融合自上而下和自下而上注意力的图像描述生成
2022-12-19武光利郭振洲李雷霆
武光利,郭振洲,李雷霆
(甘肃政法大学网络空间安全学院,兰州 730070)
图像描述生成技术是自然语言处理(natural language processing,NLP)和计算机视觉(computer vision,CV)交叉领域的重要研究课题之一[1],需要完成的任务是生成一句话对输入图片进行描述,并且描述语句不但要语法正确、符合逻辑、语句通顺,还要符合图片内容。所以它既需要CV对图片内容的深度挖掘与分析,又需要NLP对语义信息的充分理解与解析[2]。因此,图像描述有着广泛的应用场景。如在公安领域,图像描述技术能在破案时帮助公安人员快速分析现场照片内物体之间的内在关系,并找出所有证据和生成对案件的推理,有利于快速破案;图像描述还可以应用在图像检索领域[3],利用生成的描述语句进行基于语义的图像检索,比基于图片相似性的检索方法更精确,特别是当人们在淘宝、抖音等APP搜索时,内容更符合人类的预期;图像描述还可以在人机交互、幼儿学习和盲人助理等方面得到很好的使用[3]。
通过对中外研究数据进行分析,可以按照所采用的技术不同,把图像描述生成的方式分为3大类:基于模板的方法、基于检索的方法和基于深度学习的方法[4]。
基于模板的方法是给定描述语句的模板,然后识别图片中的物体及物与物之间的关系,最后向模板中补充对应单词完成整个句子[5-6]。这种方法虽然能生成正确的句子,但不够灵活。基于检索的方法是将全部的描述语句看成一个整体,然后同时将句子和图片转换到高维空间,根据图片和句子的相似性搜索得到和输入图片内容最贴切的句子作为输入图片的描述语句[7-8]。这种方法虽然能够为查询图像搜索到相关的描述语句,但是无论什么样的图片只能在现有的语句中检索相似的描述语句,并不能生成新的句子。
基于编码器-解码器架构的方法是受机器翻译领域的启迪,将图像描述生成看作是把图像“翻译”成句子。这种方法是目前图像描述领域的主流方法,通常是构建深度学习模型,生成一句描述图片内容的话。早期的方法大多是构建的端到端模型。文献[9-11]以卷积神经网络(convolutional neural network, CNN)为编码器,以循环神经网络(recurrent neural network, RNN)为解码器,构建模型生成语句;文献[12-14]通过在编码器和解码器中间添加不同作用的注意力机制,从而使生成的描述更准确。随着数据集的限制越来与明显,近几年部分研究人员开始尝试使用强化学习(reinforcement learning, RL)、生成式对抗网络(generative adversarial network,GAN)和图卷积神经网络(graph convolutional network, GCN)构建模型[15]。文献[16-17]利用GAN网络中特有的随机噪声来增加多样性,其生成器通过CNN和长短期记忆网络(long short-term memory,LSTM)生成描述句子,判别器则是用来评估生成句子与人工标注的句子的相似性。文献[18-22]利用强化学习的方法,以CNN和LSTM作为策略函数生成描述语句,以CIDEr和SPICE为奖励函数构建模型。
现提出一种融合自上而下和自下而上注意力的图像描述生成模型。该模型首先以编码器-解码器框架为基础,将ResNet101和Faster R-CNN(regions with convolutional neural network)作为编码器,分别提取输入图片的全局特征和局部特征,并利用自上而下和自下而上注意力分别计算两种特征的权重;将门控循环单元(gate recurrent unit,GRU)和LSTM作为解码器,提取上下文的语义信息和生成单词。然后利用生成式对抗网络和强化学习结合的训练方式优化模型,将上述基础模型作为策略函数或生成器,将图像-文本相似性作为奖励函数或判别器,在相互对抗中得到不断优化的策略函数和不断完善的奖励机制,从而使生成的句子更加准确、自然。
1 关键技术
1.1 生成式对抗网络
生成对抗网络[23-24]包含生成器和判别器两个部分,是一种非监督的机器学习模型。生成器的宗旨是输出能够以伪乱真的数据,而判别器的目标则是尽可能判别数据的真伪,它们两者在相互对抗中不断优化。从本质上来说GAN网络的生成器是将生成器输入分布尽可能映射为目标分布,判别器评判两个分布的相似性,如图1所示。
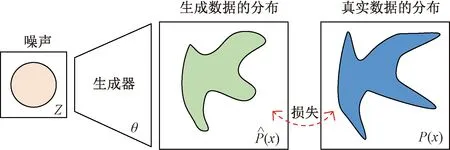
Z为噪声分布;θ为生成器;为生成数据的分布;P(x)为真实数据的分布
由于GAN网络生成的数据是不可控的随机数据,所以采用条件生成对抗网络(conditional GAN,CGAN)[25]解决图像描述生成任务,以图像特征为条件变量对生成器进行指导,生成与该图像相符的语句,并利用判别器对图片和生成语句的相符程度打分。为了能得到更加贴切的描述语句,在生成器的输入中没有加入随机噪声,增加了生成语句的可控性。如图2所示。

图2 CGAN网络原理图
1.2 强化学习
强化学习是标准的马尔可夫决策过程,通过智能体(agent)与环境(environment)之间的信息相互传递优化智能体的决策能力,使奖励(reward)最大。主流的强化学习方法分类两种,基于策略的算法和基于值的算法,它们分别旨在找到最佳策略和最好的动作-值映射关系。使用优势动作评论算法(advantage actor-critic,A2C)能同时利用两者的优点,将基于策略的算法作为演员输出动作,将基于值的算法作为评论家判断动作的好坏,共同进步。如图3所示,在图像描述生成任务中应用A2C需要构建4个关键元素,分别是状态(state)、动作(action)、奖励与优势函数,其中状态是指在当前时刻环境所被观察到的状态值,即图片特征和之前时刻生成的所有单词;动作是指智能体根据自身的策略(policy)在当前时刻的状态下做出的动作,即生成的单词;奖励是指环境接收到智能体的动作后反馈的奖赏值,即图像-句子相似性;优势函数是指当前动作对状态的改变是否具有优势的引导作用。
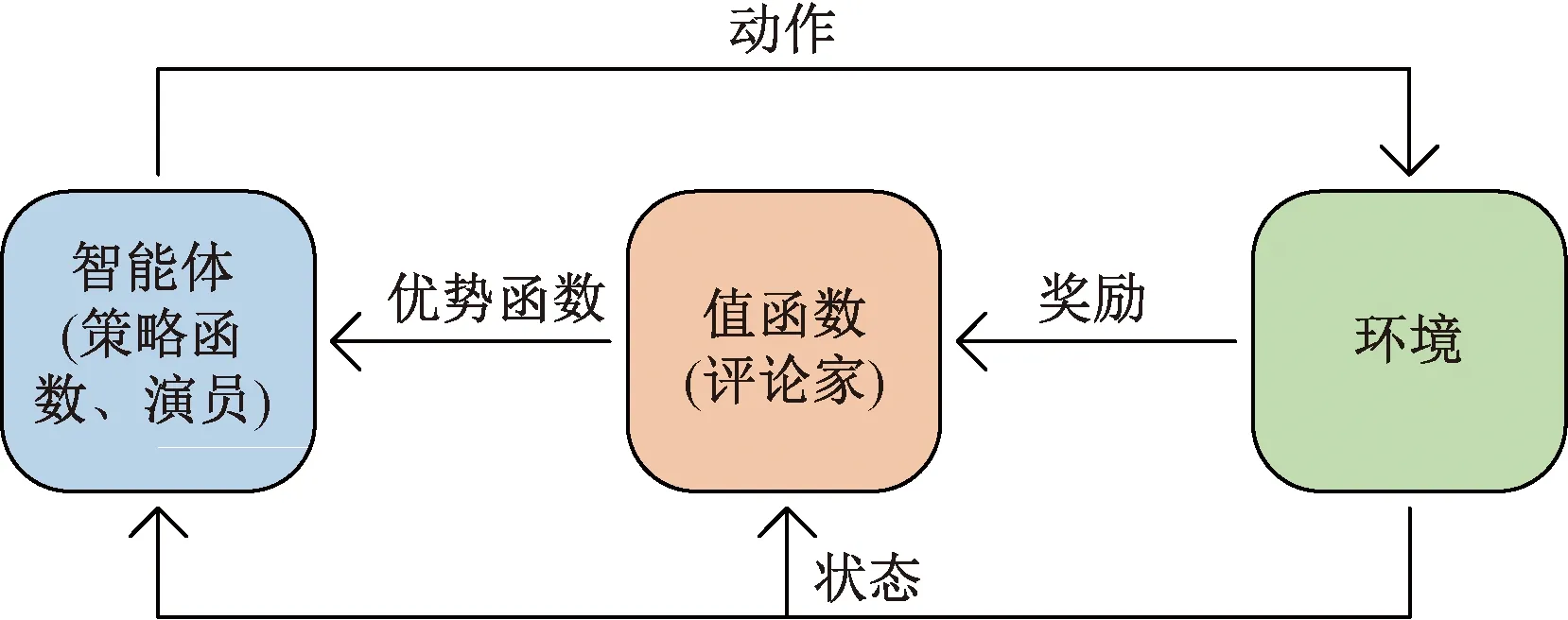
图3 A2C网络原理图
1.3 注意力机制
注意力机制是指大脑在处理视觉感官聚焦时的一种方法,将更多的注意力放在目标上,并选择性地忽略其他信息。将注意力机制应用到深度学习中可以更好地分配计算资源,从大量的数据中提取出少量的重要信息,提高了神经网络的可解释性。注意力机制由查询向量(query)和键值对(key-value)两部分组成,如图4所示。从本质上理解,键的信息越重要,其对应的值越大。
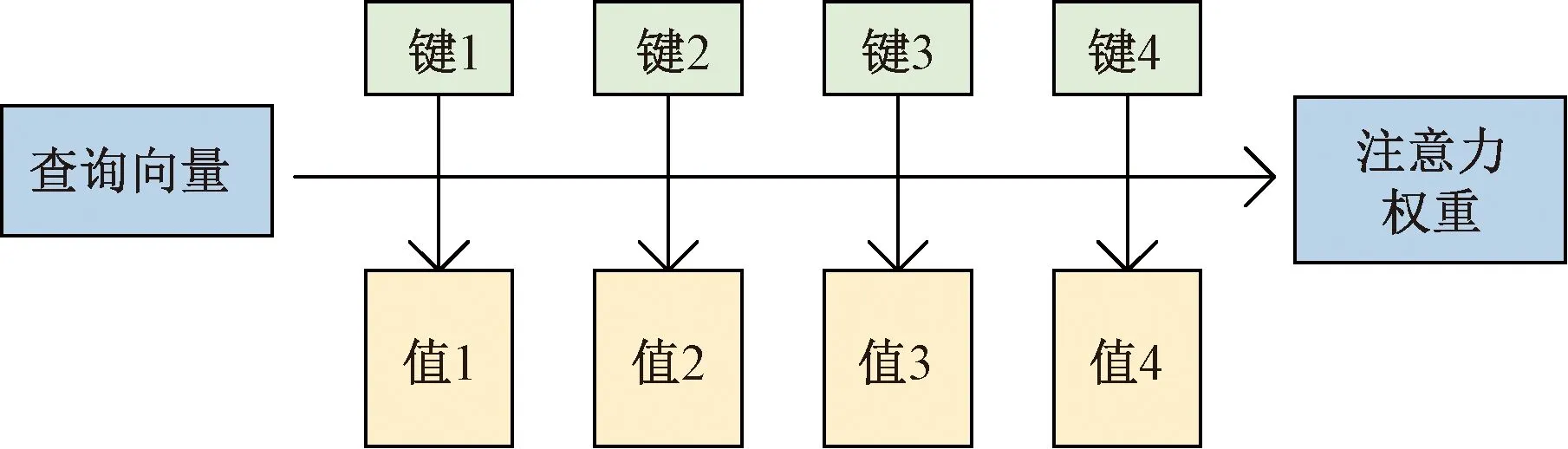
图4 注意力机制原理图
注意力机制的计算过程如式(1)所示可分为三步:①计算query和key的相关性,通常用向量点积、余弦相似性等方法;②将求得的相关性进行Softmax操作,得到注意力权重;③根据注意权重对Value进行加权求和。
(1)
式(1)中:Attention()为注意力机制的计算函数;Q为查询向量;K、V为键值对;KT为键向量的转置;Softmax()表示归一化指数函数;dk为key的维度。
Anderso等[26]将计算机视觉注意力机制分为自上而下注意力(top-down attention)和自下而上注意力(bottom-up attention)。其中自上而下注意力是通过卷积[27]等操作提取出输入图片对应的特征图,然后对特征图中的每一个元素进行权重计算,即相当于对输入图片中的每一块区域进行权重计算,是细粒度的分析,如图5(a)所示;自下而上注意力是通过Faster R-CNN[28-29]等目标检测算法提取出输入图片中的目标区域,然后计算每个区域对查询向量的权重,起到了类似于硬注意力的效果,如图5(b)所示。

图5 自上而下注意力和自下而上注意力
2 本文模型
为了更好地解决图像描述问题,在编码器-解码器框架下提出了一种融合自上而下和自下而上注意力的基础模型,并利用GAN网络和强化学习在基础模型的基础上进行改进。
2.1 基础模型
基础模型由编码器和解码器组成,它的编码器阐述了模型是怎样获取图像特征的,它的解码器则阐明了模型是如何利用特征并将其解析成语句的。基础模型结构如图6所示。
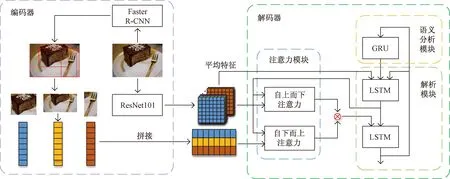
图6 基础模型结构图
如图6所示,该模型的编码器由两部分组成,分别是ResNet101和Faster R-CNN。ResNet101是图像分类中的一个经典模型,通过其特有的“shortcut connection”结构使网络一直处于最优状态。Faster R-CNN是目标检测的一个经典模型,通过区域生成网络(region proposal network,RPN)产生建议窗口,并且将RPN和目标检测网络共用一个CNN,不但减少了建议框数量,还增加的建议框的质量。采用迁移学习的方法,使用预训练的ResNet101将图片提取为7×7×2 048的特征图,以用于自上而下的注意力输入,如式(2)所示;使用Faster R-CNN检测图片的目标区域,并将每个目标区域处理为1×512的特征向量,以用于自下而上的注意力输入,如式(3)所示,假设一个图片被检测出有n个目标区域,则经处理后代表图片的目标区域特征向量形状为n×512。
VR=ResNet101(I)
(2)
VF=Faster R-CNN(I)
(3)
式中:ResNet101()为ResNet101的计算过程;Faster RCNN()为Faster RCNN的计算过程;I为输入的图片;VR、VF为两种图像特征。
该模型的解码器由3部分组成,分别是注意力模块、语义分析模块和解析模块。注意力模块以第一层LSTM[30]的输出为查询向量分别计算自下而上和自上而下两种注意力,并将两者的结果拼接后输入第二层LSTM。其中自上而下的注意力计算49个网格区域的贡献程度、自下而上的注意力计算n个目标区域的贡献程度,分别从全局和局部中找到对当前时刻生成单词贡献最大区域。语义分析模块是一层GRU[31],相比于LSTM,GRU的结构更加简单、参数量更少,通过分析之前时刻已经生成句子的语义信息,为当前时刻要生成的单词提供引导,使句子更加自然顺畅,如式(4)所示。解析模块由两层LSTM组成,第一层LSTM以上一时刻的词向量、图像平均特征、语义信息为输入,通过上一时刻的结果微调全局图像特征和整句话语义的隐藏状态,将隐藏状态看作查询向量,通过注意力模块得到当前时刻最聚焦的区域,最后通过第二层LSTM将其解析为单词。解码器的计算过程如下。
SG=GRU(wt-1,h0)
(4)
H=LSTM1(wt-1,VR,SG)
(5)
ABU=Bottom-Up(H,VF,VF)
(6)
ATD=Top-Down(H,VR,VR)
(7)
wt=LSTM2(ABU,ATD,H)
(8)
式中:GRU()为GRU的计算过程;LSTM1()为第一层LSTM的计算过程;Bottom-UP()为自下而上注意力的计算过程;Top-Down()为自上而下注意力的计算过程;LSTM2()为第二层LSTM的计算过程;wt-1为上一时刻生成的单词;wt为当前时刻生成的单词;SG为提取的语义信息;h0为当前时刻的语义信息;H为隐藏状态;ABU为自下而上注意力;ATD为自上而下注意力。
基础模型在训练时使用监督学习的方法,利用交叉熵[式(9)]计算损失值,并使用Adam优化器迭代模型梯度。
(9)
式(9)中:Loss为损失值;N为样本类别的个数;Li为每个类别的熵;yic为模型计算出来的值;pic为该值对应的概率。
2.2 强化学习模型
强化学习模型是利用强化学习的方式训练基础模型,不但需要将基础模型看作智能体的策略函数,还需要在基础模型的基础上增加奖励函数和值函数。奖励函数相当于是一种游戏规则,是一种奖惩机制,对不同的动作给出不同的奖励。值函数则是相当于一个评论家,对不同的状态打出不同的分。模型结构如图7所示。
如图7所示,强化学习模型由策略函数、奖励函数和值函数组成。策略函数和上文中的基础模型一样,在此就不多做阐述。奖励函数是计算当前时刻生成的单词对语义影响的即时奖励,先将图像特征和语义特征映射到一个高维空间[式(10)、式(11)],然后计算图像-文本的相似性[式(12)],相似性越高,奖励越接近1,相似性越低,惩罚越接近-1。值函数则是通过当前时刻的状态预测总体回报,使用多层感知机(multilayer perceptron,MLP)构建了一个回归模型代表值函数,以图像平均特征和当前状态为输入,以离散的时间状态去逼近总体回报,其输出为Vθ(St)。
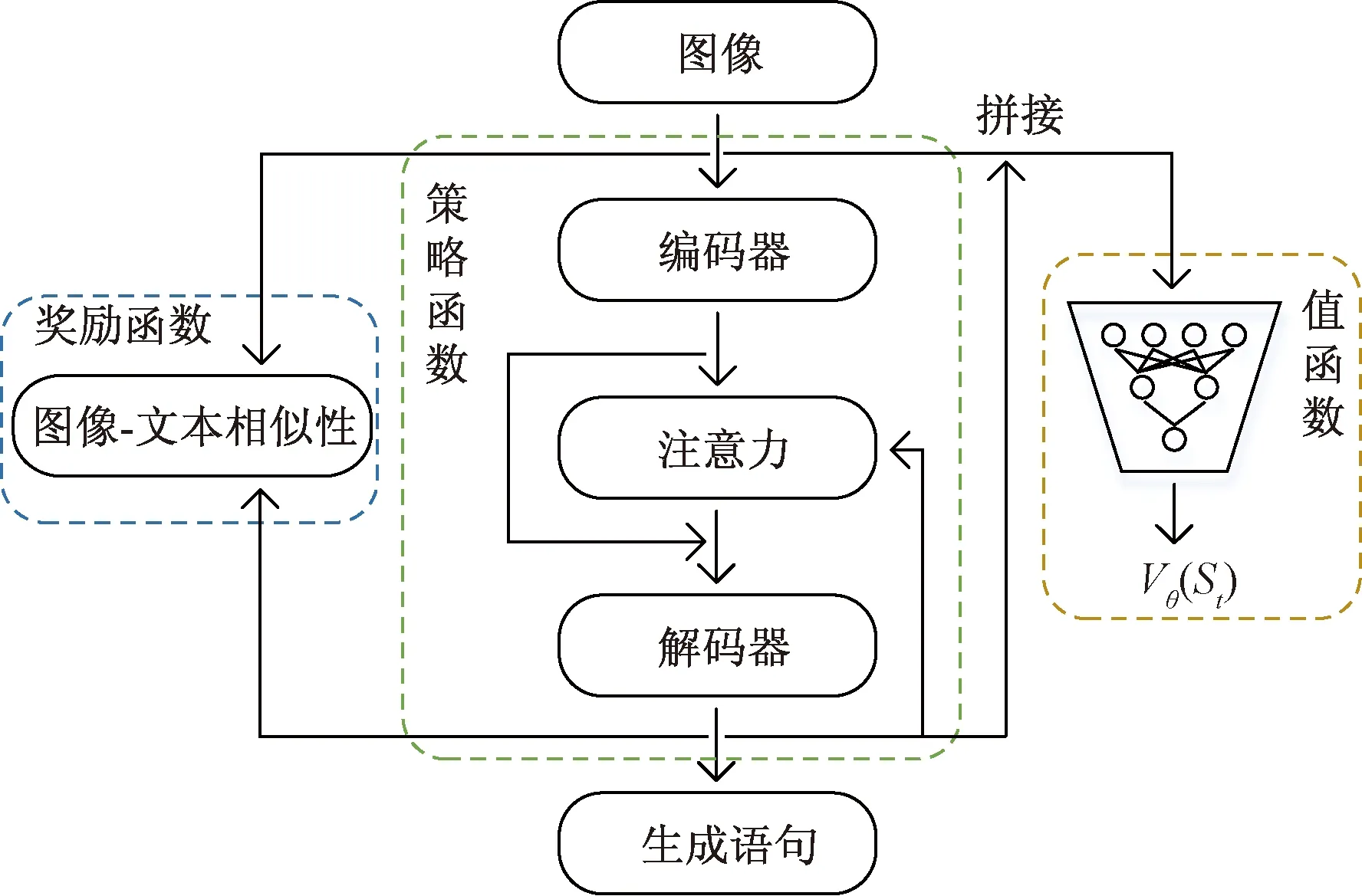
图7 强化学习模型结构
Ve=0.5(WRVR+bR+WFVF+bF)
(10)
Se=WGSG+bG
(11)
(12)
式中:Ve为映射到高维空间后的图像特征;Se为映射到高维空间后的语义特征;WR、WF、WG为映射时的权重;bR、bF、bG为映射时的偏置;r为奖励值;θ为图像特征和语义特征之间的角度。
在训练时,先固定奖励函数,然后交替训练值函数和策略函数。在训练值函数时采用监督学习的方式,使用真实的图片和描述语句作为输入,通过均方损失函数MSELoss[式(13)]和Adam优化器使其输出的结果逼近奖励函数输出的奖励值。在训练策略函数时采用强化学习的方式,只输入图片,通过奖励函数和值函数不断优化策略,使奖励r[式(12)]最大、损失Loss[式(14)]最小。
(13)

(14)
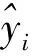
2.3 GAN网络模型
GAN网络模型是在强化学习模型的基础上改变了模型结构以及训练方式。修改后的模型将原来的策略函数和值函数看作生成器,将奖励函数看作判别器,模型结构图如图8所示。
如图8所示,在模型工作时,生成器根据输入的图片生成一系列单词组成语句,然后判别器根据图像-文本的相似性[式(12)]打分。
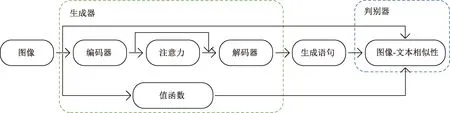
图8 GAN网络模型结构图
相比于强化学习模型,GAN网络模型做了两点改进:一是在训练时,生成器还是按照强化学习的方式训练,通过不断试错减小损失,判别器是按照半监督的学习方式训练,通过减小生成的句子和真实的句子之间的打分提高整体性能[式(13)];二是不断完善的奖励机制,众所周知,强化学习的奖励函数是固定不变的,它代表一种规则,引导着策略函数向目标函数逼近,但是任何规则都不是一成不变的,不管是游戏还是生活,与时俱进的奖励机制才能更好地指导策略函数。于是,就把奖励函数当做GAN网络模型的判别器,在与生成器的竞争中不断完善。如“A dog holding a frisbee”“A white dog holding a purple frisbee in it’s mouth”两句话,模型早期的奖励机制可能都打0.9分,但完善后的奖励机制可能打0.6分和0.9分。
3 实验设计
3.1 实验设置
本文模型在MSCOCO数据集上进行实验,该数据集共有 123 287 张图片,每张图片都标注了 5个不同的描述语句。分别使用113 287、5 000、5 000张图像进行训练、验证和测试。并且在训练模型的前期准备中,将所有的描述语句汇总,并进行简单的文本预处理,包括将所有单词变为小写字母,并删除出现频率少于5次的单词,添加
3.2 实验结果与分析
按照模型训练步骤,可将整个模型分为3种类型,分别是基础模型、RL模型、GAN模型。表1为消融实验的结果,可以观察到3种模型都得到了合理的结果。可知3种模型是层层优化的关系,所以在各种评价指标上也呈现了一种递增的趋势。最终经过GAN网络结构的优化,本文模型在各个评价指标上得到了较好的实验结果。
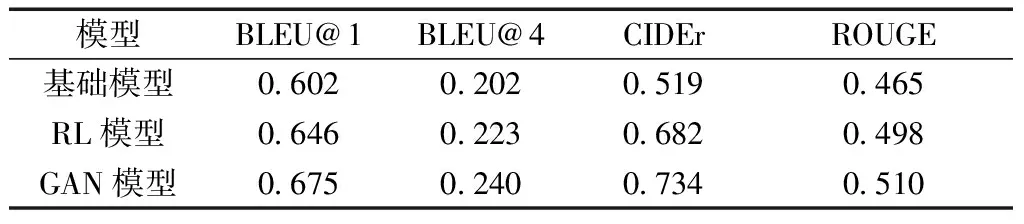
表1 消融实验结果
分别找出与编码器-解码器模型、RL模型、GAN模型3种类型相关的优秀模型和其在COCO数据集下的实验结果,如表2[9,13,21-22,28]所示。通过对比实验可知,本文模型可以在部分评价指标上达到较好的结果,充分表明了GAN网络和强化学习结合的可行性与优越性。分析没有达到最优结果的原因在于:①实验中使用的几种评价指标都是NLP领域的评价指标,人工标注的参考句子对评价指标影响大,而本文模型生成的句子虽然描述正确,但与参考句子差别较大,拉低了评价指标的得分;②模型收敛到了局部解,并未得到最优解。
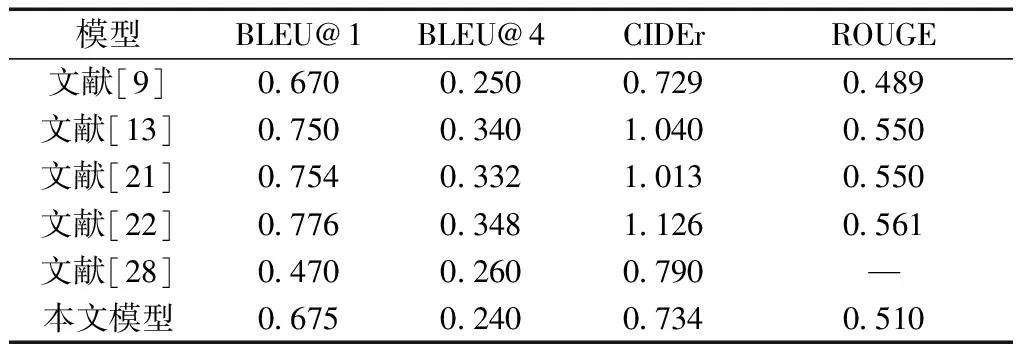
表2 对比实验结果[9,13,21-22,28]
3.3 实验结果展示
图9展示了两个在评价指标上得分较高的图片,其中,图9(a)对应的生成描述语句是 a man riding skis down a snow covered slope.(一名男子在积雪覆盖的斜坡上滑雪),其人工标注的参考句子是a person standing on top of a ski covered slope.(一个人站在大雪覆盖的斜坡上);图9(b)对应的生成描述语句是a tennis player is playing tennis on a tennis court.(网球运动员正在网球场上打网球),对应的人工标注的参考句子是a male tennis player in white shorts is playing tennis.(一位穿着白色短裤的男子网球运动员正在打网球)。

图9 得分较高的实验结果
图10展示了两个在评价指标上得分较低但生成的描述语句正确的图片,其中,图10(a)对应的生成描述语句是a white plate topped with a piece of cake.(上面有一块蛋糕的白色盘子),其人工标注的参考句子是GT: a meal is lying on a plate on a table.(一顿饭放在桌子上的盘子里);图10(b)对应的生成描述语句是Pre: a brown teddy bear sitting next to a pile of teddy bears.(一只棕色的泰迪熊坐在一堆泰迪熊旁边),对应的人工标注的参考句子是three teddy bears, each a different color, snuggling together.(3只不同颜色的泰迪熊依偎在一起)。

图10 得分较低的实验结果
4 结论
通过结合GAN网络和强化学习提出了一种融合自上而下和自下而上注意力的模型,用以解决图像描述问题。该模型能更好地关注与语义信息相关性较大的图像区域,生成更加自然、更加准确地描述语句。此外,在训练时,分别使用强化学习和半监督学习的方式优化GAN网络的生成器和判别器,通过不断优化生成器和不断完善判别器得到了更好的描述语句。在未来的工作中,将构建不同的基础模型,尝试不同的编码器、解码器。
