基于锐度感知最小化与多色域双级融合的视网膜图片质量分级
2022-12-19梁礼明雷坤詹涛彭仁杰谭卢敏
梁礼明,雷坤,詹涛,彭仁杰,谭卢敏
(1.江西理工大学电气工程与自动化学院,赣州 341000;2.江西理工大学应用科学学院,赣州 341000)
随着计算机辅助诊断技术地快速发展,视网膜图片被广泛应用于眼部疾病研究与诊断任务中,包括糖尿病视网膜病变分级[1]、视网膜血管分割[2-3]等。但由于眼科医师的操作经验与相机规格的不同,导致采集的视网膜图片在质量上存在较大差异。一项基于英国生物银行的研究表明,在眼底图像数据库中超过25%的视网膜图片质量存在问题,以至于眼科专家也无法对其进行精确诊断,而视网膜图片的质量与眼科医师的经验和眼睛的疾病类型密切相关,所以视网膜图片质量分级具有较强的主观性,使得视网膜图片质量分级具有一定的挑战性[4]。
在实际临床场景中,优质的视网膜图片有利于专业人员对患者进行准确的诊断,而模糊严重的视网膜图片,容易增加视网膜病变区域被识别成伪影的概率,对患者造成误诊。因此,高效的视网膜图片质量分级(retinal image quality assessment,RIQA)算法能有效提高医护工作者的工作效率并节约成本,对研究眼部疾病以及诊断具有重要意义。目前视网膜图片质量分级算法大致分为传统算法与深度学习算法。基于传统算法的视网膜图片质量分级大致可分为三类: 一是基于图像的锐度、对比度和光照等通用质量参数;二是基于视网膜血管、黄斑等结构信息;三是基于通用图像质量参数与视网膜结构信息结合。Wang等[5]提出了一种利用支持向量机或者决策树来处理视网膜图片通用质量参数的方法对视网膜图片进行识别。Paulus等[6]根据改进的图像结构聚类方法,对视网膜血管、视盘等结构的边缘锐度进行测量,并通过灰度共生矩阵特征对视网膜图片的图像质量参数进行评估,最后利用支持向量机对视网膜图片质量进行分级预测。基于传统算法的视网膜图片质量分级模型存在手工设计特征的处理过程复杂,不易操作的局限性。
随着深度学习地不断发展,基于深度学习的视网膜图片质量分级算法使视网膜图片质量分级模型的性能得到了显著提高。Yu等[7]结合无监督特征和有监督特征的组合方法在视网膜图片质量分级任务中取得了较大的成功。Pérez等[8]利用深度学习的方法构建了轻量化视网膜图片质量分级模型,其具有成本低,易于部署的优点。Das等[9]先将输入图像划分为图像块,再通过自动编码器提取多尺度特征来构建视网膜图片的稀疏特征,进而检测视网膜图片的异常信息,并通过证明了该方法的有效性。虽然基于深度学习的视网膜图片质量分级算法[10-11]在一定程度上克服了手工设计特征的局限性,但其普遍关注于RGB(red, green, blue)色域空间,忽略了来自于人类视觉的其他色域空间,存在一定的自身缺陷,且分级模型还普遍存在泛化性能不足的问题。
为解决上述问题,利用多色域空间提出了一种基于锐度感知最小化与多色域双级融合的算法用于视网膜图片质量分级。首先利用多个深度特征提取网络学习不同色域的视网膜图片特征,并利用不同色域的特征级和预测级进行双级融合,构建丰富的多色域特征表示。然后利用锐度感知最小化(sharpness aware minimization,SAM)[12]对视网膜图片质量分级模型优化,以期实现在临床诊断中对视网膜图片质量快速筛查的目的。
1 网络模型
基于锐度感知最小化与多色域双级融合的网络结构如图1所示。首先在将视网膜图片输入模型前需对视网膜图片进行色域空间转换,然后采用融合通道注意力机制以及多路径机制的ResNeSt网络[13]对不同色域的视网膜图片进行特征学习。ResNeSt网络先利用多路径机制学习视网膜图片的不同特征表示,再通过分裂注意块聚合视网膜图片的多色域特征上下文信息并赋予特征不同的注意力权重。最后,使用双级融合充分学习视网膜图片的多色域特征。
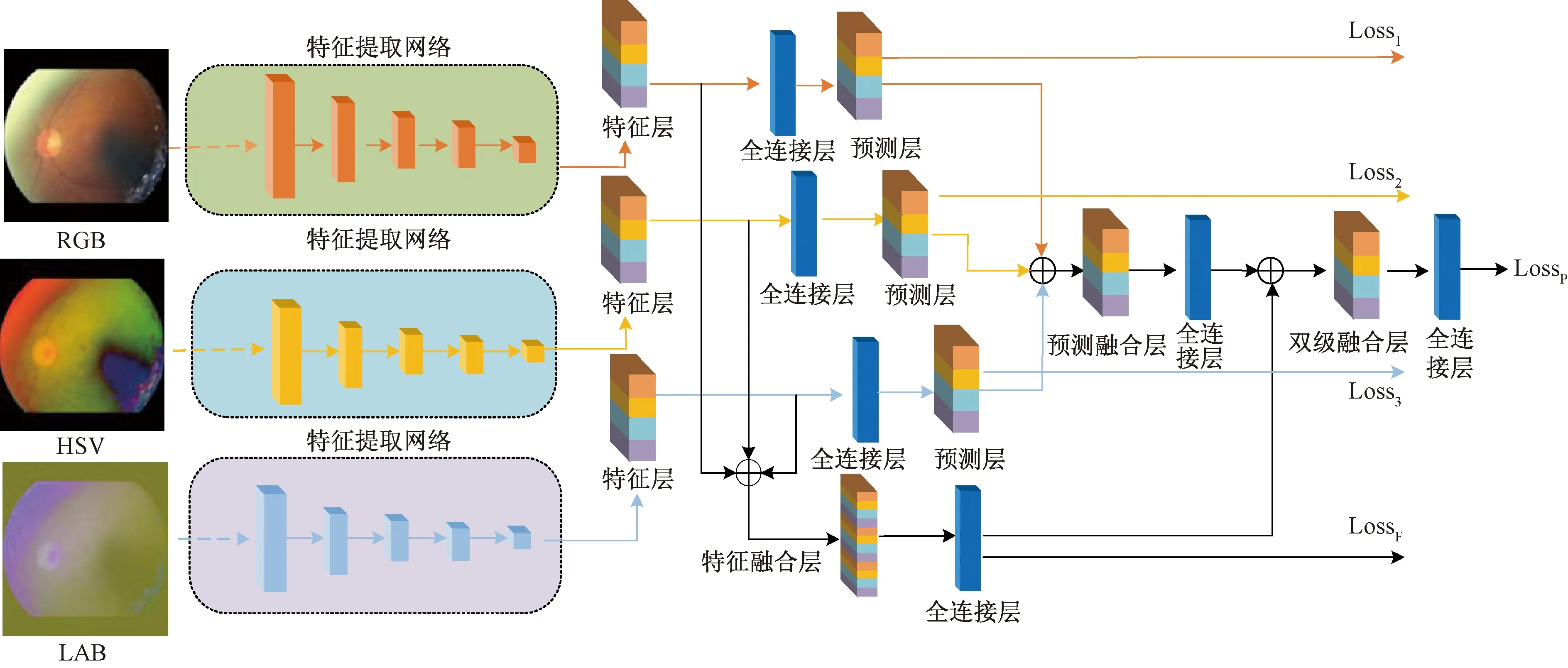
RGB(red, green, blue);LAB中,L表示像素的亮度,A表示从红色到绿色的范围,B表示从黄色到蓝色的范围;HSV中,H表示色相hue,S表示饱和度saturation,V表示亮度value;LossF和LossP分别为特征级、预测级的分类损失;Loss1、Loss2和Loss3表示不同色域空间的分类损失
双级融合先通过对不同色域空间的输出特征进行特征级融合,并对特征融合层进行预测。然后将不同色域空间的预测层与预测融合层进行融合形成双级融合特征。最后使用全连接层对双级融合层进行分级预测。
1.1 ResNeSt网络原理
ResNeSt网络的思想主要来源于多路径网络表示与注意力机制,其中由不同卷积核组成的多路径网络表示已经取得了巨大成功,而SE_Net的通道注意机制能自适应矫正通道特征响应,关注信息量大的特征通道并抑制信息量少的特征通道,并有效减少冗余特征信息[14]。
ReNeSt网络由多个ReNeSt结构块构成,其中ReNeSt结构块通过多路径表示方法将输入特征图分成K个基组,并对不同基组进行不同的分裂变换。接着基组利用不同分裂路径的输出结果与分裂注意块对输入特征图施加通道注意力,最后使用1×1卷积恢复基组的输出通道维度。ResneSt块的结构如图2所示。
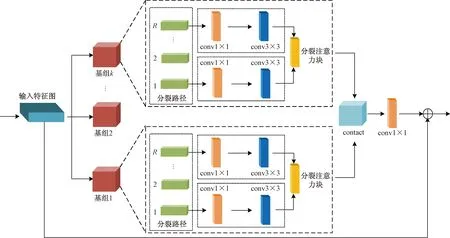
contact表示按照通道维度进行拼接
1.2 分裂注意块
第K个基组Uk由特征图的R个分裂路径求和得到,第k个基组可表示为
(1)
式(1)中:Uj为基组内第j个分裂路径。
基组的输出通过分裂注意力块先对多个分裂路径的输出进行拼接,再通过全局平均池化聚集基组的全局上下文信息sk。
(2)
接着利用全局上下文信息对基组的输出进行加权融合,输出结果为vk,其输出结果的第c个分量为
(3)

(4)
分裂注意块的结构如图3所示。

BN、Relu分别为Batch Normalization层和激活函数
1.3 双级融合
由于本文算法采用RGB、HSV(色相hue、饱和度saturation、亮度value)和LAB(L分量用于表示像素的亮度,表示从纯黑到纯白;A表示从红色到绿色的范围;B表示从黄色到蓝色的范围)3种不同色域空间作为模型的输入,使得视网膜的图片特征具有色域差异。如果仅依靠模型的特征级进行视网膜图片的分级预测,不能充分利用视网膜图片的不同色域特征信息。为解决上述问题,本文算法在融合特征级的基础上引入预测级进行双级融合,用于增强视网膜图片不同色域特征的信息交互,从而使模型充分学习同一视网膜图片的不同色域特征信息。
双级融合首先需要对经过ResNeSt网络输出的不同色域特征按通道维度进行拼接,并使用全连接层进行特征级融合。然后,将不同色域空间的预测级与特征级融合后的预测输出进行级联。最后,通过全连接层对双级融合预测输出进行分级预测。通过双级融合能够充分集成不同色域空间的特征信息。双级融合的优势体现在两个方面,一是充分集成了不同色域空间的特征信息;二能保证特征学习网络的独立性和完整性,使网络模型能根据不同任务需求进行更替。双级融合结构如图4所示。

图4 双级融合模块
1.4 损失函数
不同于现有特征融合网络仅使用单一损失函数的训练方式。本文算法不仅保留了多色域主干网络中的分类损失函数,还在模型的总损失中还引入了特征级与预测级的损失函数,即
(5)
式(5)中:Lossi、LossF和LossP分别为主干网络、特征级与预测级的分类损失;wi、wF和wP分别为各损失值的权重,这里设定为0.1、0.1和0.6,以突出融合预测层的作用。
1.5 锐度感知最小化
对于大多数超参数化模型往往具有多个局部最优解甚至全局最优解,使网络模型的泛化性能具有明显差异。为了提高视网膜图片质量分级模型的泛化性能,采用锐度感知最小化(SAM)对视网膜图片质量分级模型进行优化,其中锐度感知最小化的锐度为参数ω移动到ω+δ过程中,损失值的变化程度。锐度感知最小化优化主要分为两步,第一步计算损失函数在邻域范围δ内损失变化最大时的邻域值;第二步在该邻域范围δ内求解损失函数最小时对应的参数ω,锐度感知最小化的计算步骤可表示为
(6)
(7)
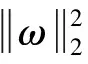
SAM优化方法的伪代码如下。

SAM优化方法 输入:训练集S、损失函数L、批次大小B、学习率η>0、ρ>0输出:优化参数wt,初始化权重ω=0,t为迭代次数,模型还未收敛时,设训练批次大小为BStep 1 计算该训练批次的损失梯度 ωLB(ω)Step 2 估计邻域大小δ^(ω)Step 3 计算SAM最终梯度近似:g= ωLB(ω)ω+δ^(ω)Step 4 更新权重: ωt+1=ωt-ηg;t=t+1
2 数据集及其预处理
2.1 数据集
实验所使用的数据集为Eye-Quality,其视网膜图片来自California Health Care Foundation and EyePACS发布的糖尿病视网膜病变彩色眼底图像数据集,并由Fu等[15]对视网膜图片进行重新标注。数据集样本如图5所示。
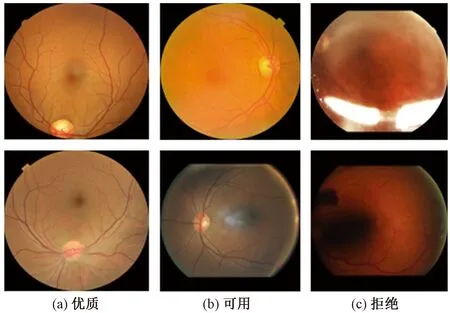
图5 视网膜图片质量差异样本
该数据集采用的是优质、可用和拒绝三级标准。具体质量等级定义如下。
(1)优质。视网膜图片中无影响质量的因素,所有视网膜图片中的病变特征清晰可见。
(2)可用。视网膜图片中存在轻微影响的质量因素,导致不能清晰地观察到整个视网膜图片或者影响正常使用医学分析方法。但其主要结构和病变区域足够清晰且能够被眼科医生识别;
(3)拒绝。视网膜图片具有严重质量问题,不能提供可靠的病变特征信息,即使眼科医生也不能对其准确识别并诊断。
该数据集样本数量分布如表1所示。可以看出,该数据集存在不均衡,因此采用垂直水平翻转、随机漂移和旋转等数据增强方式对视网膜图片样本进行数据增强。

表1 数据集数据分布
2.2 视网膜图片的预处理
由于采集视网膜图片的设备以及工作人员的经验影响,大多数视网膜图片存在大量黑色背景知识,对视网膜图片质量分级没有任何辅助作用。因此在将视网膜图片输入网络模型之前,需裁剪掉多余眼球周围的多余黑色背景,并将图片调整为244×244的统一尺寸,同时将其归一化,其预处理结果如图6所示。

图6 预处理结果
此外,由于视网膜图片的质量问题主要体现在视网膜图片上的明暗程度以及模糊区域,但视网膜图片的RGB色彩空间并不能很好地反映出物体的具体颜色信息,因此本文算法模型引入HSV与LAB色彩空间作为模型的辅助输入,用于提高模型识别视网膜图片质量的影响因素。其中HSV色彩空间能够非常直观的表达色彩的明暗、色调以及鲜艳程度,进而凸显视网膜图片上明暗差异。此外,视网膜图片在RGB色彩空间上还存在色彩分布不均衡的问题,而LAB色彩空间则弥补了RGB色彩空间中蓝色到绿色之间过度色彩多,绿色到红色之间缺少黄色和其他色彩这一缺陷,不同色域空间的转换结果如图7所示。

图7 视网膜图片的色彩空间转换
3 实验内容与结果分析
3.1 实验参数设置
所有实验均基于Ubantu16.04系统下PyTorch1.3.0深度学习框架。计算机配置为Nvidia GeFore GTX2070 GPU,Intel Core TM i7-6700H CPU,16 G内存。CUDA版本为10.0。优化器采用SGD,epoch为20,初始学习率为0.01,batch size为3。
3.2 实验评估指标
为了定量地分析所提的视网膜图片质量分级算法的性能,定义了相关评价指标,即
(8)
(9)
(10)
(11)
式中:TP、TN、FP、FN分别为真阳性、真阴性、假阳性和假阴性样本的数量;σAccuracy为准确率;σPrecision为精确率;σRecall为召回率;Fmeasure为统计量,是精确度和召回率的加权调和平均,常用于评价分类模型的好坏。
3.3 实验与结果分析
3.3.1 泛化性能
为证明SAM优化方法对提高模型泛化性能的有效性,在EyeQ数据集上对SAM优化方法进行了测试。实验分为两组:①仅使用SGD(stochastic gradient descent);②对SGD使用SAM优化。损失函数变化曲线与损失景观图如图8所示。
图8(a)、图8(b)为仅在SGD作用下的训练损失与损失景观;图8(c)、图8(d)为在SGD上使用SAM优化方法后的训练损失与损失景观。通过对比损失变化曲线[图8(a)和8(c)],可发现仅在SGD作用下的模型虽然收敛速度较快,训练过程中波动较大,模型训练不稳定。而SAM与SGD共同作用下的模型虽然收敛速度有所减慢,但模型训练波动较小,且模型训练更稳定。
对比损失景观图8(b)和图8(d)可知,仅使用SGD的模型在训练过程中,尖刺比较明显,即损失变化幅度大,锐度明显。而使用SAM优化后的模型,在寻找最优参数的过程中,变化更光滑,且尖刺减少,锐度得到明显抑制。文献[12]研究表明,损失景观越平坦,模型的泛化性能越强,因此验证了锐度感知最小化优化方法对提高模型泛化性能的有效性。

图8 损失函数变化曲线与损失景观
3.3.2 质量分级性能
将所提的视网膜图片质量分级算法在EyeQ数据集上进行实验,并通过消融实验分析多色域、双级融合以及SAM优化方法对视网膜图片质量分级的影响,消融实验分为7组:①仅保留RGB色域空间;②仅保留HSV色域空间;③仅保留LAB色域空间;④仅保留特征级融合;⑤仅保留预测级融合;⑥不使用SAM优化方法;⑦本文方法。
消融实验结果如表2所示。可以看出,所提出的视网膜图片质量分级方法的准确率为87.35%,精确率为85.87%,召回率与F1分别为85.07%和85.44%。通过消融实验①、②、③与实验⑦进行对比可知,采用单色域输入的模型与本文算法相比,融合了多色域空间的视网膜图片质量分级模型的性能更好。究其原因是多色域空的模型特征信息更丰富,特征表达能力更强。此外,采用LAB色域空间的模型性能与采用RGB色域空间的模型性能差距不明显,由此可证明LAB色域空间对提高模型性能起着重要作用。

表2 消融实验
根据实验④、⑤与实验⑦的对比结果可知,仅依靠特征级的模型与仅依靠预测级的模型相比,依靠特征级的模型更强,其主要是因为特征级比预测级的特征信息更丰富。但仅依靠特征级或预测级的特征融合,其分级性能都未达到采用双级融合后的性能。以此证明了双级融合能有效解决单级融合不能充分利用不同色域空间信息的局限性。
对比实验⑥与实验⑦的对比结果,发现使用SAM方法进行优化后,模型的准确率、精确度、召回率和F1分别增长了0.48%、1.29%、0.06%、0.21%。视网膜图片质量分级模型的整体性能得到进一步优化。
综上所述,改进后的视网膜图片质量分级算法整体上具有更好的分级性能。
3.3.3 与其他质量分级模型进行对比
由于视网膜图片同样属于自然图像,所以除与视网膜图片质量分级方法进行对比,还与自然图像的质量分级方法进行对比。不同质量分级方法的对比结果如表3所示。通过分析对比结果可看出自然图像的质量分级方法NBIQ[16]与TS-CNN[17]在视网膜图片质量分级任务上的分级性能并不突出。究其原因是部分视网膜图片样本模糊严重,且视网膜图片的质量差异不仅仅是由图像失真所引起的。

表3 不同图像质量分级方法的对比
除此之外,基于深度学习的视网膜图片质量分级方法MFQ[7]和MCF[15]与基于传统视网膜图片质量分级方法HSV[5]相比,基于深度学习的视网膜图片质量分级模型的性能更好,其准确率分别高出1.93%和3.50%。而所提的质量分级算法比传统视网膜图片质量分级方法高出3.63%。此外,且本文算法与基于深度学习的方法相比,本文质量分级性能仍然具有一定优势。
3.3.4 可视化结果分析
为了进一步验证所提分级模型的分级性能,针对NBIQ、TS-CNN、MCF以及本文算法的预测结果使用混淆矩阵进行可视化,混淆矩阵的对比结果如图8所示。图9(a)、图9(b)、图9(c)分别为NBIQ、TS-CNN及MCF的混淆矩阵,图9(d)为本文算法的混淆矩阵结果。
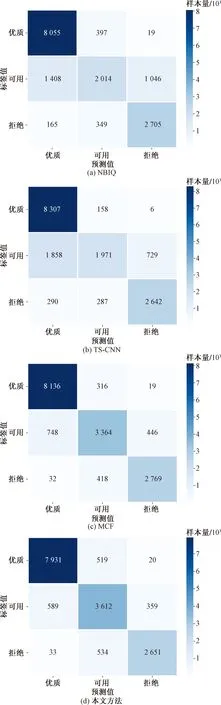
图9 混淆矩阵
通过对比混淆矩阵发现自然图像的质量分级方法在预测视网膜图片质量时,很大程度上会将可用级别的视网膜图片预测为优质或拒绝,其中将可用级别的视网膜图片预测为优质的情况更为严重。
与自然图像的质量分级算法相比,基于深度学习的视网膜质量分级算法能有效提高视网膜图片可用级别的分级准确率,还能减小模型将拒绝级别的视网膜图片判断为优质与可用级别的误差率。进而证明了自然图像的质量分级算法不能直接用于视网膜图片质量分级任务。
通过对比所提分级算法与MCF算法的混淆矩阵结果可看出,虽然所提算法对优质视网膜图片的分级性能低于MCF算法,但本文方法能够较大程度提高可用级别的分级效率,并降低可用级别的样本被预测为拒绝级别的误识别率。由此可看出所提算法能有效提高获取视网膜图片数据的效率,并提高获取的视网膜图片价值。
4 结论
提出了一种基于锐度感知最小化与多色域双级融合的视网膜图片质量分级算法,该算法采用目前先进的ResNeSt网络作为特征提取网络,通过不同色域空间作为互补输入,以及双级融合模块块充分学习同一视网膜图片的差异特征信息,最后采用SAM优化方法对模型进行优化。通过实验得出如下结论。
(1)融合了多路径表示方法与注意力机制的ResNeSt网络具有更强的特征提取能力。
(2)基于多色域空间的双级融合,能有效提升视网膜质量分级性能。
(3)SAM优化方法对于提高模型的泛化性能,有明显效果。
由于该网络模型比较复杂,推理时间长,因此在今后的研究中,将在保证质量分级准确度的前提下,进一步简化模型参数,提升模型的训练效率。
综上所述,所提出的基于SAM多色域双级融合的视网膜质量分级方法,可以在临床诊断中帮助医生提高诊断的效率和准确性,具有一定的临床意义。
