基于预训练模型的FVD在非可见光视频质量评估的应用与改进*
2022-12-05集美大学谢晓婷吴佳栋周俊丞黄勋黄斌
集美大学 谢晓婷 吴佳栋 周俊丞 黄勋 黄斌
FVD 是一种评估机器自动生成视频质量的评估指标,在可见光视频生成领域已经得到了较为广泛的应用。现有文献在计算FVD 数值时,需要通过一个预训练模型提取视频数据的关键特征。然而,这个预训练模型是通过可见光视频数据集训练得到的,目前仍缺少对其在非可见光领域视频质量评估可行性的探索。为了研究FVD对非可见光视频生成的评估效果,本文基于I3D 模型,使用非可见光领域数据集分别微调预训练模型和重新训练模型,采用红外和紫外视频数据集模拟出不同质量的生成视频,剖析FVD 在非可见光视频质量评估的应用表现。本文通过实验发现:(1)将可见光领域预训练模型直接迁移到非可见光领域,评估效果较差,无法吻合人眼观看感受;(2)当使用非可见光数据集训练出提取特征的预训练模型,FVD 的评估结果更为准确。
随着基于自注意力的深度生成模型的发展,人们从图像生成领域逐步关注到难度更大的视频生成领域,并在视频生成领域取得了一定的进展,如Video Transformer[1]模型在Kinetics-400[2]数据集上对真实人物的复杂行为实现了较好的预测,该模型根据输入的初始视频帧,自动生成未来若干帧的人物动作,从而达到行为预测的目的。Fréchet Video Distance(FVD)[3]是一种视频质量评估指标,它根据模型生成的视频与真实视频的相似程度,以此来衡量生成视频质量的好坏。在理想的情况下,使用两段真实的视频计算出的FVD 值为0;随着生成视频的质量的下降,FVD 的值逐步上升。与PSNR 和SSIM等指标相比,FVD 考虑了整个视频的分布,从而弥补了帧级指标的缺点,使评估结果更加符合人眼感受[3]。
FVD 被提出时主要考虑可见光(波长在380 ~780nm)领域的视频质量评估,使用者需要从基于可见光数据训练的I3D 模型[4]提取能够表征视频质量的特征,并用该特征计算FVD 值。因此,FVD 评估结果的准确性依赖于预训练I3D 模型能否提供可靠的特征。现有文献通常采用DeepMind 在Kinetics-400 数据集上预训练的I3D 模型提取视频特征计算FVD,该预训练I3D 模型能够在UCF-101[5]数据集上达到93.4%的预测准确率[4]。
随着视频领域的进一步发展,人们对视频生成的研究从可见光逐渐拓展到非可见光领域。非可见光波长与可见光波长不同,在实际应用中红外光和紫外光较为常见。比如,在光电探测领域中,红外探测可用于远距离检测和跟踪空中飞行目标等[6]。在电气设备的放电检测领域中,基于240-280nm“日盲区”波段紫外光信号的“日盲”紫外放电检测得到了较广泛的应用[7]。这些应用场景均存在着通过机器自动生成视频达到扩充数据集或进行目标运动轨迹预测的需要。因此,非可见光视频的生成和质量评估具有重要的意义。
然而,FVD 是否适用于非可见光的生成视频质量评估还未得到充分的研究。本文从研究基于可见光的预训练I3D 模型是否适用于提取非可见光视频的特征入手,分析通过不同方法得到的I3D 模型对FVD 计算所带来的影响,进而研究I3D 模型提取特征的位置将在何种程度上影响FVD 值的计算,逐步剖析FVD 这一评估指标的特性。同时提出FVD 在非可见光视频领域使用方法的建议和改进,使得FVD 的评估结果更具准确性。
1 相关工作
1.1 视频生成领域的近况
与图像生成相比,建立视频生成模型是一个更为复杂的任务,不仅需要捕捉物体的视觉表现,而且需要捕捉时间维度上的信息,即视频帧与帧之间的时间动态。自然视频的复杂性要求在高维的输入上,对空间和时间的相关性进行建模,这使得高保真自然视频生成方面的进展无法同图像、文本的生成达到同样的水平。
VideoGPT[8]是一个概念上简单的架构,将基于似然的生成模型拓展到视频生成领域。使用Vector Quantised Variational AutoEncoder(VQ-VAE)通过3D 卷积和轴向自注意力学习原始视频的下采样隐变量表示,同时使用类似GPT 的架构对隐变量进行时空上的建模。
VideoTransformer[1]是一个基于三维自注意力机制的自回归视频生成模型。为降低自注意力机制的一般二次空间复杂度,它将子尺度的概念扩展到视频中,将视频切分成多个更小的视频,对视频切片进行建模,并对视频切片应用Block-local Self-attention。
NÜWA[9]是一个统一的多模态预训练模型,使用3D Transformer Encoder-decoder Frame 框架和三维邻近注意力(3D Nearby Attention),将局部稀疏注意力(Localwise Sparse attention)拓展到图像和视频领域,验证了局部稀疏注意力与轴向稀疏注意力(Axial-wise Sparse Attention)更适用于生成领域。模型的训练数据涵盖了图像和视频数据,能够适应语言、图像和视频生成等多样的下游任务。
1.2 评估图像生成效果的指标
1.2.1 PSNR——Peak Signal Noise Ratio
PSNR 一般用于衡量图像经过压缩处理后的品质,它的值是峰值信号的能量与噪声的平均能量之比,值越大代表失真越少。PSNR 虽然计算复杂度较低,但由于其并未考虑到人眼的视觉特性,因而经常出现评价结果与人的主观感觉不一致的情况。
1.2.2 SSIM——Structural Similarity Index Measure
SSIM 是一种衡量两幅图像相似度的指标,从亮度、对比度与结构来对两幅图像的相似性进行评估。在实现上,亮度用均值来表示,对比度用均值归一化的方差表示,结构用相关系数即统计意义上的协方差与方差乘积比值来表征,SSIM 的取值在[0,1]之间,值越大代表失真越少。SSIM 的优点是通过感知结构信息来评价失真,和PSNR 相比可以较好地反映人眼的主观质量感受,缺点在于当影像出现非结构性失真(例如位移、缩放、旋转)的时候无法有效运作。
1.2.3 IS——Inception Score
IS[10]从生成图片的质量和多样性两个方面评价一个生成模型,IS 的值越高说明该生成模型越好。(1)将生成的图片送入Inception-Net V3(图片分类网络)中,得到一个多维向量y,y 中每个元素的值表示x 在某一类别的概率。当生成的图片质量较好时,其在某一类别的概率应该明显区别于其他类别,也就是说,p(y|x)的熵应该很小。这评价了生成图片的质量。(2)如果一个模型只能生成有限类别的高质量图片,那该模型也不足以成为好的生成模型。如果模型生成多样性较强的图片,那么生成的图片在各个类别上的分布应该是均匀的,也就是说所有类别概率的边缘分布p(y)熵很大。这评价了生成图片的多样性。
1.2.4 FID——Fréchet Inception Distance
IS 的一个缺点是没有将真实图片与生成图片进行比较,FID[11]同样基于Inception-Net V3,IS 进行了改进。它将真实样本和生成样本送进分类器获得特征向量,再求该向量的均值和协方差矩阵,最终进行FID 的计算,FID 值越小,说明生成图像与真实图像越接近,模型生成的图片质量越好,如式(1)所示。
1.3 FVD
FVD——Fréchet Video Distance,是一个用于评估生成视频质量的指标,它基于FID 在三维空间上进行扩展,利用视频帧与帧之间的联系,以此达到评估视频质量的目的。使用者通过获取生成视频和真实视频的特征,由它们的均值和协方差矩阵计算FVD(Eq.1),FVD 值越小,说明模型生成的视频质量越好。
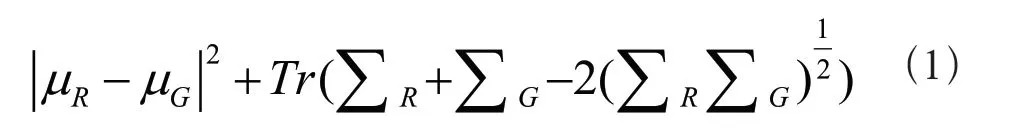
µR、ΣR:真实视频的均值和协方差矩阵
µG、ΣG:生成视频的均值和协方差矩阵
在实际计算FVD 的流程中,以Inflated 3D Convnet(I3D)作为分类器,在Kinetics-400 数据集上训练I3D;训练出的I3D 模型可以用于在真实的有挑战的YouTube视频中识别人体行为。使用训练好的I3D 模型分别对真实样本和生成样本进行特征提取,取模型最后一层输出作为特征,特征向量中的“400”代表输入数据在400 种行为类别中的分类概率,由该特征得到均值和协方差矩阵,进行FVD 的计算(如图1所示)。
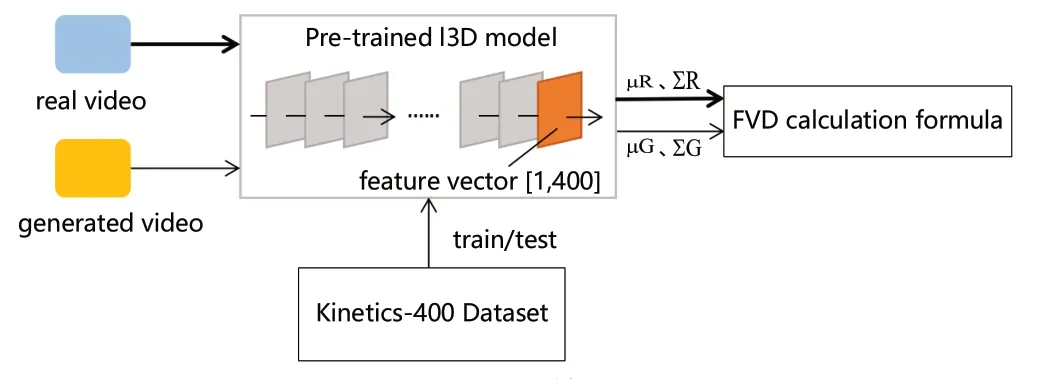
图1 FVD 计算流程Fig.1 Calculation flow of FVD
2 研究方法
本文旨在研究FVD 在非可见光视频领域的使用方法,为保证FVD 评估准确性,需要I3D 模型提供准确可靠的特征。首先使用预训练I3D 模型对非可见光视频进行特征提取并计算FVD 数值,判断在大型可见光数据集上训练的I3D 模型能否为非可见光视频的FVD 计算提供准确特征;其次使用通过不同途径得到的I3D 模型提取非可见光数据集的特征并计算FVD 数值,分析何种途径能够计算出较为合理的FVD 数值;最后我们针对I3D 模型不同层所提取的特征分别计算FVD 数值,根据结果优化特征提取策略。
2.1 节描述了本篇论文中所使用的数据集、模型和实验的相关配置。2.2 节研究预训练I3D 模型是否能够直接迁移到其他类型的数据集上。2.3 节探究不同模型对计算FVD 数值产生的影响。2.4 节分析模型不同层的特征如何影响FVD 值。
2.1 实验配置
我们选择I3D 模型作为研究对象,在自制紫外数据集、KAIST[12]数据集上进行所有实验的研究。其中,自制紫外数据集来自于对紫外目标模拟源进行拍摄所得,图像中的目标随着时间流逝产生大小变化的亮斑。所有数据集中的视频帧均被处理成224×224 大小。其中紫外数据集包含2 大类别(目标和干扰),2544 个紫外视频,每个视频100 帧;KAIST 数据集包含41 个在白天和晚上捕获的校园、街道以及乡下各种常规交通场景的视频,共95328 张图片,每张图片都包含RGB 彩色图像和红外图像两个版本。
本论文使用FVD 作为评估模型提取特征能力的标准。在计算FVD 时,将数据集均分成两份,分别为S1和S2,其中S1 作为参考集不做任何处理,S2 会做以下两类处理模拟生成视频(如图2所示)。
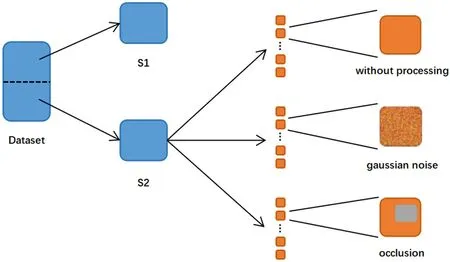
图2 数据集处理流程Fig.2 Dataset processing flow
(1)对每个视频帧I 加入高斯噪声如式(2)所示:
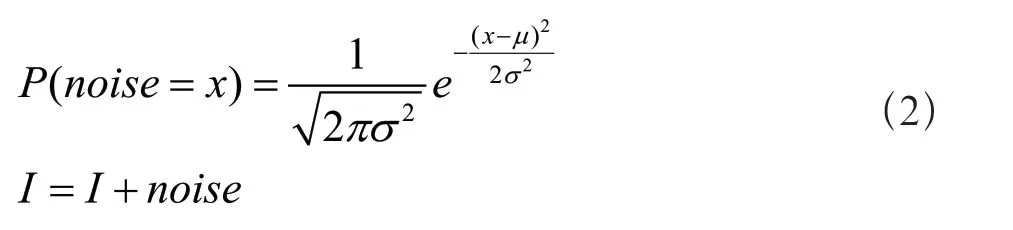
(2)对每个视频帧I 在随机区域S(大小在64×64至128×128 之间)上进行遮挡(遮挡区域像素值为I 的平均像素值)。

图3 KAIST 可见光数据集(从上至下依次为原图、遮挡、轻度高斯噪声、重度高斯噪声)Fig.3 KAIST visible light dataset (from top to bottom,original image,occlusion,light Gaussian noise,heavy Gaussian noise)
Sx:被遮挡区域的宽度 Sy:被遮挡区域的高度

图4 KAIST 红外数据集(从上至下依次为原图、遮挡、轻度高斯噪声、重度高斯噪声)Fig.4 KAIST infrared dataset (from top to bottom,original image,occlusion,light Gaussian noise,heavy Gaussian noise)
(xstart,ystart):被遮挡区域在I 中的左上角坐标如式(3)所示:

分别从S1 和S2 中随机选择多段连续16 帧的视频,送入I3D 模型进行特征提取,重复1000 次得到1000 组FVD 值。
对实验使用的不同数据集计算FVD 数值时,都进行下述三种实验配置:
(1)baseline:S1 和S2 都不做任何处理,使用S1和S2 计算FVD,得到的FVD 值作为实验的baseline。这种配置用于模拟出生成视频的质量等同于真实视频的质量的场景。
(2)遮挡:对S2 加入大小随机、位置随机的遮挡,使用S1 和S2 计算FVD。这种配置用于模拟出生成视频的质量不高、存在遮挡的场景。
(3)高斯噪声:对S2 加入不同强度的高斯噪声,使用S1 和S2 计算FVD。这种配置用于模拟出生成视频的质量不高、存在噪声的场景。
2.2 I3D 预训练模型是否能够直接迁移到其他类型的数据集上
在提出I3D 的原始论文中,我们知道在Kinetics-400数据集上预训练的I3D 模型具有较好的提取视频特征的能力。在本实验中,我们希望知道将该预训练模型迁移到其他类型的数据集上(尤其是非可见光数据集),该模型是否仍具有较好的特征提取能力。我们在KAIST 原始数据集上计算FVD,其中轻度高斯噪声:μ=0,σ=0.005,重度高斯噪声:μ=0,σ=0.01,得到的FVD 值如图6所示。
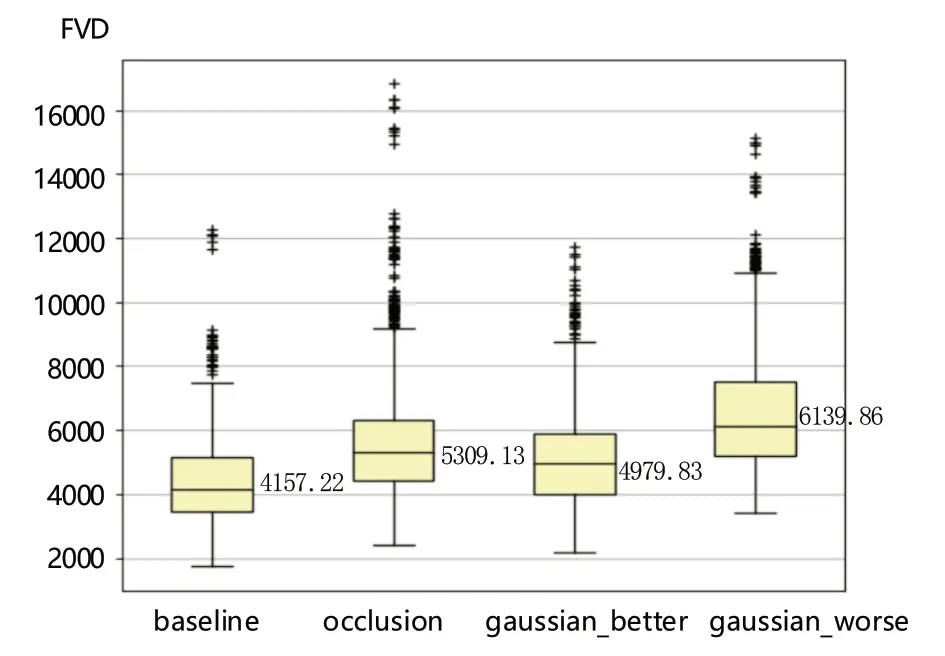
图6 对KAIST 可见光数据集计算的FVD 值Fig.6 FVD values calculated for the KAIST visible light dataset
如图6所示,对数据进行不同类型的处理(遮挡和加噪),所得FVD 值整体较baseline 有所上升。同时,不同强度的高斯噪声所得FVD 有明显差异,这说明FVD 能够在一定程度上检测注入的噪声。然而从整体上看,使用在Kinetics-400 上预训练的I3D 模型对KAIST可见光数据集进行特征提取,计算FVD 所得的baseline值相较于原始论文对机械臂运动视频评估的FVD 值[3]高出了一个数量级,这说明在可见光领域的不同数据集之间,预训练I3D 模型的迁移仍具有一定的局限性。
为研究使用可见光数据进行预训练的I3D 模型是否能够直接迁移到非可见光数据集进行特征提取,我们还在KAIST 红外数据集、紫外视频等数据集上计算FVD。其中KAIST 红外数据集的轻度高斯噪声:μ=0,σ=0.001,重度高斯噪声μ=0,σ=0.005,紫外数据集的轻度高斯噪声:μ=0,σ=0.01,重度高斯噪声μ=0,σ=0.2,得到的FVD 值如图7所示。
根据图7,将使用可见光数据集预训练的I3D 模型迁移到非可见光数据集上,对于KAIST 数据集,通过FVD 值的分布发现该预训练模型迁移到KAIST(可见光)的FVD 值反而要比迁移到KAIST(红外)的FVD值要差。通过baseline 的箱型图可以发现,对于两份质量相似度很高的数据,计算所得的FVD 值仍然较高。而对于紫外数据集,baseline 相对偏高,gaussian_better 的FVD 值比gaussian_worse 更高,这与主观视觉感受不符,无法准确地评估视频质量。因此使用可见光领域模型进行非可见光数据集的特征提取目前仍具有一定挑战。
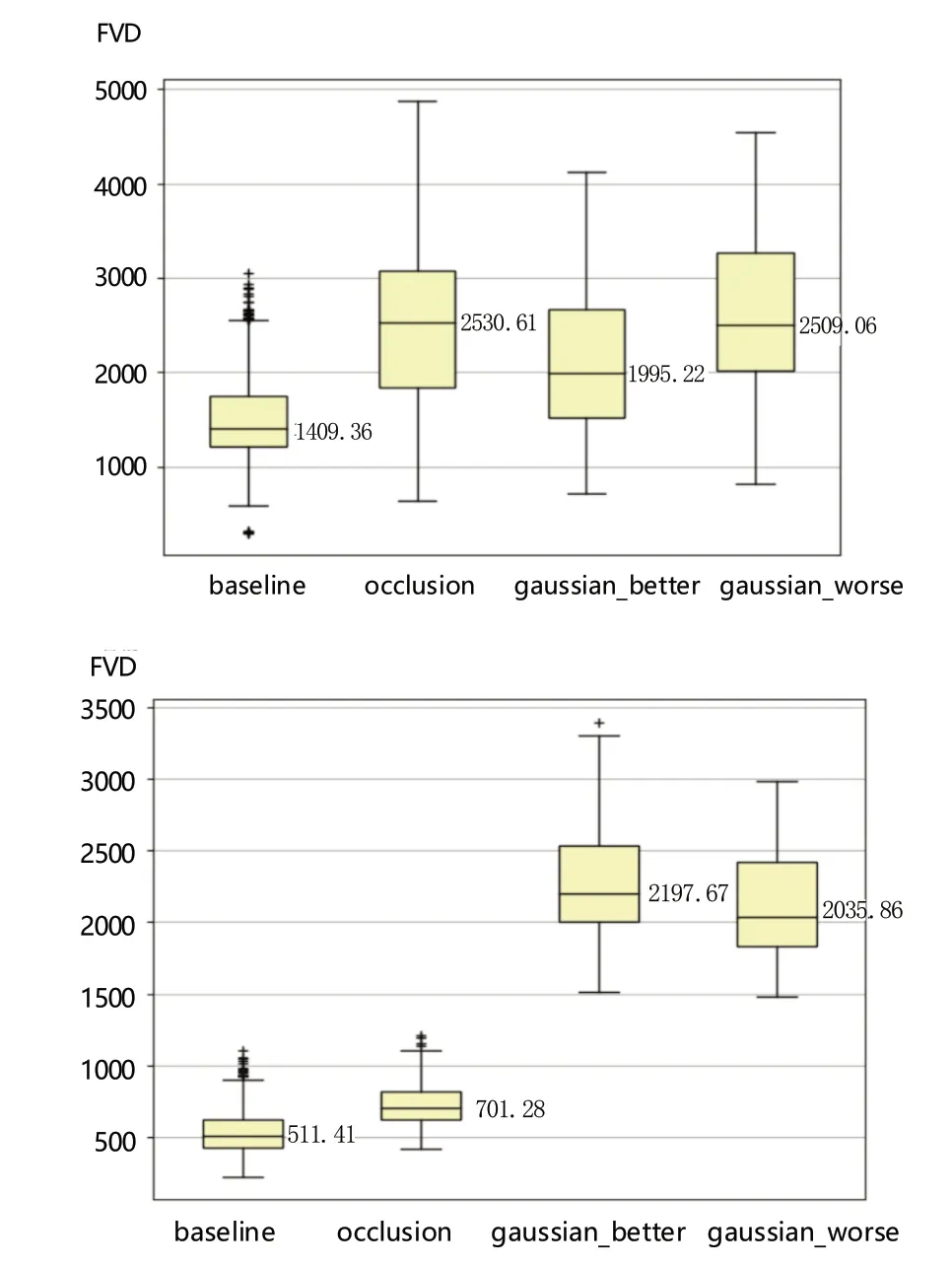
图7 KAIST 红外数据集(上)和紫外数据集(下)的FVD 值Fig.7 FVD values for KAIST infrared dataset (top) and UV dataset (bottom)
2.3 不同模型是否会对FVD 计算产生影响?
为进一步研究FVD 对非可见光视频的评估能力,我们在紫外视频数据集上进行研究,微调和训练时只取每个视频的后79 帧。
在本实验中,首先使用未经训练的I3D 模型,将模型参数随机初始化,用其计算紫外数据的FVD,以此作为本实验的参考值;其次,使用紫外数据集对在Kinetics-400上预训练的I3D 模型进行微调;最后,将紫外数据集以视频为单位,按照7:2:1 的比例划分出训练集、验证集和测试集,重新训练I3D 模型。
基于以上方法,得到以下三个模型:
(1)不经训练,参数随机初始化的I3D 模型;
(2)使用紫外数据进行微调的I3D 模型;
(3)在紫外数据集上从随机初始化权重开始训练的I3D 模型。
使用上述三个模型提取紫外视频的特征计算FVD值,其中轻度高斯噪声:μ=0,σ=0.01,重度高斯噪声μ=0,σ=0.2,所得实验结果如图8所示。
根据图8,发现使用参数随机初始化的I3D 模型在紫外数据上进行特征提取计算FVD,baseline 呈现接近于0 的数值,同时无论对视频进行遮挡或加噪处理,计算所得的FVD 值均接近于0。尽管baseline 的FVD 数值在理论上应该越接近0 越好,但加上了遮挡和噪声的视频产生的FVD 值应该越大越好。这说明了一个随机初始化权重的I3D 模型不具备有提取可靠视频特征的能力,因而无法呈现出高质量视频和低质量视频之间的差异。
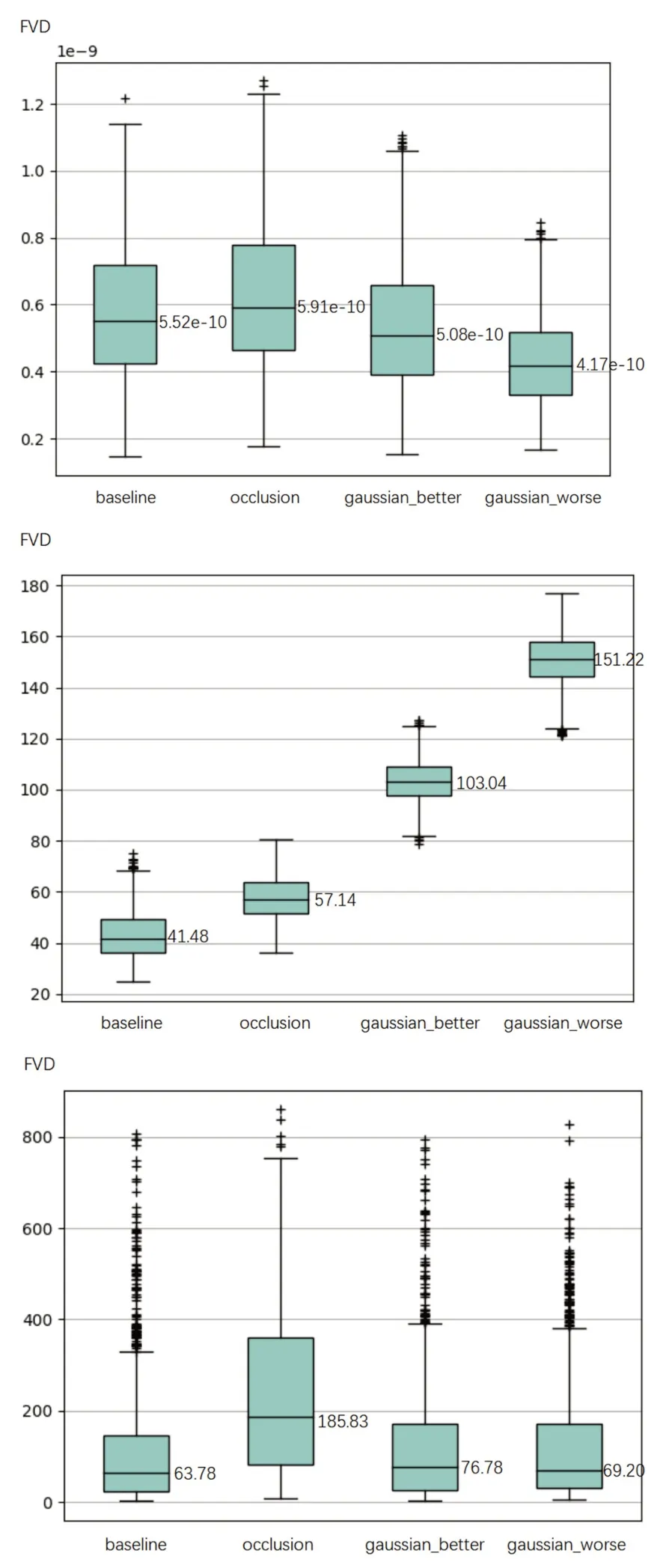
图8 使用随机初始化模型(上)、微调模型(中)和重新训练模型(下)计算的FVD 值Fig.8 FVD values calculated using the random initialization model(top),fine-tuned model (middle) and re-trained model (bottom)
使用微调的I3D 模型提取特征进行FVD 计算,baseline 呈现较低的值,occlusion 的FVD 值比baseline高但较为接近,从遮挡的视频和原始视频的视觉效果上看,两者的FVD 值差距比预想中小,这说明微调模型区分遮挡噪声的能力较弱。加入高斯噪声计算得到的FVD值相比baseline 呈现显著差异,随着高斯强度的增加,FVD 值也有明显的增加,说明微调模型能够检测不同强度的高斯噪声。总体上看,高斯噪声的FVD 值均比遮挡处理高,然而从视觉效果上观察,遮挡对视频质量的干扰程度更大,计算所得FVD 应更高,因此所呈现的FVD 值与可视化效果不符。
最后使用重新训练的I3D 模型,计算经过遮挡所得出的FVD 值比baseline 和高斯噪声高,且差值明显,这与可视化效果一致,说明重新训练的I3D 模型检测遮挡噪声的能力较强。然而,高斯噪声计算所得FVD 与baseline 呈现不出差异,且随着高斯强度的增加,FVD值变化不明显。事实上,紫外数据的一大特征在于亮斑的面积及其位置,高斯噪声不足以对亮斑这两个特性造成较大的干扰,因此所得FVD 值与baseline 呈现不出较大差异。当高斯噪声逐渐上升,使得肉眼难以分辨紫外亮斑边界时(如图9所示),FVD 值会有较为明显的上升(如图10所示)。

图9 不同强度高斯噪声下紫外图像的可视化效果Fig.9 Visualization of UV images with different intensity Gaussian noise
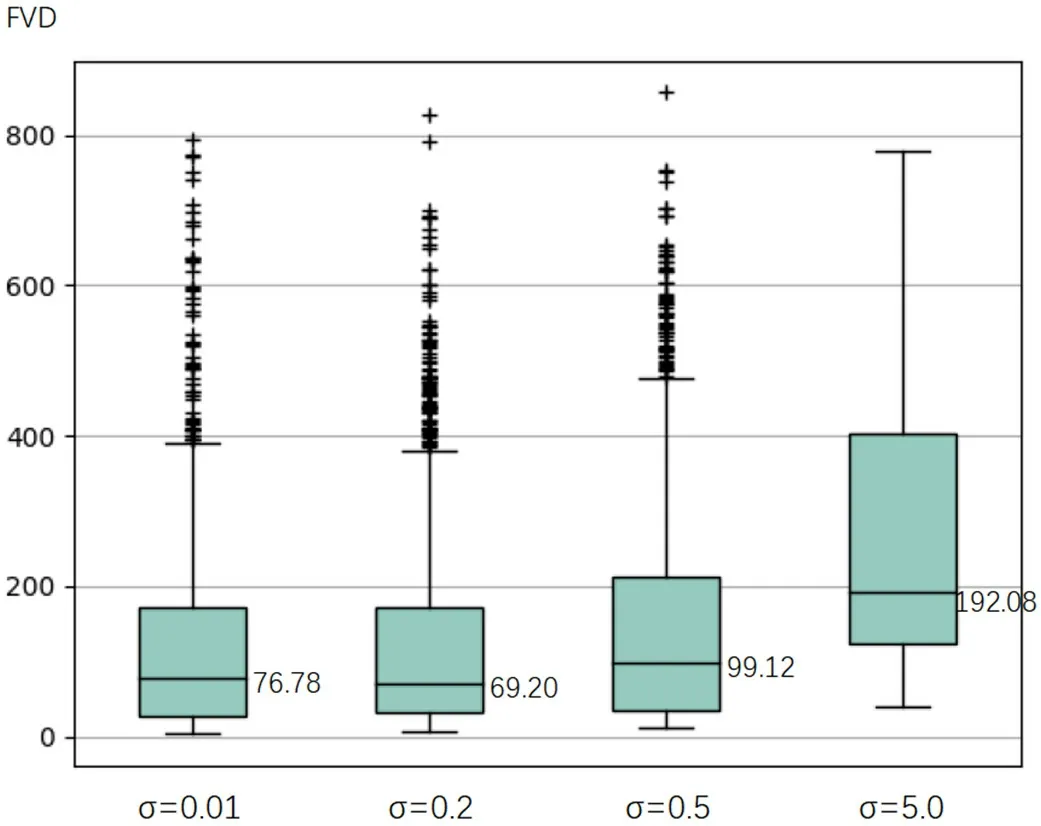
图10 不同高斯强度下的FVD 值Fig.10 FVD values at different Gaussian intensities
综合上述分析,FVD 在非可见光领域具备视频质量评估的能力,但同时应采用相应领域的数据集重新训练模型,提升模型提取特征的能力。合适的模型和FVD 二者相互结合,能使视频质量评估的结果更为准确。
2.4 模型不同层的特征是否会影响FVD 的计算
从视频分类模型的不同层提取特征,是否会影响FVD 的计算结果,为研究这一问题,本实验以下述三个模型作为研究对象,分别为:
(1)在Kinetics-400 上预训练的I3D 模型;
(2)使用紫外数据对预训练I3D 模型进行微调后得到的模型;
(3)在紫外数据集上从随机初始化权重开始训练的I3D 模型。
其中预训练模型的分类数为400,其余两个模型的分类数与紫外视频类别数相等均为2(即目标和干扰)。将紫外数据送入各个模型,根据I3D 模型特点,分别提取每个模型的最后两层特征计算FVD,结果如图11所示。
根据图11(上)发现,对于预训练模型,无论是baseline 还是经过遮挡和加噪的数据,在使用倒数第二层的特征计算FVD 值时均接近0,即FVD 无法评估视频质量,而使用倒数第一层的特征,FVD 值会有较为明显的差异,但加入高斯噪声的FVD 值比加入遮挡的FVD值更高,这与人眼感受不符,因此预训练模型仍无法准确评估二者质量好坏。
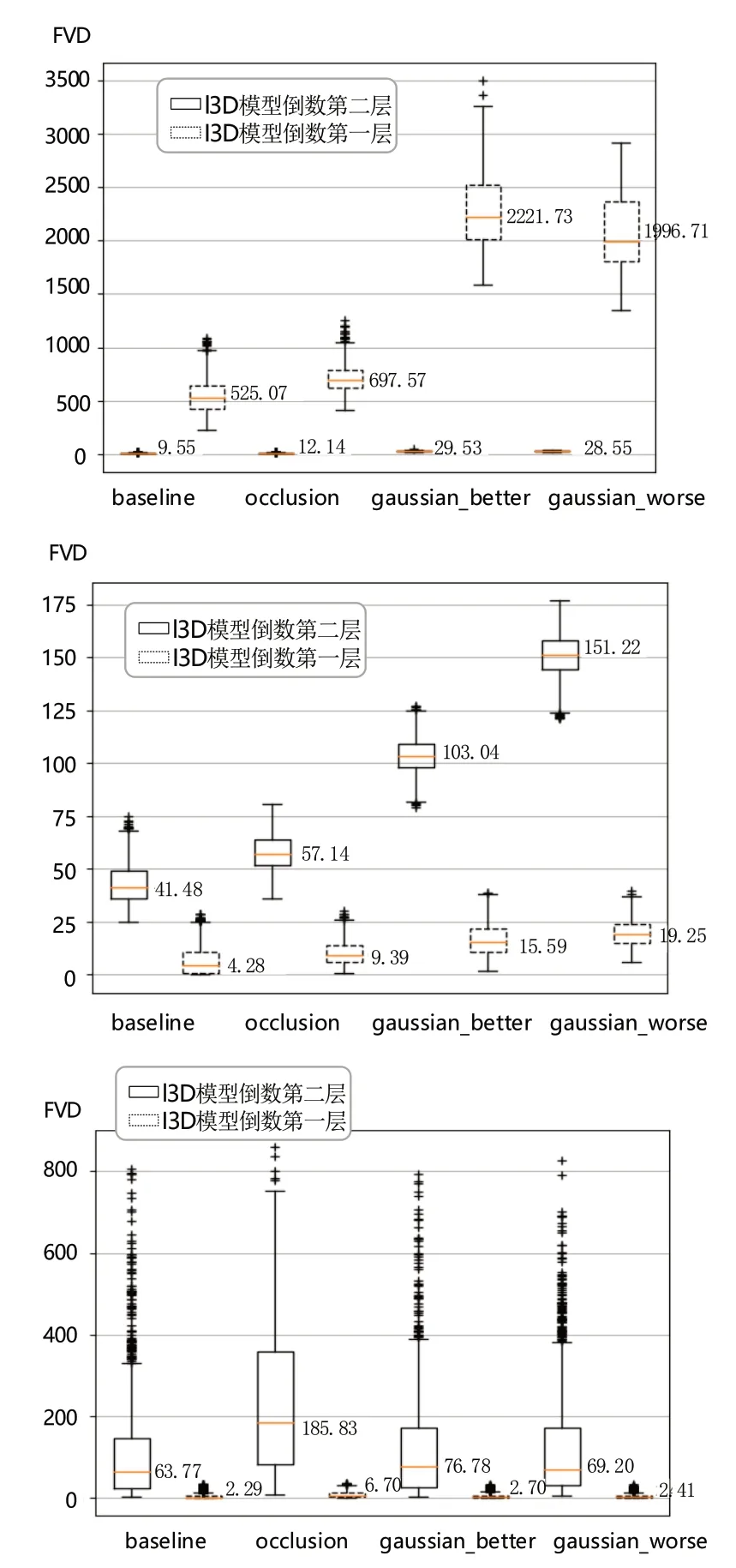
图11 使用预训练模型(上)、微调模型(中)和重新训练模型(下)计算的FVD 值Fig.11 FVD values calculated using the pre-trained model (top),fine-tuned model (middle) and re-trained model (bottom)
对微调模型,取倒数第一层特征计算出的FVD 值区分度太小,不具备评估价值。这可能是因为,I3D 模型的最后一层输出是输入数据在目标和干扰这两个类别上的概率,已经丢失了大部分能够表征视频原始特征的信息。如果取倒数第二层特征计算出的FVD 值,便能够观察到FVD 值明显的差别。然而加入遮挡的FVD 值比加入高斯噪声的FVD 值更低,这与人的视觉感受不符,因此微调模型在这种情况下也无法准确判断视频质量差异。
对于重新训练的I3D 模型,提取倒数第一层的特征计算出的FVD 值均较低,但使用其倒数第二层的特征所计算出的FVD 值能准确地区分出不同视频的质量,其中加入遮挡的FVD 值最高,加入高斯噪声的FVD 值与baseline 相差不大,这与视觉感受较为贴近。相比前两个模型,使用重新训练的I3D 模型提取倒二层特征计算FVD,能够得到更为准确的评估结果。
3 结论
本文研究了基于I3D 模型的FVD 在非可见光领域的应用表现,并根据对比实验提出了FVD 使用方法的优化。在使用FVD 这一评估指标分析非可见光视频质量时,由于在大型可见光数据集上训练的I3D 模型并不能很好地提取非可见光视频的特征,应尽量使用相关领域的数据集重新训练I3D 模型。当数据集的视频类别数较少时,I3D 模型最后一层的特征向量长度也较小,因此提取I3D 模型最后一层的特征所计算的FVD 并不能清晰准确地区分出视频质量差异,而选取倒数第二层或者更接近于模型输入端的特征能让FVD 的评估结果更为准确。
