基于GraphSage节点度重要性聚合的网络节点分类研究
2022-12-19邹长宽田小平张晓燕张雨晴杜磊
邹长宽, 田小平, 张晓燕, 张雨晴, 杜磊
(北京石油化工学院信息工程学院,北京 102617)
在计算机领域,“图”是一种把实体网络抽象出来的数据结构。图中的顶点和边也分别被称为节点和关系。例如,社交网络中的用户可看作节点,用户之间是否关注可看作关系。图数据采用非欧几里得式数据结构进行存储,其中心节点的邻居节点数量和节点顺序不固定,不满足平移不变性[1],很难定义卷积核,导致传统的卷神经网络方法无法处理。图神经网络的基本思想是通过结合节点自身和邻居节点的特征来迭代更新节点的表示[2],是解决此问题的一种有效方法,最近几年受到研究者们的广泛关注。
节点分类是图神经网络中一类最为广泛的应用,其目的是使用已提供标签的节点信息表示新的节点特征,并对未标明类别的节点进行分类。除了应用于基于社交网络,还可以应用于生物网络和引文网络[3]。
传统节点分类方法主要是基于表示学习的图嵌入方法。如DeepWalk方法[4],通过在图中随机游走并对游走的节点使用SkipGram模型[5]来实现对节点的表示学习。LINE方法[6]在引入一阶相似度和二阶相似度的基础上来学习到节点间的高阶相似性。其中,一阶相似度表示节点间是否有联系,二阶相似度则表示节点邻居的相似程度。Node2vec方法[7]使用深度优先策略和广度优先策略代替了随机游走策略,不仅能让模型自己学习如何游走,还能让模型更有效地结合图结构来实现节点的表示学习。以上方法有两个明显的缺点:①基于图嵌入方法的计算量会随着节点数呈线性增长且无法处理节点的自身特征;②直接的嵌入方法缺乏泛化能力,无法推广到新的图上。
为了寻找一种有效的节点分类方法,学者们将卷积神经网络的思想拓展到图数据上,加速了图神经网络的发展。Brua等[8]提出了Spectral Network,通过基于图对应的拉普拉斯矩阵的特征分解,在傅里叶域中定义卷积运算实现了节点分类,但这种方法计算复杂度高。基于此,Defferrard等[9]提出了ChebyNet,省去了计算拉普拉斯矩阵的过程。Kipf等[10]改进了ChebyNet网络并使用一阶卷积核,提出了图卷积网络(graph convolutional network,GCN)。Hamilton等[3]提出了归纳式学习的图神经网络模型GraphSage,GraphSage没有使用图的拉普拉斯矩阵,通过对节点邻居信息的聚合来表示出一个新的信息,不同的聚合方式会有不同的效果。Hu等[11]利用多层感知机设计的图多层感知机(Graph-multilayer perceptron,Graph-MLP)模型将图结构融入到节点的特征变换过程当中,使得模型在节点间邻接信息缺失的情况下仍能保持有效的分类。
基于此,通过在GraphSage聚合函数中引入节点自身特征信息和图结构相关信息,提出了可用于监督学习GraphSage-Degree节点分类模型,该模型首先从图中获取节点度,即节点在网络中的连接边数,然后根据节点度判断节点在邻域中的重要性,最后以重要性为权值来聚合节点的特征信息,为研究节点度在节点分类中的作用提供了科学依据。
1 网络模型
1.1 GraphSage设计
传统的图神经网络在训练模型时同时对所有训练节点及其特征进行操作,但由于计算机的内存限制,这种方法有可能导致分类失败。因此,GraphSage使用小批量的训练方式,即在训练时的每一轮epoch中,又分成若干次小训练,每一次小训练只使用20个训练数据。
GraphSage模型主要由3个步骤组成,即采样、聚合和分类,具体如下。
步骤1采样。如果模型在学习节点表示的过程中使用所有的邻居节点,则会因为邻居节点集合的大小不确定导致计算复杂度不可控。针对每一个节点,GraphSage以其为中心将整个图结构数据由内到外分成k层。这样位于第l(1≤l≤k)层的每个节点采样Sl个邻居节点,采样时若邻居节点数不足Sl个则使用全部邻居节点,否则从邻居节点中随机采样Sl个节点。缺省情况下,k值选择2,需要保证S1S2≤500[3]。图1为k=2,S1=3,S2=2时的采样示意图。图1中用虚线划分邻居节点所在层次,具有十字标志的节点为中心节点,具有一条横线的节点为采样的一阶邻居节点,具有两条横线的节点为采样的二阶邻居节点,空白节点为未被采样到的节点,箭头表示沿着节点之间边的采样方向。
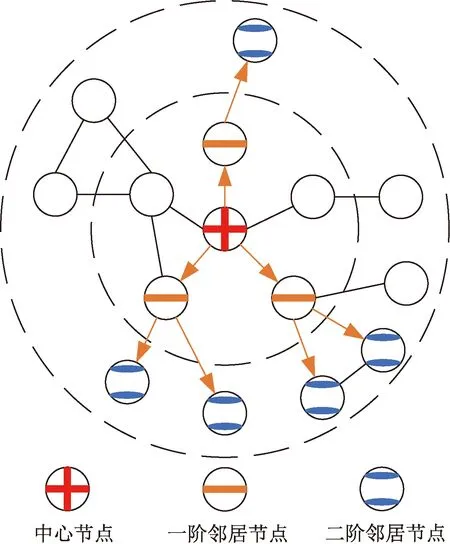
用虚线划分邻居节点所在层次;箭头表示沿着节点之间边的采样方向
步骤2聚合。通过聚合操作可以完成对邻居节点特征的整合输出,聚合时必须要对聚合节点的数量做到自适应,不管节点的邻居数量为多少,聚合后输出的维度必须是一致的。聚合时首先将二阶节点的特征聚合到对应的一阶节点,然后再将一阶节点的特征聚合到中心节点,最后根据聚合出的中心节点特征进行分类。图2为节点聚合示意图,箭头表示沿着节点之间边的聚合方向。
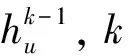
(1)
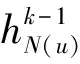
(2)
对k-1层的所有节点执行式(1)和式(2)的步骤,便可得到该层所有节点学习后的特征。继续对k-2层节点执行以上步骤便可得到k-2层所有节点学习后的特征。
两层GraphSage模型的聚合及学习过程如图3所示。
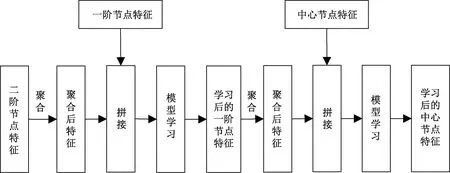
图3 节点聚合及学习过程
步骤3分类。GraphSage将完全学习后的特征首先经过一个全连接层,接着使用LogSoftmax函数分类。设分成m类,xi,c表示经过全连接层后节点i为c类别的初始值,则xi,c的LogSoftmax值pi,c的计算公式为
(3)
式(3)中:pi,c为把节点i预测为c类的概率,得到节点在所有类别上的LogSoftmax值后,最大的值对应的类别即为该节点输出的预测类别。
GraphSage使用交叉熵函数计算损失,计算公式为
(4)
式(4)中:L为损失函数;n为节点个数;i为观测节点;m为类别个数;yi,c为节点i真实类别是否为c类的判决值,只能选0或1,可当常数看。
接着通过梯度下降算法不断优化模型,使得损失函数尽可能最小。
1.2 聚合函数设计
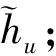
GraphSage中Mean聚合函数按照邻居节点的个数取每个邻居节点特征的均值,其计算公式为
(5)
GraphSage中Max聚合函数逐元素取邻居节点特征的最大值,计算公式为
(6)
对输入图节点的邻接矩阵A,其大小为M×N,即A为一个M行N列的矩阵,记为AM×N。邻接矩阵AM×N表示节点之间的连接关系,若第i个节点和第j个节点之间有连接,那么对应的邻接矩阵元素Ai,j=1,否则Ai,j=0。节点度为该节点与其他节点的连接边数,可以用图的邻接矩阵计算,节点i的度计算公式为
(7)
节点度常用来表示节点在网络中的重要程度或者影响力[12]。王建伟等[13]同时使用节点度和其邻居节点度来衡量节点的重要性,即认为节点及其邻居节点的度越大,该节点在网络中就越重要,含有的信息也可能更多。且一般认为网络中相邻的节点属性相似[14],含有的特征信息也可能相似,而节点之间越相似,其对彼此的影响也越大[15]。因此,所设计的聚合函数根据邻居节点的重要性进行聚合,即邻居节点中的节点度越大,聚合时能够提供更多的信息。
在计算节点重要性时,是在每个节点的邻居节点集合内部单独进行计算,得到的是该节点在所属邻居节点集合内部的重要性,而并非节点在整个图中的重要性。设邻居节点vi的度为dvi,则按照节点度的大小把邻居节点vi的重要性w(vi)定义为
(8)
式(8)中:w(vi)的取值范围为[0,1]。
由w(vi)可以定义所使用的聚合操作。
(9)
从式(9)中可以发现,聚和后特征为各个邻居节点特征以重要性为权值的加权和,特征每个位置上的聚合操作对应为
(10)
针对vi的度dvi,做以下处理。
(11)
式(11)中:D为人为设置的整数参数,用于限制使用的节点度大小,D的取值一般不超过每层的节点采样参数S。
从式(11)中可以看出,小于等于D值的节点度不做处理,将所有大于D的节点度限制为D。适当的D值可以防止聚合时过度聚合具有大节点度节点的特征,保证各个邻居节点的特征都可以有效的参与到聚合中来。
2 实验准备
2.1 实验数据集
使用的Cora、Citeseer和Pubmed为 GCN[10]所使用的3个数据集,数据集下载网址为:https://github.com/tkipf/gcn。
数据集的详细信息如表1所示。其中节点数、边数、特征数及类别数分别表示数据集中总的数据个数、所有节点间总的连接边数、每个节点所具有的特征数及数据集中节点总的类别数。数据集的划分参考GCN[10]中的方式,训练节点数量为数据集中类别数的20倍,验证节点为500,测试节点为1 000。
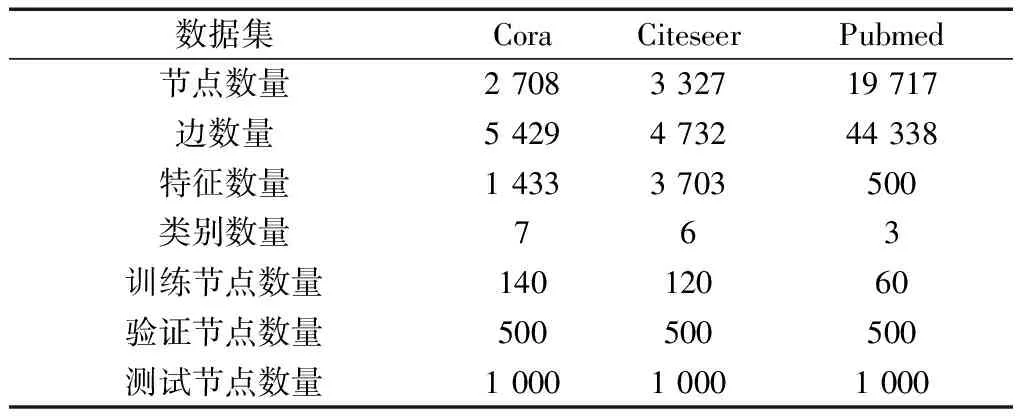
表1 数据集介绍及划分
2.2 实验过程
为了验证GraphSage-Degree的有效性,实验选取了以下方法进行比较。①DeepWalk[4]:通过在图中进行随机游走的方式,对节点采样并学习节点的表示;②LINE[6]:引入了两种节点相似度,构造了节点的邻域;③node2vec[7]:摒弃了DeepWalk中随机游走的方式,定义了深度优先和广度优先两种游走策略;④GCN[10]:图卷积神经网络,对图节点的拉普拉斯矩阵进行了对称归一化;⑤GraphSage-Mean[3]:使用对邻居节点特征均值聚合的GraphSage模型;⑥GraphSage-Max[3]:使用对邻居节点特征逐元素取最大值的聚合方式;⑦Graph-MLP[11]:使用多层感知机构成的节点分类模型。
在实验中,GCN,GraphSage和Graph-MLP的参数设置均参考各自论文,epoch均为100,各个模型所学习的节点特征最终大小,即embedding维度均为128。DeepWalk、LINE和node2vec的其他参数参考张陶等[16]的研究,参数设置如表2所示。

表2 参数设置
2.3 参数D分析
聚合函数中的参数D限制着模型中节点聚合过程中所使用的节点度值,在Cora、Citeseer和Pubmed数据集上分析了不同D值对分类效果的影响,D取值为0~10的整数,D=0时表明不对节点度进行限制,即使用节点原始的度值。不同D值在各个数据集的分类结果如图4所示。
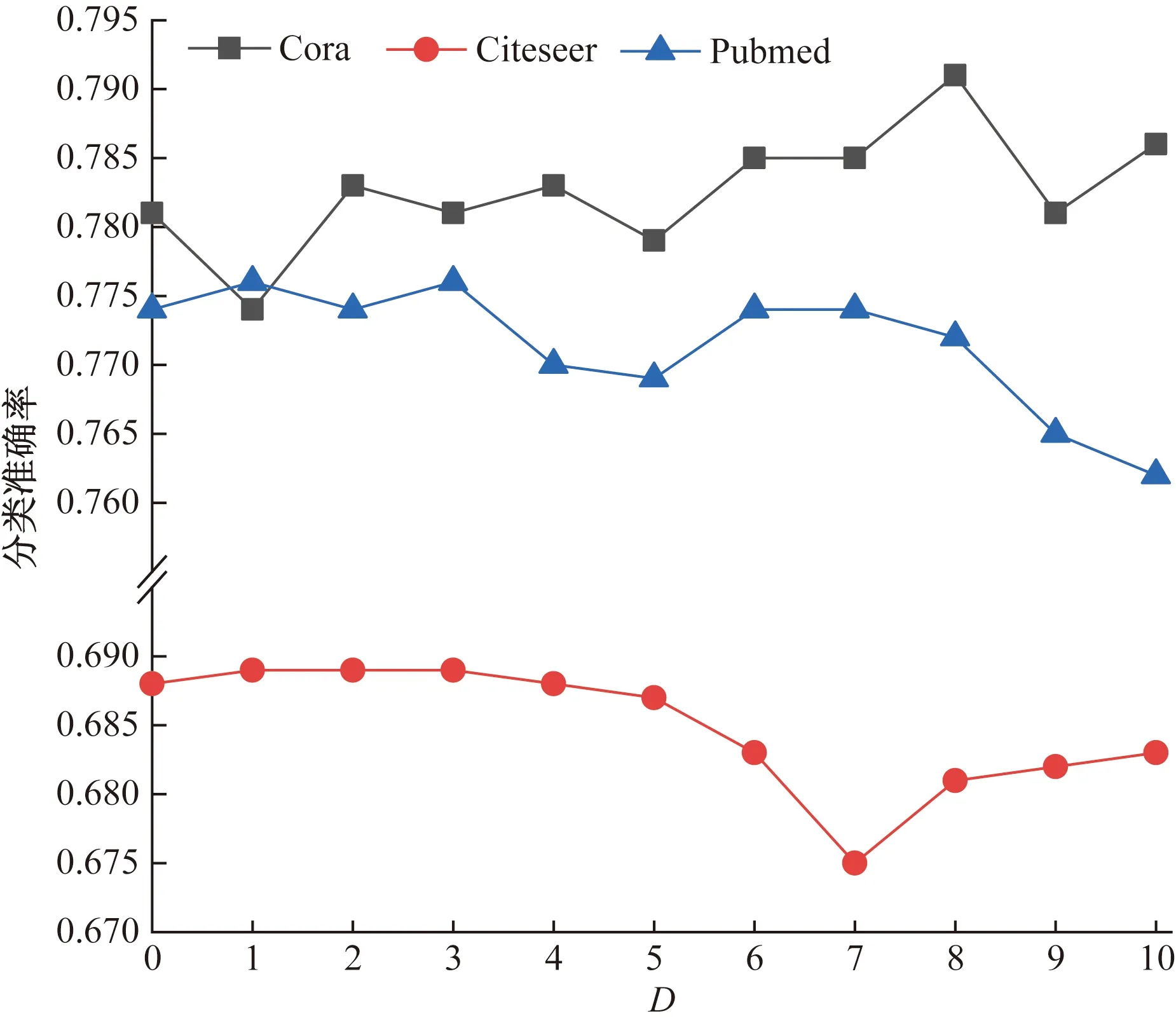
图4 不同D值下的分类结果
在Cora数据集中,最大值和最小值分别在D=8和D=1时取得,差值比例为1.7%;在Citeseer数据集中,最大值和最小值分别在D=3和D=7时取得,差值比例为1.4%;在Pubmed数据集中,最大值和最小值分别在D=3和D=10时取得,差值比例为1.4%;从数据中可以发现,D值并不是越大越好。节点度越大,意味着与该节点连接的节点就越多,也就意味着该节点有更大的可能性与不同属性的节点连接,从而导致其含有的特征信息较为杂乱。如果此时聚合该节点信息时不做处理将会很大概率影响分类效果,而D值就在此起了一个限制大度数节点的作用。因为不同的数据集数据内容不同,节点特征不同,节点度也不尽相同,所以每个数据集对D值的偏好也就不同。
2.4 实验结果及分析
选择macro-F1和micro-F1作为对不同模型进行节点分类效果的评价指标。
对于分类问题,可以根据真实类别与模型预测类别的组合划分为真正例(true positive,TP)、真反例(true negative,TN)、假正例(false positive,TP)、假反例(false negative,FN),如表3所示。
根据表3参数可定义查准率P(precision)与查全率R(recall),可表示为

表3 真实类别与预测类别分类结果定义
P=TP/(TP+FP)
(12)
R=TP/(TP+FN)
(13)
由P和R可以确定F1的计算公式为
F1=2PR/(P+R)
(14)
macro-F1为每一类F1的算术平均,假设数据共有n类,则macro-F1的计算公式为
(15)
对于micro-F1,首先计算micro-P和micro-R,计算公式为
(16)
(17)
则micro-F1定义为
(18)
从式(12)~式(18)可以看出,macro-F1和micro-F1通过不同的方式权衡查准率和查全率,区别在于macro-F1是计算每一个类别F1分数然后求平均,micro-F1是计算所有类别总的查准率和查全率。在分类任务中,micro-F1的值与分类准确率A(accuracy)的值大小相等。
各个模型的macro-F1和micro-F1结果分别如表4、表5所示,在Cora、Citeseer和Pubmed数据集上,本文模型GraphSage-Degree中参数D分别取值8、3和3。
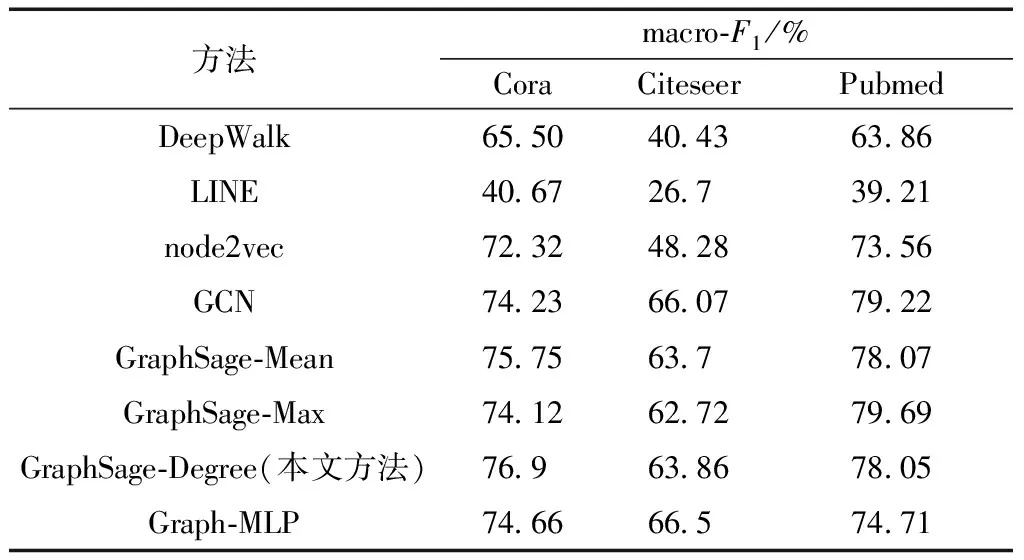
表4 不同方法的macro-F1比较
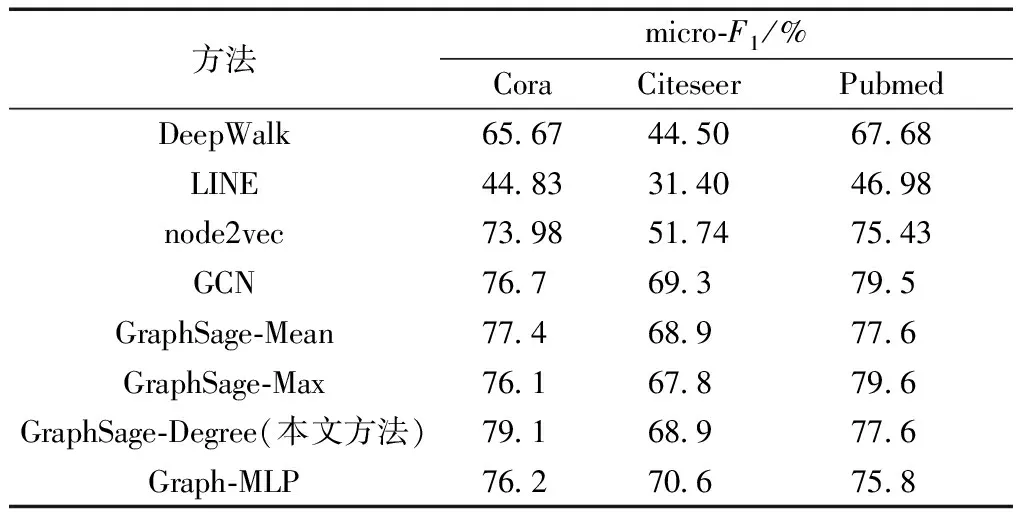
表5 不同方法的micro-F1比较
本文方法与其他方法相比,在Cora、Citeseer和Pubmed数据集上的分类结果提升值及平均提升值和最大提升值如表6所示。
从表6的数据中可以看出,GCN、GraphSage和Grap-MLP模型的效果明显优于DeepWalk、LINE和
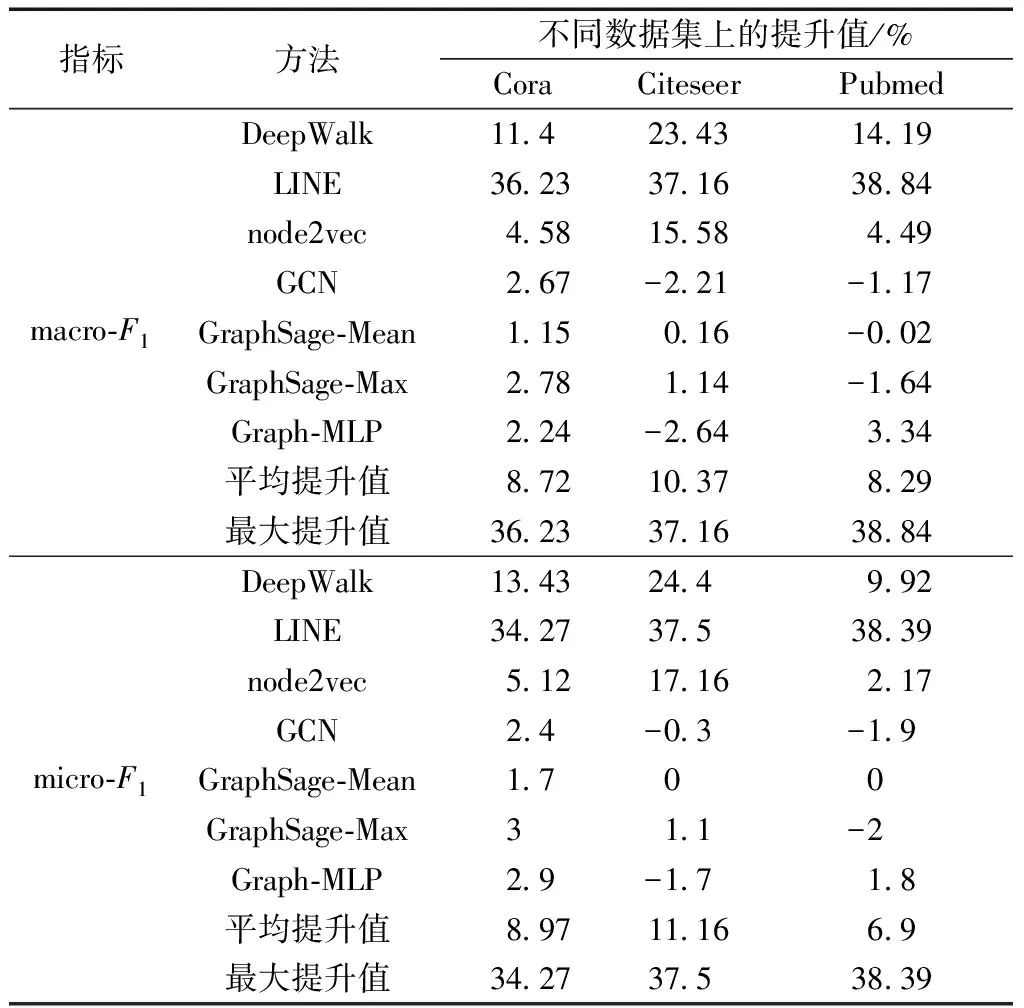
表6 本文方法和其他方法相比的提升值
node2vec等图嵌入算法模型,原因在于图嵌入算法受图结构的影响较大,而且没有充分使用节点的特征信息。在Cora数据集上,本文方法的macro-F1分数高于GCN2.67%,提升比例约为3.6%,高于GraphSage-MLP2.24%,提升比例约为3%,高于Graph-Max2.78%,提升比例约为3.75%;micro-F1分数比GCN高2.4%,提升比例约为3.13%,比Graph-MLP高2.9%,提升比例约为3.8%,比Graph-Max高3%,提升比例约为3.94%。在Citeseer数据集上,本文方法的macro-F1分数比GraphSage-Max高1.14%,提升比例约为1.8%;micro-F1分数比GraphSage-Max高1.1%,提升比例约为1.6%。在Pubmed数据集上,本文方法的macro-F1分数比Graph-MLP高3.34%,提升比例约为4.47%;micro-F1分数比Graph-MLP高1.8%,提升比例约为2.37%。
本文方法与GCN、Graph-MLP和其他GraphSage模型相比,在Cora数据集上的结果要优于Citeseer和Pubmed数据集,可能与Citeseer数据集中节点特征数过大(3 703维),含有信息杂乱,Pubmed数据集中节点特征数过小(500维),难以提取出更有效的特征信息有关。
本文方法在Cora、Citeseer和Pubmed数据集上和其他方法相比,macro-F1的平均提升值分别为8.72%、10.37%和8.29%,在Pubmed上有最大提升值38.84%;micro-F1的平均提升值分别为8.97%、11.16%和6.9%,在Pubmed上有最大提升值38.39%。
3 结论
在GraphSage模型的基础上,提出了基于节点重要性的聚合算法。该方法通过度计算节点的重要性,并根据节点重要性为权值聚合特征信息,分析了不同参数D值下的模型分类效果。与图嵌入算法、GCN、Graph-MLP及其他GraphSage模型相比,本文方法在Cora、Citeseer和Pubmed数据集上macro-F1的平均提升值分别为8.72%、10.37%和8.29%,在Pubmed上有最大提升值38.84%;micro-F1的平均提升值分别为8.97%、11.16%和6.9%,在Pubmed上有最大提升值38.39%。本文方法在Citeseer数据集上取得的macro-F1和micro-F1分别为63.86%和68.9%,在Pubmed数据集上取得的macro-F1和micro-F1分别为78.05%和77.6%;此外,本文方法的macro-F1和micro-F1在Cora数据集上取得了最优成绩,分别为76.9%和79.1%,表明本文模型在网络节点分类上的可行性和有效性。
