Block,具体方法就是用全连接、GELU激活函数还有Dropout组成,比较重要的是,第一个全连接层会把输入节点个数翻4倍即为[197,768]→[197,3072],第二个全连接层会还原回原节点个数即为[197,3072]→[197,768]。
1.4 Vision Transformer模型的MLP Head部分
在经过MLP Head 层时,Vision Transformer 所处理的内容是通过所提取到的特征进行分类,也就是对本文所研究的8 种故障类型进行分类,特征提取时需要在图片序列上添加[class]token,并且提取出[class]token 所生成的对应结果和其他的特征一起进行特征交互,和其他图片序列的特征进行融合,然后用Multi-head Self-attention 结构提取特征后的[class]token来进行全连接分类。
2 实验结果和分析
2.1 实验环境和数据集
本文数据集InfraredSolarModules 来源于ICLR 2020的AI地球科学研讨会上,是一个机器学习数据集,包含在太阳能发电场中发现的不同异常的真实图像。用于检测异常的红外太阳组件数,该原始数据集未经过数据增强之前由7217 张红外图像组成,每张图像大小为24×40 像素,总共是有8 种故障类型,分别是cell、cell-Multi、Diode、Diode-Multi、Hot-Spot、Hot-Spot-Multi、Offline-Module、Shadowing。数据由“猛禽”地图团队汇总,并由配备中波或长波红外(3~13.5 m)和可见光谱成像系统的有人驾驶飞机和无人机系统收集。图像分辨率为3.0~15.0 像素/cm。异常被裁剪到单个模块,并被分成类。
实验环境是:所有的模型都基于Python 3.7 和Pytorch 1.11.1 框架,电脑采用Windows10 系统,内存为16 GB,CPU为AMD Ryzen 7 5800H with Radeon Graphics,GPU 为NVIDIA GeForce RTX 3050 Laptop GPU,使用CuDA11.3 和CuDNN8.2.1。实验具体模型参数设置如表1所示。
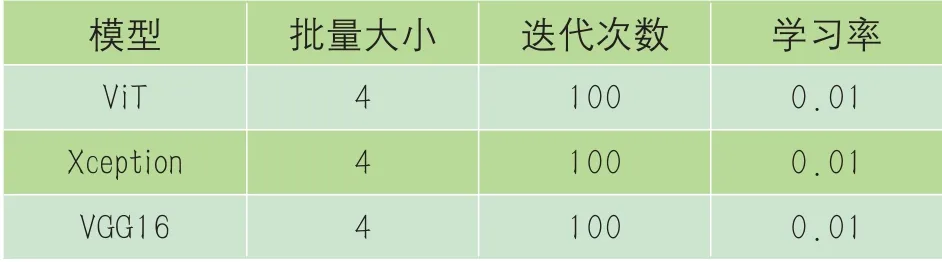
表1 Vit、Xception、VGG16模型参数
2.2 实验预处理
由于原数据集的样本相对较少,而对于图片分类的任务而言,需要大量样本才具有准确性,所以本文做了5种方式的数据增强,分别是左右翻转、上下翻转、增强亮度、降低亮度,改变锐度,将数据集的图片扩充到了43302 张。运用大量的数据集进行训练,提高了模型的鲁棒性和泛化能力。本文将34638张图片划分为训练集,8664张图片划分为测试集。其中1张图片的数据增强效果如图2所示。

图2 数据增强示例
2.3 实验结果分析
本文通过使用准确率、精确度、召回率和F1来验证Vision Transformer 模型的性能优于传统模型Xception 和VGG16 模型,其中准确率A、精确度P、召回率R和F1的计算公式见式(3)、(4)、(5)、(6):
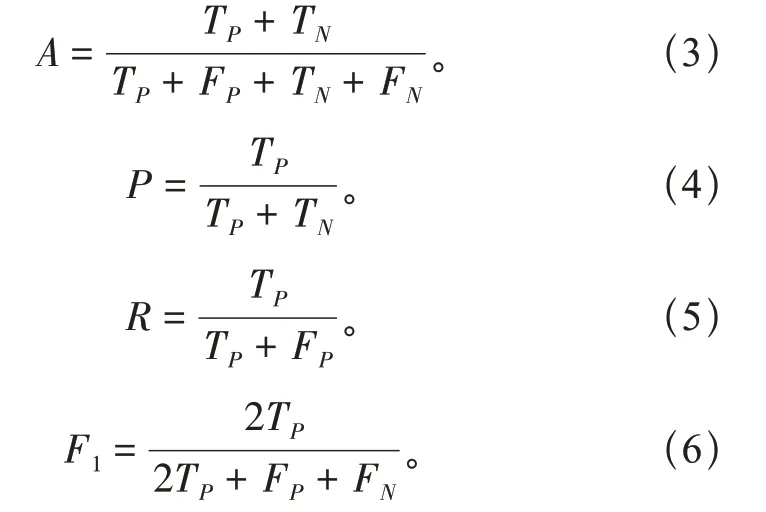
式中:TP为有故障图像的数量正确分类;TN为无故障图像的数量正确分类;FP为有故障图像的数量错误分类;FN为无故障图像的数量错误分类。准确性表示由本文提出的模型产生正确分类的概率。精度表示检测到的故障图像占所有故障图像的比例。召回率表示被本文的模型正确检测到的故障图像的比例。F1分数表示查准率和查全率的调和均。对比图3(a)、(b)、(c)、(d)可知,无论是准确率、精确度、召回率还是F1,本文所提出的模型均明显高于其他2个常规模型。由图3 (a)可知,Vision Transformer(Vit)模型准确率最高可达95.787%,高于Xception模型最高值11.9%,比VGG16模型增加了17.74%。由图3(b)可知,Vision Transformer 模型精确率最高可达96.441%, 高于Xception 模型最高值12.125%,比VGG16 模型增加了18.242%。由图3(c)可知,Vision Transformer 模型精确率最高可达95.462%,高于Xception 模型最高值11.805%,比VGG16模型增加了19.948%。由图3(d)可知,Vision Transformer 模型精确率最高可达95.857%,高于Xception 模型最高值12.347%,比VGG16模型增加了19.524%。
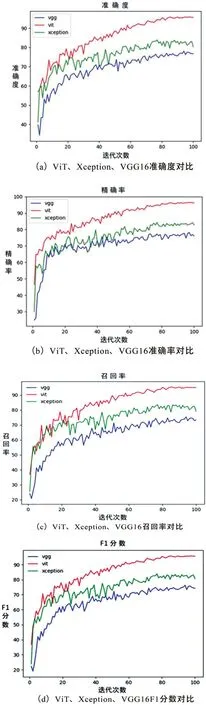
图3 Vit、Xception、VGG16对比图
3 结束语
本文基于Vision Transformer 模型,设计了光伏组件红外图像故障检测的方法,提高了检测的准确率。Vision Transformer 模型主要就是先将图像进行分块处理,然后进行图像块嵌入和位置编码工作,最后利用Transformer 编码器和MLP 进行分类处理。适用于大规模数据集的光伏组件红外图像故障检测。
光伏组件红外图像故障检测的方法能够促进光伏产业的发展,应用到实际生产之中,可以提高故障检测的效率,在组件发生故障的时候及时进行处理,减少由于故障带来的损失,以确保光伏电站的正常运行。本文所用方法受红外图像分辨率、摄像头参数影响,还有很大的改进的空间。
