面向采摘机器人的改进YOLOv3-tiny轻量化柑橘识别方法
2022-12-19汤旸杨光友王焱清
汤旸, 杨光友,2*, 王焱清,2
(1.湖北工业大学农机工程研究设计院, 武汉 430068; 2.湖北省农机装备智能化工程技术研究中心, 武汉 430068)
柑橘人工采摘劳动强度大、效率低,机器人代替人工作业是未来的发展趋势,柑橘识别作为机器人采摘的首要任务,其识别方法的高效精准至关重要。
随着深度学习技术发展[1],基于卷积网络模型的水果识别方法获得了广泛应用,如王丹丹等[2]在ResNet-50和ResNet-101的基础上,改进设计了ResNet-44全卷积网络,并由ResNet-44全卷积网络、区域生成网络以及感兴趣区域子网构成了R-FCN深度卷积神经网络,实现了对于蔬果前期苹果的识别,识别准确率达到95.1%,召回率达到了85.7%,平均每幅图像的识别时间为0.187 s;岳有军等[3]将Cascade RCNN网络中的非极大值抑制算法替换为了Soft-NMS算法对模型进行优化,改进后的Cascade RCNN番茄识别准确率提高了2%,同时也能用于区分番茄的成熟度;吕石磊等[4]采用MobileNet-v2网络作为模型的骨干网络,采用GIoU损失函数改进了YOLOv3的损失函数,建立了YOLOv3-LITE轻量化卷积网络模型,实现了对柑橘的实时识别,平均识别精度达到了91.13%,在高性能GPU下的识别单幅图像所耗时间为16.9 ms,模型占用内存28 MB,通过改进提高了识别精度和识别速度,减少了模型权重所占用内存;赵辉等[5]提出了一种改进YOLOv3的果实识别方法,将DarkNet53网络的残差结构与CSPNet结合,加入空间金字塔池化(spatial pyramid pooling,SPP)模块,采用Soft NMS替换NMS,采用Focal Loss和CIoU Loss联合损失函数对模型进行优化,针对果园复杂环境下不同成熟度的苹果进行识别平均精度均值(mean average precision, mAP)达到了96.3%,F1达到了91.8%,在高性能GPU下的检测速度达到了27.8 帧/s。与传统识别方法[6-7]相比,这类方法减少了对人的依赖,具有复杂场景适应性强、识别精度高等优点[8-13],然而上述文献方法所用网络模型计算量普遍较大,应用于配置性能较差、算力有限的采摘机器人控制系统时,会占用大量的计算资源,识别速度大幅降低,影响控制系统的实时性。YOLOv3-tiny卷积网络模型作为YOLOv3[14]的简化版,网络结构更简单,更适合算力有限的应用场景[15-16],但在一些应用中也存在着识别精度不足的问题。
针对上述问题,提出一种基于改进YOLOv3-tiny轻量化卷积网络模型的柑橘识别方法,用DIOU(distance intersection over union)损失函数[17]替换YOLOv3-tiny原有的损失函数,用MobileNetv3-Small[18]卷积网络替换了主干特征提取网络,并为其添加新的残差结构,在加强特征提取网络中加入了简化的SPP网络结构[19]、深度可分离卷积层集、下采样层以及hard Swish激活函数,以达到减少识别所耗时间、提高识别精度、减小模型占用内存并且能够应用于采摘机器人控制系统的目的。
1 改进的YOLOv3-tiny轻量化卷积网络模型
1.1 YOLOv3-tiny卷积网络模型
YOLOv3-tiny卷积网络模型的主干特征提取网络由七个3×3卷积层和六个最大池化层组成,加强特征提取网络为双尺度结构包含一个上采样层,预测网络有两个输出层,相比于YOLOv3网络模型的结构进行了大幅简化,因此计算量更小、识别速度更快,但也导致识别精度相对较差。如图1所示为YOLOv3-tiny的网络模型结构。

图1 YOLOv3-tiny模型结构示意图Fig.1 Structure diagram of YOLOv3-tiny mode
1.2 基于 DIOU的YOLOv3-tiny损失函数改进
改进的YOLOv3-tiny损失函数主要由定位损失、置信度损失以及分类损失3个部分组成,表达式为

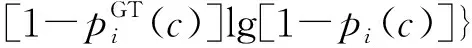
(1)

式(1)的第1行负责计算定位损失值,所采用的就是DIOU(distance intersection over union)损失函数,替换了YOLOv3-tiny原有的边框回归损失函数,第2行和第3行负责计算置信度损失值,第4行负责计算分类损失值。
相比原有的损失函数,DIOU中的IOU能更直接地反映预测框和真实框之间的重合程度,保证预测框在训练中趋向于和真实框的形状一致,中心点距离和对角线长度则能保证在训练中当预测框和真实框还未发生重合时,预测框趋向于和真实框发生重合,避免出现无法重合的情况,因此DIOU能有效提高模型的识别精度。
1.3 YOLOv3-tiny网络结构的改进
如图2所示为改进YOLOv3-tiny网络模型结构。如表1所示为改进YOLOv3-tiny模型结构参数。
1.3.1 主干特征提取网络的改进
如图2、表1所示的1~13层为改进后的主干特征提取网络,主要负责特征信息提取。
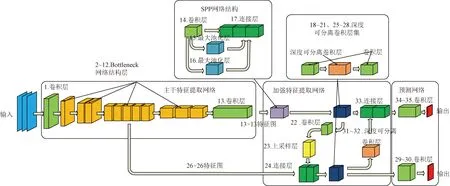
图2 改进YOLOv3-tiny模型结构示意图Fig.2 Structure diagram of improveYOLOv3-tiny model
表1 改进的YOLOv3-tiny模型结构参数Table 1 Improve YOLOv3-tiny network model parameters
采用MobileNetv3-Small作为新的主干特征提取网络,替换了如图1所示的YOLOv3-tiny原有的主干特征提取网络,保证了模型更快的识别速度、更小的计算量以及对设备更低的算力要求。
同时,为了改善MobileNetv3-Small作为主干特征提取网络会降低模型识别精度的问题,如图3所示,在MobileNetv3-Small的bottleneck网络结构层中添加新的包含1×1卷积层和BatchNorm层的残差结构,提升主干网络保留特征信息的能力,减少其特征信息的损失,进一步提高模型的识别精度。

图3 改进MobileNetv3-Small的bottleneck网络结构层Fig.3 Improved MobileNetV3-Small bottleneck layers
1.3.2 加强特征提取网络的改进
如图2、表1所示的14~28、31~33层为改进后的加强特征提取网络,主要负责对特征信息做进一步的处理。
为了更进一步提高模型的识别精度,在如图1所示的YOLOv3-tiny原有的加强特征提取网络中添加了一个仅有9×9和13×13最大池化层的简化空间金字塔池化(spatial pyramid pooling,SPP)网络结构、两个由5×5深度可分离卷积层、1×1卷积层组成的深度可分离卷积层集,然后加入一个由大小为5×5步长为2的深度可分离卷积组成的下采样层,同时将加强特征提取网络中原有的Leaky ReLU激活函数全部替换成了hard Swish激活函数,上述这些新添加的网络结构的具体结构参数分别对应如表1所示的14~17层、18~21层、25~28层以及31~33层。简化SPP网络结构可以通过其中的最大池化层加强模型提取特征信息的能力,同时保留之前主干网络的特征信息,并进行特征融合,深度可分离卷积层集的5×5深度可分离卷积层同样加强了模型提取特征信息的能力,同时又可以减少5×5卷积运算所带来的计算量,其中的1×1卷积层则是为了对提取出的特征进行降维、整合,也起到降低后续卷积运算计算量的作用,下采样层可以将两个尺度间的特征信息进一步融合,而hard Swish激活函数能够提升模型的识别精度且计算量小。
2 改进YOLOv3-tiny模型训练与测试
2.1 柑橘数据集准备
使用深度相机对室内场景中的仿真柑橘进行多角度拍摄,共采集572张图像,利用翻转、平移、尺寸缩放等方法对图像进行数据增强,将图像数量扩增至1 144张。如图4所示为柑橘数据集中的部分图像。

图4 柑橘数据集中的部分图片Fig.4 Part of the citrus datase
使用labelImg标签工具软件对图像中的柑橘进行标注,再将图像和标签文件组成的柑橘数据集按照训练集64%、验证集16%、测试集20%的方式进行划分。
2.2 实验平台
在搭载Windows10系统,硬件为NVIDIA GTX950M 2G DDR3独立显卡、Intel Core i5-4210M双核处理器、4 GB DDR3L内存的笔记本电脑上,基于Tensorflow-gpu、Keras深度学习框架,采用Python编程语言和PyCharm编程工具来搭建模型,并进行模型的训练、测试。
2.3 模型训练
如图5所示,左侧是模型训练、测试流程,右侧是基于模型的柑橘识别方法流程。
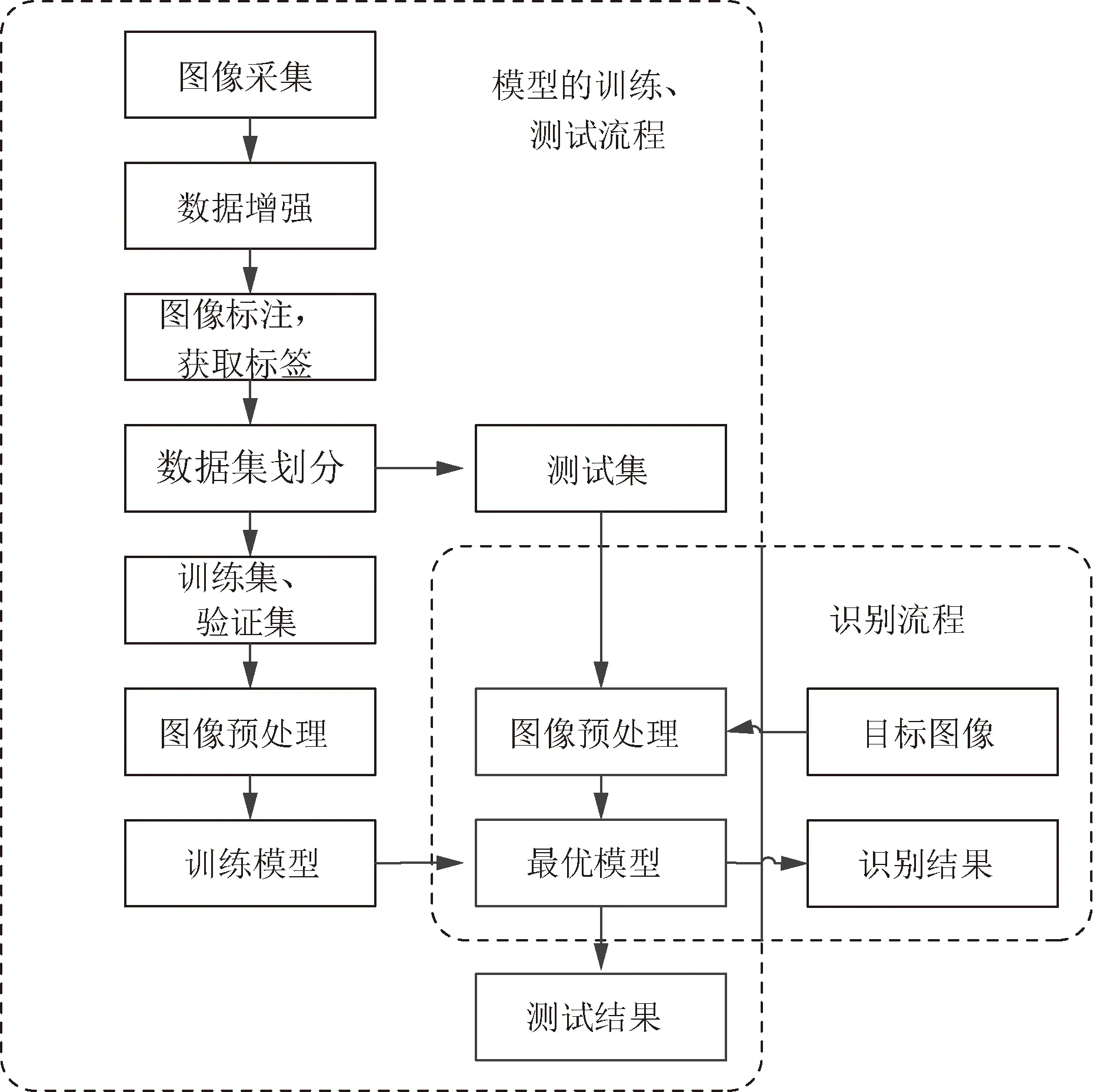
图5 模型训练、测试以及识别流程Fig.5 Model training, testing and recognition method flow chart
模型以小批量样本的方式训练,每批量样本数为8,模型每训练完一次训练集中的图像就称为一次迭代,每完成一次迭代就通过验证集进行一次验证,计算出验证集损失值,模型采用10-3作为初始学习率,学习率会根据学习率阶层下降法来调整,即当模型在训练过程中连续两次迭代损失值都不下降时,学习率将下降到原来的1/2,根据验证集损失值的变化以及当前学习率,通过Adam优化器来反向调整模型的参数,通过不断的迭代来获得最优模型,每迭代一次保存一次模型。
如图6所示,为改进YOLOv3-tiny在训练过程中的损失曲线图。
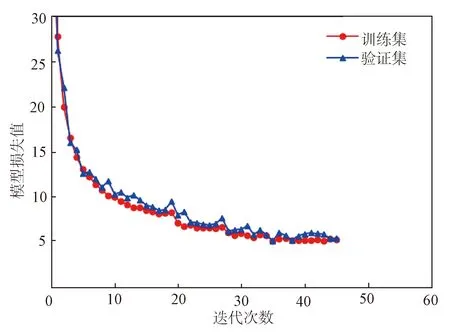
图6 损失曲线图Fig.6 Loss graph
2.4 模型测试
为了测试改进YOLOv3-tiny模型的性能,搭建了原有的YOLOv3-tiny模型作为对比模型。
2.4.1 不同模型之间的性能对比
通过模型的平均识别精度均值(mean average precision,mAP)、F1、识别单帧图像所耗时间、模型权重大小这四项指标来对比模型性能。其中mAP和F1两者共同衡量模型的识别精度,其计算公式为

(2)
根据IOU=0.5将不同的预测框划分成正负样本,TP(true positive)表示正确预测为正样本的样本;FP(false positive)表示错误预测为正样本的样本;FN(false negative)表示错误预测为负样本的样本;P(precision)表示精准度,正确预测为正样本的样本在所有被预测为正样本的样本中所占的比重;R(recall)表示召回率,正确预测为正样本的样本在所有真正为正样本的样本中所占的比重;C表示识别对象的类别数量,mAP的计算实际上就是计算根据不同置信度绘制出的P-R曲线下方的面积,再根据类别数量取平均值。
如表2所示为模型的性能对比结果。

表2 模型之间的性能对比Table 2 Performance comparison between the models
由表2可知:相较于YOLOv3-tiny,改进的YOLOv3-tiny模型的平均识别精度均值mAP达到了96.52%,提高了3.24%;F1达到了0.92,提高了0.03;平均识别单幅图像所耗时间仅为47 ms,减少了24%;模型权重大小仅为16.9 MB,减少了49%,约占YOLOv3-tiny权重大小的1/2。
2.4.2 不同场景条件下的识别情况对比
根据模型的识别结果统计出四种不同场景条件下的柑橘识别情况,计算出正确识别率,其中类别预测准确、预测框定位准确即为正确识别。如表3所示,为不同场景条件下的柑橘识别情况对比。

表3 不同场景条件下柑橘的识别情况对比Table 3 Comparison of citrus recognition in different scenes
由表3可知:相较于YOLOv3-tiny,改进的YOLOv3-tiny在光照充足且未遮挡条件下的柑橘正确识别率为98.6%,提高了0.7%;在光照充足且遮挡条件下的柑橘正确识别率为90.5%,提高了6.5%;在光照不足且未遮挡条件下的柑橘正确识别率为95.8%,提高了3.2%;光照不足且遮挡条件下的柑橘正确识别率为86.8%,提高了7.7%。
2.4.3 识别结果对比
如图7所示,为改进YOLOv3-tiny和YOLOv3-tiny的部分柑橘识别结果对比。
由于图7(a)①中的柑橘离相机较远,目标较小,处于背光环境光照不足,存在柑橘相互堆叠现象,图7(a)②中的柑橘一部分离相机较近目标较大且受到枝叶遮挡,图7(a)③中的柑橘一部分离相机较近目标较大且受到枝叶略微遮挡,一部分离相机较远且受到枝叶严重遮挡,YOLOv3-tiny的识别结果出现了预测框不准确、重复识别、未识别的问题,而在相同条件下改进YOLOv3-tiny的识别结果如图7(b)④~⑥所示,未出现识别错误且预测框更准确,实际识别结果要优于YOLOv3-tiny。

图7 识别结果对比图Fig.7 Comparison of recognition results
根据网络模型的对比测试结果,改进YOLOv3-tiny轻量化柑橘识别方法提高了识别速度和识别精度,减少了模型权重占用内存,在不同场景条件下的柑橘识别效果也有所提升,达到了预期的改进效果。
3 采摘试验
将改进YOLOv3-tiny轻量化柑橘识别方法应用于柑橘采摘试验,通过采摘测试平台识别并抓取仿真柑橘树上随即摆放的30个柑橘,用以验证识别方法在采摘机器人控制系统中的性能。
3.1 采摘测试平台
采摘机器人硬件平台如图8所示,由上位机、深度相机、机械臂及其控制器、柔性手爪及其控制器组成,上位机采用的是与之前模型训练、测试相同的笔记本电脑。

图8 采摘机器人平台Fig.8 Picking robot platform
采摘控制系统程序界面如图9所示。

图9 采摘控制系统程序界面Fig.9 Program interface of picking control system
3.2 采摘试验结果
实验室环境下,基于改进YOLOv3-tiny轻量化柑橘识别方法的采摘机器人平台执行柑橘采摘作业的实际过程如图10所示。

图10 柑橘采摘过程Fig.10 Citrus picking process
实验室环境下,基于改进YOLOv3-tiny轻量化柑橘识别方法的采摘机器人平台在执行柑橘采摘作业过程中的识别测试结果如表4所示。

表4 柑橘采摘测试结果Table 4 Citrus picking test results
根据测试结果可知,改进YOLOv3-tiny轻量化柑橘识别方法能够在算力有限的采摘机器人平台上良好运行,为自主柑橘采摘作业提供识别功能,该方法的实时性、识别成功率均达到了预期效果。
4 结论
(1)提出了一种面向算力有限的采摘机器人平台的改进YOLOv3-tiny轻量化柑橘识别方法,用于识别不同光照条件、不同遮挡情况下的柑橘。该方法用DIOU损失函数改进了原有的损失函数,提高模型的识别定位精度;采用MobileNetv3-Small替换了原有的主干特征提取网络,使模型更加轻量化,提高识别速度;通过在MobileNetv3-Small中加入新的包含1×1卷积层和BatchNorm层的残差结构,使主干网络能够更好地保留之前提取出的特征信息,减少特征信息的损失,从而提高模型的识别精度;在加强特征提取网络加入一个仅有9×9和13×13最大池化层的简化空间金字塔池化SPP网络结构和两个包含5×5深度可分离卷积层、1×1卷积层的深度可分离卷积层集,提升模型提取特征信息的能力,再加入一个由5×5深度可分离卷积组成的下采样层,将两个尺度间的特征信息进一步融合,进而提高模型的识别精度;将加强特征提取网络中原有的Leaky ReLU激活函数全部替换成hard Swish激活函数,进一步提高模型的识别精度。
(2)通过与YOLOv3-tiny在柑橘测试集上的识别效果进行对比,改进的YOLOv3-tiny的平均识别精度均值mAP、F1分别达到了96.52%、0.92,提高了3.24%、0.03,平均识别单幅图像所耗时间、模型权重大小仅为47 ms、16.9 MB,分别减少了24%、49%;通过与YOLOv3-tiny在针对柑橘测试集中处于不同环境条件下的柑橘的识别效果进行对比,改进的YOLOv3-tiny在光照充足且未遮挡条件下、光照充足且遮挡条件下、光照不足且未遮挡条件下、光照不足且遮挡条件下的柑橘正确识别率分别为98.6%、90.5%、95.8%、86.8%,分别提高了0.7%、6.5%、3.2%、7.7%。该方法改进效果显著。
(3)改进YOLOv3-tiny轻量化柑橘识别方法结合采摘机器人平台进行了柑橘采摘试验,柑橘的识别成功率达到了100%,平均识别时间约为47 ms。该方法能够应用于算力有限的采摘机器人平台,为平台提供了一种高效准确的柑橘识别方法。
