基于长短期记忆网络的心理健康数据分布式采集模型研究
2022-12-06秦波
秦波
(新疆工程学院,学生处,新疆,乌鲁木齐 830000)
0 引言
人类的健康包含身体健康和心理健康两部分。心理健康表示一种可以适应所处环境,在自身认知、情绪行为、精神意识方面也能保持正常的调控能力[1-2]。人类身体健康水准持续提升、寿命延长的同时,心理健康问题日益严峻,引发社会广泛关注。全方面收集心理健康数据、研判数据所呈现出的问题是目前心理学专家们研究的重要课题[3]。而有效保证采集数据的效率与安全则成了其中的重要环节。
文献[4]使用双决策树方法实现结构化数据采集,生成一棵决策树,利用其在数据源中筛选合适的采集点,再利用另外一棵决策树评估采集点的质量,在质量最佳的采集点完成数据采样。但该模型考虑的变量较少,导致采集结果精度不高。文献[5]组建了实时采集数据模型,利用传感器采集相关信号,然后通过Kalman滤波器消除采集过程中的环节噪声,再通过零状态补偿算法消除采集误差。该模型操作复杂,在真实场景中很难得到高效利用。
为此,本文设计了基于长短期记忆网络的心理健康数据分布式采集模型。
1 基于长短期记忆网络的心理健康数据冗余过滤
心理健康数据具有一定阶段性与长期性,在采集数据过程中,极易产生冗余数据,本文使用长短期记忆网络实现冗余数据过滤,确保心理健康数据完整性与时效性。
长短期记忆网络属于循环神经网络的特殊体现,因其独有的循环架构,对时间序列拥有很强的学习能力,可以把时序内的冗余数据剔除并遗忘,降低冗余数据对心理健康数据的不良影响。反向传播神经网络是输入层传递到隐含层最后抵达输出层,各层级之间互相联系,但节点之间无连接,不能得到序列当前时段输出和上一阶段数据间的耦合关联。长短期记忆网络利用自身内部的遗忘门、输入门、输出门及循环架构[6]能对前面数据实施选择记忆同时运用于当前数据,也就是隐含层间的节点能够互相连接。
图1是长短期记忆网络时序架构。其中,xt表示目前时段单元输入,ct是目前时段单元记忆情况,能储存长期记忆,ht是目前时段单元输出。在长短期记忆网络内,目前输出值取决于上一时段状态、输出和目前输入。
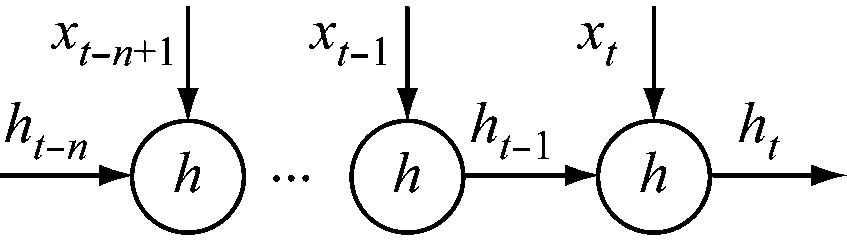
图1 长短期记忆网络时序架构示意图
长短期记忆网络详细框架如图2所示。其中,网络利用遗忘门ft、输入门it与输出门ot操控每个时段信息的输入,所以长短期记忆网络对过往数据拥有优秀的选择性[7],可妥善过滤冗余数据干扰。

图2 长短期记忆网络单元框架
遗忘门ft按照各个时段的输入xt与上一时段的输出ht-1明确上个时段的单元记忆状态内的某些长期记忆是否要遗忘。将遗忘门ft的推导解析式记作:
ft=σ(Wf[ht-1,xt]+bf)
(1)
其中,ht-1表示上个时段心理健康数据特性,Wf表示遗忘门权重矩阵,bf表示遗忘门偏置,σ表示激活函数,将其进一步拓展为
(2)
倘若在t5时段输入心理健康数据,遗忘门ft5内代表t4时段冗余数据特征的维度值约为0,并被消除于长期记忆状态。去除冗余数据特征后,引入全新特征。输入门it5按照x5与ht4决定何种信息引入长期记忆状态内,并获得全新形态ct5。将输入门与新形态的推算过程分别描写成:
it=σ(Wi[ht-1,xt]+bi)
(3)
(4)

(5)
输入门在t5时段,剔除了t4时段对数据序列的影响,把全局振荡形态特性保存于ct5内。长短期记忆网络获得全新的记忆状态后,还要产生t5时段的输出,也就是现阶段序列的短期特征ht5。输出门ot5按照新状态、上个时段输出与目前输入来得到目前时段输出[8],将其计算过程定义为
ot=σ(Wo[ht-1,xt]+bo)
ht=ot×tanh(ct)
(6)
心理健康数据序列分解重构时,需要训练长短期记忆网络。将网络分为两层,对双层网络内各个门的参变量进行持续优化,保持重构数据与初始数据处于相同状态,从而使初始数据内的多数信息都作用在重构过程中,确保重构的精确性。将重构序列描述成:
(7)


(8)
依次设定以下函数最小值:
(9)
(10)

2 基于C/S架构构建采集模型
数据分布式采集模型使用C/S形式,其整体结构如图3所示。

图3 心理健康数据分布式采集模型结构
2.1 服务器端关键功能
服务器端利用测点的基础属性,实现数据源测点和目标测点的映射,给客户端提供需要的相关信息。为了方便管理与查找,测点属性一般储存于实时数据库,客户端只保存副本即可,无须采取手动修订。若测点配置发生改变,服务器会第一时间推送修改信息于客户端,并得到更新后的本地副本。
2.2 客户端关键功能
客户端管理包含配置管理与实时情况管理。配置管理能实现快速的客户端基础信息融合,实时情况管理能测试现阶段客户端绑定的信息,获得数据链路流量具体数值,评估客户端运行模式与形态,并监测网络通信情况,完成自主管理。在心理健康数据采集预处理过程中,服务器端利用标识字符串,梳理测点和客户端间的逻辑关系。
2.3 数据分布式采集模型运行流程
1) 配置预先处理。配置预先处理是数据分布式采集的基础。首先对数据进行双重校准,去除心理健康数据源内不具备的点数据,防止服务器端和数据源测点类别不同致使采集数据不准确的问题。在预处理阶段,挑选部分属性值完成映射表重构,能增强搜索速率,降低数据包长度,让传输质量得到质的提高。
2) 数据变换。从源数据库读取当前心理健康数据后,一般要按照测点配置进行3种数据变换。数值二次变换可以处理元数据的单位与基准值问题。一对多变换能解决单个源测点响应若干目标测点的状况,利用变换过程维护数据采集完备性。
3) 数据传输。基于C/S架构的心理健康数据分布式采集模型的重要功能就是数据传输,为了增强数据传输时效,从以下2个角度完成数据传输处理。
(1) 网络链路要使用长连接方式。由于数据源和目标服务器传输间距很长,为得到较快的传输速率,数据传输运用长连接方式。输送数据量不多时,使用周期性传送心跳包模式保持链路平稳,降低因路由器、防火墙等设施的超时策略而出现网络传输断开现象。
采用变长数据包。依照数据包头消息,实现数据整体核查、分包和分析。变长数据包模式如图4所示。

图4 数据包模式示意图
(2) 在传输板块引入数据缓存制度。凭借数据分布式采集特征,在传输板块内代入数据缓存。短时间内的网络故障、数据会被缓存至内存,系统处理不包含任何运行开销。假如采集模型发生故障的时间很长,为维护后期采集结果真实性,会把数据保存在本地文件。图5为数据缓存架构示意图。
为了维护心理健康数据安全性,模型多功能板块互动时,使用线程安全队列,降低模型功能板块间的相关性,完成高质量数据分布式采集目标。
3 仿真实验
为了证明本文模型的实用性,将其与文献[4]、文献[5]模型展开仿真检验,实验包含有效性检测与能耗检测两部分。

图5 数据缓存结构图
3种模型的采集误差绝对值如图6所示。

图6 心理健康数据分布式采集误差绝对值对比
分析图6可知,本文模型的采集误差绝对值最小,始终小于0.2。文献[4]与文献[5]模型检测误差较高,且采集过程的稳定性略差。这是因为本文模型利用长短期记忆网络过滤了心理健康冗余数据,能获得具有参考价值的心理健康数据,误差绝对值也随之降低。
根据心理健康数据时间跨度大等性质可以看出,数据采集过程中具有不稳定因素,将不稳定因素拟定为不良系数,取值区间为0~1。比较3种模型的数据采集时间,结果如表1所示。

表1 心理健康数据分布式采集消耗时间对比 单位:ms
分析表1可知,本文模型受到不良系数的影响较小,有效抵御了因为复杂外部环境引发的采集效率低下问题,拥有很强的实用性及鲁棒性,为心理健康数据的快速采集与分析提供充分保障。
4 总结
本文针对心理健康数据时间跨度大、数据类型复杂等问题,运用长短期记忆网络剔除冗余数据,并采用C/S架构创建数据分布式采集模型。该模型未考虑区域发展给心理健康数据带来的差异,下一步将融合不同地区发展数据来衡量心理健康数据采集可靠性。
