信息蒸馏与异构上采样的眼底图像超分辨重建
2022-12-06李航宇玄祖兴周建平胡晰远程钢炜
李航宇,玄祖兴,周建平,胡晰远,程钢炜
1.北京联合大学 北京市信息服务工程重点实验室,北京 100101
2.北京联合大学 数理与交叉科学研究院,北京 100101
3.安徽工业大学 计算机科学与技术学院,安徽 马鞍山 243032
4.南京理工大学 计算机科学与工程学院,南京 210094
5.北京协和医院 眼科中心,北京 100005
眼底图像是许多眼部和全身疾病的诊断工具,包括糖尿病视网膜病变、青光眼、恶性高血压和多发性硬化等[1]。然而,由于高清眼底照相设备价格昂贵且不便于携带,许多贫困地区的大规模疾病筛查主要依靠便携式手持摄像机和远程诊断来完成。研究表明,这一过程获得的眼底图像质量较差、分辨率低,不利于医生的诊断[2-3]。同时,尽管正常的眼底图像具有较高的分辨率来方便医生对图像的分割和诊断,但在一些较暗的光线和角度下拍摄的图像,不足以清晰地显示小的部位(微动脉瘤,出血,血管分支)。目前,在不升级硬件的情况下,超分辨的方法有望解决这个问题。
由一幅或多幅低分辨率(low-resolution,LR)图像生成对应高分辨率(high-resolution,HR)图像的过程称为图像的超分辨率重建[4](super-resolution,SR)。在多幅图像的SR任务中,利用同一场景下的多幅LR图像提取信息生成一幅HR图像,这不仅需要从同一场景下对图像快速获取,并且需要将它们快速地配准,这本身就是具有挑战的问题,同时,这往往伴随着巨大的计算量。因此,眼底图像的SR任务更适合由单幅图像来生成。
在过去的研究中,SR领域有许多出色的工作,传统的SR算法大致分为基于插值的算法和基于学习的算法两大类。其中插值算法包括双线性[5]、双三次插值[6]等方法,都被广泛应用于医学图像的SR任务。可是由于HR图像是由LR图像像素间进行数学插值得到,在细节处往往会产生模糊。字典学习[7]和锚定邻域回归[8]等属于基于学习的算法,它们往往需要大量的数据作为支撑,在数据不完备或者数据不匹配(例如用自然图像作为字典来表示眼底图像)的情况下,效果经常不理想。
随着深度学习的快速发展,各种深度学习方法也成为了SR领域的研究热点。其中基于卷积神经网络的SRCNN[9](super-resolution convolutional neural network)和FSRCNN[10](fast super-resolution convolutional neural networks),它们较早被提出并应用于医学图像的SR任务[11]。VDSR[12](very deep super-resolution networks)、EDSR[13](enhanced deep super-resolution network)和RCAN[14](residual channel attention networks)通过构建局部和全局残差结构使网络深度增加来提取深度特征。但是它们需要巨大的参数量,并且对于数据量少且特征单一的医学图像,训练比较困难。同时,也有许多工作围绕网络轻量化进行。CARN[15](cascading residual network)采用级联结构在稳定训练的同时只使用了极小的参数量,在自然图像上取得了优异的结果并应用于眼底图像的SR任务[16]。IDN[17](information distillation network)提出了信息蒸馏结构,它将提取过程中的浅层特征明确地分成两部分,一部分保留,另一部分被进一步处理,该结构可以有效地提取局部长路径与短路径特征。在此基础上,IMDN[18](information multi-distillation network)提出了信息多蒸馏结构使在网络不加深的情况下尽可能地提取深度特征,并发现了网络的运行速度受网络深度的影响。LESRCNN[19](lightweight enhanced super-resolution CNN)提出了异构的结构来解决很深的网络丢失低频特征的问题。为了让生成的图像更符合真实图像的概率分布,对抗神经网络(GAN)[20-22](superresolution using a generative adversarial network)也在SR领域有大量的工作并应用于眼底图像的SR任务[23]。
尽管上述方法在自然图像上取得了不错的成绩,也在眼底图像上进行了应用。但对于眼底图像的SR任务应该考虑减少算法的参数量,能够集成在手持摄像机或者一般的医生电脑上运行,并且保证运行时间尽可能得低,保证在疾病筛查时不造成延误。不同于自然图像,眼底图像的高频特征集中在视盘部分(图1所示),可是对于其他边缘处的血管(低频特征)仍需要进行清晰的修复[24],这对于轻量级的网络是一个两难的问题。针对这个问题,在IDN[17]和IMDN[18]的启发下提出了一种基于残差信息蒸馏结构和异构上采样的轻量级超分辨网络,在方法部分详细介绍了本文提出的网络结构。实验在IDRID[25]数据集上进行,定性定量地探讨了提出的结构的作用。对比于许多先进的方法,提出的网络在参数量小于大多数轻量级网络的同时获得了最高的图像质量(PSNR、SSIM[26])。
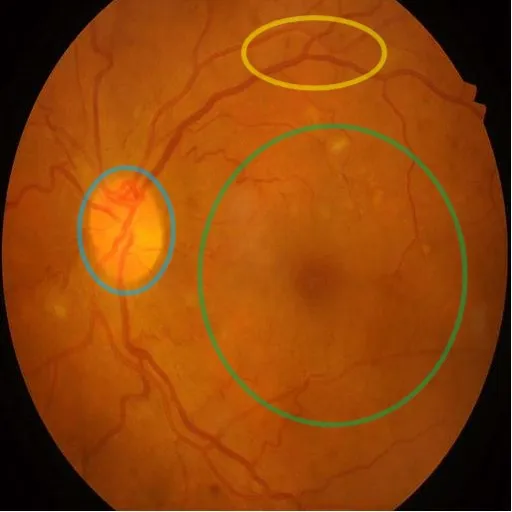
图1 眼底图像的特征分布(蓝色区域为高频特征较多的视盘部分,黄色区域是密集的血管,绿色区域低频特征较多)Fig.1 Feature distribution of fundus images
1 算法流程
提出网络的结构如图2所示,将LR图像作为输入,通过卷积(CONV3×3)变换为64通道后经过8个残差信息蒸馏块(residual information distillation)提取特征,每个残差信息蒸馏块会分离出8个通道。将共计64个分离出的通道合并后通过通道注意力机制[27](channel attention)赋予每个通道新的权重,再与初始信息相结合后进行上采样(up-sample)。同时被残差信息蒸馏块提取的深度特征也进行上采样操作,将两个上采样后得到的特征结合通过信息集成(information ensemble)模块输出HR图像。
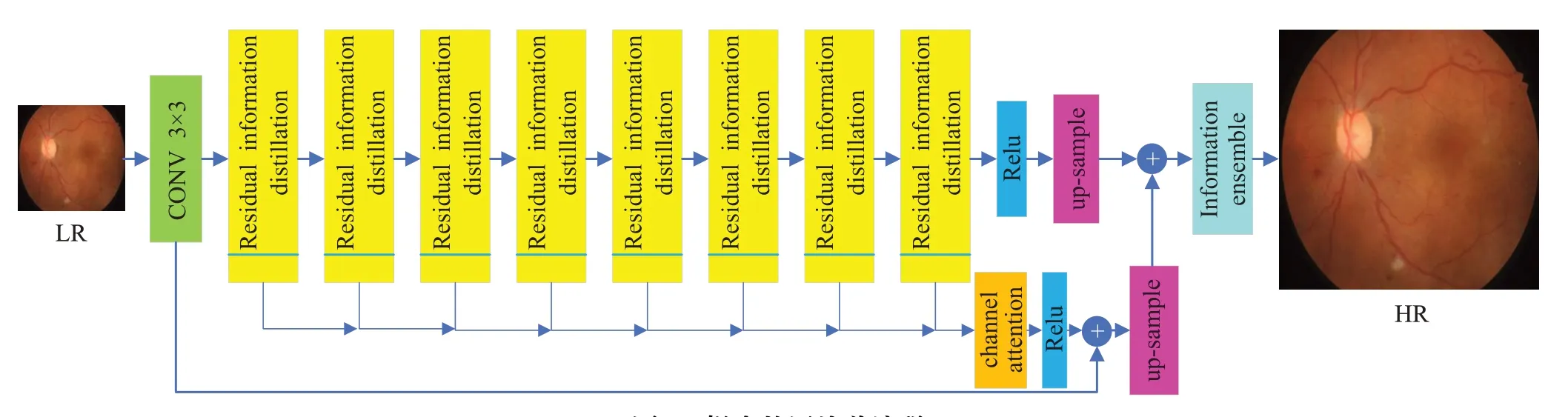
图2 提出的网络总流程(第一个CONV输入为3通道,输出64通道,up-sample模块参数是共享的)Fig.2 Overall flow of proposed network
本章后面的内容介绍了每个结构的详细信息和损失函数的设置。
1.1 残差信息蒸馏与通道注意力机制
影响网络运行速度的一个重要因素是网络的深度,在运行过程中网络的前一层和后一层有依赖的关系,进行当前的计算必须等待上一次计算完成,但是每一层的多个卷积运算可以并行处理,残差信息蒸馏块(如图3(a))可以在不加深网络的情况下尽可能提取到不同层次的特征,它的表达式如下:
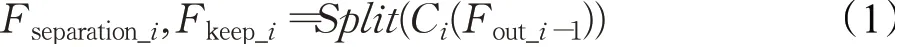
其中,Ci表示第i个残差信息蒸馏块的Relu和CONV3×3操作,Split表示通道分离操作,Fseparation_i表示第i个蒸馏出的8个通道,Fkeep_i表示第i个保留的64个通道。Fout_i-1是第i-1个残差信息蒸馏块的输出,它的表达式如下:
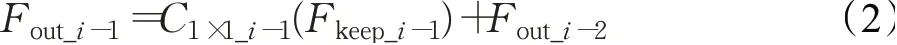
其中,C1×1_i-1表示第i-1残差信息蒸馏块的CONV1×1操作。每个Fseparation_i包含8个通道,将它们拼接后得到64个通道的特征经过通道注意力模块重新赋予权重,具体的表达式如下:
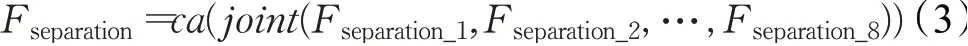
其中,joint表示通道拼接操作,Fseparation是总的蒸馏特征。ca表示通道注意力操作(如图3(b)),表达式如下:
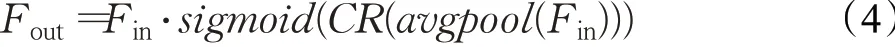
其中,Fin和Fout是输入和输出,avgpool是平均池化操作,CR是模块中的CONV1×1和Relu操作。由于被蒸馏出来的通道深度是不同的,所以在通道注意力机制中将通道从64压缩至8个,再生成64个通道,目的是让网络关注于更重要的通道,调节通道之间的平衡。
1.2 异构上采样与信息集成
每一层蒸馏出的特征都从某种程度上包含了当前深度的特征。因此将通道注意力块处理过后的蒸馏特征看作是对初始的粗特征的一种补足。将它们结合后与残差信息蒸馏块保留的特征用同一个上采样块(参数共享)(如图3(c))进行上采样,具体表达式如下:
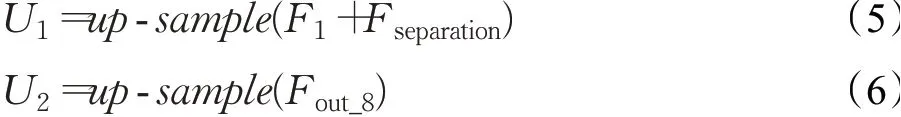
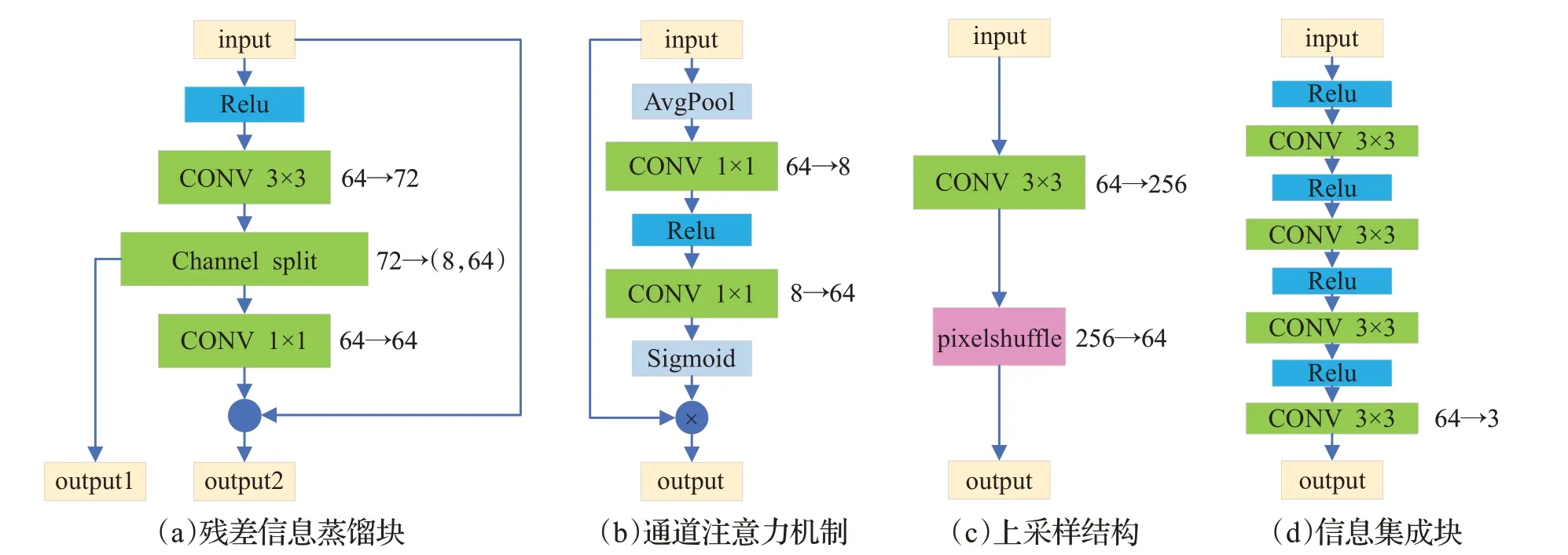
图3 提出网络的详细结构注((a)中的output1是分离的蒸馏特征;(b)中乘法操作是对应通道乘以对应权重;(c)为2倍SR任务的上采样示意图(4倍任务通道再乘4);(d)中除最后一个CONV以外均为64通道))Fig.3 Detailed structure of proposed network
其中,up-sample是上采样操作,F1和Fout_8分别为第一个CONV3×3和最后一个残差信息蒸馏块的输出,U1和U2分别是粗特征和深度特征上采样的结果。深度特征往往包含许多高频的细节信息,而粗特征包含更多低频的整体结构信息。将二者异构上采样的目的是使生成的HR图像能够兼顾整体结构和细节信息。将上采样后的特征结合,通过信息集成模块(图3(d))整合特征后输出HR图像,具体表达式如下:

其中,IHR表示生成的高清眼底图像,IE是信息集成模块的操作,通过4个Relu和CONV3×3交替处理后输出3通道的彩色图像。
1.3 损失函数
考虑生成图像有丰富的细节并保持和ground-truth一样的结构信息,用到了两个损失函数。第一个损失函数是平均绝对误差(L1范数),具体表达式如下:
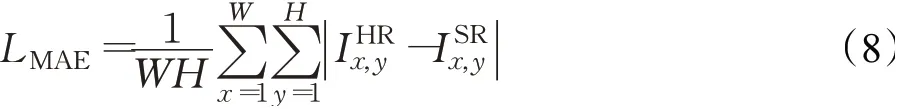
其中,W和H是图像的宽和高,指真实的图像和生成的图像在(x,y)处的像素值。第二个损失函数是由VGG16网络构造的感知损失,具体的表达式如下:
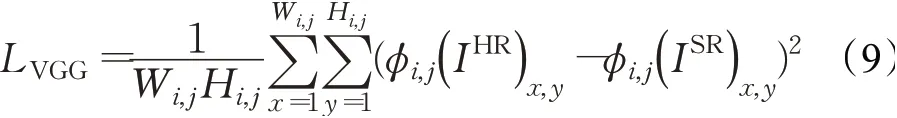
其中,Wi,j和Hi,j是VGG16网络中第i个激活层前第j个特征图的宽和高分别是将真实图像和HR图像输入VGG16网络后在该层的特征图的(x,y)位置的像素值。VGG网络是预训练好的分类网络,通过控制特征图相互接近来保证生成图像具有和真实图像接近的结构特征。
2 实验分析
2.1 实验设置
实验使用IDRID[23]数据集来验证提出的模型,数据集包含1 113张眼底图像,所有图像均具有足够的质量和临床意义,没有重复。其中前750张作为训练集,后350张作为测试集,剩余13张作为快速验证集。为了去掉边框和检测背景,统一将图像裁剪缩放至512×512作为ground-truth,通过双三次插值下采样得到2倍(256×256)和4倍(128×128)的LR图像。随机提取LR图像中大小为48×48的图像块和对应的HR图像块来训练模型,每组数据都通过随机水平反转和90°旋转实现增强。所有的模型均在pytorch1.7中实现,服务器的CPU为10700k,频率为3.8 MHz,运行内存大小为64 GB,频率为3 200 MHz,GPU为NVIDIA GeForce GTX 3080(10 GB),硬盘为三星970EVOPlus NVMe M.2(1 TB)。模型训练持续100 epochs,初始学习率为0.001,每10 epochs减半,batch size设置为16,平均绝对误差和感知损失函数的比例为1∶0.06(通过网格搜索得出)。实验结果的衡量指标主要采用PSNR和SSIM[24]。
2.2 模型分析
在这一节中,对提出的模型进行消融实验,所有比较实验均在四倍SR任务下进行。首先探讨异构上采样对网络的增益,为了公平的比较,不对残差信息蒸馏块进行通道分离的操作,并且不增加CONV3×3的通道数(固定64通道),将这样的结构称为基本块。表1记录了五次异构上采样和仅将基本块输出的深度特征上采样的平均结果。由于上采样模块的参数是共享的,所以网络的参数内存并没有变化,异构上采样在测试集上运行的时间略高,但在图像质量尤其是SSIM上获得了更高的成绩。在异构上采样的情况下,比较仅粗特征被通道注意力块处理和利用蒸馏特征补充粗特征之间的差别,表2记录了五次实验的平均结果。在使用残差信息蒸馏块分离的特征补充粗特征后,参数内存和运行时间有小幅的增加,但图像质量有更明显的增长。图4展示了使用异构上采样并用蒸馏信息对粗特征补足在图像上的效果。由于粗特征包含更多的低频信息,可以观察到图像在边缘位置(蓝色箭头标出)更加的光滑,而仅使用深度特征上采样的图像在边缘处有更多的锯齿。

表1 异构与普通上采样对比结果Table 1 Compare heterogeneous and normal up-sampling

表2 不同特征提取块的对比结果Table 2 Compare different feature extraction blocks
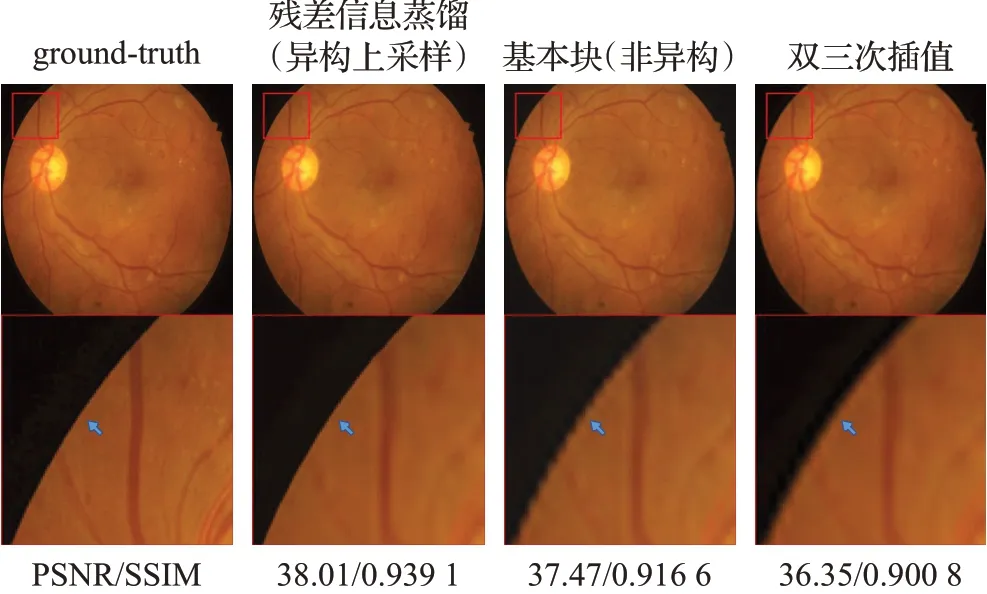
图4 提出的结构生成眼底图像对比Fig.4 Fundus image generated by proposed structure
2.3 与先进的方法比较
为了进一步地验证模型的性能,将它与一些先进的 方 法(双 三 次 插 值[6]、SRCNN[9]、VDSR[12]、EDSR[13]、CARN[15]、IMDN[18]、LESRCNN[19]、SRGAN[20])从生成图像质量、参数内存、运行时间三个方面进行比较。表3记录了每个方法五次训练的平均结果,相比于不需要预先上采样LR图像的方法(EDSR、SRGAN、CARN、IMDN、LESRCNN),提出的模型在参数内存和运行时间上取得了较好的成绩(仅高于IMDN)。同时,对比于所有方法,提出的模型获得了最高的图像质量(PSNR、SSIM[26])。图5展示了不同方法生成高清眼底图像的差别,在第一行中,细微血管的生成往往是比较困难的,预先上采样的方法(双三次插值、SRCNN、VDSR)生成的部分颜色不明显且很模糊,其他方法生成的血管都有一些颗粒感,本文提出的模型生成出了较细腻的血管。在第二行图像的视盘部分,在血管密集部分其他方法生成的图像都有些许血管粘连。在第三行图像的黄斑区部分,尽管在二倍图像的SR任务下与其他方法生成的图像结构差别不大,但是其他的方法的背景有一定的色差并且伴随少量伪影。图6展示了本文提出的方法与先进的轻量级网络的比较,其中SRGAN作为参考,提出的网络在参数量仅高于IMDN且远小于一般网络(SRGAN为例)的情况下取得了最高的重建质量,这表明考虑眼底图像的特征分布提出针对性的网络结构是有效的。图7展示了不需要预先上采样LR图像的方法的验证曲线。由于训练时蒸馏特征对粗特征的补足,提出的模型验证曲线波动较小,相比于其他方法,训练较为稳定,更易收敛。
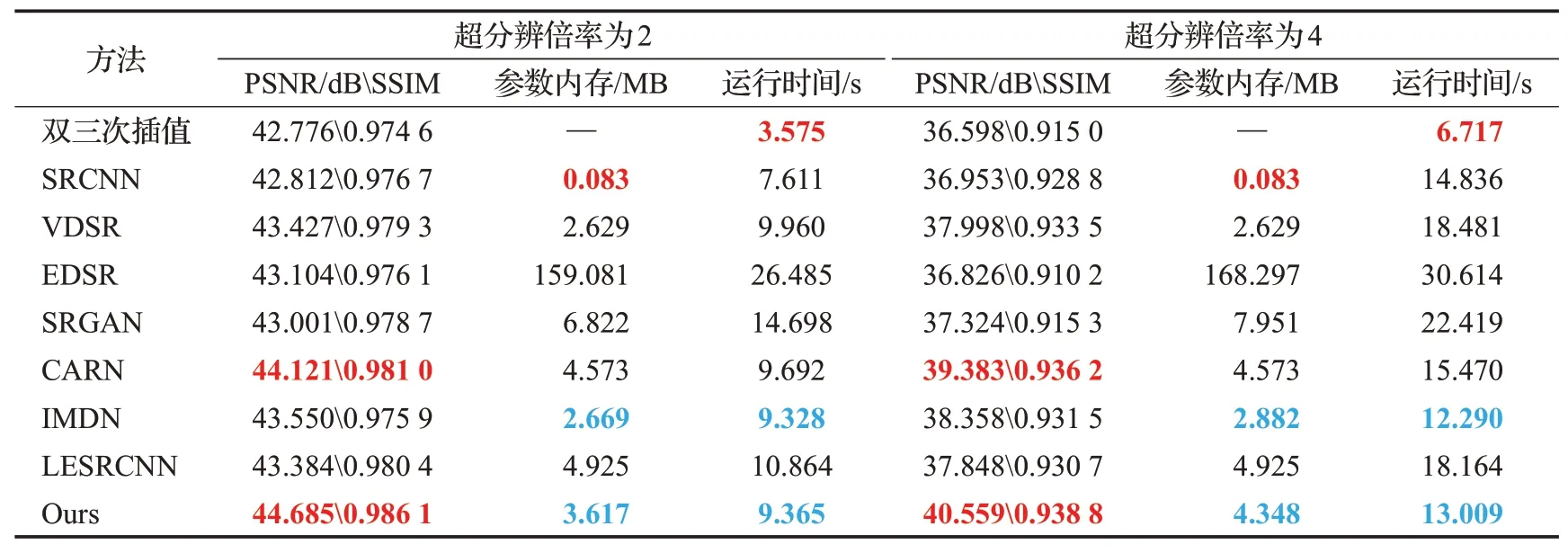
表3 与先进的方法比较的结果Table 3 Results of comparison with advanced methods
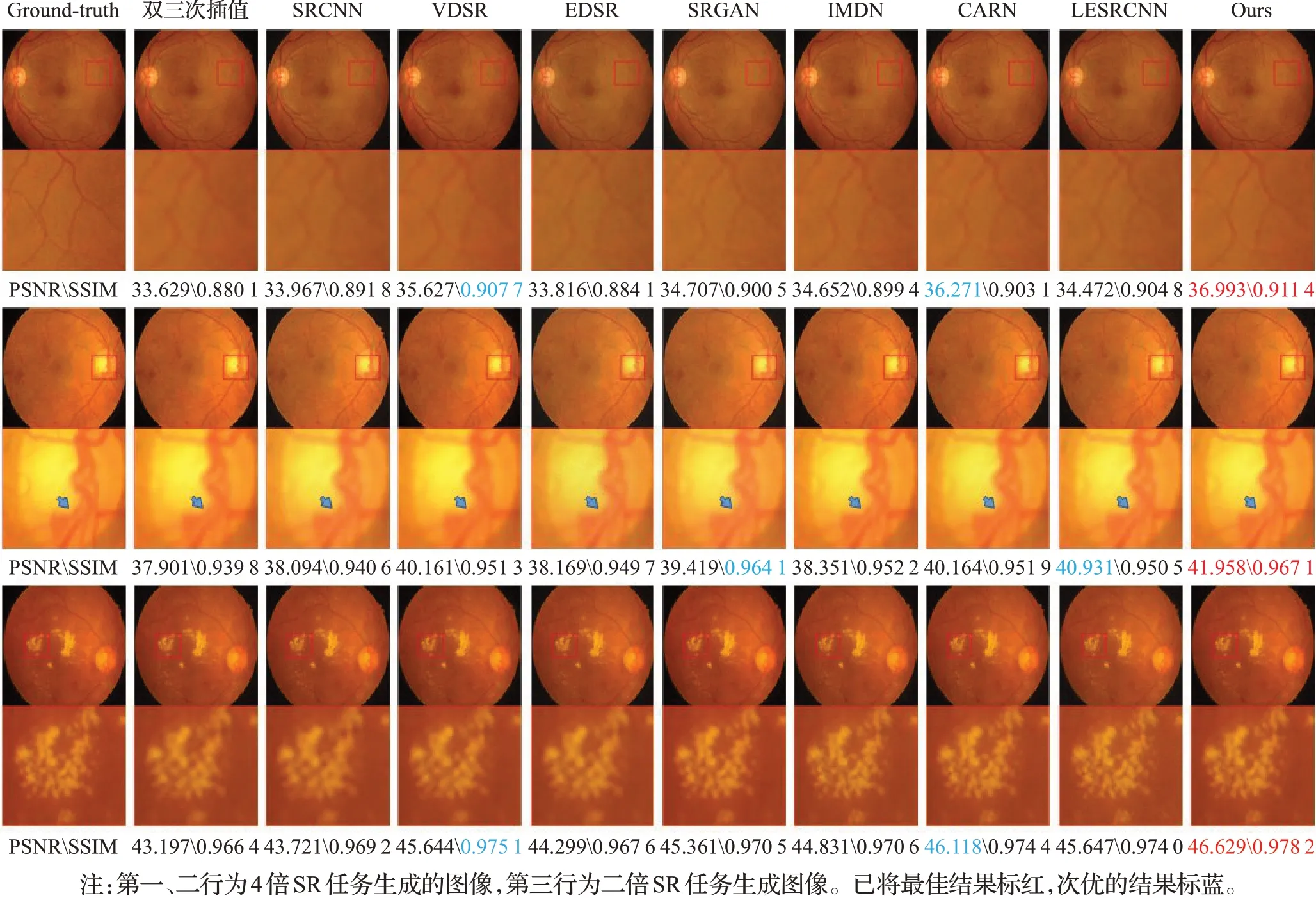
图5 与先进方法生成的图像对比Fig.5 Comparison with image generated by advanced method
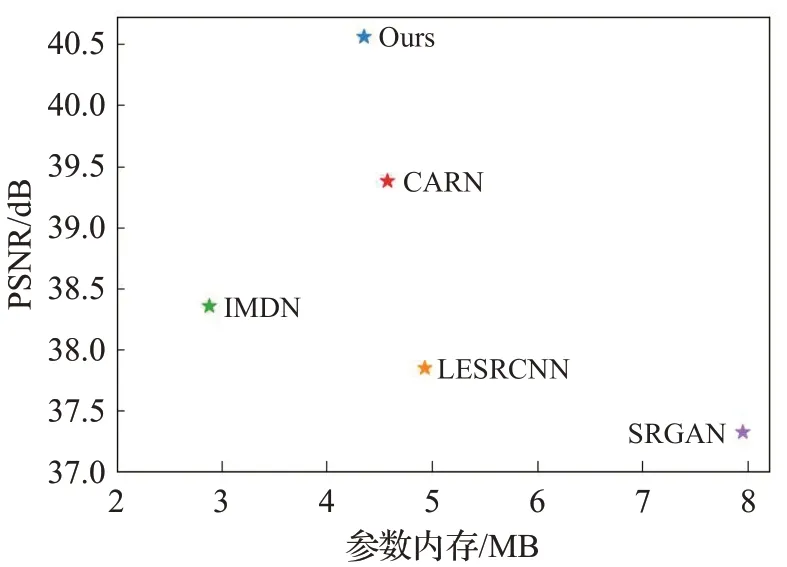
图6 与先进的轻量级网络比较Fig.6 Comparison with advanced lightweight networks
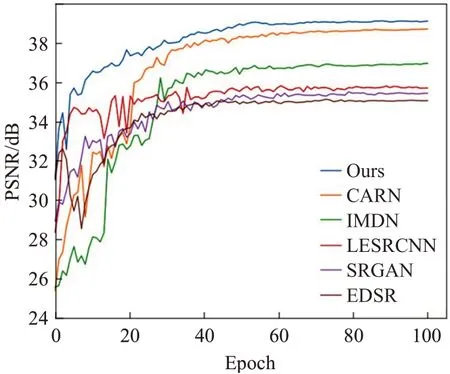
图7 后上采样方法的验证曲线Fig.7 Validation curve of post-up-sampling method
3 结束语
本文提出了一种基于信息蒸馏与异构上采样的眼底图像超分辨算法。不同于自然图像,眼底图像特征种类较为单一,但对于细节和整体结构的准确度需求较高。因此设计了一个残差信息蒸馏块,在深度提取特征的同时不断分离出蒸馏特征对初始的粗特征进行补足。同时,采用异构的方式将粗特征和深度特征分别进行上采样,集成二者的上采样特征生成高清眼底图像。与一些先进的算法比较,在参数内存和运行时间取得优异的成绩同时获得了最高的图像质量。因此,提出的模型为超分辨算法嵌入在移动式眼底摄像机或者普通医用设备上提供了思路。
在设计网络时,为了减少参数量,共享了异构上采样模块的参数,这导致蒸馏特征的通道数量需要与深度特征的通道数一致。本文将残差信息蒸馏块分离的通道数量设置为常量(每次分离8个通道,共计分离出64个通道),尽管减少了模型的复杂度,但也限制了模型的表达能力。这也表明模型具有在降低参数量的同时提升重建图像质量的潜力。通过设计更灵活的信息蒸馏块使网络适应不同种类的医学图像(不同的特征分布)和自然图像将是未来工作的一部分。
