结合二阶注意力机制的多尺度人体姿态估计
2022-12-19张云绚董绵绵王鹏李晓艳吕志刚邸若海毋宁
张云绚,董绵绵,王鹏,李晓艳,吕志刚,邸若海,毋宁
(西安工业大学电子信息工程学院,西安 710021)
人体骨骼关键点的定位对于描述人体姿态实例,预测人体行为动作是首要前提,因此人体骨骼关键点检测是诸多计算机视觉领域应用的基本问题,如人体行为分析[1]、人的重新识别[2]、人机交互[3]等。而人体姿态可为人体部位分割和标记提供结构信息。但不同距离拍摄摄像机等终端与相应目标之间拍摄高度和角度的变化,以及人体目标自身大小不一致,使得在同一张图像或者不同图像中人体目标的尺度和姿态存在较为明显的差异,这些尺度的问题会造成人体目标某些特征上的变化,这对人体关键点定位的准确性检测提出了一定要求。
人体是非刚性和柔性的,相对而言人体姿态灵活性、自由度极高,使得它们的准确程度受到限制。因此,在预测人体姿态估计面临许多挑战[4],特别是在任务中遇到的多尺度实例问题[5],文献[6]采用对称空间变换网络,对自顶向下框架中的不同尺度目标候选框进行修正,选择一个精准的目标提议区域,从而提高模型的性能;文献[7]采用4个并行的分支结构,最后对4个通道进行组合;文献[8]采用串行的多尺度特征结构,通过跳层连接来实现特征组合;文献[9]采用不同的特征尺度进行预测,最后将结果进行融合。文献[10]和文献[11]以将上述的方法进行组合,即将高层的特征添加到相邻的低层组合成新的特征,当然也可以反向的将低层的特征添加到高层。文献[12]设计了金字塔残差模块来有效提取人体多尺度信息。但这些都没有针对性解决尺度问题,部分原因是早期方法[13-15]的表达能力较差,首先关键点局部信息的区分性较弱,需要考虑较大的感受野区域;其次人体不同关键点的检测的难易程度不一样,尤其是受尺度变换影响下;最后更高的分辨率表示对高质量特征图的特征提取会更加友好,而不仅是通过上采样进行分辨率恢复。
深度卷积网络目前在视觉识别任务中取得了较好的表现,HRNet(high-resolution network)[8]目前在人体姿态估计任务中取得了前沿的、先进的(state-of-the-art,SOTA)表现。在此之前,主流的关键点检测的高分辨率网络是由一系列串联的高到低分辨率子网组成,最后通过上采样才做输出高分辨率的表示,这类网络由于上采样操作而带来空间分辨率的信息损失,导致最终输出的高分辨率表征所具有的空间敏感度并不高,很大程度上受限于语义表达力强的表征所对应的分辨率;还有一些高分辨率网络虽然将不同分辨率的子网并行链接,但子网间并没有进行多尺度的信息交换,最终输出的高分辨率表征只是由原本的高分辨率表征经过少量的卷积操作得到,导致网络最终输出的高分辨率表征只能是低层次的语义表达。因此,HRNet相比于其他的人体姿态估计高分辨率网络能够输出更可靠的高分辨率表征,但信息融合的越多不可避免的带来特征图的冗余信息,增加了特征图的空间维度和计算资源消耗,降低了模型的效率,对图像尺度变化带来的影响,没有得到有效的解决。
在无约束图像中,人体尺度变化通常很大,这可能会对人体姿态估计方法的性能产生负面影响。同时由于图像内容的复杂多变性,在进行人体姿态估计时,不仅要考虑关节本身的相似度之外,还要考虑人体整个的多尺度形变。虽然本身人体的定位不会产生太大的偏差,但不同图片中的多尺度变化、遮挡导致相连关节的实际定位情况并不相同,估计结果可能较差。为此,以主流算法HRNet为基础框架进行结构设计,提出了结合二阶注意力机制的多尺度网络(global second-order attention and octave scale convolutional high-resolution networks,GOS-HRNet)。为了对多尺度图像提取高质量特征图,利用Octave卷积扩大经典卷积有限的感受野大小;通过二阶的注意力机制捕获图像远处位置的特征相关性,增强特征的表示能力。采用尺度增强训练的方法训练模型,提高模型对图像尺度变化的鲁棒性,尽可能保留上采样获取更准确的位置信息和下采样中提取的语义信息。
1 基本网络模型
1.1 GO-HRNet网络模型
多分辨率网络从多个接受域中提取大量上下文信息,以获得更好的语义特征。但其中冗余的信息可能会误导关键点定位和识别,为了减少空间信息冗余,提出了一种采用Octave模块的改进HRNet人体姿态估计算法GOS-HRNet。GOS-HRNet算法整体流程框图如图1所示。
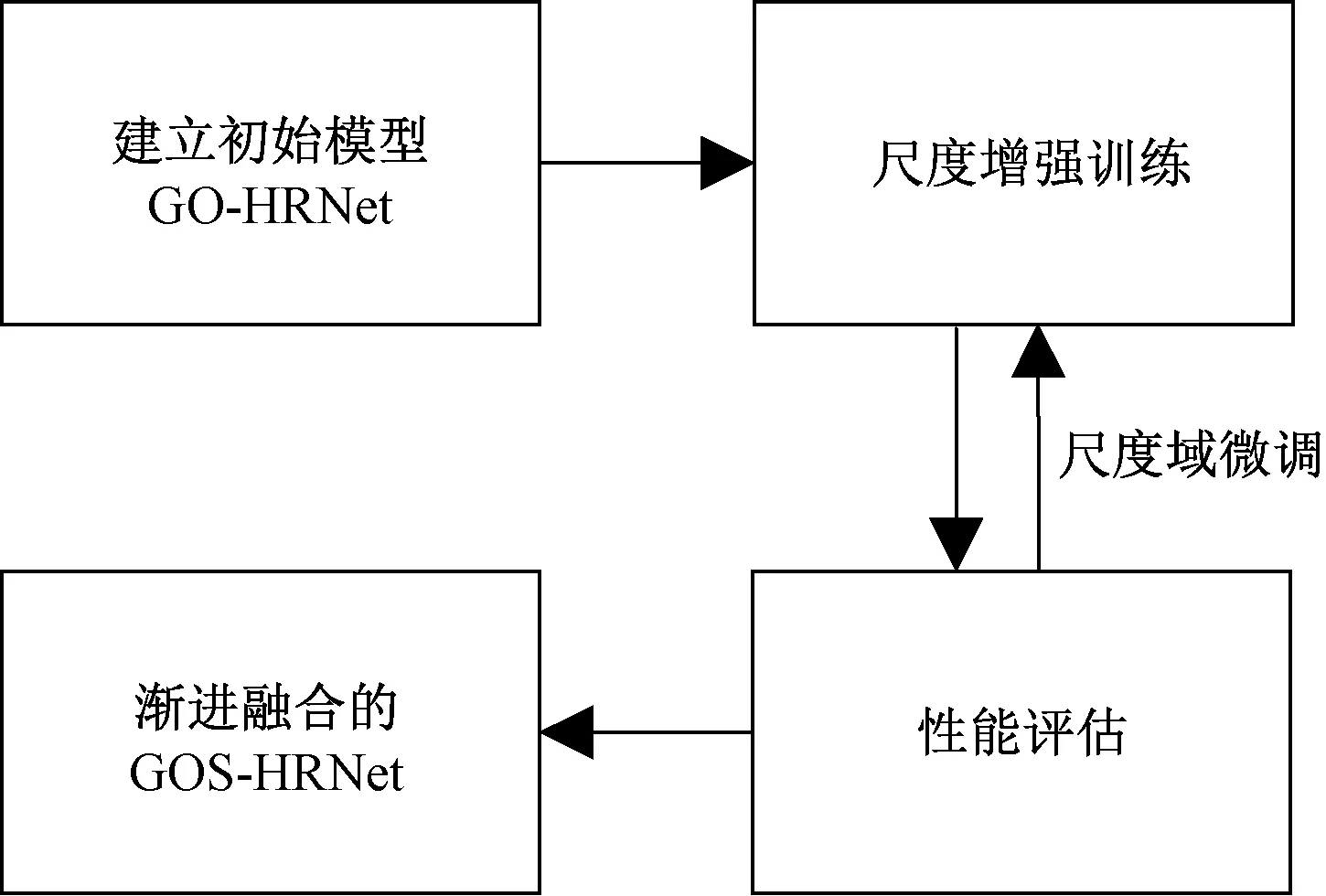
图1 GOS-HRNet算法流程框图
建立初始人体姿态估计网络模型GO-HRNet。采用Octave卷积模块完成卷积操作,通过分别存储和处理低频和高频特征生成Octave特征图,不仅降低了内存和计算成本,而且在低频段和高频段之间进行有效的通信,同时增大接收域的大小,获得更多的全局信息,从而提高识别性能。在网络模型中引入二阶注意力GSoP(global second-order pooling)模块,充分利用空间注意力来更好的挖掘不同尺度特征之间的上下文信息,学习高阶表示,丰富特征图的信息,进而有效提升网络性能,完成GO-HRNet模型的建立。利用尺度增强的方法确定尺度域,得到渐近融合的GOS-HRNet模型。基于尺度增强的方式训练初始模型再对网络模型进行尺度域微调,在保证人体姿态估计准确度的同时,提升模型对人体实例尺度变换的鲁棒性,从而获得高精度、多分辨率、高效的多尺度人体姿态估计模型。
1.2 多尺度特征融合
通过少量的卷积层,得到的特征分辨率高,包含更多位置、细节信息,但其所包含的语义信息少,噪声多。而通过大量的卷积层,得到的特征分辨率偏低,对细节的感知能力差。构建多分辨率的网络结构主要目的是提取多尺度特征,以应对人体的各种尺度变化,处理不同比例的身体部位,如面部、手部、脚等,并获得更大的全局和局部推理感受野。改进高分辨率网络HRNet,如图2所示,来捕获不同尺度和分辨率节点之间的相互依赖关系。相较于原有网络结构,增加了密集连接结构,在不同的分辨率阶段将不同的感受野扩大逐步实现特征细化,可以更好地结合全局信息。有效加强网络前层和后层之间的关联,同时保留原有网络之间不同分辨率之间的信息关联,网络整体之间可以有效地复用各层之间的特征图计算,进一步保证感受野区域融合多尺度特征,减少每层需要用的训练参数。
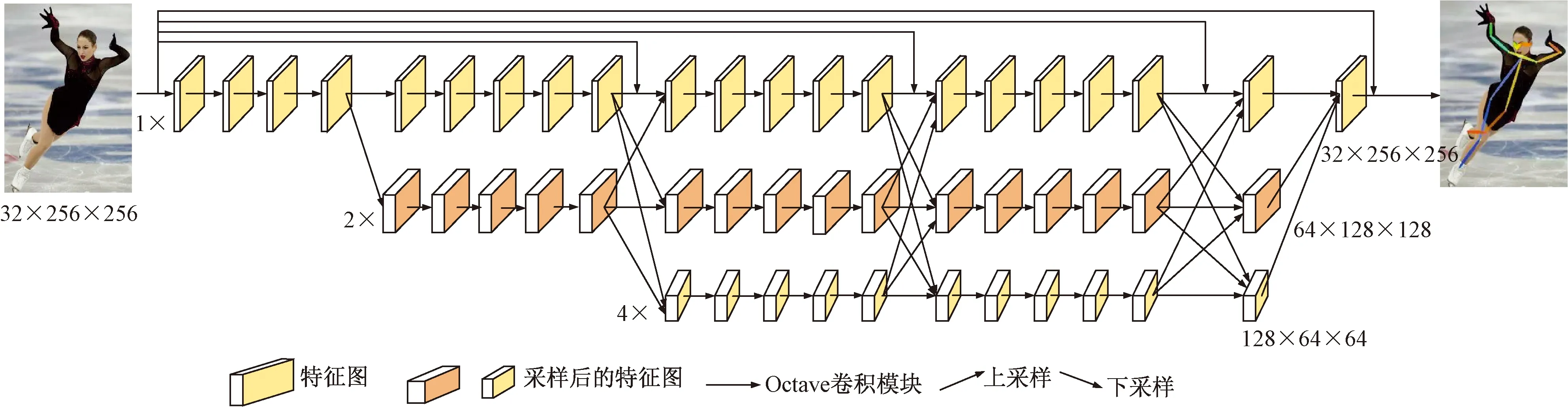
图2 改进的HRNet结构
2 基于Octave卷积模块重构人体姿态估计网络
Chen等[16]研究表明,特征图中也存在高频部分和低频部分,但是低频特征图包含的信息较少,为了降低特征图的冗余信息,因此提出一种新的卷积方式Octave卷积模块。一般在进行传统卷积运算时:令w∈Rc×k×k,其中,k为卷积核尺寸,c为输入的通道数或特征图,输入张量和输出张量分别表示为X、Y,X,Y∈Rc×h×w,其中,h和w分别为输入数据的长和宽,表示空间维数。传统卷积和Octave卷积示意图如图3所示。通过传统卷积公式[式(1)]得到特征图。
(1)
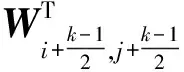
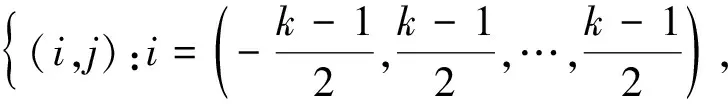
(2)
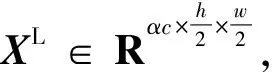
YH=YH→H+YL→H
(3)
YL=YH→L+YL→L
(4)
式中:YH→H、YL→L为相同频率进行频率内更新;YL→H、YH→L为不同频率间进行频率间通信;相同频率进行频率内更新,不同频率间进行频率间通信。为了更好地计算参数,卷积核W由两个分量组成,令W={WH,WL},每个分量可进一步分为频率内和频率间部分,其表达式分别为
WH=[WH→H,WL→H]
(5)
WL=[WH→L,WL→L]
(6)
经过式(3)~式(6)计算可以有效地对应处理多频特征,实现高效的频率间通信,如图3(d)所示。最后特征图计算公式为

图3 传统卷积与Octave卷积
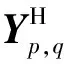
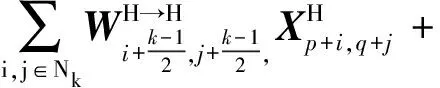
(7)
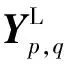
(8)
式中:⎣」表示向下取整操作;*为卷积。
与传统卷积相比,Octave模块可以有效地将感受野扩大2倍,有助于人体姿态估计网络在面对不同尺度变换时,捕获更多上下文信息,提高人体姿态估计网络性能。在整个多分辨率的网络中,替换了所有的传统卷积模块为Octave卷积模块。
2.1 二阶注意力机制模块
为了更好地增大感受野,融合局部特征与全局特征,注意力机制被引入到网络架构中,选择通道注意力[17]的一种,GSoP模块[18]可以通过局部操作激发图片的显著性特征,从而对图片进行整体性建模。输入数据为一个三维张量h′×w′×c′,其中h′和w′分别空间高度和宽度,c′为输入通道数,首先,使用1×1卷积进行通道降维,得到一个新的三维张量h′×w′×c′;然后,通过二阶池化操作计算通道与通道之间的相互性,得到一个c×c的协方差矩阵,也就是一行通道与所有通道的相关性;最后通过Sigmoid函数得到一个权重向量,与输入数据进行相乘,恢复成与输入数据一样的大小,作为输出数据,GSoP模块如图4所示。
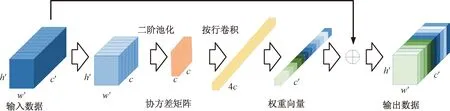
图4 GSoP模块
二阶的池化层可以有效保留图像空间特征,GSoP模块相对于传统卷积的最大池化操作选择了平均池化层,且对统计量进行了二阶计算,扩大了感受野,再通过不同权重的通道得到了重要的全局特征和局部特征,最后进行了特征融合,丰富了特征信息,从而提升人体关键点检测性能。综合考虑引入参数以及二阶注意力机制模块的实际应用性,在卷积层末端融入多个二阶注意力模块,考虑到多尺度和参数的影响,采用GSoP-Net1结构,其引入位置如图5所示,引入多个GSoP模块后的HRNet模型称为GO-HRNet。

图5 GSoP模块引入位置
2.2 尺度增强训练
本文模型采用尺度增强的方法来提高模型对图像尺度的鲁棒性。在训练中,选择并应用随机比例因子。根据图片的实际情况进行人体姿态估计,避免人体多尺度变化对人体关键点定位的影响。通过尺度增强训练,每一次输入的尺度将选择一个尺度因子进行尺度变换,然后送入网络模型中进行训练。图片裁剪宽高比为384∶288,采用随机翻转策略将图片随机旋转(-45°~+45°)并改变图像尺度,尺度变化为0.7∶1∶1.35三个不同尺度[19],如图6所示。

图6 尺度变化示意图
3 分析与讨论
3.1 实验环境
实验的测试环境为Ubuntu 18.04操作系统,采用深度学习框架Pytorch,实现了GOHNet人体姿态估计算法。服务器硬件配置为:Intel(R)Core(TM)i7-8700CPU@3.20 GHz,内存32 G,1TSSD+1THDD,Geforce RTX 2060Ti显卡。
3.2 实验数据集及验证指标
MSCOCO数据集被广泛使用在多种深度视觉任务中,它分为3个版本,即COCO2014、COCO2015和COCO2017。选择COCO2017作为数据集,它包含80个类别,200 000张图像,以及目标检测,人体关键点检测等5种标注信息。COCO2017中已经划分好训练集、验证集和测试集。其中训练集、验证集分别为train2017和val2017。train2017包含57 000张图像,150 000标注有人体关键点的人体实例,val2017包含5 000 张图像。而训练集有test-dev2017、test-change和test-standard共3个版本,均包含20 000张图像。使用train2017来训练模型,使用val2017和 test-dev2017来验证以及测试本文模型。MSCOCO评估指标中,对象关键点相似性(object keypoint similarity, OKS)定义为
(9)
式(9)中:p为地面实况中人的ID;i为关键点的ID;dpi为地面实况中每个人关键点与预测关键点的欧氏距离;Sp为当前人的尺度因子即此人在地面实况中所占面积的平方根;σi为第i个关键点的归一化因子;vpi为第p个人的第i个关键点是否可见;δ为将可见点 选出来进行计算的函数。
3.3 实验验证分析
对比了GOS-HRNet与其他的人体姿态估计网络的实验结果,如表1所示,GOS-HRNet与其他网络在COCO2017数据集上的验证结果表明,GOS-HRNet相比于其他网络取得了较好的精确度。

表1 不同模型AP-AR值
由于本文数据预处理中采用随机翻转与旋转策略,且生成3个不同的图像尺度,既扩增了数据规模,也使得数据具有良好的尺度不变性和旋转不变性。网络结构设计中融合不同层目标特征,加入上下文语义信息,有利于提高困难关键点的检测准确率。由2017COCOtest-dev数据集评估指标可得,本文模型关键点检测精度得到提高,平均检测精度比CPN(cascaded pyramid network)模型提升了6.1%,比HRNet模型提升了2.2%其中,CPN模型姿态估计器采用ResNet(deep residual networks)+Inception,Simple Base姿态估计器采用ResNet。
模型在输入图像尺寸为256×192和384×288时不同交并比下AP与AR值如表2所示,姿态估计模型训练过程中,人体检测框数据基于数据集中标注的人体边界框数据。随着输入图像尺寸增加,本文姿态估计模型的平均准确率有所提高,模型的性能也随之提升,其原因在于图像尺寸和分辨率越大,网络提取的特征图分辨率就越高,模型的表现也就越好。

表2 不同输入下模型AP-AR值
3.4 消融实验分析
通过Octave卷积和二阶注意力机制的方法来对网络模型进行改进,平均准确率上升了2.2%,在对比实验分析中对仅引入Octave卷积和二阶注意力机制的融合方法进行实验验证,如表3所示的消融实验中对比了两种方法的分别引入和融合方法对网络模型带来的影响。
从表3中可以看出,两种方法的引入均得到了比较好的准确度(mean Average Precision, mAP)提升,其中在仅使用Octave卷积方法O-HRNet时准确度得到了0.9%的提升,对于OS-HRNet方法是通过尺度增强训练后的网络模型,再通过引入二阶注意力机制的融合方法时GO-HRNet模型准确度相比于HRNet得到了1.9%的提升,最后完成的模型GOS-HRNet方法相比于HRNet得到了2.2%的提升。通过引入Octave卷积作为基础卷积,在网络基础特征提取部分可以有效改善传统卷积感受野不足,不能抓取更多上下文信息的缺点;二阶注意力机制充分利用全局二阶统计信息,可以捕获长期的统计相关性,使网络具有更好的适用性。实验结果可以证明,引入二阶注意力的多尺度网络可以更好地提取特征,减少空间冗余,更好的利用网络中不同分辨率子网不同多尺度图像下的特征图信息。

表3 消融实验分析
3.5 实验结果分析
以网络图像、自主拍摄和COCO2017数据集图像为例进行人体姿态估计,展示多尺度、遮挡和公共数据集下的模型泛化能力。原网络和本文网络GOS-HRNet人体姿态结果对比图,如图7所示。其中,图7(a)、图7(b)是在俯视角度下存在遮挡情况的效果图,本文网络可以更好地识别出在俯视角度下目标存在遮挡时的结果。图7(c)、图7(d)是在俯视角度下,因距离变换导致尺度变换结果,可以看出在视角较近时两个网络均可以识别出,但增加距离后原网络模型无法很好地识别出结果。图7(e)、图7(f)是在同一视角下,连续改变距离带来的多尺度影响结果。可以看出,尺度变换、带有部分遮挡、角度改变的情况下本文网络的预测结果均有较好的表现。

彩色点的位置表示人体实例关键点位置;点与点之间的线段表示人体实例关键点之间的连线
4 结论
提出了一种基于Octave模块的结合二阶注意力机制的多尺度人体姿态估计算法GOS-HRNet。通过实验结果,得出以下结论。
(1)通过Octave模块增加了对卷积特征图的感受野,对特征图内部的高频信息进行处理,同时在空间上,减少冗余信息,提升了基础网络的人体关键点定位准确率。
(2)利用二阶的注意力机制模块,以协方差的形式重新体现了通道与通道之间的关系,对图像进行整体性建模,获取更多的上下文信息。
(3)采用多分辨的网络结构以及密集跳层连接,融合了不同分辨率层的特征信息交换,得到了高质量的特征图,能够有效提取图像尺度变换后的特征,并在训练阶段使用尺度增强的训练方式,提升模型的鲁棒性。
