基于LongTransformer的轨道交通装备及关键零部件剩余寿命预测
2022-12-11代钰赵蓉郭浩男高振杨雷
代钰,赵蓉,郭浩男,高振,杨雷
(1.东北大学 软件学院,沈阳 110169;2.东北大学 计算机科学与工程学院,沈阳 110169)
0 引言
对轨道交通装备以及关键耗损性部件进行寿命预测,可以根据剩余使用寿命对相关零部件进行维护或者更换,从而减少设备非计划停机时间,避免因计划外停机而带来的经济损失。传统的剩余寿命预测方法通常需要2个基础步骤:
1)建立性能退化指标;
2)研究预测模型[1]。王凤飞[2]等提出了一种考虑随机效应的多源信息融合剩余寿命预测方法,利用了同类设备的先验信息,提高了参数估计和剩余寿命预测的精度。这种传统的剩余寿命预测方法需要对历史退化数据和失效寿命数据进行合理融合,需要充分了解这些多源信息,也需要一定的经验和专业知识,这降低了寿命预测的智能性。
利用信号采集和计算机技术,可以获取机械设备运行过程中大量的状态监测数据,这推动了数据驱动的设备剩余寿命预测方法研究的发展。这些监测数据使得利用机器学习和深度学习的方法进行剩余寿命预测成为可能。齐盛[3]等提出了基于贝叶斯和极值分析的剩余寿命预测方法,该方法使用极值分布确定尺度参数和剩余寿命预测公式,最终得到寿命预测值。但是贝叶斯模型只在小规模的数据集上表现较好,当数据较多时,贝叶斯模型预测精度会下降。
深度学习中的循环神经网络能够利用全生命周期时序数据的前后关联关系[4],故可以将其应用到剩余寿命预测问题中。刘树鑫[5]等采用灰色关联分析法和皮尔逊相关系数法剔除冗余信息,进行特征选择,最后利用LSTM模型进行训练。但是循环神经网络由于梯度爆炸和梯度消失的问题难以训练,这使得模型缺乏学习长期依赖的能力[6]。虽然LSTM设计了遗忘门在一定程度上解决了传统循环神经网络会出现的梯度爆炸、消失问题,但是如果超过了100个随时间反向传播(BPTT)步骤,也会存在误差积累的情况,同样也会有以上问题的出现[7]。循环神经网络在长序列预测建模中还存在路径过长的问题,路径越短,在神经网络中进行前向传播和反向传播的次数越少,意味着输入与输出之间采集信息的累计误差越小,长期依赖也捕捉得更清晰。然而,LSTM在进行时间序列预测时,最长路径可达到O(L),L为序列长度[6],过长的路径导致输入与输出之间的累积误差过大,降低模型捕捉长期依赖的能力。现有的循环神经网络模型大多是在时间序列长度较短的情况下训练的,长度一般在48或者更短,如Li[8]等提出的DCRNN模型,Yu[9]采用的HOT-RNN结构。当输入时间序列较长时,以上模型很难精确捕捉长期序列之间的依赖关系,预测精度会降低。
与LSTM类似,为了解决RNN中出现的梯度问题,在剩余寿命预测问题中也会使用门控循环单元(GRU)模型。袁烨[10]利用门控循环单元,对时序关系进行建模,提取了数据时间上的特征,建立了特征与真实剩余寿命值之间的映射关系,从而得到剩余寿命预测值。姚德臣[11]等提出了注意力GRU算法,将注意力机制与门控循环单元相融合进行剩余寿命预测。但是以上方法只使用两个甚至一个门控循环单元,网络层数较少,无法提取较高层次的特征,导致模型预测精度不高。
本文就轨道交通装备及关键零部件剩余寿命预测中的由于时间序列长度增加导致模型捕捉长期依赖的能力降低这一问题进行分析,提出了基于Transformer的LongTransformer剩余寿命预测模型。LongTransformer模型对Transformer网络中的编码器层进行改进,通过自注意力蒸馏机制将级联层输入减半来突出主导注意力,增强了对于长周期时间序列依赖关系特征的提取,从而能够有效地处理更长的输入序列。首先将获取的历史数据进行位置编码,作为编码器层的输入;将真实的剩余寿命值输入到解码器层中,经过掩盖多头注意机制,再与编码器层的输出值一起输入到多头注意力机制中,通过全连接层得到最终的剩余寿命预测值。与传统的剩余寿命预测方法相比,LongTransformer模型需要的先验知识更少,泛化能力更强。利用LongTransformer有效捕捉长时间序列之间精确的依赖关系的能力,在与LSTM模型输入相同长度的时间序列时,LongTransformer的最长路径可减少到理论上最短的O(1)[6],大大降低了路径长度,累积误差减小,捕捉时间序列之间依赖关系的能力增强,提高了剩余寿命预测的准确率。
1 问题描述
1.1 数据集介绍
本文使用的实验数据采用中车株洲电力机车有限公司提供的轨道交通装备及关键零部件数据集。此数据集包含了2015年11月至2021年11月一列车组在行驶过程中列车各零部件参数的变化情况。此列车组由8列车厢组成,每列车厢有4根轴承。车厢按照功能可分为3类:有司机室动车(Mc)、带受电弓拖车(Tp)、动车(M),列车组的整体结构如下图所示。

图1 列车组示意图
此数据集包含8个子数据集,每个子数据集记录一列车厢行驶中各零部件的状态监测数据,数据的采样间隔为1min。不同种类车厢所监控的零部件类型不同,本实验以轴承为例对算法进行测试,在验证过程中选用了Mc1车厢的1号轴承数据集(下文用Mc1-1表示),Mc1-1共31列传感器监测数据,实验时取前80%数据作为模型的训练集,剩余的20%数据作为测试集输入。
1.2 数据预处理
首先对轴承状态监测数据进行筛选,筛选的意义在于某些特征参数在列车运行过程中近似恒定不变,对于模型的训练过程没有任何价值。经过计算后,有3列状态监测数据不随时间变化,故舍弃,使用其余28列状态监测数据进行剩余使用寿命预测。
下面需要对每列数据分别进行标准化,标准化是将数据按比例缩放,使之落入一个小的特定区间。这样做的好处是提高模型训练性能,简化计算。本文采用min-max标准化,计算公式如式(1)所示:

式(1)中,xj‘‘为min-max标准化后的第j个数据,j=1,2···,n;xj为原始的第j个数据;xj,min为该列数据的最小值,xj,max为该列数据的最大值。
为了量化模型性能,确保模型的准确性与可用性,需要计算评价指标对模型进行综合评估。本文采用的模型评价指标如下:
平均绝对误差(MAE):是绝对误差的平均值,这是一种更一般化的求误差方法,计算公式为:

式(2)中,n为剩余寿命预测值的个数;yi为剩余寿命真实值;为剩余寿命预测值。均方根误差(RMSE):是预测值与真实值残差的标准差,均方根误差具有无偏性,计算公式为:
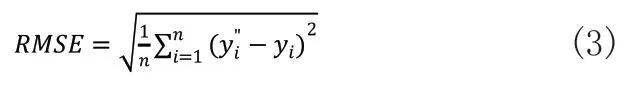
本文使用滑动窗口构建训练数据与测试数据,滑动窗口是指将数据集中连续的n条数据打包成二维矩阵,此时称滑动窗口的大小为n;这样做的目的是将前n-1条数据与第n条数据同时放入模型中进行训练,以便获取数据间的隐藏关系,得出更好的结果。
1.3 剩余寿命预测问题描述
在具有固定大小的滑动窗口的预测设置下,本文输入数据格式为X(t)=[x1(t-N+1),...,xN(t)]T的矩阵,大小为M×N。其中xn(t-N+n)表示在t时刻,采用第t-N+n时刻的传感器数据对零部件进行预测,大小为M×1。M为监测某个零部件的传感器的数量,N为滑动窗口的大小,yt代表的t时刻该轴承真实的剩余寿命值。模型的输出值即预测目标为Y=y'',表示模型对该零部件剩余寿命的预测值。
2 基于LongTransformer模型的剩余寿命预测
Transformer抛弃了传统的卷积神经网络(CNN)和循环神经网络(RNN),整个网络结构完全是由注意力机制组成,即由self-Attention和Feed-Forward Neural Network组成。与LSTM等传统的循环神经网络相比,Transformer输入与输出之间的路径较短,捕捉长时间序列依赖的能力较强。然而,随着工业技术的升级,短周期的轨道交通关键零部件状态监测数据已经不能显著反映剩余寿命的变化,剩余寿命对已有算法的预测能力也提出了更高的要求即需要处理更长周期依赖性特征,从而提高模型预测的准确率。为了解决这一挑战,本文提出了基于改进Transformer剩余寿命预测算法(Long-Transformer),整体结构如图2所示。该模型分别搭建了2层编码器和解码器,编码器层包括多头自注意力机制、自注意力蒸馏机制以及前馈神经网络,解码器层由掩盖多头注意机制、多头注意力机制、前馈神经网络组成。接下来对各个部分做详细说明。
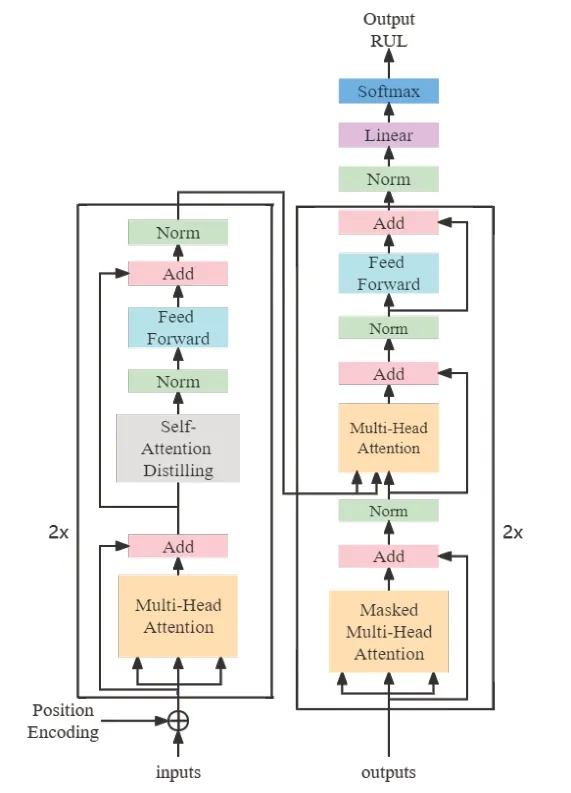
图2 LongTransformer整体结构图
2.1 Encoder layer
本文利用LongTransformer中的Encoder层来捕获关键零部件剩余寿命的长期与短期依赖关系。Encoder层包括三个部分,分别是Multi-Head Self-Attention(多头自注意力模块)、Self-Attention Distilling(自注意力蒸馏模块)和Feed-Forward Neural Network(前馈神经网络模块)。另外,为了解决深度学习中的退化问题,多头自注意力模块使用了残差网络中的short-cut结构。
2.1.1 Multi-Head Attention
当采用自注意力模型时,模型只能关注到单方面的信息,无法将多方面的信息合并,使得模型预测精度不高。由于剩余寿命预测
问题需要关注每条数据不同特征部分,捕捉到数据之间潜在的依赖信息。所以本文使用多头自注意力机制将模型分为多个子空间,每个子空间关注不同方面的信息。多头自注意力模块将Query向量(Q)、Key向量(K)以及Value向量(V)进行N次拆分,并将每次拆分分别通过不同的头传递,再将所有头计算的结果合并得到最终的注意力得分,这可以使多头注意力关注到不同的信息,提高剩余寿命预测的准确率。在自注意力中,每条数据有三个不同的向量,分别是Query向量(Q)、Key向量(K)以及向量Value(V),这三个向量由输入的数据与三个值不同、维度相同的权值矩阵Wq、Wk和Wv相乘得到。多头自注意力模块实际上是多个不同的Self-Attention(自注意力)的集成,本文的多头自注意力模块包括4个自注意力模块,即head个数为4。步骤如下:首先,每个head根据输入数据得到K、V、Q三个向量:

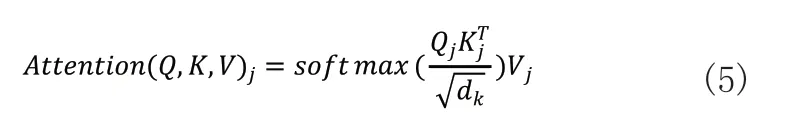
在head为4的情况下,多头自注意力模块的步骤为:首先,将得到的注意力矩阵连接,接着经过softmax激活函数,最后,与一个随机初始化的权重矩阵WA相乘得到最后的注意力矩阵,即多头自注意力模块的输出:
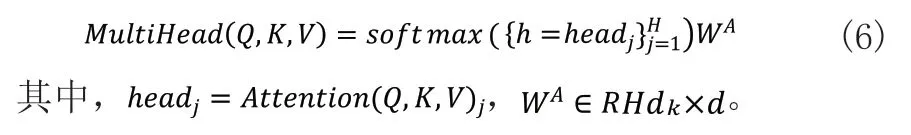
2.1.2 Self-Attention Distilling
由于编码器层的特征映射存在值V的冗余组合,导致模型空间复杂度较高,不能接受较长的输入序列。但是,短期的零部件监测数据输入序列,已经不能显著地反映出剩余寿命的趋势,所以,需要能够处理更长周期输入序列的模型。因此在自注意力蒸馏模块中,通过将级联层输入减半这一步骤来突出主导注意力并优先处理,具体做法是对具有主导特性的优势特征赋予更高的权重,蒸馏操作将总空间复杂度降低到O((2-α)LlogL),这有助于接受更长的输入序列。该模块从第j层推进到第j+1层的过程如该公式所示:

其中,一维卷积层Conv1d使用的卷积核大小为3,最大池化层MaxPool的步长为2。
2.1.3 Feed-Forward Neural Network
在多头自注意力机制的内部结构中,主要进行的是矩阵乘法,即线性变换,线性变换的学习能力与非线性变换相比较弱,但是,由于剩余寿命预测的数据时间跨度较长,需要具有更强学习能力的模型来捕捉输入与输出之间的长周期依赖特征。所以本文通过采用激活函数的方式来强化多头自注意力模块的学习能力。前馈神经网络模块由两个线性变换组成,激活函数为ReLU函数。公式表示为:

其中,x为多头自注意力模块的输出,W1、b1分别为第一层线性变换的权重和偏置项,W2、b2分别为第二层线性变换的权重和偏置项。
2.2 Decoder layer
传统的解码器层的输入是上一层和编码器的输出,由于预测偏差会逐渐积累,导致最终预测结果精度降低,所以本文将寿命预测的真实值(ground-truth)和编码器层的输出作为编码器层的输入,让数据的真实值输入到解码器层进行训练,以缓解误差的积累,提高预测准确率。解码器层包括masked Multi-Head Attention模块、Multi-Head Attention模块和Linear模块。Masked Multi-Head Attention模块的作用为防止模型看到要预测的数据,由于解码过程是一个顺序操作的过程,也就是指当解码第i个特征向量时,模型只能看到第i-1及其之前的解码结果。向量Xde经过位置编码后,与特征矩阵相乘后得到向量Q,K,V,作为Masked Multi-Head Attention模块的输入,向量Xde的计算公式为:
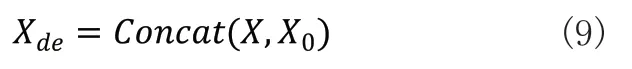
其中,X是数据集中的真实剩余寿命,X0是需要补充的占位符,值设置为0。
Multi-Head Attention模块的K和V来自于编码器层的输出,Q来自于Masked Multi-Head Attention模块的输出,计算过程与编码器层相同。
2.3 position Encoding
由于LongTransformer模型的编码器层和解码器层不包含循环和卷积网络,因此不能利用输入序列的前后顺序,所以要在编码和解码之前注入序列中关于数据之间位置关系的信息。本文采用不同频率的正弦函数和余弦函数来计算输入数据的位置信息,通过位置编码(position Encoding),使LongTransformer有了捕捉长时间序列顺序的能力,之所以选择正弦函数和余弦函数,是因为对于任意确定的偏移k,可以表示为的线性函数,这允许模型很容易学习对相对位置的关注。位置编码一般是一个长度为d的特征向量,这样便于和输入的数据进行单位加的操作,编码公式如下:
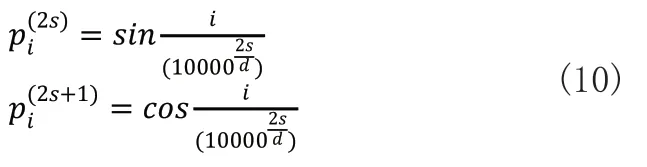
其中,pi表示第i条数据的位置编码,s表示数据的维度。这样,对于给定任意的长度l,pi+l与pi都有线性关系,即pi+l的位置向量可以表示pi为的位置向量的线性变化,这方便捕捉数据之间的相对位置关系。
3 实验验证
本实验分为两个部分,第一部分讨论在相同滑动窗口长度下,不同模型的预测结果比较及分析;第二部分讨论随着滑动窗口的长度增加,不同模型的评价指标对比。本文使用的基线模型为LSTM,Attention-GRU[11]。
首先,当滑动窗口的长度为60时,不同模型的预测结果随时间增加的变化情况如图3所示。
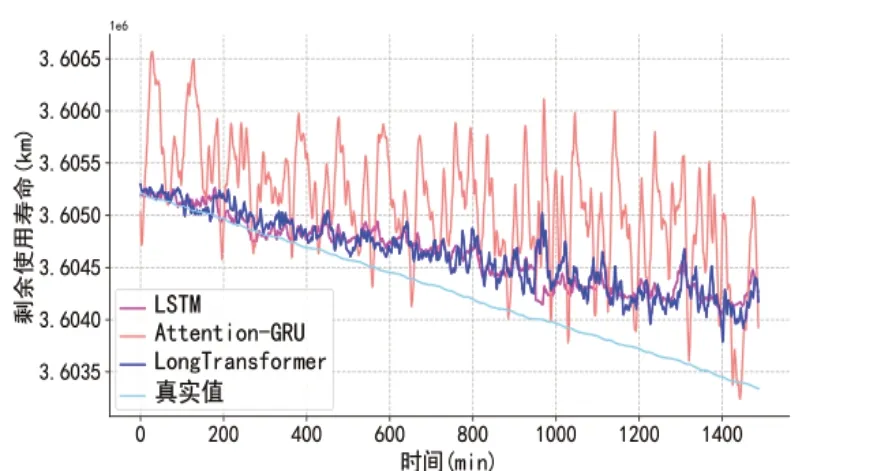
图3 滑动窗口长度为60时模型预测情况
从图3 中可以看出,相比较于其他两个模型,Attention-GRU模型的预测结果浮动较大,精度稍差。当测试集数据在前400分钟内时,本文提出的LongTransformer模型与基线LSTM模型预测结果都较为准确,随着时间推移,两模型的预测精度逐步下降。这是由于开始时的测试数据,在时间上距离训练数据较近,测试集与训练集的数据相似度较高,容易得到准确性较高的结果。随着时间推移,状态监测数据发生变化,测试集与训练集的数据相似性逐步降低,预测值的准确性也逐渐降低。
为了进一步比较三种模型的预测结果随时间的变化趋势,下表分别列出0~420分钟,421~960分钟以及961分钟之后三种模型预测值与真实值的MAE与RMSE情况。
从表1中可以看出,在前420分钟内,LSTM模型MAE与RMSE两项指标均好于本文提出的模型,表现最差的为Attention-GRU模型。当时间在421~960分钟时,表现最好的模型为LongTransformer,其MAE相较于LSTM、Attention-GRU模型分别降低了6.63%、58.73%,RMSE值分别降低了2.41%、45.83%。随着时间的增加,三种模型的MAE与RMSE值继续增大,在961分钟后,表现最好的依旧为本文提出的LongTransformer,其MAE与RMSE值相较于LSTM模型分别提高了2.16%,2.05%;相较于Attention-GRU模型,这两项指标分别提升了45.83%,49.08%。这是因为相较于基线模型,LongTransformer能够更好的捕捉相邻输入序列之间的相关性,具备预测更长时间序列的能力。
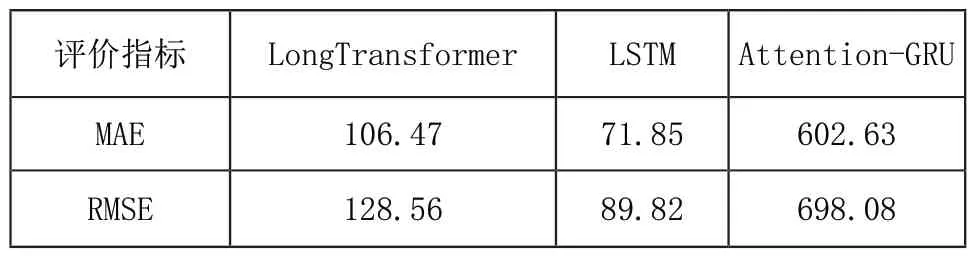
表1 (a) 0~420分钟内不同模型的评价指标

表1 (b) 421~960分钟内不同模型的评价指标

表1 (c) 961分钟后不同模型的评价指标
下面讨论随着滑动窗口的长度增加,即输入数据的周期变长,不同模型平均绝对误差与均方根误差的变化情况,结果如图4所示。

图4 (a) 不同滑动窗口长度下不同模型的MAE值比较
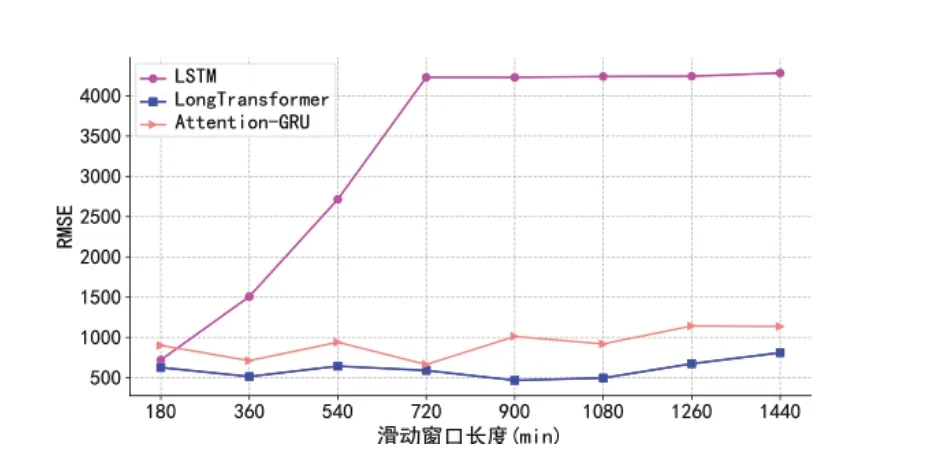
图4 (b) 不同滑动窗口长度下不同模型的RMSE值比较
本实验的输入滑动窗口长度为180~1440分钟,即3~24小时,中间每3小时进行一次测试,从图中可以看到,不同模型下MAE与RMSE的变化趋势基本相同。当滑动窗口长度为180分钟时,两评价指标最低的模型均为LongTransformer,其次为LSTM,最次为Attention-GRU。相较于后两个模型,LongTransformer的MAE值分别降低了19.07%,29.32%;RMSE值分别降低了13.11%,30.47%。随着滑动窗口长度增加,小滑动窗口期间表现较好的LSTM模型的两个评价指标迅速增长,到720分钟后,评价指标变化平稳,当输入序列长度为1440分钟时,LSTM模型的MAE与RMSE值分别为4281.85,4283.68,预测精度降低明显,故此模型不适用与长周期序列预测。这是因为输入序列过长,导致LSTM在训练过程中产生梯度消失,模型参数无法迭代更新。
Attention-GRU模型与LongTransformer模型的精度虽然也随滑动窗口输入周期的增加而降低,但评价指标变化相较平稳,当滑动窗口长度为1440分钟时,表现最优的为LongTransformer模型,MAE值与RMSE值分别为738.60,810.45;其次为Attention-GRU模型,两值分别为1085.66,1136.01。前者与后者相比,两评价指标分别降低了31.97%,28.66%。这是因为相较于Attention-GRU,LongTransformer模型能够更好地提取长距离输入内部的依赖关系,而忽略数据之间的无关信息。
4 结语
本文提出了基于LongTransformer的轨道交通装备及关键零部件件剩余寿命预测方法。通过自注意力蒸馏操作中的级联层输入减半方法大幅降低了空间复杂度,增强了对长时间序列依赖关系特征的提取能力。实验结果表明,本文所提出的方法优于两种较先进的基于循环神经网络的方法,在剩余寿命预测问题上有更高的准确率。
