考虑贡献率和可信度的测试性试验优化方法
2022-12-14邱文昊连光耀闫鹏程黄考利
邱文昊,连光耀,闫鹏程,黄考利
(1.陆军工程大学(石家庄校区),石家庄 050000;2.中国人民解放军32181部队,西安 710000)
测试性验证是根据装备的技术规范和指标要求,在承制方和使用方风险约束下,综合考虑试验成本、研制周期等因素,采用单次抽样、多次抽样或序贯检验等方法制定验证试验方案,进而判断是否达到规定的测试性水平[1]。
由于现有中国军标规定的测试性试验方法所需样本量较大,相关学者对基于Bayes融合的试验方法开展了研究,文献[2]运用Bayes理论建立了融合先验信息的决策模型,通过定义不确定性和支持度得到加权因子,然后对先验信息进行融合,明显降低了样本量;文献[3]针对测试性试验数据小子样变总体的特点,建立了指标动态增长模型,并结合最大熵原理得到先验分布,依据Bayes最大后验风险准则确定试验方案,提高了评估结果置信度。文献[4]研究了先验分布参数计算方法,提出混合Beta分布的小子样测试性评估方法。然而,上述方法中的系统级先验信息很难直接获取,先验分布权值确定大都依据数据关系或主观经验,没有考虑先验信息来源,导致现有方法的准确性和适用性存在一定问题。
基于此,本文提出了基于分系统先验信息的测试性试验优化方法,通过引入分系统贡献率对先验信息进行折算,得到系统级先验数据;在此基础上提出了基于理想点排序-层次分析法(Technique for order preference by similarity to ideal solution-analytic hierarchy process,TOPSIS-AHP)的先验分布可信度计算方法,确定了先验分布权值;最后,研究了基于截尾序贯后验加权检验(Sequential posterior odd test, SPOT)的试验方法,并给出了截尾阈值计算方法。
1 基于贡献率的数据折算方法
1.1 测试性多源先验信息分析
在装备研制过程中,不同的寿命周期、不同的层次结构、不同的试验手段都会积累多种试验信息,这些信息都可以作为测试性验证试验的先验信息[5]。测试性先验信息的种类较多,从层次结构的角度分为部组件级、分系统级和系统级试验信息;从寿命周期各阶段的角度分为设计阶段信息、生产阶段信息和试验阶段信息;从信息来源的角度分为专家经验信息、虚拟试验信息、摸底试验信息等。测试性多源先验信息分类如图1所示。
本文从信息来源的角度选取用于Bayes融合的测试性先验信息,主要包括以下5种典型的先验信息:
1)专家经验信息。由设计人员或领域专家根据自身经验知识给出的测试性指标评估值,通常是连续区间估计或单侧置信下限估计,此类信息主观性较强。
2)虚拟试验信息。通过搭建装备分系统虚拟样机,利用计算机仿真技术进行测试性验证故障注入试验,代替部分实装故障注入试验,试验结果通常为成败型数据,此类信息的可信度需要考虑。

图1 测试性先验信息分类
3)增长试验信息。部组件或分系统在不用阶段开展的有计划、有继承的测试性试验,各阶段的试验数据服从不同总体,属于“异总体”情况,通常为成败型试验数据。
4)单元摸底试验信息。在设计研制阶段进行的针对某些部组件或分系统的摸底试验,可信度较高,可以向上综合为系统信息,多为成败型试验数据。
5)相似装备历史信息。许多装备的设计研制具有继承性,相似装备测试性水平是十分重要的历史信息,可以作为新型号装备的先验信息,通常表示为指标区间估计或单侧置信下限估计。
不同先验信息具有不同的数据形式,为有效利用多源先验信息,需要将不同的数据形式折合为成败型试验数据,相关文献已经给出了详细的成败型试验数据折合方法[6],这里不再赘述。通常采用Beta分布作为成败型试验数据的先验分布[7],分布形式为
(1)
式中:p为检测/隔离率,a,b为分布超参数。
1.2 分系统贡献率确定
不同分系统在装备对测试性指标评估的影响是不同的,借鉴装备体系贡献率评估中的计算方法[8-9],依据不同分系统的测试性指标分配值计算分系统贡献率,通过指标分配的不同表示在测试性验证评估中,分系统对指标评估的作用大小。
定义1贡献率ci,在测试性指标评估中,分系统指标作为贡献者,系统指标作为受益者,待测系统的分系统指标的增加或减少对系统指标变化的贡献程度为分系统贡献率,表达式为

(2)
第i个分系统的测试性指标分配值为
(3)
式中:γi为测试性指标分配值,λs为系统的总故障率,由故障模式及危害性分析(Failure mode, effects and criticality analysis,FMECA)确定[10],γr为系统测试性指标要求值,λi为第i个分系统的故障率,k为分系统数量。
由分系统指标计算系统指标时,主要考虑诊断能力问题,即发生和诊断的故障次数或相对故障率,则由测试性指标分配值得到的系统指标值为
(4)
则第i个分系统的贡献率为
(5)
1.3 基于信息论的先验分布折算
在可靠性综合评估中,由信息量等效原则和信息量可加性可知,分系统可靠性试验提供的信息量与系统的总信息量相等[11]。在测试性验证中,信息量等效的方法也应用于虚拟试验数据向实装试验数据的折合[12]。基于此,结合分系统贡献率,提出基于分系统贡献率和信息论的数据折算方法。

(6)
设折合后的第i个分系统的成败型试验数据为(ni,fi),其中ni为试验总次数,fi为试验失败次数。根据信息量可加性,k个分系统全部试验的总信息量为
(7)
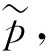
(8)

(9)
结合各分系统贡献率和测试性指标的极大似然估计值,可得各先验信息对应的系统测试性指标估计值为
(10)
根据信息量等效原则,即Iss=Ist,则可得k个分系统的成败型试验数据向系统级成败型数据的折算公式为
(11)
2 基于可信度的混合先验分布
2.1 先验分布可信度
为保证有效利用先验信息,需要检验先验信息和实装试验数据的相容性。已知先验分布π(p)的类型为Beta分布,采用贝叶斯置信区间估计的方法进行相容性检验。设π(p)的贝叶斯置信区间为[p1,p2](置信度为1-αh),其中,p1,p2由式(12)确定。
(12)
即使先验信息满足相容性检验条件,其获取方式和数据处理过程的可信程度仍不明确,在用于测试性试验前需要评估其可信度。通常,实装试验数据的可信度最高,以实装数据为基准,用先验分布和实装试验数据分布函数的相似性度量表示先验信息的可信度。设X为实装试验样本,Y为先验信息试验样本,给出如下假设:
(13)

(14)
定义2先验分布可信度ρ,指接受H0的条件下H0为真的概率,表示X与Y来自相同总体的概率,即X与Y的相似程度,其表达式为
(15)
2.2 基于TOPSIS-AHP的先验分布融合
式(15)中,两类错误概率αh、βh由承制方和使用方协商确定。P(H0)为先验相似度,指在获得先验信息前,先验信息与试验信息属于相同总体的概率,与信息获取途径、数据处理方法、试验方法等多种因素有关,实质上反应的是对先验信息来源和类型的信任程度,属于多准则综合评判问题,很难直接通过显式定量计算,在无法获得先验相似度信息时,通常取P(H0)=0.5。

(16)
则先验信息与理想解的贴近度为
(17)
依据先验信息贴近度,采用三标度层次分析法[15]对先验信息信任程度进行两两比较,建立比较矩阵A=[aij]n×n,信任程度序列指数为
(18)
设信任程度判断矩阵为S=[sij]n×n。令umax=max(ui),umin=min(ui),则
(19)
式中,bm为基点比较标度。
对判断矩阵S进行按行求和,并进行标准化后可得各先验分布的P(H0)值,代入式(15)可得先验分布可信度ρi。
设有r种先验信息通过了相容性检验,其可信度为ρi,i=1,2,…,r,可得混合先验分布为
(20)
3 基于分系统先验信息的试验方案
3.1 试验方案设计流程
基于分系统先验信息的测试性试验方案设计流程如图2所示。

图2 试验方案设计流程
首先,由分系统先验信息和贡献率,通过分系统数据折算得到系统级先验信息;然后,对先验信息进行相容性检验,并通过计算先验分布可信度得到先验分布权值;最后,基于混合先验分布,采用序贯验后加权检验(SPOT)法进行试验方案设计。
3.2 序贯验后加权检验试验方案
相比于单次抽样方法和序贯概率比检验(SPRT)方法[16],融合先验信息SPOT法可以有效减少试验样本量[17],故采用SPOT方法进行试验方案设计。设试验方案约束条件为:最低可接受值p0,设计要求值p1,承制方风险α,使用方风险β。
设测试性指标p的检验假设为:H0:p∈Θ0,H1:p∈Θ1。其中,Θ0={p|p≤p0},Θ1={p|p≥p1},Θ=Θ0∪Θ1为参数空间。
则对于实装试验结果为(n,c)的样本X=(X1,X2,…,Xn),验后加权比[18]为
(21)
检验准则为:当On≤A时,采纳假设H0,判为拒收;当On≥B时,采纳假设H1,判为接收;当A (22) (23) 上述判决准则可能会一直出现A (24) 令Ma=h-1(A),Mc=h-1(C),Mb=h-1(B),则由截尾判决造成的承制方和使用方风险增量分别为: (25) (26) 由Bayes后验风险准则[19],对于给定的风险增量上界αsπ0和βsπ1,将确定截尾阈值转化为以下优化问题: s.t. Δαsπ0≤αsπ0 Δβsπ1≤βsπ1 Ma (27) 将式(27)的优化结果代入式(24)即可得到检验点C。 某航空装备控制系统由4个分系统组成,分别为控制功能分系统、发射功能分系统、通信功能分系统和导航功能分系统。以故障检测率(Fault detection rate,FDR)为例进行测试性验证试验方案设计。根据装备测试性设计要求确定SPOT试验方案的约束条件为:最低可接受值p0=0.85,设计要求值p1=0.95,双方风险α=β=0.1,截尾方案中风险增量上界αsπ0=βsπ1=0.01。 由文献[6]的数据等效模型可得各分系统先验信息的成败型试验数据见表1。 表1 分系统的成败型试验数据 表2 系统先验分布参数 依据基于TOPSIS-AHP的先验分布融合方法可得先验分布的可信度矩阵ρ=[0.930 6,0.667 2,0.686 6],进而可得先验分布取值向量为[0.402 8,0.290 7,0.301 2]。 由式(20)可得混合先验分布为 (28) 图3为先验分布函数,以及考虑先验分布可信度和未考虑先验分布可信度的分布函数曲线。 图3 先验分布函数 将试验约束条件和混合先验分布代入式(22)、(23),可得判决阈值A=0.024 0,B=1.950 1。根据风险增量约束,可得截尾SPOT方案的截尾次数为43,此时检验点C=0.253 5。 对控制系统进行实装故障注入试验,设当前试验结果为(ni,ci),代入式(21)可得当前试验方案的验后加权比值,与判决阈值进行对比,即可得出判决结果,判决过程如图4所示。 图4 SPOT判决过程 在相同试验约束条件下,采用同为序贯类试验方案的SPRT方法的判决过程如图5所示。 图5 SPRT判决过程 由图4可以看出,对于基于可信度融合的判决过程,当试验结果为(N,C)=(36,2)时,做出接收判决;对于直接融合的判决过程,当试验结果为(N,C)=(38,2)时,做出接收判决。由图5可以看出,当试验的成功失败数为(N,C)=(42,2)时,做出接收判决,此时试验样本量为42。 对控制系统进行多次试验,分别采用SPRT、SPOT方法进行判决,均做出接收判决,不同失败次数下的试验次数对比见表3。 表3 不同失败次数下的试验次数对比 为进一步验证该方法的有效性,在相同的试验约束条件下,分别采用经典定数抽样试验方案、文献[2]传统Bayes试验方案和文献[20]的改进Bayes试验方案,各方案的对比分析结果见表4。 表4 不同试验方案对比 根据上述试验结果,从先验信息获取、先验分布权值、试验样本量、双方风险4个方面对比分析本文试验方案的总体性能: 1)先验信息获取。由表1、2可知,本文方法可以有效实现分系统试验数据折算,与文献[20]方法相比,考虑了分系统贡献率,使得数据折算更为合理。 2)先验分布权值。基于可信度确定权值为[0.402 8,0.290 7,0.301 2],文献[2]方法确定权值为[0.293 5,0.313 6,0.392 8],文献[2]确定的虚拟试验信息和专家经验信息权值较大,而本文方法确定的单元试验信息权值较大,相对不准确的专家经验信息权值较小,更符合试验实际情况。由图3也可以看出,直接融合先验分布(先验分布权值相等)得到的指标点估计值小于基于可信度的方法,这是因为专家经验对指标的估计比较保守,但其可信度较低,若直接融合先验分布,导致可信度较低的专家经验数据一定程度上湮没可信度较高的单元试验数据,使得专家经验对评估结果产生的影响较大,导致融合结果过于保守。由图4(b)和表3也可以看出,直接融合先验分布的试验方案在相同失败次数下所需的样本量更多,导致评估结果过于保守。 3)试验样本量。由表3可以看出,同为截尾序贯试验方案,在相同判决结果下,基于可信度融合先验分布和直接融合先验分布下的SPOT试验方案与SPRT试验方案相比,样本量分别平均减少18.6%和13.1%;由表4可以看出,传统定数抽样方案得到的样本量普遍比较大,经典试验方案为(60,5),文献[2]的方案为(38,0),文献[20]的方案为(34,0),在相同约束条件下,与Bayes试验方案相比,本文试验方案所需样本量平均减少61.1%。 4)双方风险。对于基于可信度的SPOT方案,试验方案(14,0)即可在满足双方风险的条件下做出接收判决,而对于表4中的传统定数抽样方案,若采用(14,0)方案,其使用方风险分别高达0.51、0.36、0.27,均无法满足双方风险要求。 1)在分析多源先验信息的基础上,定义了分系统贡献率,并基于信息量等效原则进行数据折算,为获取系统级先验分布提供了有效途径。 2)采用TOPSIS-AHP方法计算先验相似度P(H0)能从先验信息来源的角度给出合理的计算可信度的方法,得到的混合先验分布更加准确。 3)从先验信息获取、先验分布权值、试验样本量、双方风险4个方面进行对比分析,表明该试验方案能够有效解决系统级先验信息获取难的问题,确定的先验分布权值更合理,而且可以有效降低试验样本量和双方风险。3.3 截尾序贯验后加权检验试验方案
4 案例分析
4.1 分系统数据折算



4.2 先验分布权值确定

4.3 试验方案设计



4.4 试验结果对比分析


5 结 论
