基于主动学习的跨项目软件缺陷预测方法
2022-12-19米文博李勇陈囿任
米文博,李勇,2,3*,陈囿任,2
(1.新疆师范大学计算机科学技术学院,乌鲁木齐 830054;2.新疆电子研究所股份有限公司,乌鲁木齐 830054;3.南京航空航天大学高安全系统的软件开发与验证技术工信部重点实验室,南京 211106)
软件质量保证是软件项目在开发阶段中的重要目标。软件在运行过程中出现失效,可能会造成严重的后果,有时甚至是致命的。其中,软件缺陷是导致软件失效的根本原因。因此,软件缺陷预测技术在软件可靠性工程中有着极其重要的作用[1]。
软件缺陷预测依赖于历史数据,通过对软件结构和代码进行度量,基于机器学习分类器对历史数据进行学习从而构建缺陷预测模型。其中,项目内软件缺陷预测(with-project defect prediction,WPDP)基于当前项目软件数据构建模型,通常会取得理想的预测性能。但在实践场景中,由于缺少足够的训练数据以及数据标注代价较高等问题,使得项目内软件缺陷预测方法无法满足软件工程的需求[2]。为此有研究提出了跨项目的缺陷预测(cross-project defect prediction,CPDP)方法,CPDP基于其他已标注的源项目软件数据训练模型,实现对目标项目的预测,可以有效解决WPDP方法中存在的历史数据不足和标注代价高等问题[3]。在跨项目软件缺陷预测的研究中,已有研究通常基于数据过滤策略解决软件数据间存在的数据漂移问题。但这类方法仅关注于源项目的数据过滤,忽略了目标项目的先验知识,使得缺陷模式匹配不足,对于跨项目预测模型的性能提升有限[4]。
针对该问题,提出一种基于主动学习的跨项目软件缺陷预测方法(active learning based cross-project software defect prediction,ALCP)。采用主动学习算法从目标项目中筛选出对模型贡献度高的数据,对该部分数据进行标注后与源项目进行数据融合,形成增强数据集,并基于朴素贝叶斯(naive Bayes,NB)算法构建软件缺陷预测模型,从而解决缺陷模式难以匹配的问题,使得软件数据满足独立分布的条件[5]。采用真实软件缺陷预测数据集进行实验,为跨项目软件缺陷预测提供了新的思路。
1 相关工作
1.1 基于跨项目的软件缺陷预测
在软件工程中,由于项目间开发过程、开发环境等条件的不同,使得缺陷分布和缺陷的特征空间不同。传统软件缺陷预测在WPDP场景下进行研究,当目标项目是新项目时标记较少,通常采用CPDP进行研究。由于项目间存在不同的分布条件,因此需要对源项目和目标项目之间的数据进行处理后才能进行预测。基于迁移学习的方法来实现CPDP,通常分为两大类:属性特征迁移和模块实例迁移。WPDP与CPDP区别如图1所示。

图1 WPDP与CPDP区别
属性特征迁移是指度量属性通过特征变换使得源项目和目标项目符合相同的独立分布。文献[6]通过调整缺陷预测模型提出了度量属性的补偿方法,不同项目的度量属性取值范围不相同,通过属性补偿可以调整到同一水平。文献[7]对特征映射TCA+(transfer component analysis+)方法和公共度量属性方法进行描述。文献[8]通过构建“最佳属性子集”,结合机器学习模型中的朴素贝叶斯和逻辑回归构建缺陷预测模型,从而使得缺陷预测模型性能和缺陷预测模型构建成本的平衡。文献[9]在源项目和目标项目数据间使用特征转换的方式,使得软件属性特征进行对数转换,去除数据中的离群点进行预测,取得较好的预测效果。
模块实例迁移是指在软件模块实例层对包含缺陷信息丰富的数据进行迁移。目前基于模块实例迁移的文献有:文献[10]使用Burak过滤的方法,通过K近邻(K-nearest neighbor,KNN)算法从源项目中找到与目标项目最接近的训练数据。同时也指出特征不相似的数据在某些条件下也会对模型训练有帮助。文献[11]提出迁移贝叶斯算法。将源项目和目标项目的数据分布作比较,通过数据引力方法计算实例的权重,为数据划分权重,采用加权方式构建训练模型。文献[12-13]通过聚类算法在源项目和目标项目中聚成实例簇,通过相似的聚类建立局部模型实现预测。
现有跨项目软件缺陷预测方法流程如图2所示,该方法可以有效解决传统WPDP中存在的数据不足等弊端,但现有属性特征迁移和模块实例迁移的方法通常从源项目角度进行模型数据的转换或选择,没有充分考虑目标项目的缺陷模式。
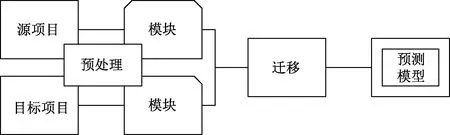
图2 跨项目软件缺陷预测方法整体流程
1.2 基于主动学习的软件缺陷预测
Lewis[14]最早提出了主动学习方法,主动学习关注于降低标注的成本,构建高质量模型数据集。主动学习常用策略有不确定性采样策略、委员会查询策略、随机采样策略、误差缩减策略等。在机器学习模型构建中,通过主动学习对样例进行筛选可以有效提高分类器的性能。
目前在软件缺陷预测研究中,主动学习方法常用于项目内缺陷预测和跨版本缺陷预测研究。项目内获取高质量数据的代表性方法有:Luo等[15]提出了TAL算法(two-stage active learning algorithm),使用聚类方法和主动学习方法对实例进行扩充,得到较好的结果。Li等[16]提出了半监督方法结合主动学习方法。跨版本获取高质量数据的代表性方法有:Lu等[17]提取了缺陷项目历史数据经过特征压缩技术构成训练集,然后结合主动学习策略在前版本中提取模块,实现数据集的扩充。Xu等[18]关注数据分布,将特征映射方法和主动学习方法相结合,提出了HALKP(hybrid active learning and kernel PCA)方法,实验表明通过主动学习获得了预期的预测性能。
现有研究中两种预测方法获取数据的方式不同,但都可以通过主动学习的方法获取高质量的数据,从而有利于软件缺陷模式的匹配、有利于分类器性能的提高。因此,将主动学习引入跨项目软件缺陷预测,通过主动学习获取目标项目的先验知识,解决传统跨项目预测的缺陷模式匹配问题[19]。
2 基于主动学习的跨项目软件缺陷预测方法
传统跨项目缺陷预测是基于源项目构建缺陷预测模型,并没有考虑目标项目的先验知识以及源项目与目标项目之间的缺陷模式。为解决上述问题,提出基于主动学习的跨项目软件缺陷预测方法(an active learning-based approach to cross-project software defect prediction,ALCP)。
2.1 ALCP方法框架
ALCP方法可以解决历史数据不足的问题,利用主动学可以减少大量人工标注,并引入部分目标项目使得源项目与目标项目匹配相似的缺陷模式。ALCP方法整体流程如图3所示。
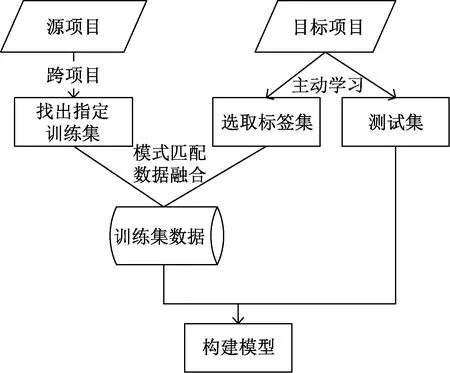
图3 ALCP方法整体流程
算法1ALCP整体框架
输入跨项目特征向量Sfeature(m),目标项目特征向量Tfeature(n)
输出缺陷预测模型的评估指标PD、PF、AUC
步骤1feature(1..k)←Sfeature∩Tfeature
//特征选择得到公共特征
步骤2for i←1 to k do
obtain Strain
//筛选出公共特征对应数据
步骤3ALclassifier=strategyclassifier(Ttrain)
步骤4TLbael=ALclassifier.update(Ttrain)
//筛选样本并标记
步骤5train←TLbael∪Strain //样本合并
步骤6PD,PF,AUC=model.predict(train)
//缺陷预测
步骤7return PD、PF、AUC//得到PD、PF、AUC
在算法1中,首先进行知识迁移,在源项目和目标项目中对特征进行对比,筛选出源项目与目标项目中相同特征所对应的数据,并将经过筛选后的源项目组合作为初始训练集。然后使用主动学习策略对样本进行筛选,所选样本通过主动学习进行标注并加入到初始标签集,其余样本划分为测试集。通过不断选择标记高价值样例,训练集与标签集经过模式匹配,可以使得初始训练集粗糙的超平面迅速进行变化拟合到最终的决策面。最后结合朴素贝叶斯算法进行缺陷预测。
2.2 主动学习算法
ALCP所采用的主动学习策略为不确定性采样策略,该策略通过对信息熵对比的可以筛选不确定性最大的样例从而提高分类器的泛化性能。主动学习标记流程如图4所示。

图4 主动学习标记流程
算法2主动学习算法流程
输入跨项目数据Strain,目标项目T(i)
输出缺陷预测模型的评估指标PD、PF、AUC
步骤1ALclassifier=strategyclassifier(Ti)
//构造主动学习模型
步骤2Strategy=uncertainy(ratio=α)
//选择策略,设定标注比例α
步骤3for j←1 to i do
Strategy each_data
if ALclassifier(Strain)=each_data
Slabel=each_data
//添加标签并加入标签集
步骤4train←Strain∪SLabel
步骤5PD,PF,AUC=model.predict(train)
//进行缺陷预测得到预测结果
步骤6return PD、PF、AUC //得到PD、PF、AUC
根据软件缺陷帕累托法则,设置标注比例为20%,采用不确定性采样策略对缺陷模块的信息熵进行评估,其定义为
(1)
式(1)中:H(x)为随机变量x的熵值;p为概率质量函数;b的取值通常为2、e、10;xi表示标号为i的软件模块x。
由式(1)可以计算软件模块所含信息量的大小,从而找到高信息熵样例进行标注。
主动学习算法可以解决数据没有标签、标注代价高的问题。首先将标签集投放到分类器中,然后对未标签的数据进行预测,可以得到样本被预测为缺陷模块和不是缺陷模块的概率。通过对各样本之间的信息熵进行对比,结合预测概率选出对模型贡献度高的样本进行标注。在真实应用场景下需要对样本进行人工标注,在实验中数据均有标签,因此可以直接得到样本的标签。为了使预测模型达到最终预期的性能,学习模块可以依据主动学习策略筛选出分类贡献率高的样例。从而提升模型性能,并减少对数量巨大的无标签样本标注的代价。在算法2中可以找到有关主动学习方法的伪代码。
3 实验
3.1 数据集
本实验采用美国航空航天局(National Aeronautics and Space Administration,NASA)软件度量数据集,是专门用来对软件缺陷预测模型进行研究的公开数据集[20]。实验采用12个项目进行实验,其中每个软件模块的静态代码度量属性包含McCabe等属性。因为软件缺陷预测为二分类问题,因此将软件缺陷属性离散化,得到两个布尔值0和1。其中,0表示没有缺陷的模块,1表示有缺陷的模块。数据集如表1所示。

表1 数据集描述
3.2 评估
研究软件模块的分类,可以划分为有缺陷的模块和没有缺陷的模块。这是一个二分类问题,将分类学习任务中少量的缺陷模块定义为正例,将分类学习任务中多数没有缺陷的模块定义为负例。由此,混淆矩阵定义如表2所示。

表2 混淆矩阵描述
3.2.1 预测率PD和误报率PF
利用混淆矩阵对类不平衡问题可以做出更加直观的分析,主要目的是提高对软件缺陷模块的识别效率。根据混淆矩阵的定义,预测率PD和误报率PF可分别表示为
(2)
(3)
3.2.2 ROC和AUC
类不平衡问题会对实验结果造成影响,为确保实验的准确性,采用ROC(receiver operating characteristic curve)曲线来对实验结果进行评估[21-22]。ROC曲线通过衡量PD和PF之间的关系来对“期望泛化性能”进行判断。ROC曲线不能直接反映分类器的置信度,较为合理的判断规则是比较曲线所围成的面积。这个指标为曲线下面积(area under curve,AUC)面积越大,性能越好。将AUC的衡量值作为主要比较标准。
3.3 实验模型
本实验中,选用在软件缺陷预测工作中最为广泛使用的两种机器学习分类器:NB和支持向量机(support vector machine,SVM)。朴素贝叶斯分类器确保特征之间不相互依赖,只需要很少的训练样本投入到预测模型中。Menzies确定每个类变量之间的差异,不需要确定整个协方差矩阵,建立基于对数的NB预测模型,得到较好的结果[23]。使用SVM分类器基于二次规划问题,可以提供最佳决策面。SVM分类器可以划分两个类别的边界,并且使用较少的样本建立较好的预测模型。通过调整间隔参数来降低噪音的影响,也可以解决非线性分类的问题。
3.4 实验设置
为选取性能较优的主动学习策略和模型,以及验证本实验结合主动学习匹配相近缺陷模式的有效性,设置以下两类实验。
3.4.1 策略模型构建实验
为了找到跨项目缺陷预测下最佳主动学习策略和算法,采用不同主动学习策略和算法进行对比。实验将跨项目下委员会查询策略记录为Baes1,跨项目下随机采样策略记录为Base2。采用软件缺陷预测中常用的朴素贝叶斯算法和支持向量机算法。
3.4.2 缺陷模式有效性实验
为了验证结合主动学习方法缺陷模式的有效性,设置如下对比试验:传统跨项目缺陷预测实验、传统主动学习缺陷预测实验、传统项目内缺陷预测实验。实验将跨项目缺陷预测记录为Base3,将采用不确定性策略的主动学习缺陷预测记录为Base4,将采用委员会查询策略的主动学习缺陷预测记录为Base5,将采用随机采样策略的主动学习缺陷预测记录为Base6,将传统项目内缺陷预测记录为Base7。
跨项目缺陷预测基于多源数据进行特征选择,在多源项目上直接构建预测模型,然后实现对目标项目的预测。这一过程的关键因素是实现CPDP的过滤实验。主动学习的实验是基于项目内的实验,通过主动学习策略对目标项目进行标注,然后实现对目标项目的预测。这一过程的关键因素是选取最佳主动学习策略。
传统的项目内软件缺陷预测选择已有软件模块的部分数据作为训练集,其余部分作为测试集。通过交叉验证实现对目标项目的预测。这一过程关键因素是选取与之前实现相同的测试集比例,从而保证实验的公平原则。
3.5 实验分析
为了更为直观地表示预测性能,使用盒须图进行更为清晰的展示,图5分别列出了不同实验下PD、PF、AUC的盒须图。

图5 PD、PF、AUC值盒须图
3.5.1 策略模型构建实验分析
主动学习模型构建实验结果如表3所示。可以看出,综合三项指标,最佳策略为不确定性采样策略,最佳算法为朴素贝叶斯算法。

表3 不同策略模型实验结果
在对PD的比较中,基于SVM分类器的ALCP表现出最佳性能。当以NB为分类器,3种主动学习策略表现出的性能较为接近。在对PF的比较中,ALCP所使用的不确定性策略在NB和SVM两种分类器中都具有较低的误报率,并且表现出了相同的低误报率。在对AUC的比较中,3种主动学习策略都表现出了良好的性能,其中ALCP方法在两种分类器中都展现出了最佳性能。综合来看,委员会查询策略和随机采样策略在两种分类器上表现出的较为接近的性能,均低于不确定性策略。综上,ALCP方法表现出较好的性能。
3.5.2 缺陷模式有效性实验分析
缺陷模式匹配前后结果如表4所示。对比缺陷模式匹配前后的变化,结果表明:ALCP在两种分类器上AUC均比传统方式性能好。

表4 不同缺陷模式实验结果
跨项目缺陷预测实验没有直接使用跨项目数据的原因是,这样很可能会导致训练集引入不相关的数据。在数据挖掘中,将这样的数据称为离群点或者噪音。经过特征选择的CPDP过滤器能得到更高质量的训练数据。在PD的比较中,传统跨项目方法和传统主动学习方法在两种分类器上表现性能较差。但是对于指标PF,CPDP均表现出了较好的性能,本文方法ALCP性能略低于CPDP,但也表现出了良好的性能。在AUC的比较中,CPDP和主动学习方法都表现出了良好的性能,但在两种分类器上效果都略低于ALCP方法。对于PD这一性能指标,传统的WPDP表现出优良的性能,但在PF和AUC这两个性能指标上,结果较差。采用ALCP方法在两种分类器上效果均优于WPDP。这也证明了本文方法的有效性。在图5中可以直观地看到,基于ALCP方法性能优于其他方法。
4 结论
(1)在软件工程中,当遇到新项目或者没有足够历史数据的项目时,可以使用主动学习来筛选有价值样本、降低标记代价,使用跨项目软件缺陷预测解决历史数据少的问题。针对源项目与目标项目的缺陷模式难以匹配的问题,提出基于主动学习的跨项目软件缺陷预测方法。使用主动学习方法查询并标记目标项目中对模型贡献度高样本,结合源项目进行数据融合,构建增强数据集实现模式匹配。在NASA数据集上基于朴素贝叶斯算法构建模型,实验结果验证了所提算法具有良好的鲁棒性,可以解决源项目与目标项目的缺陷模式难以匹配的问题。
(2)未来的工作将从以下两个方面展开:一是针对跨项目软件缺陷预测中可能由于商业隐私问题导致的源数据不足,将结合联邦学习进一步探索。二是进一步深入探索主动学习策略与更多的机器学习算法相结合,为软件缺陷预测提供新的视角。
