基于智能算法的火电厂锅炉燃烧控制系统及系统仿真分析
2022-12-05乔印杰高志佳董振广
乔印杰,高志佳,董振广
(河南京能滑州热电有限责任公司,河南 滑县 456400)
基于闭环控制的锅炉燃烧系统是以锅炉运行实时数据和负载情况作为输入变量,在此基础上利用工业计算机发出指令不断调节输入变量,保证输出结果最优,让锅炉得以高效、节能、环保运行。但是调查发现,国内许多火电厂的锅炉燃烧控制系统存在控制响应延时严重、参数调节不够灵敏、无法兼顾效率与节能等问题。为了实现火电厂效益最大化,对锅炉燃烧控制系统进行优化成为一项重要任务。在工业设备的人工智能控制领域,遗传算法有着广泛的应用,在锅炉燃烧控制系统的改进中,引入遗传算法寻优方法,可以准确预测锅炉燃烧的整个过程以及燃烧过程中各个参量的变化情况,达到了优化控制的目的。因此,探究基于遗传算法的锅炉燃烧控制系统优化策略,成为火电厂技术革新的重要内容。
1 基于遗传算法的锅炉燃烧控制系统设计
1.1 基于遗传算法的系统优化
火电厂锅炉在实际运行中,由于设备负载能力、工作环境温度、使用煤炭种类等因素的不同,导致锅炉本身的燃烧性能也表现出明显的差异。为了使锅炉的运行效率、节能效果达到最优,必须对锅炉的燃烧控制系统进行优化。基于遗传算法的系统优化思路为:以锅炉参数作为输入参数,构建锅炉燃烧优化模型,分析锅炉燃烧各个参数与热效率之间的映射关系。然后利用遗传算法进行全局寻优,保证锅炉燃烧重要参数与热效率之间实现最佳匹配,达到锅炉燃烧效率最大化的目的。基于遗传算法的寻优模型见图1。
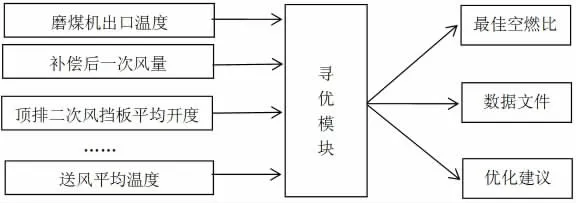
图1 遗传算法寻优模型
在该寻优模型中,基于遗传算法的核心模块采用实数编码的方式,计算遗传算法的输入变量,最终结果保存到数据文件中。同时,系统根据运算结果给出优化建议,锅炉燃烧系统可通过自动方式或人工手动方式进行参数调节,从而保证锅炉达到最佳空燃比。
遗传算法的寻优步骤如下:
(1) 确定遗传算法的输入变量。以锅炉燃烧控制系统为例,输入变量主要包括氧量、负荷、一次/二次风量、环境温度、总燃料量等。然后结合实际问题设置约束条件,得到问题的解空间。
(2) 对解空间展开分析,参考目标函数形式,推导出算法寻优的数学形式,如极值、拐点等,构建相应的优化模型。
(3) 采取染色体编码方法,把问题求解过程转化成对应的遗传基因逐渐生长过程,确定问题的搜索空间。结合基因从个体特征到群体特征的表现过程,进一步求出基因的编码过程。
(4) 判断个体在整个样本集合中的适应度,根据优化模型对目标函数做适应性调整。根据适应度函数和目标函数之间的关系,确立转换规则。
(5) 结合实际问题确定遗传算子的具体形式,以及遗传算法的运行参数(如终止条件、交叉概率等)。
(6) 根据遗传算法的运行参数,确定最优解,得出寻优结果。
1.2 遗传算法在锅炉燃烧控制参数寻优中的应用
1.2.1 寻优流程设计
基于遗传算法的寻优策略主要有比例选择、轮盘赌选择、最优保存策略选择、无回放随机选择等若干种[1]。本文基于轮盘赌选择设计锅炉参数寻优模型,寻优流程如下:
建立锅炉的运行参数模型后,读取锅炉的原始数据。成功识别数据后,进行锅炉参数的初始化处理。系统调用锅炉运行参数,并执行一个判断程序“锅炉运行参数是否成功读取?”
如果判断结果为“是”,则利用遗传算法进行数据处理,并将处理后的数据导入到系统模型中。该模型自动将输入的结果数据与双亲数据进行对比,并判断两种数据的适应度。如果结果数据的适应度低于双亲数据,则取双亲中适应度较好的带入。然后执行一个判断程序“是否进行下一次遗传?”如果所得结果符合优化要求,则自动结束本次寻优过程;如果所得结果不符合优化要求,则继续进行第二次遗传。将第一次遗传后的数据添加到原始数据表,并作为新的原始数据,重新导入模型进行适应度对比,重复上述流程。
如果判断结果为“否”,则继续判断是否存在交叉变异。如果无交叉变异,则将原始数据保存以后,由系统重新读取锅炉运行参数;如果有交叉变异,首先将变异后的原始数据进行保存,然后采用轮盘赌算法确定双亲,再根据双亲计算子节点数据。将求得的子节点数据添加到数据表中,作为新的原始数据,然后由系统重新读取,并再次执行“锅炉运行参数是否成功读取?”的判断程序。
1.2.2 确定基因代码
将锅炉可调参数作为锅炉燃烧效率寻优的基因代码,具体见表1。
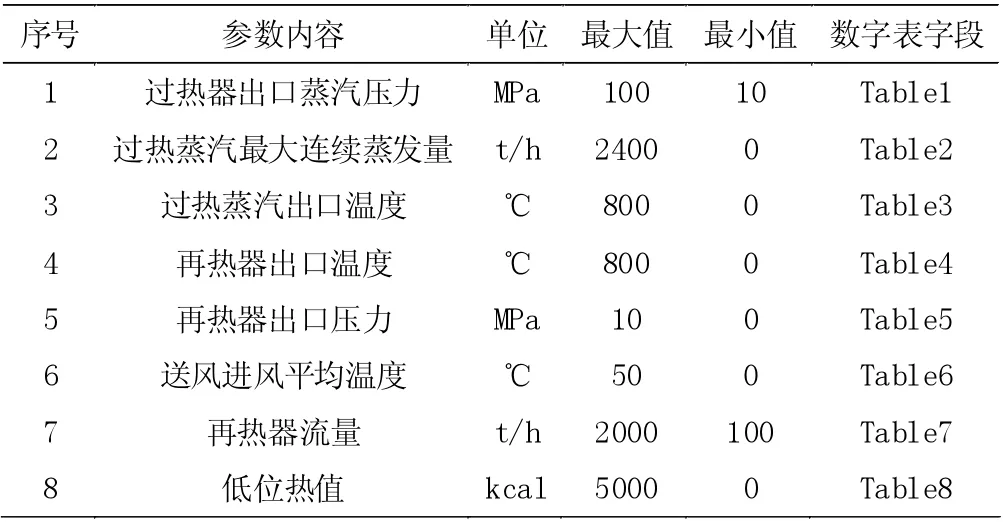
表1 锅炉参数变化范围
结合锅炉设备的运行状况,确定再热器流量、再热器出口压力、给煤机煤量等可调参数的取值范围,如再热器流量的取值范围为100~2 000 t/h。如表1所示,每一个基因代码都包含了8 个控制变量,将每一组控制变量作为单一个体,然后进行个体适应度计算。此外,将选定的可调变量,与其他不可调变量全部加入到训练集中,一同输入到已经完成训练的系统模型中,作为输入值进行锅炉燃烧效率的预测。利用遗传算法,得到优化后的调整参数,系统根据优化后的参数重新编辑控制指令,实现对锅炉输入参数的调节,从而保证锅炉始终以最佳燃烧效率运行[2]。
1.2.3 锅炉参数优化设计
将锅炉运行中的8 个变量,按照table1~8 依次表示,参数的适应度即为锅炉的燃烧效率。适应度越好,说明锅炉的燃烧效率越高。锅炉参数的优化流程可分为3 个步骤:
(1) 种群初始化。从海量的原始参数中,选择250 组锅炉燃烧效率较好的参数作为遗传寻优的原始数据,并按照1~250 的序号输入到Excel 表格中。
(2) 适应度评价。锅炉燃烧效率的取值范围为0~100%,将其作为适应度,寻优目标值为1,此时锅炉燃烧效率有最大值。
(3) 遗传选择。基于遗传算法的锅炉参数优化程序,采用轮盘赌选择方法确定双亲。
在该程序下,燃烧效率越高的运行参数,其适应度越好,因此被遗传到下一代的概率越大。这样经过若干轮的遗传后,即可得到最优结果[3]。
2 火电厂锅炉燃烧控制系统仿真分析
2.1 锅炉燃烧控制系统的模型设计
系统仿真实验选择安全性闭环控制模式,通过实时监测的方式获取锅炉热效率数据。同时利用控制器发送指令实现对机组运行参数的调节,在此基础上结合上文提出的遗传算法进行优化,保证了试验机组能够发挥最大效能。机组优化运行原理见图2。
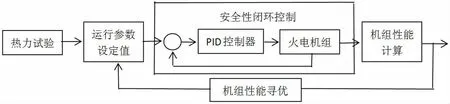
图2 机组优化运行原理图
在仿真试验中,使用DCS 作为控制单元,确保在锅炉参数调整时能够通过程序指令完成精准控制。DCS 与锅炉之间通过工业总线完成通信,保证DCS 控制指令的顺利下达以及锅炉测量参数的及时上传。
2.2 锅炉燃烧稳态模型
锅炉燃烧期间受到诸多不确定因素(如煤的质量、燃烧温度等)的影响,锅炉氮氧化物的排放量和飞灰含碳量的变化均呈现出非线性特点。而本文提出的机遇遗传算法的优化控制模型,则能够很好地适应非线性函数;此外还具有较强的自适应、自学习能力,在此基础上建立起的锅炉燃烧稳态模型能够对提升锅炉燃烧有积极帮助。该模型以再热器出口温度、出口压力,以及给煤机的压力、煤量等变量作为输入,以锅炉燃烧效率作为输出,基于模型定性分析锅炉燃烧特性与相关变量之间的关系。锅炉燃烧稳态模型为:

式中:Cfh表示飞灰含碳量,f 表示飞灰含碳的计算函数,Mv表示再热器出口温度、出口压力等操作量,Dv表示给煤机煤量、环境温度等相关量[4]。
2.3 应用实例
选择一台350 MW 的超临界对冲锅炉作为测试装置,使用钢铁球磨机制粉系统切向燃烧。使该锅炉在240 MW、280 MW、320 MW和350 MW 四种负荷工况下运行,并收集不同工况下的水分、灰分、含氧量、飞灰含碳量等参数,统计结果见表2。

表2 锅炉热态试验工况表
将采集到的数据作为训练样本,基于LM学习规则进行模型训练。完成训练后,对比飞灰含碳测试集的预测值和实际值,结果见图3。
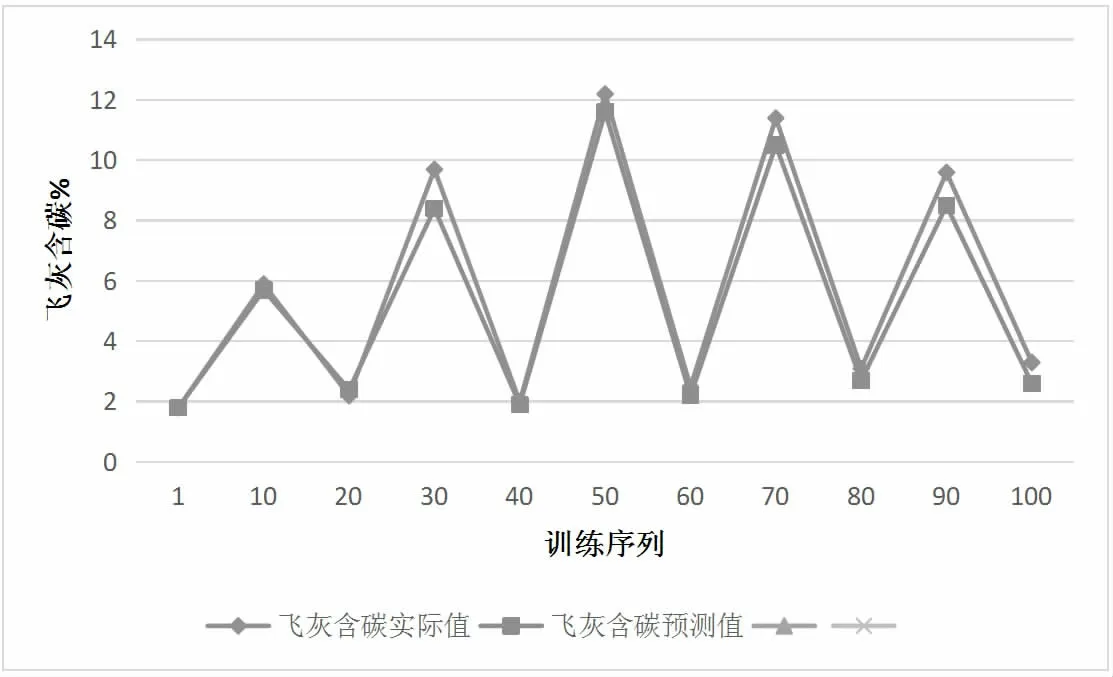
图3 飞灰含碳测试集预测值与实际值比较
如图3 所示,锅炉飞灰含碳测试集的预测值与实际值之间呈现出较高的拟合度。两者之间的最大误差为1.61,最大相对误差为26.74%。这一结果表明经过遗传算法模型训练的锅炉燃烧控制系统,能够准确预测煤粉灰燃烧后的飞灰含碳量,在此基础上不断调整含氧量、给煤机煤量等输入量,可以使飞灰含碳测试值与实际值之间的误差始终保持在较低水平,从而让锅炉燃烧控制系统的燃烧效率达到最优[5]。
按照同样的方法,在本次仿真实验中还建立了NOx排放模型,选择烟气含氧量、风压、二次风挡板开度、炉温等作为输入,以NOx排放作为输出。经过LM神经网络训练后,分别统计并对比NOx的实际值和预测值。结果表明,两者之间的最大误差为0.47,最大相对误差为6.78%,说明经过遗传算法训练后的模型,也能够较为准确地预测NOx的排放值。在此基础上不断调整一次风压、二次风挡板开度、炉温等输入量,可以使NOx的排放值控制在较低水平,减少环境污染
3 结论
在环保标准日益严格的背景下,火电厂锅炉燃烧控制系统也必须与时俱进的优化,在提高燃烧效率的同时降低污染排放,实现生态效益和经济效益的统筹兼顾。基于此,本文利用遗传算法构建了锅炉燃烧稳态模型,并收集锅炉燃烧时的基本参数作为变量,进行模型训练。然后将该模型应用于锅炉的燃烧控制中。从仿真试验结果来看,该模型投入应用后,能够实现闭环控制,动态调节输入变量,保证输出结果的最优化,在提高燃烧效率、降低氮氧化物排放浓度等方面取得了理想效果。
