卷积神经网络并行化设计及FPGA实现
2022-12-11刘华陶冠男杨文清
刘华,陶冠男,杨文清
(广东电网有限责任公司广州供电局,广州 510000)
0 引言
近年来,人工智能技术飞速发展,越来越多的智能化产品开始在日常生活中崭露头角,尤其是以卷积神经网络(Convolutional Neural Network,CNN)[1]为基础的深度学习技术。卷积神经网络以独特的局部感知和权值共享结构能够更好地进行特征提取,其所带来的实际应用价值不断地凸显,在图像分类[2]、目标检测[3]、语义分割[4]以及语音识别[5]等领域都有着十分重要的应用。
GPU是专用的图像处理单元,拥有大量的计算资源,随着NVIDIA推出统一计算设备架构(Compute Unified Device Architecture,CUDA),结合cuDNN[6]深度神经网络的GPU加速库,GPU已经成为主流的硬件计算平台,但GPU功耗较高、体积较大,难以应用到对体积与功耗要求较高的嵌入式移动与边缘设备当中。专用集成电路(Application Specific Integrated Circuit,ASIC)在嵌入式平台的卷积神经网络硬件加速上具有绝对的优势,但ASIC需要较长的研发周期,一旦流片完成便不可进行更改,难以应对复杂多变的算法结构,成本高、灵活性差。现场可编程门阵列(Field Programmable Gate Array,FPGA)是一种半定制、可重构的专用集成电路,即弥补了ASIC灵活性差的不足又克服了GPU高功耗的缺点,使用FPGA作为卷积神经网络硬件加速平台逐渐成为研究热点[7]。
使用FPGA进行网络相关模型的加速由来已久,早在1996年,Cloutier等[8]开始研究使用FPGA进行卷积神经网络的加速,其在FPGA上实现了手写字母识别的相关设计,受制于当时芯片的制造工艺,FPGA片上资源密度很低,其对卷积神经网络的并行性没有充分展开设计。2015年,Zhang等[9]使用HLS的设计方法,针对CNN在FPGA上的部署,提出了基于Roofline的模型分析方法,通过对数据吞吐率以及系统存储带宽的量化分析,得到了模型部署的最小资源消耗与最佳性能方案,该方案消耗了较多的硬件资源,难以应用在低成本的嵌入式场合。2016年,Qiu等[10]基于VGG网络,通过对卷积神经网络各层的计算资源消耗、内存需求的分析,采用动态数据量化方法,实现了与浮点型数据十分接近的网络分类精度。同年,Ghaffari等[11]提出一种通用卷积神经网络加速框架,该设计中对网络中的每类网络层设计专用的计算单元,并使用统一的逻辑控制单元进行调度,使用LeNet5对设计架构进行测试。
并行化设计是卷积神经网络加速方法的核心方法之一,网络并行化的设计主要是针对卷积层,通常根据卷积层的计算特征,使用循环分块、循环展开等方法进行优化。文献[12]在特征图的输入与输出层面进行并行化设计,以此提升卷积层的计算速度,然而并未充分利用卷积计算的内在并行性。文献[13]则提出了一种5层并行化结构,详细分析了卷积神经网络的内部并行性,设计了一种可配置的CNN并行计算单元,但并未给出硬件资源受限情况下的卷积复用设计。
基于以上分析,使用FPGA进行卷积神经网络硬件加速设计能够在低功耗的同时满足对高效性能与灵活性的要求,符合嵌入式应用场景。本文使用设计一种卷积神经网络加速器,旨在为基于FPGA的卷积神经网络工程化实现提供一种设计方案,研究提出一种低功耗、可扩展、高性能的卷积神经网络并行化框架,从而实现面向嵌入式场景的卷积神经网络部署。
1 基本理论及设计方法
1.1 神经网络基本模型
神经网络的基本组成单位是神经元,研究人员通过对人脑结构的模拟,对神经元进行数学建模,构成人工神经网络[14]。一个神经元的组成结构可用图1表示。该神经元接收上一级n个神经元(x1,x2,...,xn)的输出,并将其与对应的权重w(w1,w2,...,wn)相乘,进而决定不同输入信号的作用强度,通过求和单元将n个输入信号与偏置b混合,最终通过一个激活函数f将该节点的运算结果输出。

图1 神经元的组成结构图
则单个神经元的计算可用式(1)表示:

偏置能够使激活函数平移,进而增强网络的鲁棒性。激活函数的作用在于对神经元的输出进行非线性变换,使网络模型具有良好的非线性模拟能力,并限定神经元的输出范围,提高模型的表达能力。常见的激活函数有sigmoid、tanh以及relu等。
1.2 卷积计算原理
卷积层是卷积神经网络的主要组成部分,一个卷积层由多个特征面组成,每个特征面由多个神经元组成,每个神经元通过卷积核与上一层特征面的局部区域相连,卷积核是一个权值矩阵,卷积层通过卷积运算提取不同的特征。
如图2所示,一个5×5的输入特征图与一个3×3的卷积核进行卷积计算,使用Xx,j表示输入特征图的第i行的第j个元素;使用wm,n表示卷积核第m行的第n个列权重,用wb示卷积核的偏置项;使用Yi,j表示输出特征图的第i行的第j个元素;用f(x)表示激活函数。则根据式(1)可得:
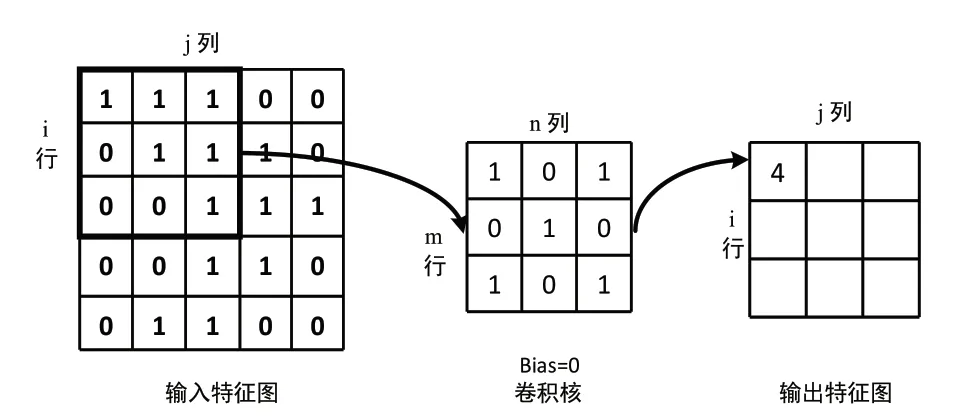
图2 单输入通道卷积计算示意图
实际上卷积层通常是多输入通道,图3展示了多输入通道卷积计算的过程,图中M表示卷积核个数,N表示输入特征图个数,H和W分别表示特征图尺寸,K表示卷积核尺寸。每组卷积核与对应输入通道的特征图进行单通道的卷积计算,然后将各个通道的计算结果进行累加,再加上偏置wb就到了一个输出特征图上的结果输出。
图3 多输入通道卷积计算示意图
1.3 卷积层并行性分析
文献[13]对卷积神经网络中的并行性做了详细介绍,本文在此基础上对并行性进行简单分析。卷积神经网络的前向推理过程中具有不同维度的并行性,其中卷积的运算是网络计算中的主要计算单元,因此对并行性的分析主要针对卷积计算单元。
1)卷积核间并行性
卷积核间并行是指每个卷积计算的卷积核是相互独立的,所有的卷积核共享输入特征图,因此卷积核间的计算是不存在相互依赖的关系,我们可以通过图4来描述这种卷积核间的并行性。
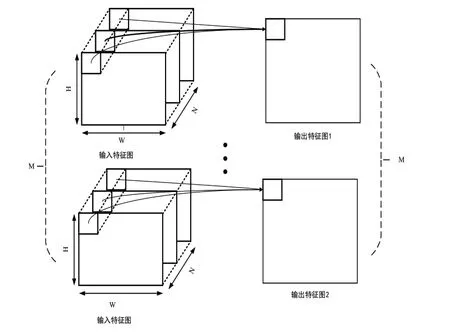
图4 卷积核间并行性
可以发现M个卷积核的计算可以同时进行,彼此相互独立,可以将此过程展开,使得M个卷积核同时进行计算,但要求系统加速器的设计有较高的数据吞吐量,对数据带宽的要求极高。
2)特征图间并行性
特征图间的并行性是指对于N个输入特征图来说,每一组卷积核都有N卷积核与之对应。当进行卷积计算时,每个卷积核与对应的输入特征图进行乘加计算。特征图间并行性如图5所示,实际计算时可将每个特征图与对应卷积核进行并行计算,然后将计算得到的结果相加即可得到输出特征图。
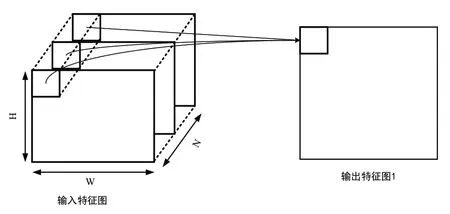
图5 特征图间并行性
特征图间并行性对系统带宽与吞吐率的要求相对较小,可通过一定的设计充分利用特征图间的并行,但对于大多数的片上嵌入式系统来说,资源需求量还是稍高,实际使用时可以使用循环分块等方法降低系统对带宽的要求。
3)特征图内并行性
一个特征图共享一个卷积核,因此可以将特征图上的卷积滑窗同时进行运算。特征图内并行运算方式如图6所示,在一个特征图上的不同位置使用共享的卷积核进行并行运算,可减少循环的次数。

图6 特征图内并行性
特征图内的并行性相对容易实现,其对系统的带宽与吞吐率要求不高,可以使用循环切片实现特征图内的并行性,但会消耗较多的片上存储资源且数据复用度较低。
4)卷积核内并行性
卷积核内的并行性是整个卷积计算过程中最基本的计算单元。k*k的卷积核与特征图上k*k的滑窗进行卷积计算,通常需要进行k*k次乘法运算与k*k-1次加法运算。以图7中3*3的卷积核为例,整个计算过程需要进行9次乘法与8次加法运算,如果使用串行计算共需要循环9次,每一次循环需要进行一次乘法与加法运算;如果将卷积核与特征图滑窗展开为图7中的向量形式,可同时进行9次乘法运算,然后在进行1次加法运算即可完成整个计算,卷积核的并行性可通过循环展开的形式实现。

图7 卷积核并行性
2 并行化设计
卷积层的计算占据整个网络中的大量计算资源,因此对卷积层的加速能够大幅提高网络的前向推理时间。通过对卷积层并行性的分析可知,卷积层存在大量的并行性,针对标准卷积并行性的分析,我们提出一种标准卷积加速器设计思路,加速器的设计核心内容是以减少数据的重复传输为目的,在此基础上尽可能地将标准卷积计算的并行度与数据复用度最大化。
2.1 循环分块
卷积计算中的并行性贯穿于整个卷积层的计算过程。通常情况下,由于硬件计算资源的限制,难以将计算过程中的所有循环都展开。因此,在实际设计过程中,采取循环分块技术以降低加速器对硬件资源的消耗。所谓循环分块技术是指对于一个较大的循环体可以将其拆分为几个较小的循环体,以此实现对代码的优化,降低循环体对硬件资源的消耗。
如图8所示,对于输出通道来说,可将M个卷积核分割为M/p份,通过M/p次循环完成整个卷积核的并行计算,则此时卷积核的并行度为p,即一次进行p个卷积核的计算。同样,如图9所示,对于输入通道来说,可以将N个输入通道分为N/q份,通过N/q次循环完成整个输出通道数据的遍历,则此时特征图间的并行性为q,即一次进行q个输入特征图的计算。每完成一次循环,需要将本次循环的计算结果与之前所有的卷积计算结果相加,作为本次循环的最终输出结果,当进行最后一次循环时,将本次循环的最终计算结果与偏置相加,然后通过激活函数输出,得到一个卷积核的最终输出特征图。
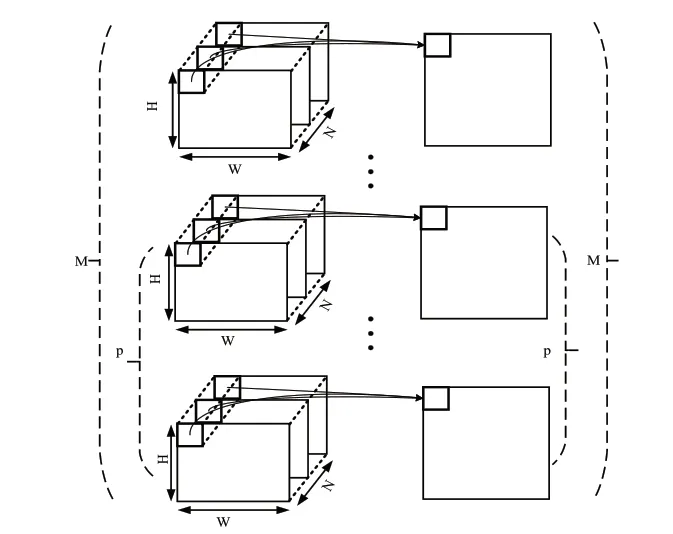
图8 输出通道遍历循环分块示意图
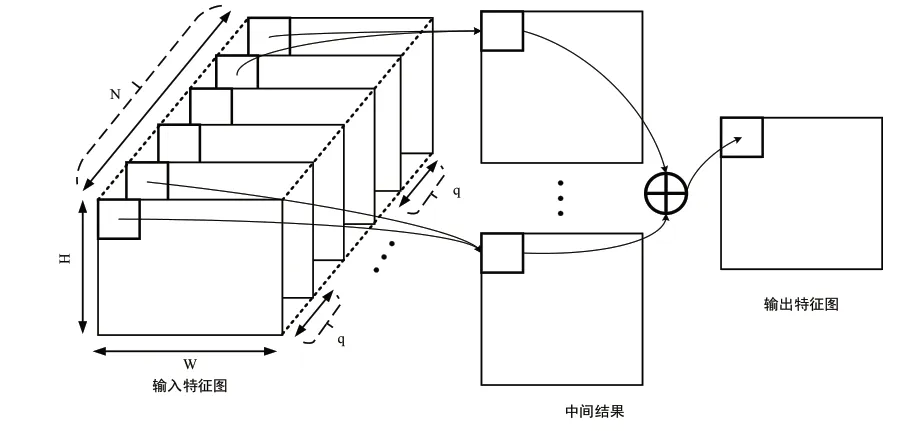
图9 输入通道遍历循环分块示意图
我们将输出通道的p和输入通道的q称为循环分块因子,可使用图10中的代码表示上述卷积计算过程。循环分块因子的选择对系统并行性的影响至关重要,如何确定循环分块因子需要根据具体的网络模型以及具体的硬件加速平台,当硬件加速平台资源较多时,可以适当的增大循环分块因子,反之使用较小的循环分块因子。此外,并不是分块因子越大越好,当系统的资源较为丰富时,循环分块因子不再是限制系统性能的主要原因,此时系统的加速性能与系统数据传输带宽有关。

图10 输入、输出通道遍历循环分块代码
2.2 循环展开及调整
循环展开是一种最直接的并行化加速方法,采用循环展开的方法能够大幅地提高并行运算的速度,当硬件加速平台的资源充足时,可将计算过程没有依赖关系的循环进行展开。对于整个卷积层的计算来说,仅对卷积计算过程中循环最内层的计算单元进行展开难以达到理想的加速效果,因此需要根据实际的硬件资源对其他的循环进行展开。为了便于进行循环展开的设计,我们将卷积层计算的代码调整为图11中的形式。

图11 改变循环次序的代码
对调整后的代码进行循环编号,从外层到内层分别编号为1~8,此时循环1和循环2是对输入、输出通道的循环分块,循环分块的目的是为了减少加速器对硬件资源的要求,增大加速器的并行性,因此将循环分块置于最外层。循环3和循环4是输入对特征图尺寸的遍历,对于不同的卷积核其共用同一个输入特征图,因此对输入特征图的遍历存在一定的数据复用度,可充分利用这一特点减少加速器对数据通信带宽的要求,降低输入数据的反复读取。循环5和循环6是对输入、输出通道循环分块因子的遍历,为了能够充分利用卷积计算的并行性,可在循环分块因子的尺度进行循环展开设计,能够大幅提高对硬件资源的利用率以及卷积层计算的速度,使用循环展开技术能够有效地增加卷积运算的并行性,并行计算的大小由循环分块因子决定。
2.3 片上存储设计
片上存储设计是卷积层加速器的核心设计内容之一,加速器性能的好坏和片上存储设计有直接联系,FPGA的片上存储资源十分有限,因此难以进行大规模的数据存储。对于FPGA来说,块随机存取存储器(Block Random Access Memory,BRAM)和触发器(Flip Flop,FF)均可作为片上存储器,通常使用FF构成寄存器存储需要进行反复读取的数据,FF的读取速度大于BRAM,但能存储的数据量远小于BRAM。
卷积加速器片上存储的设计主要包括权重偏置数据缓存、特征图输入缓存以及卷积计算结果输出缓存三个层面,下面分别对其进行分析,并给出可行的设计方案。
1)权重偏置数据缓存
对于一个未进行剪枝、压缩等优化的j卷积神经网络模型来说,模型的参数量远大于多数FPGA内部的BRAM资源。因此,难以一次性将模型的全部参数部署到FPGA内部,此时需要合理的设计片上存储使加速器能够具有较高的性能。对于一层卷积的计算,只需在卷积计算之前将本层的权重偏置数据传输到FPGA内部的BRAM上,虽然会导致一定的数据传输与计算延时,但能够大幅降低加速器对片上存储资源的要求。
从循环展开的设计中可知,加速器一次计算需要完成p个卷积核对q个的输入特征图的遍历。因此,对于片上存储设计来说只需在卷积计算之前将p*q*k*k个权重参数传输到FPGA内部的BRAM上即可,这样能够进一步降低对片上存储资源的消耗,但会增加加速器的延时。
2)特征图输入缓存
卷积层的计算过程中通常难以将参与计算的输入特征图一次传输至加速器的片内存储。因此,需要设计输入特征图的缓存结构,使得加速器能够满足并行化计算。由卷积计算的原理可知,卷积的计算过程可描述为卷积核在特征图上的滑动,不同的卷积核共享同一个输入特征图,可以将特征图输入缓存设计成行缓存的结构,需要缓存的行数与卷积核的尺寸k有关。
为了兼顾卷积计算的并行性、数据复用度以及FPGA的片上资源,采用图12所示的行缓存结构,交替地将特征图的数据传输至FPGA内部。该缓存结构可以实现特征图间的并行性以及卷积核间的并行性。当进行卷积计算时,q个不同的卷积核共享对应的p个输入特征图行缓存,将p个输入特征图的卷积计算结果叠加即可得到一个卷积核的计算输出。行缓存结构相对复杂,但计算效率较高,能够在有限的片上资源实现较大的并行性,此外引入多通道输入特征图的缓存能够有效地降低临时数据存储。
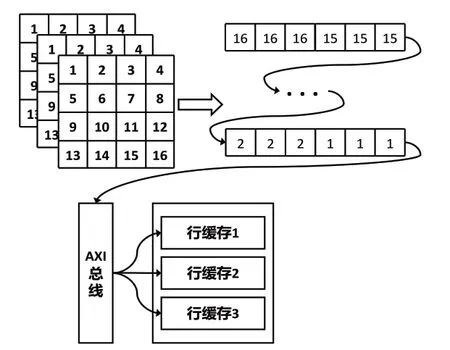
图12 特征图行缓存结构图
当进行卷积计算时,特征图的数据通过AXI[15]总线串行的传输至FPGA内部,如图13所示。以4*4的输入特征图和3*3的卷积核为例进行行缓存内部结构的介绍(表示缓存器当前位置),行缓存尺寸为3*4,一次缓存的最大尺寸为3行。
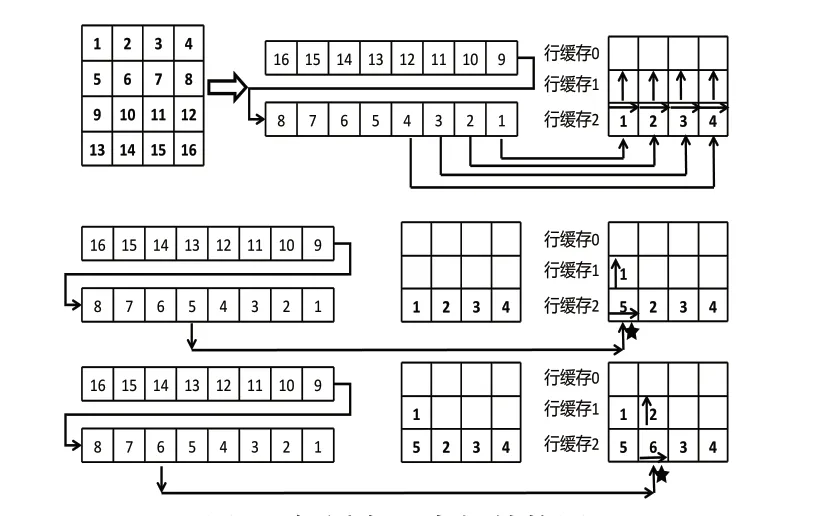
图13 行缓存器内部结构图
假设AXI总线每个时钟周期传输一位输入特征图数据,行缓存每个时钟周期就能获取一个数。每个时钟周期下缓存器将当前列的数据向上移动,然后将新的数据读入缓存器的当前位置。下一个时钟周期到来时缓存器将当前位置向右移动一个位置,然后将当前列的数据向上移动,再将新的数据读入缓存器的当前位置,以此类推不断重复这个过程,直到缓存器当前位置移动到最后一列,在下个时钟周期时再从第一列重复之前的过程。
3)特征图输出缓存
由卷积层的计算过程可知,一个完整的输出特征图与所有的输入特征图有关。因此,在引入循环分块的加速器设计中,只有当一组卷积核将所有的输入通道遍历完成后,才能得到对应的输出特征图。无论是最终的输出特征图还是一组循环中的中间计算结果,都需要在完成q个卷积核对应的p个输入特征图的卷积计算后,才将计算结果通过AXI总线传输至片外存储。卷积层的计算中通常输入特征图的通道数小于输出特征图。因此,当进行卷积计算时,AXI总线对输入特征图的数据读取次数就小于对输出特征图的数据写入次数,这样会造成读取与写入数据的不平衡,影响系统的数据吞吐率。为了提高加速器的整体数据吞吐量,我们在卷积的计算中引入FIFO的输出缓存设计,通过FIFO缓存卷积计算结果。
假设卷积的计算有4个输入通道和8个输出通道,AXI总线一次能够传输2个通道的数据,因此对于输入通道来说需要2个时钟周期进行数据的读取,对于输出通道来说需要4个时钟周期进行数据的输出。
图14是无FIFO的输出缓存结构图,从图中可知,由于没有引入FIFO的结构,当完成两个输入通道的数据读取后,卷积开始产生计算结果的输出,此时需要将部分计算结果传输至片外存储。当完成整个输入通道的读取后,卷积计算完成,而输出通道的数据大于输入通道,因此还需额外的时钟周期将剩下的输出通道数据传输至片外存储,整个数据传输需要消耗5个时钟周期。
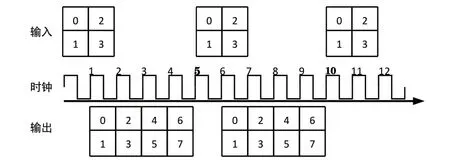
图14 无FIFO输出缓存结构图
图15是有FIFO的输出缓存结构图,FIFO的深度为2,每进行一次输入数据的读取则进行两次输出数据的写入,完成卷积计算时需要进行FIFO状态的判断,当FIFO非满状态下进行FIFO的数据写入,将当前的计算结果缓存至FIFO中。同样当进行数据读取时需要判断FIFO是否为空,当FIFO状态非空时进行数据的读取,将卷积计算结果输出至片外存储器。从图中可知,由于引入FIFO的结构设计,当完成两个输入通道的数据读取后,卷积开始产生计算结果的输出,此时需要将本次的计算结果写入到片内的FIFO缓存中,在进行数据读取的同时将上一次计算的结果从FIFO中读取出来,通过AXI总线传输至片外存储。

图15 有FIFO输出缓存结构图
两种结构对比可知,从单次计算的时钟周期来说,没有引入FIFO的结构中完成一次完整的卷积计算所需要的时钟周期是5,引入FIFO所需要的时钟周期是4。从数据吞吐量来说,没有引入FIFO的结构中,12个时钟周期内完成了3次输入数据的读取与2次输出数据的写入,引入FIFO的设计中12个时钟周期内完成了4次输入数据的读取与2次输出数据的写入,一定程度上提高了数据的吞吐率。
2.4 Padding控制器设计
为了保证卷积计算前后特征图的尺寸不发生变化,通常在卷积计算时引入补“0”技术。此外,补“0”后的特征图在进行卷积计算时,其边缘的特征值也能多次参与卷积计算,从而达到减少特征图边缘信息丢失的作用。因此,补“0”对卷积计算十分重要。特征图补“0”的方法有多种形式,本文仅以较为常用的边缘均匀补“0”进行具体设计的介绍。
如图16所示,输入特征图数据以数据流的形式传输至FPGA内部,数据在进入FPGA的片上行缓存之前需要经过片内的Padding控制器,Padding控制器根据特征图当前传输的数据状态决定是否进行补“0”。在进行特征图数据传输之前,首先将特征图原本的行数与列数传输至Padding控制器内部,以此作为行、列控制器判断补“0”个数与位置的依据。每次将AXI总线上的数据传输至行缓存内部之前,Padding控制器中的行、列控制器会记录当前数据所处的位置,并根据当前位置对行缓存数据流进行补“0”。具体的做法是:当行控制器检测到当前行位于第一行或最后一行时,则在读取特征图数据之前将行缓存数据流中的所有列数据全部置为“0”。当行控制器检测到当前行位于第一行与最后一行之间时,则在读取特征图数据之前将行缓存数据流中的第一列与最后一列数据全部置为“0”。当列控制器检测到当前列为最后一列时则进行换行,以此对数据流中的数据进行分行处理。
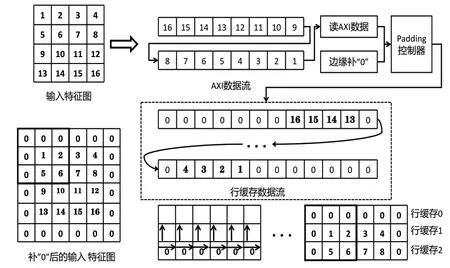
图16 Padding 控制器结构图
2.5 卷积复用
网络中的卷积核通常有3*3与1*1两种尺寸,为了降低硬件资源的消耗,提升资源利用率,我们设计了一种卷积复用的方法。如图17,我们首先对1*1的卷积核进行扩充,使其转换为3*3的卷积计算,然后将其送入3*3的卷积计算单元,即可完成卷积计算。扩充的方法是,将原始1*1卷积的权重放置3*3卷积核权重的第5位,3*3卷积核剩余8位权重均置0。根据图17可知,扩充前后1*1卷积的计算结果相同,无需对3*3卷积计算单元做出更改,因此复用设计正确。卷积计算单元的复用没有使用额外的硬件资源,极大地提高了硬件的利用率,但会造成1*1卷积计算效率的下降以及一定的无效数据传输,每传输一个权重需传输8个无效的数据,此外还会增加一定的片外存储空间用以存放扩充的“0”。总的来说,当硬件资源较为紧张时,计算复用带来的优势远大于劣势。
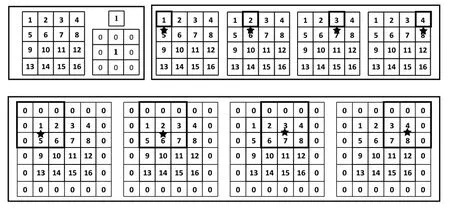
图17 卷积复用转换示意图
2.6 设计优化
设计优化主要是使用高层次综合(High-level Synthesis,HLS)[16]工具的Directive指令对卷积计算单元的延时进行优化,优化的目标是以较小的资源消耗换取最大的计算效率,HLS工具会自动进行设计优化,但需指定采用何种优化方法 。我们的优化对象主要有两个:循环以及片上存储结构即数组。
1)循环优化
卷积的计算中存在多层循环,我们使用“PIPELINE”对循环进行优化,多层循环嵌套的情况下,“PIPELINE”指令会对内层循环进行展开,因此仅需在外层循环应用“PIPLINE”即可。卷积计算单元一个时钟周期能够传输64位数据即4个输入通道的数据,则输入通道最大循环次数为q/4,一次数据传输需完成p个卷积的计算。通常卷积层的最小输入通道数为3,最大输入通道数为可达1024,我们将卷积输入通道的并行度设置为可变值,最大为q,并在此循环上使用“PIPLINE”进行优化,由于循环次数q/4不固定,因此该循环并不被展开,该循环内部即为卷积计算过程:行缓存、卷积滑窗、卷积计算、数据累加以及计算输出,将该循环内的循环均设为定值,则一次循环可完成p个输出通道的计算,即输出通道的并行度固定为p。
2)数组优化
数组优化的指令为“ARRAY_PARTITION”,通常是为了提升“PIPLINE”的性能。数组存储在片上的BRAM中,BRAM的最大读取端口数量为2,数据访存速度较慢,为了提升吞吐量,通常将一个大的数组分割为几个小的数组,这样就能对数组进行并行访存,提高数据吞吐量。HLS提供block、cyclic、complete三种数组分割方法,如图18所示。对于block和cyclic指令,可使用factor指定将原始数组分割为多少个小数组,图中factor等于2。对于complete指令,其直接对数组中的每个存储单元进行完全分割,使其成为寄存器级接口,访存速度最快。

图18 数组分割示意图
网络模型中需要进行数组优化的有权重、偏置、输入行缓存、数据累加缓存以及输出数据缓存,可分别使用Weight[p][q][k2]、Bias[p]、LineBuffer[q]、AccumulationBuffer[p]、OutputBuffer[p]表示。权重数组Weight[p][q][k2]是一个三维数组,通过以上分析可知对于权重数组的第一维参数p与第三维参数k2需使用complete对其进行优化,而对于第二维参数q则将其分割为q/4个block。行缓存数组LineBuffer[q]一个时钟周期只需进行4个输入通道数据的写入,因此将其拆分为4个block即可。对于Bias[p]、AccumulationBuffer[p]和Output-Buffer[p],由于输出通道并行度p为固定值,因此需使用complete对其进行优化。
我们以3*3的卷积计算为例,并其在外层加上一个不定循环,使用“PIPLINE”与“ARRAY_PARTITION”对计算进行优化。
优化前后的资源消耗及计算延时如图19所示。从图中可以看出,使用“PIPLINE”与“ARRAY_PARTITION”能够大幅提高计算单元的速度,但会消耗一定的硬件资源。
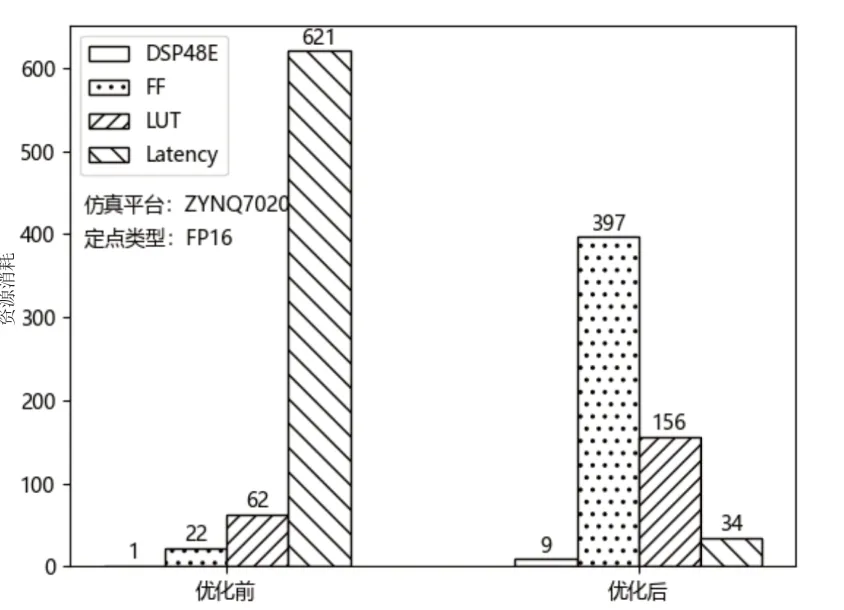
图19 卷积运算优化前后性能对比图
3 实验结果分析
实验平台使用Z-turn Board开发板,Z-turn Board是深圳市米尔科技有限公司推出的一款以Xilinx Zynq作为主处理器的嵌入式开发板,核心芯片为Zynq7020,板上配备两片512MB的DDR3、一个16MB的SPI Flash、千兆以太网接口、USB接口等外部资源,这里我们不作出具体介绍。
我们使用Vivado软件对卷积计算单元的IP进行综合设计,生成比特流文件,然后在SDK环境下进行实验测试。实验平台的资源配置如表1所示,实验设计分为两部分,首先是对不引入加速器仅使用Z-turn Board的PS端进行性能测试,然后是使用加速器的性能测试。测试所用的卷积层为YoloV3-tiny[17]网络的第一层,输入特征图参数为416*416*3,输出特征图参数为416*416*16,使用16位定点数进行计算。我们将从资源消耗、计算延时、功耗、三个角度对实验结果进行分析。

表1 实验平台资源配置表
实验测试结果如表2所示。从表中可以看出,对于资源消耗,由于使用PS(ARM A9)端进行模型推理不涉及到PL(FPGA)端的资源消耗,因此资源消耗为0,使用FPGA进行计算加速,消耗量了一定的计算资源,其中主要消耗了大量的DSP48E与BRAM_18K。对于计算延时,使用并行加速的设计大幅提高了卷积的计算速度,相较于未并行化的方案加速比可达216.91,且功率仅增加0.569W。因此,本设计能够在较小的资源消耗小取得较大的计算性能,能够为面向嵌入式的卷积神经网络加速提供一定的设计参考。

表2 加速前后资源消耗对比
4 结语
近些年来,人工智能技术快速发展,模型所需的算力不断攀升。尽管服务器级CPU或GPU能够提供强大的计算力,但其单位算力下的功耗,使其难以应用在功耗敏感的嵌入式领域。FPGA能够在保持低功耗的同时,提供强大的并行计算能力。本文通过对卷积神经网络计算特性的分析,使用循环分块、循环展开等技术,完成了一种具有通用性能的卷积神经网络加速器架构设计。引入了输入、输出通道两个维度的并行化因子,分别设计了可扩展的卷积硬件计算单元以及资源受限情况下的卷积复用结构。此外,针对片上硬件结构,分别设计了权重偏置存储结构、特征图行缓存结构、多级输出缓存结构,并使用数组分割进行设计优化。
