公平低时延的太赫兹无线个域网定向MAC协议
2022-12-06李维政刘奕君
任 智,李维政,何 亮,刘奕君
1(重庆邮电大学 通信与信息工程学院,重庆 400065)
2(重庆邮电大学 移动通信技术重庆市重点实验室,重庆 400065)
1 引 言
随着物联网、虚拟现实等高速数据传输业务的发展,未来的无线速率需求可能会达到数10Gbps.现如今所许可的通信频段无法满足这个需求[1],太赫兹波是介于无线电波与光波之间的电磁波,频率范围在0.1Thz到10.0Thz之间,支持100Gbps以上的传输速率[2-4],是未来超高速通信的备选频段[5-7].由于其频率特性,方向性好,在水中易衰减,所以更适合短距离通信,一般通信范围在10米以内[8],多应用于无线个域网(Wireless Personal Area Network,WPAN)和无线局域网(Wireless local area network,WLAN)[9].
太赫兹无线个域网MAC协议以最新的802.15.3[10]为标准,定向部分以802.15.3c[11](简称3c)的MAC部分为重要参考,曹建玲等人提出[12]更改太赫兹无线个域网MAC协议的超帧结构,将竞争接入时期提前,合并同一对节点间的时隙请求,可以降低时延,避免组网初期的时隙浪费.Akhtar A[13]提出了一种基于波束赋形监听机制的MAC协议(ENLBT-MC),其思想是一旦某一节点处于波束赋形时期,其它节点则监听波束赋形帧,后续与这一节点进行数据传输前就不需要进行波束赋形.在移动场景下,上一个节点的波束赋形结果不一定适用于下一个超帧,所以这种方法存在风险,一旦相对扇区产生变化,数据就会发送失败,直至分配的CTAP结束.Han C等人[14]提出了角分复用存储波束赋形结果的方法,用存储来减少后续再次进行数据传输的波束赋形开销,与ENLBT-MAC类似,存储下来的波束赋形结果可以应用于同一个超帧内,CTA比较靠近的时候,比较适用于静态节点.动态情况下,移动节点出错概率比较大,反而会造成数据无法正确接收,协议要严格控制节点之间的对准效果,就要在数据传输的近期及时更新波束赋形结果.邱钟维[15]提到在太赫兹无线个域网定向MAC协议的开发实现中,为了增大时隙利用率,往往会将超帧长度设置为接近最大值,因此超帧时间比较长,上一超帧的结果不适用于下一超帧.AD-MAC[16]提出了各时期的复用机制及静态场景下的全网波束赋形机制,前者源节点发送消息时其它节点可以进行空分复用,但是目的节点回复消息时仍然可能发生碰撞.后者按照节点序号,采用一对所有节点的方式进行波束赋形,一次完成所有节点之间的波束赋形.比较冗余,对于动态节点来说时效性比较差.FLL-MAC针对目前的太赫兹MAC协议理论研究,结合实际设计中的参数,提出了公平低时延的时隙分配机制.解决了太赫兹定向MAC协议存在的时隙分配不公平、同一超帧内多次数据交互的移动节点的波束赋形问题,数据交互重复率为50%的时候可以减少约25%的波束赋形开销,100%重复率时最大可减少近50%的波束赋形开销;提出了新的标准帧聚合重传机制,可以避免因无法解析子帧导致的整个聚合帧的重传,可减小重传开销,降低时延;提出了入网和时隙请求的结合机制,减小了信息请求的碰撞概率,可有效降低时延.后两者在设置多节点和5%左右的错误率的情况下可降低约18%的时延.
2 网络模型及问题描述
2.1 网络模型
太赫兹无线个域网定向MAC协议在802.15.3c的基础上制定最终的标准.太赫兹无线个域网定向MAC协议的网络模型中存在一个中心控制节点(Piconet coordinator,PNC)和多个普通节点(Device,DEV).所有节点入网或者数据交互都需要经过PNC的同意.
时间上分为多个连续的超帧(superframe),如图1,每个超帧的时间根据超帧内的数据量变化.超帧由3个时段组成,分别是信标时期(Beacon Period,BP),竞争接入时期(Contention Access Period,CAP)和信道时隙分配时期(Channel Time Allocation Period,CTAP),Beacon时期PNC发送上一超帧期间节点申请的时隙分配等信息给微微网内的节点,CAP时期各节点申请入网以及申请时隙,CTAP各节点在自己所申请到的时隙(CTA)内进行波束赋形和数据传输.

图1 超帧结构图
2.2 问题描述
1)a:目前的太赫兹无线个域网研究中对于CTAP时隙分配的改进很少,大多数采取的机制都是PNC循环接收DEV发送的时隙请求帧,接收到后根据CTAP的时间顺序,按需的给DEV分配时隙.CAP时期各节点在Regular S-CAP申请时隙,PNC循环接收时隙请求帧,收到时隙请求帧后回复时隙请求回复帧给各节点按需分配CTA.如果按照标准的时隙分配机制分配的话,位于后面扇区的节点分配到的时隙比较少,这种情况有失公平性.
b:原机制还不适用于多个节点之间相互进行通信的情况,例如微网内A与B、B与C、C与D、D与A之间都要进行通信,那么传输数据之前总共需要进行4次波束赋形,同一个节点需要进行多次波束赋形.所以现有的时隙分配机制存在不合理之处,忽略了多节点互相通信的情况.
2)标准帧聚合的重传机制中,聚合帧的确可以省去很大一部分的物理层开销,但是帧越大越容易出现错误,而出现错误就需要重传,对于聚合帧中的MAC子头部出现问题的情况,例如MAC子头部长度字段出错的情况,就无法提取对应的子帧,相应的后面的子帧也无法正确提取.子标头其它字段出错也会出现相同的问题.标准是直接进行整个帧的重传,这样的重传机制效率极低,降低了数据吞吐量.
3)根据3c标准中的节点入网和时隙申请规则,在超帧的Association S-CAP时段,PNC首先需要旋转天线方向依次扫描每个扇区,并停留一段时间以便接收来自该扇区的DEV发送的入网请求帧.如果接收到,那么就发送入网请求回复帧,然后经过一个保护时隙进入下一个扇区,直到遍历完所有的扇区,进入Regular S-CAP时段.这一时期PNC仍然类似于关联时期,依次扫描每个扇区,循环一周接收时隙请求帧,收到则回复时隙请求回复帧,直到结束.如果一个扇区节点比较多的话,那么就有多个节点的请求消息发生碰撞的可能,且可能性存在于两个阶段.
3 FLL-MAC协议
针对上述问题,提出了一种公平低时延的太赫兹无线个域网定向MAC协议,协议将时隙请求阶段的过程由一次申请一次及时回复改成一轮申请一次循环回复,根据按需分配时隙的不公平问题,提出公平分配机制.根据多节点相互进行数据交互的情况,将重复节点的CTA聚集在一起,采用一对多的波束赋形方式减去冗余的波束赋形操作.根据聚合帧子帧头部传输错误的情况提出重传聚合帧子头部的方法,结合了入网和时隙请求过程以减少碰撞的可能性.
3.1 公平低时延时隙分配机制
针对问题描述1中的b案例的解决方法是:1)A同时对B和D进行波束赋形训练,等待A发送完波束训练帧;2)B和D依次循环发送波束训练回复帧,A记下来B和D所在扇区号;3)A先与B进行数据交互;4)A转换天线方向至D所在扇区,接收D所发送过来的数据;5)C同时对B和D进行波束赋形训练;6)参考A与B、D的步骤.这个过程与标准波束赋形机制的区别在于重复节点同时对多个节点进行波束赋形训练,首先发送波束赋形训练帧的节点不固定于源节点,从这个例子中可以得出,可以节省两个第一轮波束赋形的时间,也就是2n×n个时间单位(一个时间单位为发送一个波束赋形帧的时间,n代表扇区个数).
CTAP时期所有节点的时隙分配都是由PNC来分配,然后在下个超帧的Beacon时期将信息发布出去,所以需要在时隙分配机制这里做一个算法改进,公平低时延时隙分配机制步骤为:
步骤1.时隙请求开始阶段,PNC存储之前超帧未分配的时隙请求信息,结束转步骤2.
步骤2.PNC操作:循环一周,在每个扇区接收时隙请求命令并存储下来各节点所需的时隙长度,每个扇区停留时间为原时间的一半.DEV操作:在PNC转至自己所在扇区时发送时隙请求帧,采用CSMA/CA竞争接入机制;时隙请求结束后转步骤3.
步骤3.PNC按照各节点的时隙请求量,先按平均分配原则给所有PNC同意分配时隙的节点分配CTA,分配结束后如果存在节点的CTA申请量低于平均水平,转步骤4,否则转步骤5.
步骤4.CTA申请量低于平均水平的节点把多的CTA平均分配给其它节点,结束转步骤5.
步骤5.PNC计算重复节点CTA的聚集优先级,首先选出重复次数最多的节点,如果选出了多个节点,重复次数相同,那么先申请的节点优先级更高.结束转步骤6.
步骤6.将选出的重复节点的相关CTA聚集在一起,然后去掉其它重复节点中包含的上述相关CTA.结束后判断是否还有重复节点,是转步骤5,否则转步骤7.
步骤7.按照单对节点或者多对节点中最早申请时隙的节点的时隙申请先后顺序,将CTA或者聚集CTA放入CTAP时隙,结束转步骤8.
步骤8.PNC遍历所有扇区,发送每个节点的时隙请求回复命令,遍历结束转步骤9.
步骤9.下一超帧的CTAP时段,按照CTA顺序,各节点判断自己是否为重复节点,是则转步骤10,否则转步骤11.
步骤10.重复节点针对它的源节点或者目的节点进行第一轮波束赋形训练,循环一周结束后重复节点进入第2轮波束赋形接收时期;重复节点的源、目的节点按照申请时的顺序,在各自CTA内依次循环发送波束赋形回复帧进行第2轮波束赋形,然后在各自CTA内进行数据传输.CTAP结束进入下下个超帧,未结束转步骤9.
步骤11.未重复节点的源节点先进行第一轮波束赋形,然后目的节点进行第二轮波束赋形.结束后在剩余CTA内进行数据传输.CTAP结束进入下下个超帧,未结束转步骤9.
这种机制不仅可以公平的分配CTAP的时隙给各个DEV,而且还可以节省重复节点的波束赋形时间,考虑到无线个域网内的节点大多数都是移动节点,尤其是达到波束级波束赋形的时候,每个扇区角度很小,导致微小的移动都会影响扇区,所以波束赋形和数据传输的时间间隔不宜过长.
3.2 帧聚合子帧重传机制
针对3c标准中聚合帧MAC子标头传输错误的情况,提出重传子标头的机制,其思想是源节点重传MAC子标头给目的节点,目的节点根据新的MAC子标头解析MAC子标头错误的聚合帧.将每个子头部的保留字段设置为1,表示此重传帧为重传子标头,子帧长度等信息仍然是之前子标头错误的聚合帧的信息,负载为空.重传聚合帧只有头部以及尾部的FCS检验序列,子帧错误时重传错误的子帧.
如下设计为新的聚合帧重传机制,实现了哪部分错误,重传哪部分的功能.具体步骤如下:
步骤1.目的节点收到聚合帧后,解析聚合帧帧头,如果子标头错误,转步骤3;否则转步骤2.
步骤2.目的节点提取子帧头部内容,如果子帧头部保留字段为1,那么提取缓存区子帧,不为1则提取子帧.然后进行CRC循环冗余检验,如果错误转步骤4;否则转步骤7.
步骤3.目的节点缓存子标头错误的聚合帧帧体,并发送块确认帧给源节点,请求重传子标头,转步骤6.
步骤4.目的节点发送块确认帧给源节点,请求重传错误子帧,转步骤5.
步骤5.源节点接收到块确认帧后提取错误子帧序号,重传错误的子帧,转步骤2.
步骤6.源节点提取块确认帧中的内容,重传没有负载的聚合帧.聚合帧子帧头部的保留字段置1,表示重传帧为重传子标头,其它字段与前一个错误帧子标头相同,转步骤1.
步骤7.目的节点给源节点发送块确认帧,源节点收到后解析,然后发送下一个聚合帧,目的节点等待接受下一个聚合帧.
新聚合帧重传机制流程图如图2所示,采用这种机制重传可以避免因子标头传输错误无法解析子帧而进行的全部子帧重传.降低了时延,增大了吞吐量.

图2 重传机制流程图
3.3 入网时隙请求结合机制
该方法的思路是将在同一超帧内入网和请求时隙的节点(统称A类节点)合并到同一个时期,这个操作由DEV和PNC共同完成,标准的关联时期是非常复杂的,如果能省去这个过程,对时隙浪费会有一定的减少,并且当节点很多的时候可以减小入网和时隙请求过程中碰撞的概率.
时隙请求时期每个时隙请求帧的帧长是有限制的,如图3所示为入网时隙请求过程帧格式,CTRqB代表的是时隙请求信息,每一个CTRqB代表这个节点与某一个节点之间的时隙请求块.关联时隙请求命令格式如a所示,原入网请求命令字段的长度相对于时隙请求命令来说较短,只有22个字节.所以如果某个节点想在时隙请求阶段既入网也申请时隙.那么就把入网请求帧的主体信息放到时隙请求帧的第一个时隙请求块的位置,然后重新定义一种新的命令类型,关联时隙请求命令.标准中命令类型字段长度为2字节,0x001D-0x00FF为保留字段,定义0x001D为入网时隙请求命令.

图3 CAP命令格式
如图3中b,因为入网请求回复命令比较长,且末尾有供应商特殊字段可以延伸.而时隙请求命令比较短,所以把时隙回复字段加入到供应商字段之前.同样,回复命令类型为入网时隙请求回复命令,定义0x001E为入网时隙请求回复命令.
4 性能分析
对比ENLBT-MAC协议和802.15.3c标准,FLL-MAC所提出了“公平低时延时隙分配机制”、“帧聚合子帧重传机制”以及“入网时隙请求结合机制”3种机制.此部分从理论上对FLL-MAC协议进行性能分析.
推论1.在动态场景下,FLL-MAC协议的波束赋形开销比ENLBT-MAC协议低.
证明:设SFLL为FLL-MAC的波束赋形开销,Y表示重复节点数据交互次数,N表示重复节点个数,y表示重复次数,波束赋形帧长为l,n表示扇区个数,ENLBT-MAC协议在完全动态情况下反而会增加波束赋形开销.在i%节点移动的情形下,当移动节点占比比较大的时候,FLL-MAC的波束赋形开销相对来说要小很多.对比3c标准、ADM-MAC和ENLBT-MAC协议的波束赋形开销,重复节点波束赋形总开销分别为:
S3c=Y·l(n2+n)
(1)
SEN=Y·l(i%·(n2+2n)+(1-i%)·n)
=i%Y·l·n2+(1+i%)·Y·l·n
(2)
SFLL=(Y-y)·l(i%·(n2+2n)+(1-i%)·n)
=i%(Y-y)·l·n2+(1+i%)·Y·l·n
(3)
假设节点个数为4,两对节点通信的情况下,根据概率论得知重复概率为PFLL,计算可得PFLL约为51.56%,而重复次数为1或2,概率比为1∶2.
(4)
当重复节点达到50%的重复率时,波束赋形的总开销减少了将近25%.而当节点个数为4个以上时,并且通信节点对大于2时,波束赋形总开销相比ENLBT-MAC减少了大约20%,重复节点占比较大时,几乎可以减少50%的波束赋形开销.
推论2.FLL-MAC协议的时隙分配更加公平.
证明:“公平低时延时隙分配机制”中提出的节点先请求时隙PNC再统一分配的机制可以公平的给每个节点分配CTA,保证每对节点的数据传输速率大致相同.其它协议的时隙分配机制中先申请的节点先分配CTA,显然无法满足速率相同的需求.
推论3.FLL-MAC协议的入网和时隙请求成功率更大.
证明:“入网时隙请求结合机制”省去了A类节点的单独入网请求过程,设P1代表FLL-MAC协议的A类节点入网时隙请求的碰撞概率,P2代表ENLBT-MAC和3c的A类节点入网时隙请求碰撞概率.P3代表FLL-MAC协议的其它节点入网请求的碰撞概率,P4代表ENLBT-MAC和3c的其它节点入网请求碰撞概率.扇区个数为n,入网节点数为N1,时隙请求节点数为N2,同时入网和请求时隙的节点数为N3.当前超帧内发生碰撞的概率为:
(5)
(6)
(7)
(8)
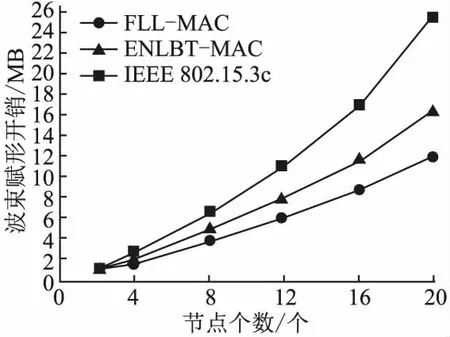
从P1和P2的表达式明显可以得出P1 本文的验证平台是OPNET14.5通信仿真网络仿真软件,对比FLL-MAC协议、802.15.3c标准以及ENLBT-MAC协议的性能进行仿真分析.仿真中设置的数据传输对象是随机的,每个节点与其它节点的通信概率相同. 流程1.定义进程模型,MAC层进程模型包含Init、Beacon、CAP、CTAP这4个状态机,分别对应初始化和超帧的3个阶段. 流程2.定义的节点模型分为5层,应用层、传输层、网络层、MAC层和物理层,物理层设置有定向天线模块以发送定向数据,传输层和网络层采用透传模式. 流程3.构建网络模型,3种协议的场景设置都一样,在一个10×10m内放置多个节点,PNC放置在场景中心,其它节点环绕在PNC周围以每秒10m的速度随机或者顺时针移动. 流程4.收集统计量、仿真调试,OPNET软件可直接统计网络内的数据传输总量以及对应的时间,通过计算节点发送和另一节点接收数据的时间差计算发送和接收时延.统计应用层的数据包发送和接收个数来确定仿真成功率.设置固定的错包率来对比重传效率.ENLBT-MAC在3c的基础上修改了核心代码,而FLL-MAC是在ENLBT-MAC的基础上修改了时隙分配代码、帧聚合代码,以及竞争接入时期的代码.3种协议的对比是在一套协议仿真模型下进行的,通过对比各自的统计量,观察控制帧的时序来调试仿真代码. 流程5.仿真结果分析,通过对统计量进行进一步计算,得出吞吐量、数据传输时延以及波束赋形开销. 表1所示为具体的参数设置. 表1 仿真参数设置 收发信机设置数据率为10Gbps,发送功率为40W,带宽为3GHz,最小频率为0.14THz,采用调制方式为qam64;天线设置主瓣形状为锥形,张角为5度,主瓣内天线增益为20dB. 应用层设置产生数据包的时间为0.5s,间隔时间为0.0005s,数据包大小为700MB. 5.3.1 网络吞吐量 网络吞吐量如图4所示,仿真设置节点个数每次加4,而重复节点的比例稳定设置为50%,相比ENLBT-MAC,FLL-MAC的数据吞吐量提升了大约7%,具体与数据包大小有关.FLL-MAC与ENLBT-MAC协议和802.15.3c标准对比起来之所以能够有效提升是因为:1)FLL-MAC协议在动态场景下存在多个重复节点的时候,其波束赋形效率更加高,且不会出现因为波束方向没对准而导致数据接收不到的情况.2)采用“帧聚合重传机制”可以使因为子标头错误导致的重传帧的大小减小.虽然出错的概率很小,但是一旦子标头出错,在原机制下重传所有子帧是非常耗时的. 图4 MAC层数据吞吐量 5.3.2 波束赋形开销 波束赋形开销如图5所示,在50%重复率的情况下,FLL-MAC相比ENLBT-MAC可减少20%左右的波束赋形开销.FLL-MAC协议与ENLBT-MAC协议、802.15.3c标准相比能够节省波束赋形开销的原因是FLL-MAC协议在某些节点多次通信的时候,可以节省这些节点需要进行的波束赋形次数,这样每个节点只需要进行一次波束赋形操作.把重复的节点分配到的CTA排在一起,可以避免节点运动导致波束方向对准失效. 图5 波束赋形开销 5.3.3 平均时延 数据平均时延如图6所示,FLL-MAC相比ENLBT-MAC可降低18%左右.ENLBT-MAC和802.15.3c标准相比,由于FLL-MAC协议波束赋形所花的时间更少、开销更低,帧碰撞概率更小,重传帧更小,所以能够更快地进行数据传输.其次,由于CTAP分配机制的公平分配原则,不会出现一个超帧内某对节点分配的CTA很多,而其它节点分配不到CTA或分配的CTA极少的情况.这样的结果就是所有节点的数据传输时延是大致相同的. 图6 数据平均时延 本文针对现有的节点重复波束赋形、时隙分配不公平等问题,提出了一种公平低时延的太赫兹无线个域网定向MAC协议.包含“公平低时延时隙分配机制”、“帧聚合子帧重传机制”以及“入网时隙请求结合机制”.机制一先申请再分配的机制统一分配一个超帧内的CTA,并将重复进行数据交互的节点的CTA放在一起,对多节点同时进行波束赋形.机制二重传子标头避免子标头错误导致的传输子帧.机制3结合A类节点的入网和时隙请求过程,减少碰撞概率并减少控制开销.针对太赫兹MAC协议仍然存在的问题和可优化处,可以从空分复用等方面进行研究.5 仿真验证
5.1 仿真流程设置
5.2 仿真参数设置

5.3 仿真结果分析


6 结束语
