基于AlphaZero 的不围棋博弈系统研究
2022-12-11高彤彤丁佳慧舒文奥阴思琪
高彤彤,丁佳慧,舒文奥,阴思琪
(北京信息科技大学 计算机学院,北京 100101)
0 引言
作为2012 年出现在大学生博弈大赛[1]中的一种新棋种,不围棋迅速在博弈比赛中流行起来。一般情况下,对围棋的基本理解是消灭敌人取得胜利,而不围棋则与其相反。不围棋的规则不允许有棋子死亡,无论是哪一方自杀、或是吃掉了对方的棋子都会判负。这种规则看似不合理,其实是要求玩家在和平中取胜,最后依然是比较双方占地盘的多少。从某种角度来说,不围棋更符合中华传统文化中“和为贵”的思想。在此背景下,本文提出了基于AlphaZero 的不围棋博弈系统[2],通过不断自我学习提高棋力。
1 研究现状
计算机博弈,历来是人工智能的一个重要的研究领域,早期人工智能的研究实践,正是从计算机下棋开始。从1997 年的“深蓝”,再到2016 年谷歌公司研发的阿尔法围棋战胜围棋世界冠军,计算机博弈取得了可观的成就。在这期间,蒙特卡洛思想的UCT(Upper Confidence Bound Apply to Tree)算法曾在围棋人工智能领域主导很长时间。人们围绕蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)算法始终在做改进和研究,从而不断提高围棋棋力。
不围棋作为研发时间不长的新棋种,相关研究较少。最早对不围棋的研究报道出现在2011年,通过对比围棋发现,MCTS、快速评估、UCT 等方法在不围棋中同样有效。文献[3-4]都是利用MCTS 解决不围棋问题。文献[3]在启动MCTS 算法时,优先对评分较高的局面进行模拟,通过这种方法来尽可能减少模拟次数。文献[4]为克服MCTS 计算复杂的问题,利用不围棋博弈本身特点,构建了价值评估模型和函数,递归实现不围棋人工智能。文献[5]提出在对弈过程中进行UCT 树的重用,可以增加5%~30%的搜索深度。
本文基于AlphaZero 对不围棋博弈进行研究,使用深度神经网络和MCTS 搜索组合形成强化学习框架,不断自我对弈学习博弈知识,优化损失函数,提升不围棋博弈棋力。
2 不围棋及其规则[6]
2.1 棋盘
不围棋使用9×9 棋盘,分别用字母和数字表示横纵坐标,棋子位置形如C4、E1。棋盘表示如图1所示。

图1 棋盘表示Fig.1 Representation of a chessboard
2.2 棋规
(1)黑棋先行,之后黑白交替落子,落子后棋子不可移动。
(2)对弈的目标不是吃掉对方的棋子,不是像围棋那样围空占领地盘,相反,如果一方落子后吃掉了对方的棋子,则落子一方判负。
(3)如果一方在棋盘上某个交叉点落子后,该棋子将呈现无气状态,相当于自杀,落子自杀一方判负。
(4)不围棋对弈中,禁止空手(pass),空手一方判负。
(5)如果有时间限制的,超时一方判负。
(6)对弈结果只有胜负,没有和棋。
3 基于AlphaZero 不围棋博弈系统的设计思想[7]
基于AlphaZero 不围棋博弈系统主要分为3 个阶段:自我对战学习阶段,训练神经网络阶段和评估网络阶段。对此拟做研究分述如下。
3.1 自我对战学习阶段
3.1.1 自我对战
自我对战学习阶段主要是蒙特卡洛树搜索进行自我对弈,产生大量棋局样本和胜负关系的过程,由于AlphaZero 并不使用大师的棋局来学习,而在没有对战数据基础的前提下训练效率不高,因此需要蒙特卡洛树搜索进行自我对弈得到训练数据用于后续神经网络的训练。在自我对战学习阶段,每一步的落子是由MCTS 搜索来完成的。在MCTS 搜索的过程中,遇到不在树中的状态,则使用神经网络的结果来更新MCTS 树结构上保存的内容。而每一次的迭代过程中,在每个棋局当前状态s下,每一次移动使用1 600 次MCTS 搜索模拟。最终MCTS 给出最优的落子策略π,这个策略π和神经网络的下一步输出p是不一样的,此时的神经网络还没有进行训练。当每一局对战结束后,可以得到在s棋局状态下,使用落子策略π 最终的胜负奖励z,z为1 或者-1,这取决于游戏的胜负,如此一来,就可以得到非常多的样本(s,π,z),这些数据可以用来训练神经网络。
3.1.2 蒙特卡洛树搜索[8]
MCTS 就是用来自对弈生成棋谱的。MCTS 树中保存的数据包括N(s,a)、W(s,a)、Q(s,a)、P(s,a),分别表示状态s下可行动作a被选中的次数、总的行动价值、平均行动价值、可行动作a的先验概率。搜索过程主要由选择、扩展求值、仿真回溯三部分组成,经过多次模拟后落子。这里对此将给出阐释论述如下。
(1)选择:选择平均行动价值与总行动价值之和Q(s,a)+U(s,a)最大的action搜索分支,U(s,a)和Q(s,a)的计算公式如下所示:

其中,s为搜索树的一个节点代表的棋局状态;a表示某一个可行的动作;N(s,a)表示状态s下可行动作a被选中的次数;P(s,a)表示状态s下的可行动作a的先验概率;Q(s,a)表示状态s下可行动作的平均动作价值;W(s,a)表示状态s下可行动作的总动作价值;puct表示一个决定探索程度超参数。
(2)扩展和求值:当棋局还没有结束且当前结点为叶子结点时,就需要进行扩展。扩展的新的结点作为当前结点的子结点,将当前局面输入神经网络得到向量p和胜率v。由此得到的数学公式为:

(3)仿真回溯:如果已被扩展的局面进行选择操作分出了胜负,或者未扩展的局面执行扩展操作,则将胜率回传给上一层,对上一层的值进行更新,被选中的次数加1,总的行动价值加v,并重新计算平均行动价值。此时需用到的数学公式分别如以下公式所示:

其中,st表示搜索树中当次被遍历路径上节点对应的棋局状态;at表示搜索树中当次被遍历路径上节点对应棋局状态下选择的动作;v表示搜索树中当次被遍历路径上节点的价值,由于搜索树中相邻2 层的落子方是不同的,因此相邻2 层的节点价值互为相反数。
(4)落子:往棋盘上落一个棋子之前,会进行1 600次模拟,每次模拟都包含上面的3 个步骤,在此基础上MCTS 才会做出真正的决策。文中推导得到的公式可表示为:

其中,τ为温度参数,控制探索的程度。τ越大,不同走法间差异变小,探索比例增大。反之,则更多选择当前最优操作。在零狗中,每一次自我对弈的前30步,参数τ=1,即早期鼓励探索。游戏剩下的步数,该参数将逐渐降低至0。如果是比赛,则直接为0。
3.2 训练神经网络阶段
3.2.1 局面描述
使用4 层9∗9 的二维特征描述当前局面。9∗9 表示棋盘大小。各层的数学表述具体如下。
(1)第一层:表示当前棋局。
(2)第二层:表示白子当前所占的位置。
(3)第三层:表示黑子当前所占的位置。
(4)第四层:表示哪一方先下棋,如果该下黑子,则矩阵全部等于1;如果该下白子,则矩阵全部等于0。
以图2 局面为例,分析4 层特征,即如图3 所示。
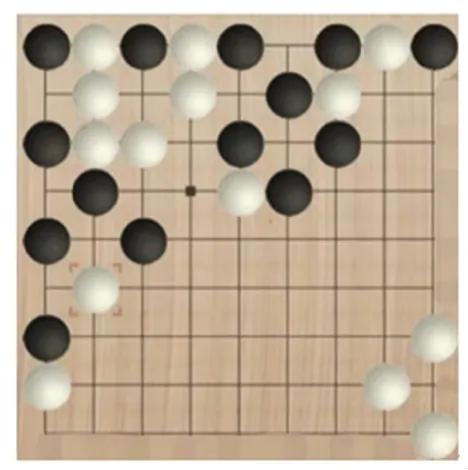
图2 局面描述Fig.2 A description of the situation

图3 各层特征详解Fig.3 Detailed explanation of the characteristics of each layer
3.2.2 网络结构描述[9]
策略价值网络训练流程如图4 所示。使用卷积神经网络(Convolutional Neural Network,CNN)进行策略价值网络的训练。CNN 结构比较简单,由公共网络层、行动策略层和状态价值网络层构成。AlphaZero 需要策略网络输出各个动作先验概率以及价值网络评判当前棋局状态的好坏。在AlphaZero 中策略网络和估值网络共享一部分的卷积层,共享的卷积层为3层,分别使用32、64、128 个3×3 的filter,使用relu激活函数,此后再分成策略policy和价值value两个输出。在policy这一端,先使用4 个1×1 的filter 进行降维,再接一个全连接层、内有81 个神经元,使用softmax非线性函数直接输出棋盘上所有可能的走子概率。在value这一端,先使用2 个1×1 的filter 进行降维,再接一个全连接层、内有64 个神经元,最后再接一个全连接层,使用tanh 非线性函数输出局面评分。
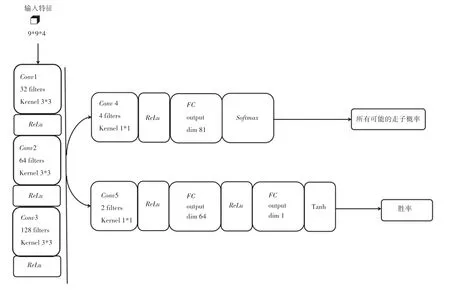
图4 策略价值网络训练流程图Fig.4 Strategy value network training flow chart
该方法既能避免人工设计复杂的静态评估函数,又能较好地解决传统的智能博弈程序中搜索用时巨大、智力水平受程序编写者对博弈技巧理解水平的限制的问题。
3.2.3 最小化损失函数
神经网络的输入为当前的局面s,输出为下一步行动的概率p和对于当前局面胜率的估计v。在训练神经网络阶段,使用自我对战学习阶段得到的样本集合(s,π,z),训练策略网络和价值网络的模型参数。训练的目标是让策略价值网络输出的当前局面下每一个可行动作的概率p更加接近蒙特卡洛树搜索输出的概率π,让策略价值网络输出的局面评分v更加接近真实的对局结果z。在自我对弈数据集上不断地最小化损失函数,如式(8)所示:

其中,z表示真实的对局结果;v表示策略价值网络输出的胜率;π为蒙特卡洛树搜索输出的概率;p为策略价值网络输出的当前局面下每一个可行动作的概率。式(8)的第三项是用于防止过拟合的正则项。
3.3 评估网络阶段
当神经网络训练完毕后,进行评估阶段,这个阶段主要用于确认神经网络的参数是否得到了优化。这个过程中,自我对战的双方各自使用不同训练程度、不同参数的神经网络指导MCTS 搜索,并对战若干局,来检验AlphaZero 在新神经网络参数棋力是否得到了提高。除了神经网络的参数不同外,这个过程和第一阶段的自我对战学习阶段过程是类似的。如果使用新参数后胜率达到55%,就更新参数,而不再使用旧参数。
4 实验结果与分析
本次研究的不围棋项目结合上文所提到的算法,使用Python 语言进行编写,在Windows10 下进行了基于AlphaZero 的不围棋博弈系统的开发。
实验中,硬件环境设置如下:i7-8750H,主频2.2 GHz,内存16 GB,显卡1060,四核八线程。
表1 是该算法与OASE-NoGo 软件的对弈结果及胜率统计,该算法的胜率均在90%以上,体现出本文提出算法的可行性和高效性,实现的不围棋博弈有较强的棋力。

表1 对弈结果统计Tab.1 Statistics of game results
本项目中使用深度学习优化损失函数,最小化自我预测的价值和自我对弈胜者之间的误差,并最大化神经网络的走子概率和搜索概率,令博弈程序通过自我对弈学习博弈知识,得到了自我强化,优化了评估函数。
5 结束语
针对不围棋本身的博弈特点,本文给出了基于AlphaZero 的不围棋博弈系统,详细介绍了算法的训练过程。在与开源软件OASE-NoGo 的多次对弈实验中,本文算法取得了90%以上的胜率,证明了本文算法的可行性和有效性。
