重型半挂牵引车行驶工况研究及其动力传动系统优化*
2022-12-08尤国贵卢剑伟苏俊收栾铭湧
尤国贵,卢剑伟,苏俊收,栾铭湧,黄 帅
(1.合肥工业大学汽车与交通工程学院,合肥 230009;2.徐工集团高端工程机械智能制造国家重点实验室,徐州 221000;3.中国重型汽车集团汽车研究总院,济南 250000;4.徐工汽车事业部技术中心,徐州 221000)
前言
合理的动力总成配置可降低重型半挂牵引车的燃油消耗,在进行整车设计开发时,定义好相关工况至关重要,要进行动力性、经济性仿真计算并优化动力总成配置,从而避免因常用工况不在发动机高效的工作区或动力不足导致的燃油油耗偏高的问题。
汽车行驶工况是表征车辆行驶的速度-时间曲线,主要用于确定车辆尾气物排放量和燃油消耗量,驾驶循环提供了在特定区域的典型驾驶行为。国内重型商用车目前使用的是C-WTVC工况,相较于国外的行驶工况,该工况是在全球重型商用车的WTVC基础上调整而得的,但该工况的代表性和覆盖性还需进一步提升。新发布的GB∕T 38146.2—2019《中国汽车行驶工况第2部分:重型商用车辆》行驶工况国家标准,虽然对不同类型的车辆行驶工况进行了分类,也丰富了车辆的行驶工况的数据量,但仍无法完全代表中国复杂的道路行驶状况。新的中国工况与NEDC、FTP75 WLTC和C-WTVC工况相比存在较大差异,中国工况更符合中国道路交通实际情况。标准通用工况在公告(汽车能耗和排放检测)认证方面有着很高的权威性,而且极具代表性。能耗和排放测试采用通用工况,可减少企业产品开发投入,减少企业检测认证费用,比较适合主机厂的公告认证。但在不同海拔和气候的城市,不同的车辆类型和车辆驾驶循环工况,车辆的燃油经济性和排放性能会有较大的差异。故国内外很多城市越来越重视自己城市的驾驶循环构建,重型商用车企业在整车匹配工作上不能完全依赖统一的驾驶循环工况。国外的学者对车辆的行驶工况进行了研究和探索,开发出了新加坡工况、马来西亚工况等具有地方特色的车辆行驶工况[1-2]。
近些年,国内的学者也对部分城市的乘用车和一些商用车进行了行驶工况构建研究。如北方环境乘用车行驶工况研究[3]、太原市公交车行驶工况构建研究[4]、大连市乘用车典型工况构建研究[5]、西安市公交工况研究[6]和合肥市乘用车典型行驶工况研究等[7],但目前对于重型半挂牵引车行驶工况创建方法研究的学者较少。吉林大学的李红雪等[8]对重型危险品半挂列车行驶工况的构建进行了研究,张海瑞等[9]对LNG搅拌车实际使用过程中的行驶数据进行分析,划分成4类行驶工况,一汽技术中心的刘延林等[10]应用数理统计和多参数统计理论,解析出自卸车行驶循环工况。因重型商用车行驶工况的研究试验周期较长和成本很大,车辆类型较多,使用工况差别巨大,如果采集车辆的数据量和周期段不足,行驶工况的覆盖性会有些欠缺。目前国内外常用的行驶工况很难完全适用于车辆行驶过程中停车较少的半挂牵引车。
而对于整车的动力性、经济性仿真和动力总成匹配工作,多数学者和主机厂都是在标准循环工况C-WTVC或CHTC-TT下进行仿真计算的,此种方法虽能提高整车动力系统匹配的效率,但标准循环工况对于特定地区车辆的行驶工况覆盖性有一定的不足,故动力系统匹配仿真计算的准确度相对较差。基于上述分析,本文中提出了一种基于山西地区重型半挂牵引车真实行驶工况的动力性、经济性仿真计算方法,此种仿真方法具有一定的先进性,仿真结果的可信度更高。对于动力总成的匹配优化能起到很好的指导作用,从而缩短新产品的开发周期,节省开发成本。
为创建山西地区重型半挂牵引车典型工况,利用车辆行车的信息大数据云平台对山西地区的半挂牵引车进行为期3个月的数据采集。通过车载服务器和云平台行车监控系统,能够对车辆行车的信息记录和数据处理。为确保数据的可靠性和准确性,在山西地区做了实地数据采集工作,以真实地反映山西地区重型半挂牵引车总体的行驶状况。利用主成分分析、聚类分析和马尔科夫方法,构建了山西地区重型半挂牵引车的行驶循环工况。基于山西工况对原车的动力传动系统进行匹配优化,使优化后的车辆能够更适应山西地区的路况,从而获得最佳的燃油经济性。不同地区代表性工况会有较大差异,特定城市或区域的重型半挂牵引车典型行驶工况的构建对车辆动力总成匹配、新车型的技术开发和性能评估研究具有更高的可信度。与车辆实际运营情况高度贴近的行驶工况,对正确引导车辆开发和标定、促进我国交通特征和使用特征的企业节能减排技术的研究与应用具有较好的实用价值。
1 数据采集
试验路段选择在山西的城市、郊区和高速等地区,为保证采集数据的完整和连续性,采用了车载终端+远程传输+跟车实地采集的数据采集方法。利用内置GPS定位、存储器等模块的车载终端将采集的CAN数据通过无线网络传送到云平台上,对车队半挂牵引车进行不间断后台数据采集。大数据云平台见图1。
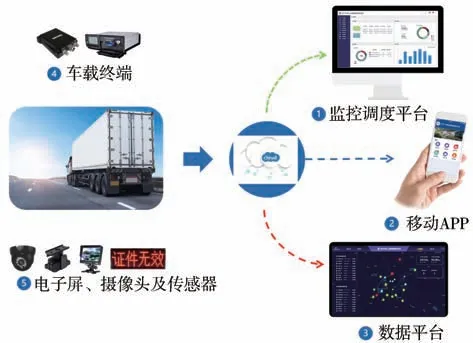
图1 车联网数据采集平台
试验团队也实地跟车进行了近半个月的数据采集工作,使用的数据采集仪能够实时采集并记录车辆行驶车速、发动机转速、发动机输出转矩、冷却液温度、油门踏板位置、进排气压力、行车距离等信号参数。将数据采集设备连接到整车OBD接口,当车辆行驶时会自动采集并保存数据,数据的采样频率设置为2 Hz。图2为使用的数据记录仪,表1为车辆的特征参数和定义情况。
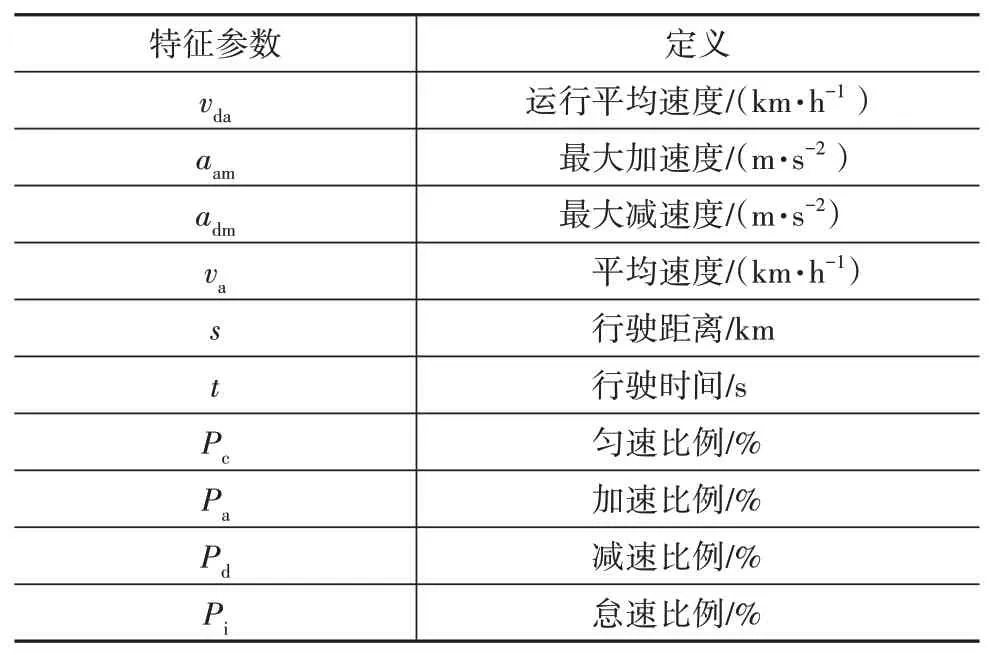
表1 车辆特征参数与定义

图2 数据记录仪
对采集的数据进行短片段相关定义和筛选原则如下。
(1)运动片段:车速从0开始到大于0,最后到等于0为止的一段数据片段。对于行程时间较短和不完整的数据进行剔除。
(2)怠速片段:车辆完成一个运动片段后,状态保持车速为0,发动机转速大于0的一段片段。要求怠速片段的时长小于200 s,如果时长大于200 s,默认时长为200 s。
(3)加速片段:车辆运行的加速度大于等于0.15 m∕s2,运行加速度小于5.0 m∕s2。
(4)减速片段:车辆运行的加速度小于-0.15 m∕s2,运行加速度大于等于-5.0 m∕s2。
(5)匀速片段:加速度的绝对值小于等于0.15 m∕s2。
表2为运动片段特征值。
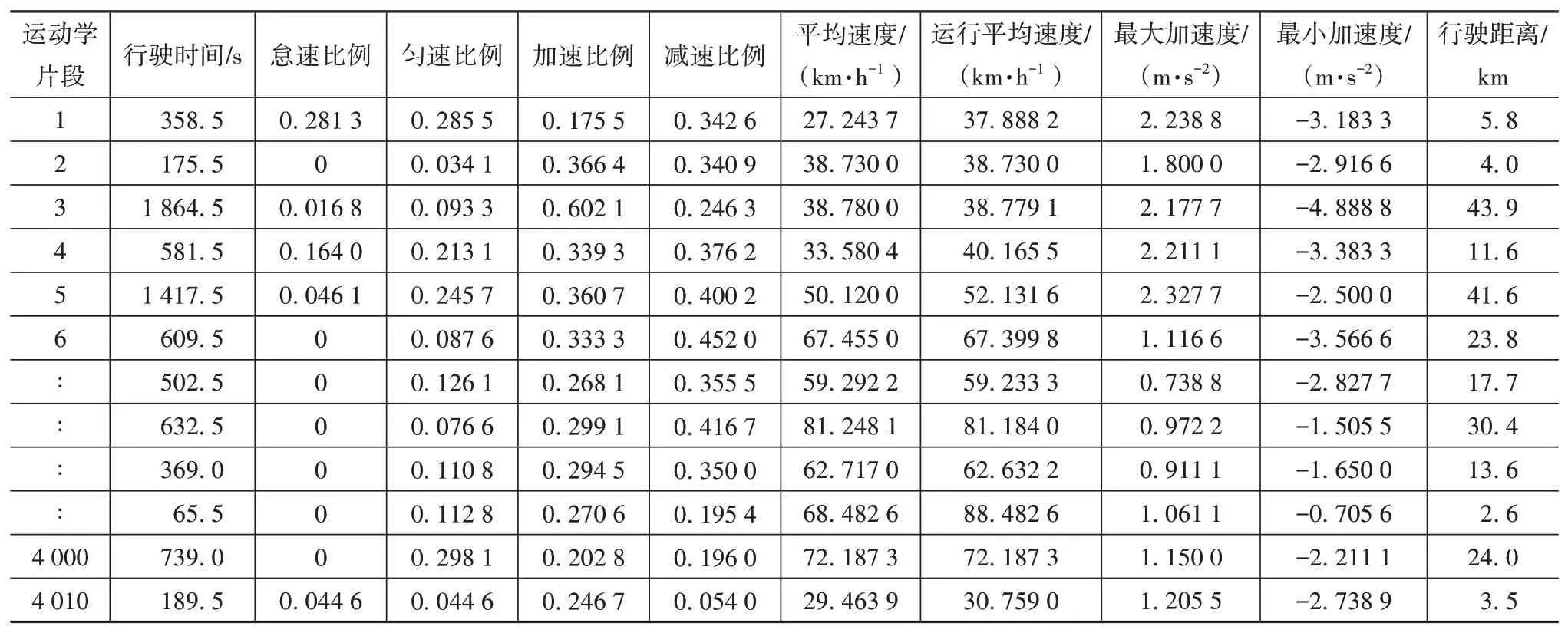
表2 运动学片段特征值
2 主成分分析
针对不同类型重型商用车进行研究,主要通过主成分和聚类分析划分工况区间,再根据区间的比重和工况循环的总时长确定各区间时长。半挂牵引车在行驶过程中会多次怠速、起步加速、制动。匀速行驶再到怠速整个循环工况,考虑到交通状况的影响,车辆行驶过程中要经历多次起停操作。将车辆行驶一次怠速开始到下一次怠速开始定义为一个运动片段。对于采集的原始数据,倘若用全部的特征参数进行分类的话,计算量会相应增加。而各个特征参数之间并不是相互独立的。为了体现短运动片段的综合特征,对多个特征参数进行降维以降低计算的复杂度。
主成分分析的主要计算步骤如下[11]。
本次采集的数据包括4 010个运动片段,每个样本共有10个特征变量描述,样本数n=4010,特征变量p=10,则可得到n×p维矩阵Z:
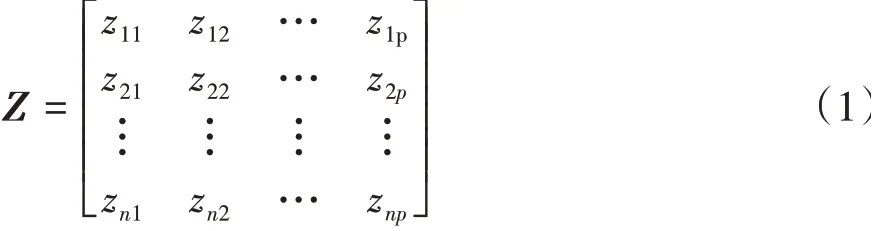
因10个特征变量的量纲会存在差异,需对Z矩阵进行标准化处理,使标准化的变量均值为0,标准差为1。标准化后的矩阵Z1为

其中:
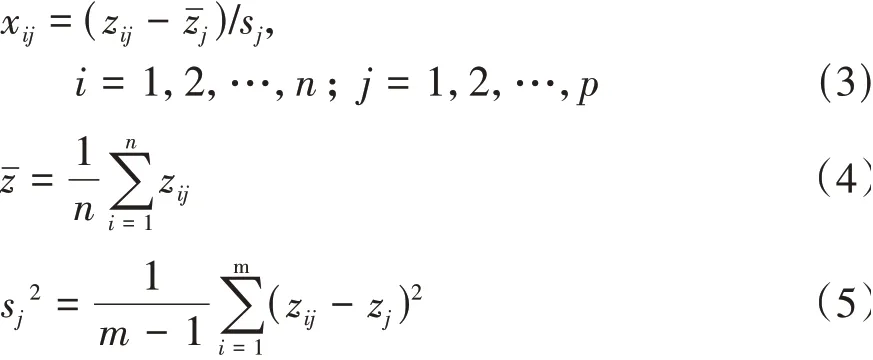
相关系数矩阵R:
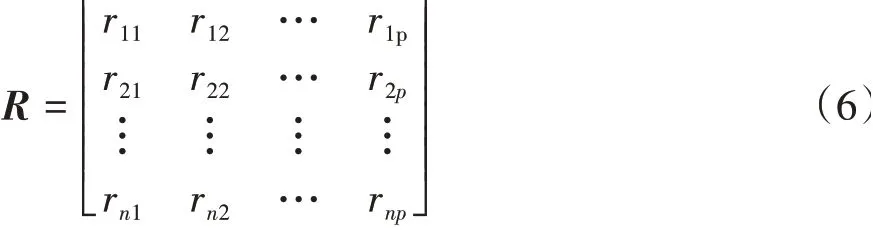
式中rij为各变量之间的相关系数:
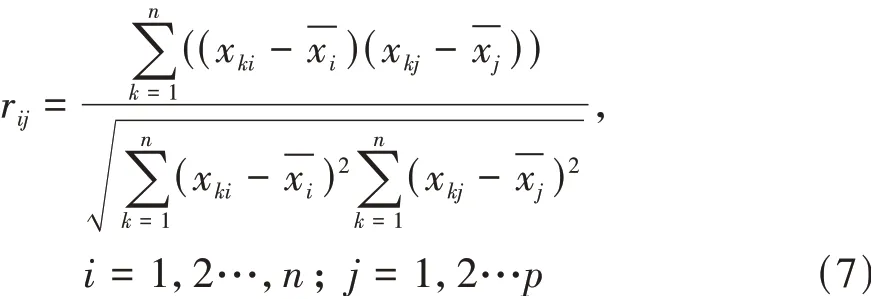
计算相关系数矩阵R的特征根,要对特征方程|λI-R|=0求解,特征根λ1≥λ2≥λ3≥λ4…≥0,求出对应的正交化的特征向量ei,eij表示向量ei的第j个分量。为第k个主成分的贡献率。ϕω=为ω个主成分累计贡献率,累计贡献率超过80%时就能满足应用的要求[12]。
3 k聚类分析
k-means聚类分析是把各个样品聚集到最近均值类之中,通过聚类分析可定量衡量样本之间的亲疏程度,以此进行分类。而片段之间的亲疏关系可用运动片段的距离来表示。计算样本到各原始聚类中心的距离为

式中xik为第i个样本的第k个特征参数,此式为明可夫距离。当q=1时,表示曼哈顿距离,当q=2时,称为欧几里德距离;当q=∞时,称为切比雪夫距离。当运算数据较大时,此算法较为高效。
3.1 工况构建
由于车辆的行驶状态的特征较多,为降低数据处理和分析难度,又尽可能地全面表征各个变量的信息[13-14],利用主成分分析方法得到各主成分的贡献率和累计贡献率,见表3。利用SPSS软件分析,得到各主成分的载荷矩阵[15],如表4所示。
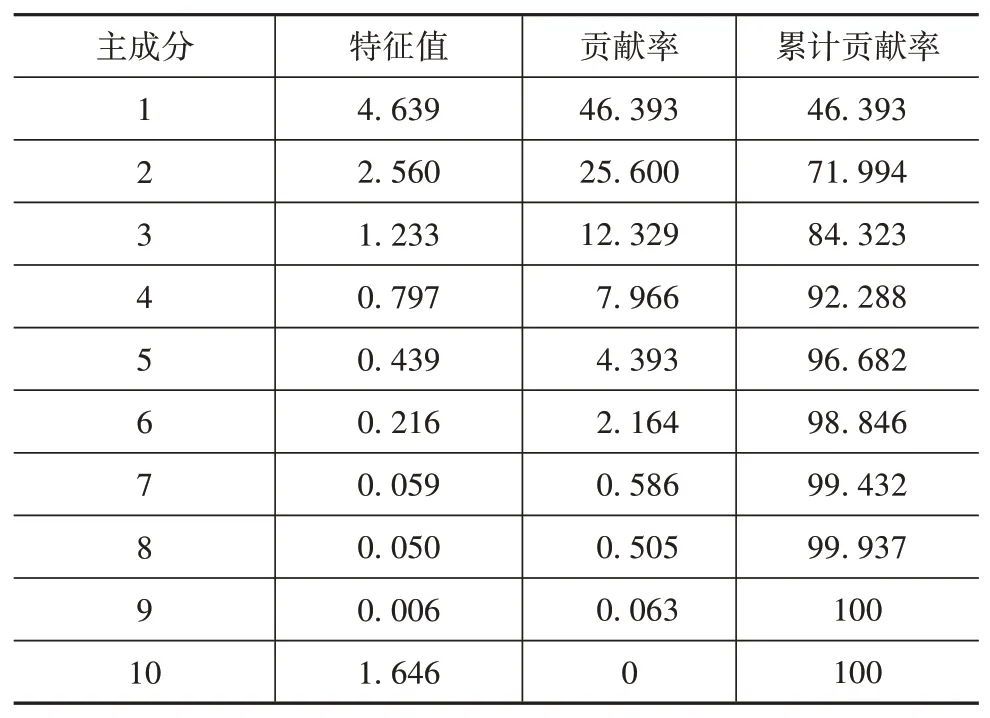
表3 主成分的贡献率及累计贡献率
从表4可以看出,第1主成分主要反映了最大加速度和平均速度以及匀速比例。
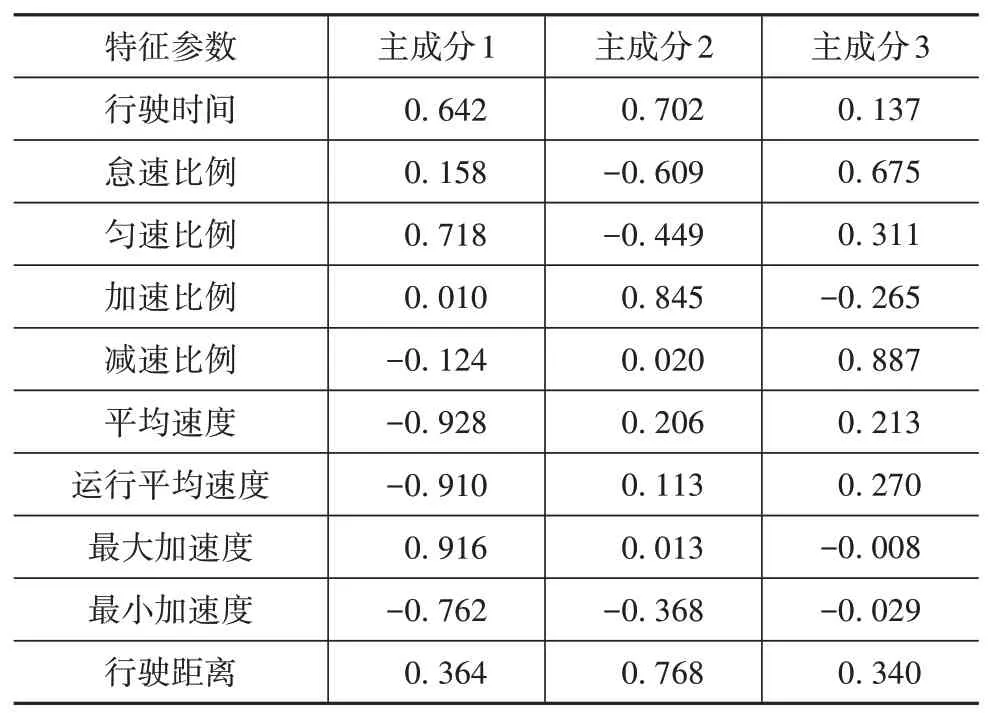
表4 主成分载荷矩阵
第2主成分主要反映行驶时间和加速比例,第3主成分主要反映减速比例及怠速比例。
3.2 k-means聚类结果
利用上文中k-means聚类分析的原理,通过Matlab软件编程对运动学片段进行分类[16-17],表5为各类运动片段库特征参数值。

表5 各类运动片段库特征参数值
根据聚类结果可以将运动学片段分为3种工况,第1类是中等车速的郊区行驶工况,第2类是路况较好的高速路段驾驶工况,第3类是较为低速较为拥堵的驾驶工况。
依据聚类片段于聚类中心的距离进行运动片段的选择,距离第1类聚类中心最近的运动片段是221。695运动片段距离2类聚类中心最近,1 100运动片段与3类的聚类中心最近。
将所属不同类的运动片段进行归类合成[18],构建获得山西地区车辆行驶工况,如图3所示。
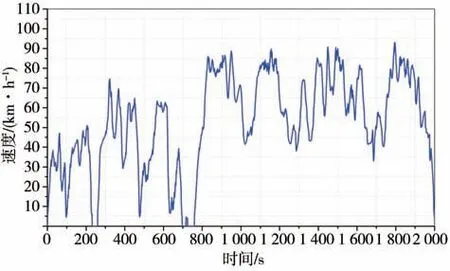
图3 山西地区半挂牵引车典型行驶工况
4 基于马尔科夫链行驶工况构建
马尔科夫过程是一个随机过程,马尔科夫链是一组具有马尔科夫特性的离散随机变量的集合。
利用状态空间的转移矩阵选择运动片段。马尔科夫过程当前时刻状态的概率只和前一时刻的状态有关,即车辆的n+1时刻状态的概率只和n时刻的状态有关,利用这一特性可将车辆的不同行驶片段进行拟合,构建成典型的车辆行驶工况。
随机变量集合为X={Xt:t>0},条件概率P={Xt=si|Xt-1=si,Xt-2=si-1,…,Xt-n=sj,X1=s1},P={Xt=m|Xt-1=n}为状态m到状态n的转移概率。转移矩阵可表示为
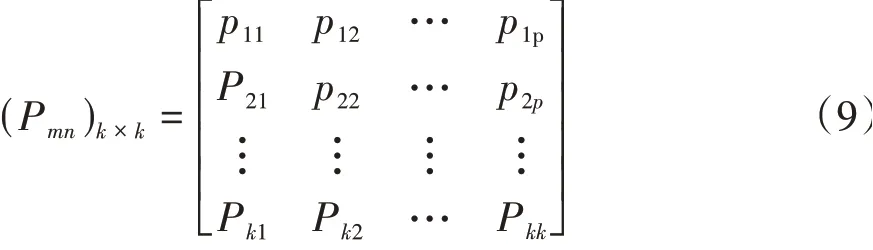
式中:每行元素之和为1;矩阵的每个元素均为非负。
状态转移概率Pmn的计算公式为

式中:Wmn是此刻状态为m、下一状态为n的次数;Wn为当前状态为n的总统计数。
马尔科夫链法的核心思想是建立能够反映实际行驶规律的状态转移概率矩阵,如果数据样本较小或状态转移概率的计算准确度不高,则得到的状态转移概率矩阵就会出现较大误差,进而影响最终的工况构建效果[19]。本文中对马尔科夫方法进行了一定的改进,以确保所构建的行驶工况对真实行驶数据的代表性。采用Modified Kneser-ney方法对状态转移概率进行平滑处理,能够避免状态转移概率值为零的情况出现,具有较高的可信度。基于马尔科夫链行驶工况构建流程如图4所示。将选取的起始片段、中间片段及结尾片段拼接成一个完整的行驶工况曲线。构建的山西工况如图5所示。
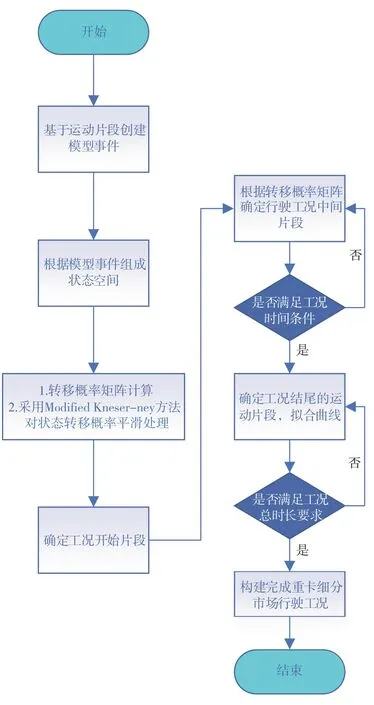
图4 马尔科夫链行驶工况构建流程
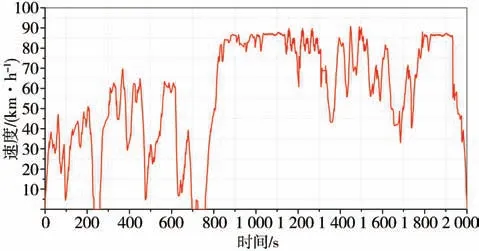
图5 基于马尔科夫法构建的山西工况
为了验证两种方法构建的工况与真实行驶数据平均加速度分布的吻合度,使用SPSS将两组工况求出的加速度值分别与真实行驶的加速度值进行K-S检验,通过与真实行驶工况数据进行误差分析,结果如表6所示。可以看出基于改进的马尔科夫方法构建的行驶工况与基于主成分分析和k均值聚类构建的行驶工况相比,曲线的拟合度更高,从代表性工况的多样性来说,也能更好地体现车辆真实的运行情况[3]。故最终的山西地区重型半挂牵引车的典型行驶工况是基于改进的马尔科夫方法构建的行驶工况。
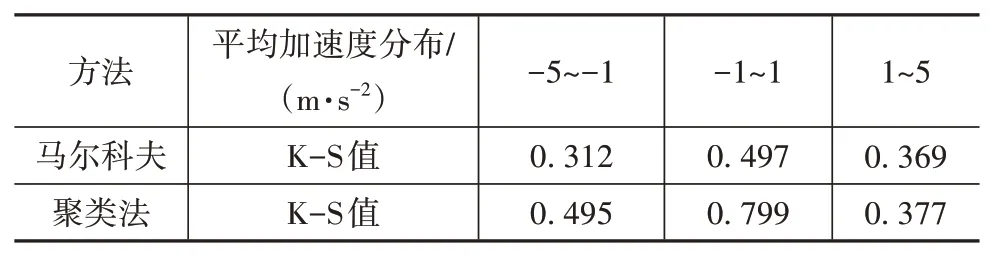
表6 两种方法构建的山西工况与真实行驶数据的K-S检验
山西工况曲线与GB/T38146.2—2019中的CHTC-TT工况曲线,以及GB∕T 27840—2011中CWTVC工况曲线在加速比例(Ta)、减速比例(Td)、匀速比例(Tc)、怠速比例(Ti)上存在着一定的差异[20],对比结果如图6所示。
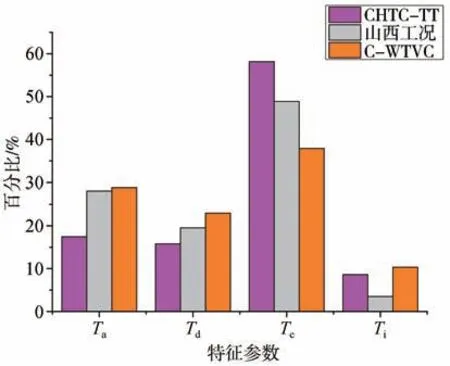
图6 行驶工况对比
根据对比分析,构建的山西工况的匀速比例和怠速比例比CHTC-TT分别低15.93%和59.34%。表明新中国工况虽能较好地覆盖各类运行区域的工况体系[21],但不能完全替代山西地区车辆的行驶工况。而目前重型商用车常用的C-WTVC工况曲线和车辆的实际行驶工况差异较大,在进行油耗测试时也有很大差异。C-WTVC相较于CHTC-TT测试结果偏小。排放结果方面CHTC-TT也略高于CWTVC。
5 基于行驶工况的动力匹配
5.1 行驶工况对比分析
将构建的行驶工况曲线、新中国CHTC-TT工况曲 线、C-WTVC工 况 曲 线 分 别 导 入Cruise∕M软 件Profile中创建整车性能仿真模型,车辆的主要参数如表7所示。图7为3种工况曲线对比图。
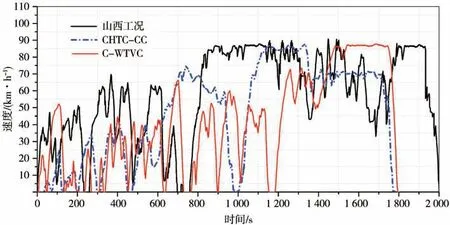
图7 3种工况曲线对比图

表7 整车主要参数
对匹配型号1变速器的半挂牵引车燃油经济性进行仿真计算,计算结果见表8。

表8 工况仿真结果对比
通过数据平台和跟车记录获得的山西地区车辆(匹配配置2)的百公里燃油消耗量为34.5 L,故仿真的山西工况的百公里综合油耗35.84 L的数据与山西地区半挂牵引车实际行驶过程油耗更为接近。证实了基于山西工况的整车动力性和经济性的仿真结果相较于基于标准的循环工况(CHTC-TT∕CWTVC)可信度更高。整车燃油经济性仿真模型见图8,从图中可看出某个时刻整车能量流分布情况。
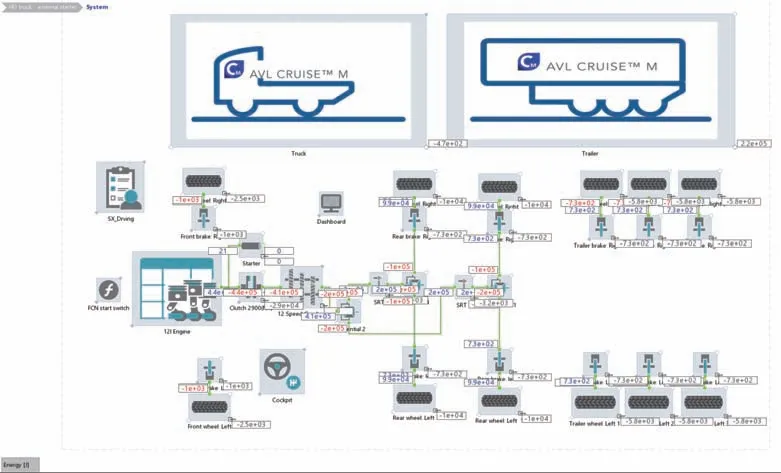
图8 整车燃油经济性仿真模型
由仿真计算结果与实车测试的油耗数据对比分析可得,构建的山西行驶工况曲线能更加真实地反映山西地区半挂牵引车的行驶特征,验证了重型半挂牵引车循环工况的合理性。图9为记录瞬时油耗和累积油耗设备。

图9 瞬时油耗和累积油耗观测设备
5.2 传动系统优化分析
如果利用遗传算法或粒子群算法等优化算法对传动系统参数进行优化,虽能获得更优的传动系参数,但考虑到现实中变速器资源条件有限,从模具和加工工艺难度等方面因素考虑,供应商很难严格按照优化后的参数进行设计,故在现有资源的基础上进行动力总成组合匹配,根据仿真结果,在满足通用工况公告认证的前提下,合理地选出符合实际、整车综合性能最优的一组动力系统配置。
基于山西行驶循环工况曲线,在原车型的基础上对整车动力传动系统进行匹配优化计算。图10是Cruise∕M软件中的山西地区工况路谱图,设置相应的挡位和速度范围。并将行驶过程中采集的坡度数据转化为车辆的行车坡道阻力,以MAP的形式加入到整车仿真模型中。图11为一段带有道路坡度数据的车辆行驶工况图。
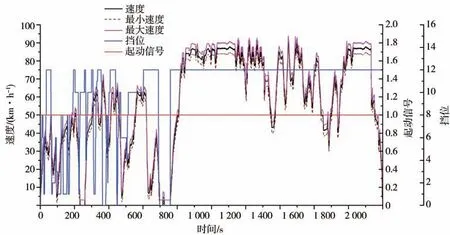
图10 山西地区行驶工况路谱
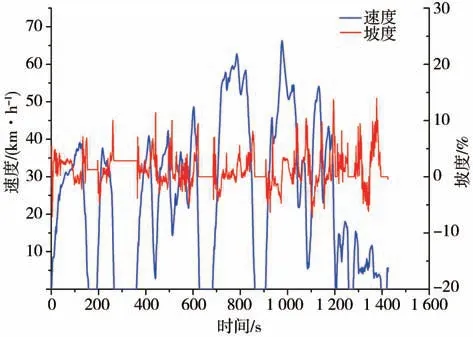
图11 一段带有道路坡度数据的行驶工况图
本文选取两款变速器C12JSDQXL220TA、C12JSDQXL220T,5款后桥减速比分别为4.11、3.7、3.364、3.083和2.846。
利用Crusie软件中的Component Variation做动力总成配置的DOE Plan进行仿真计算分析,仿真的结果能为传动系统的匹配工作提供改进意见,选配出适合山西地区工况的动力传动系统,进而优化整车的燃油经济性。图12为整个循环工况下,发动机的转速和输出转矩。
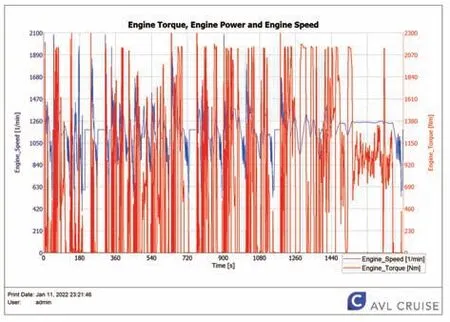
图12 山西工况下的发动机转速和转矩图
计算结果如表9所示。原车的动力总成为配置2。仿真结果可由表9显示,在发动机和轮胎均相同的条件下,可匹配C12JSDQXL220T手动变速器和速比为2.846的后桥。即配置3不仅能满足车辆的动力性能和排放标准的要求,燃油经济性也相较于其他配置最优。
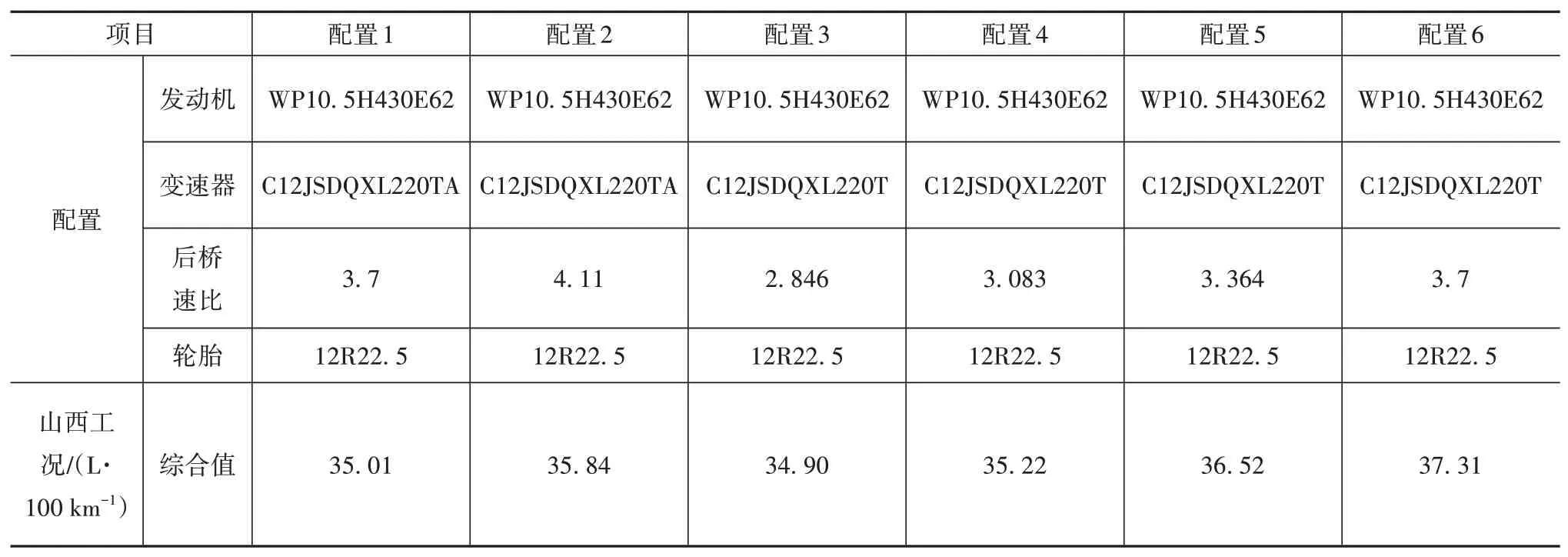
表9 基于山西工况燃油经济性仿真结果
由图13和图14发动机运行工况散点图和概率分布图可看出,配置3的发动机工作点靠近发动机燃油经济区,工作在发动机经济区域的概率更大。更适用于山西地区的路况特征。山西地区道路坡度大都小于3%,一般车辆运距小于500 km,常用车速一般为75~90 km∕h。基于山西地区半挂牵引车行驶工况,根据仿真结果可得,优化动力总成配置后的车辆,燃油经济性相较于原车提升了0.94 L∕100 km。
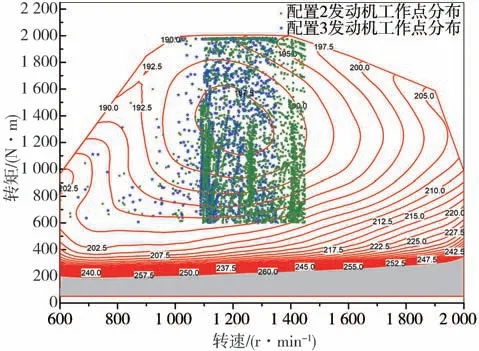
图13 配置2和配置3发动机运行工况散点图
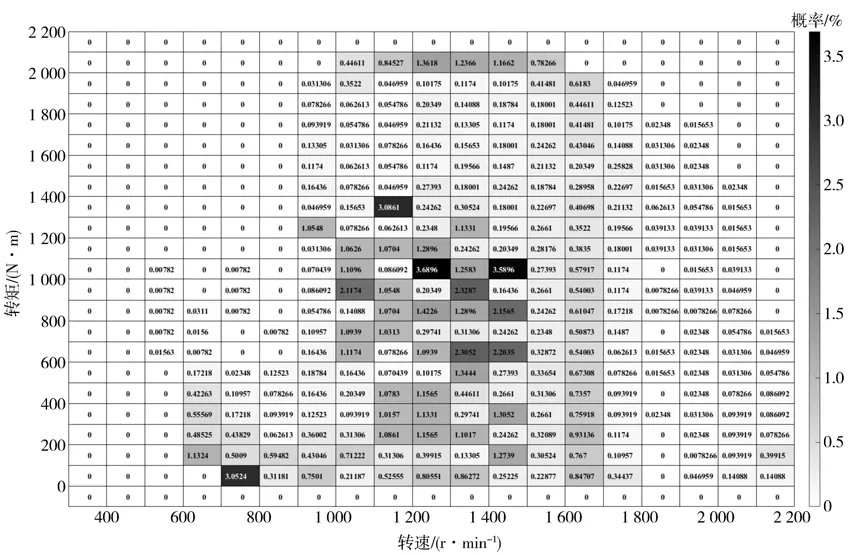
图14 配置3发动机工作点概率分布图
基于车辆真实行驶路谱的仿真计算能够较好地复现车辆的行驶阻力,仿真结果可信度更高,对整车的匹配优化工作具有重要的指导作用,不仅降低了车辆开发过程中的试验成本,而且缩短开发周期,提升了车辆的燃油经济性能。
6 结论
(1)本文采用企业车联网大数据平台和使用数据采集仪两种方式实地跟车进行车辆的行驶工况数据采集。对车辆行驶状态数据采集周期长,数据量充足,为行驶工况构建提供了重要保证。
(2)利用主成分分析法、k均值聚类和马尔科夫方法进行山西地区重型半挂牵引车工况构建,能更为客观地表征山西地区车辆的行驶工况特征。通过对山西工况、新中国工况CHTC-TT和C-WTVC的比较分析,可知新中国工况虽具备较好的覆盖性,但对于特定区域的车辆行驶工况数据仍需进一步完善。而构建的山西行驶循环工况能够真实地反映该地实际交通道路状况,具有较好的应用价值。
(3)基于山西地区重型半挂牵引车真实行驶工况,利用Cruise软件进行整车燃油经济性仿真计算,对动力传动系统进行匹配优化,得到最适合山西地区半挂牵引车行驶工况的动力传动系统配置。动力总成系统优化后的车辆相较于原车百公里节省0.94 L。实车测试采集的油耗数据也进一步验证了优化方案的准确性。
(4)构建细分市场的车辆行驶工况能为新车型的开发提供参考基准。基于车辆真实行驶工况的整车性能仿真计算对性能预测和动力总成匹配优化具有更好的指导作用。以具有城市特色且高度贴合车辆的实际工况作为产品设计开发的基础,更能够取得真实的节能减排效果。
(5)所提出的车辆行驶工况创建方法可为其他城市发展自己的行驶工况提供一定的借鉴。此外已开发的方法不仅适用于重型半挂牵引车,类似的工况构建和匹配优化方法也可应用于其他类型车辆的动力性经济性开发工作。
