基于MABM的消费者情感倾向识别模型
——以电影评论为例
2022-12-04刘洪伟林伟振温展明陈燕君易闽琦
刘洪伟,林伟振,温展明,陈燕君,易闽琦
(广东工业大学 管理学院, 广东 广州 510520)
消费者(用户)在使用各种网络平台后留下大量带有情感倾向的信息,这些信息表达了网民的情绪、情感与观点等主观性态度[1]。人们在网络发表的主观意见反映了他们对产品、服务和现有技术的满意程度,同时也影响消费者购买决策[2-4]。对于企业信息系统而言,在主观情感层次与用户进行交互具有重要意义,如提高产品质量、调整营销和经营策略、改善客户服务、危机管理、监控业绩、顾客需求识别、产品推荐等[1]。用户生成内容(User Generated Content,UGC)指用户在互联网中主动产生的内容,内容形式包括文字、图片或音视频等,文字是UGC的主要形式之一[5-6]。电影评论是用户观影后对电影质量做出的主观原创内容,反映了评论用户对某部电影的看法,并对其进行了积极或消极的批评,从而使其他用户都能了解这部电影的整体思想和概要,以影响电影消费选择。观众的评论成为一部电影是否成功的主要因素[7],电影评论影响电影口碑,从而影响电影利益相关方的盈利。与网络购物类似,用户做出观影购买决策前也会事先了解电影的评价和口碑。同时导演或演员看到电影评论也会被针对性地改善,使得更多客户的需求被满足。此外,对于电影院线平台,从用户既往评论中识别用户对电影的偏好,有利于个性化电影推荐系统机制的构建。因此,如何对电影评论进行分类,从而更有效地捕捉、检索、量化和分析观众情感需求,是一个至关重要的问题[8]。
情感分析(Sentiment Analysis, SA) 是理解消费者需求的关键途径[9]。电影评论分为正面或负面评论,评论的情感倾向与评论文本中出现的词汇有关,以及这些词汇之前是否在正面或负面语境中使用过等,理解这些因素有助于使用情感分析增强对评论的理解。情感分析也被称为意见挖掘(Opinion Mining, OM),是指识别和分类在文本所表达的主观意见,以确定顾客对某个特定话题的感受、态度或情绪是积极的还是消极的。SA也被定义为将具体数据转化为主观数据的过程,可以在不同的层次(文档、句子或方面) 进行。SA的过程包括分词、词过滤、停用词处理、字体繁简体转换、文本向量化、情感标注以及情感识别分类等。分词是将一段评论文本转化为一个词汇序列的过程[7]。通过词语过滤和停用词处理可以将介词、连词等无意义的词汇过滤[10]。字体繁简体转换是中文特有的文本方式,类似于英文词汇大小写转换。文本向量化表示是进行评论情感倾向识别建模的重要步骤,通过此过程得到评论情感倾向识别模型的输入特征[11]。文本向量化是机器学习领域对文本信息进行特征工程的主要流程,常见算法有Word2Vec, Text2Vec, Word2Vec-CBOW等,所得到的文本向量可作为机器学习模型的直接输入特征[12]。在自然语言处理领域,深度学习模型的输入特征向量由文本嵌入层Embedding Layers生成。不同于Word2Vec算法,Embedding层具有可训练性,可以跟随模型一同训练以更好地学习文本数据中的信息[13]。关于电影评论情感分类的既有研究常使用经典机器学习模型,如支持向量机、决策树、随机森林、K近邻等[7]。对于深度学习模型的选择,也往往简单应用循环神经网络,以及长短期记忆网络[14]、循环门控单元[15]、多头自注意力机制模型[16]等。
因此,本文提出基于多头自注意力机制和双向长短期记忆机制的神经网络模型MABM(Multi-head self-Attention and Bidirectional long-short term Memory neural-network),以既有研究中被验证有效的多种机器学习模型作为对照组,使用来自豆瓣电影的真实电影评论数据集,采用多种评估指标(准确率,精准率,召回率,F1值,曲下面积值),通过两组对比实验(交叉验证和测试集验证),以检验MABM模型情感分类识别的稳健性和有效性。本研究的贡献可以概括为:
其一,本文将基于多头自注意力机制神经网络和双向长短期记忆机制的神经网络进行结合,提出MABM模型,并采用多种模型评估指标和评估验证方法,综合对比MABM与10种不同机器学习分类器以及4种深度学习分类器的情感识别表现,以说明本研究所提出模型的有效性和稳健性,为挖掘用户情感倾向和电影需求偏好提供建议。
其二,本文以423 804条真实评论数据作为语料库训练文本向量化CBOW-Word2Vec模型,再训练10种机器学习模型作为本研究的对照组模型。既往研究已证明有效的情感识别分类模型有逻辑回归(Logistic Regression, LR)、支持向量机(Support Vector Machine, SVM)、决策树(Decision Tree, DT)、随机森林(Random Forest, RF)、多层感知器(Multi-Layers Perception, MLP)和自适应梯度提升树(Adaptive Boosting, Adaboost)等[7]。同时,由于文本向量维度高的特点,本研究还考虑了降维算法和支持向量机相结合的方式进行实验。
其三,本研究还选择同类型Embedding+深度学习模型作为对照组,包括模型11~14,以确保对比实验结果的稳健性、可行性和有效性。
本文的结构如下:引言介绍研究背景意义;第1节进行文献综述介绍既有研究进展;第2节介绍本文研究框架;第3节开展实证研究;第4节总结研究结论和局限性。
1 文献综述
当前,情感分析被广泛应用于识别并抽提文本蕴含的情感状态与要素。在方法上被认为可以分为基于情感词典和知识库的情感分析、基于机器学习的情感分析和基于深度学习的情感分析等3个类别[17-19]。比如,有学者通过利用语义分析技术建立基于知网的情感词库,分析并设计学生评教系统[19],再如有的学者基于超短评论建构了情感词典,用于分析图书评论场景中的情感分析与挖掘[20]。然而,这类方法普遍存在着情感区分度不够导致数据适恰性与分类效能较低的缺陷[17,21]。
此后,随着不同机器学习算法的提出与优化,基于机器学习算法的情感分析方法逐渐成为情感分析领域内的重要分支,学者们取得了一系列的研究成果[22]。譬如有学者使用支持向量机SVM方法建构微博情感分类模型分析舆情情感演化,以期有效实现舆情精准预测[23]。再如,有的学者使用并行朴素贝叶斯算法(Naive Bayesian, NB)对于Twitter实时情绪进行分类,进行大数据背景下的算法适配性研究[24]。但是这些机器学习模型被认为在复杂分类问题上泛化能力较差,在实际情感分类上的表现并不如基于主题的分类好[25-27]。
在基于机器学习模型进行情感分类遇到发展瓶颈时,神经网络因克服了高维数据稀疏问题而逐渐引领了情感分类领域的研究[17]。譬如有学者基于卷积神经网络对电子商务领域的消费者情感分类,实现了自适应的情感分类[28],还有学者提出结合多粒度卷积神经算法和双向门控循环单元(Bidirectional Gate Recurrent Unit, Bi-GRU)的深度学习情感分析方法,在中文语料的处理中加入了多层自注意力机制,使得情感分类的性能得到了显著提升[29]。学者朱丽等[30]更是将卷积神经网络与双向长短时记忆Bi-LSTM(Bidirectional Long-Short Term Memory)网络结合建立混合模型,对脑电波情感识别进行了研究。有学者通过对上述三类情感分析方法进行横向比较,指出基于多策略学习机制混合的方法是未来情感分析的重要方向[10,31]。
长短期记忆神经网络LSTM(Long-Short Term Memory)作为循环神经网络的一种,被广泛应用于序列化数据,如文本数据、点击流数据、时间序列数据等[32]。此外,门控循环单元GRU(Gate Recurrent Unit)也是一种基于长短期记忆机制的循环神经网络。相比于LSTM,GRU具有结构简单、计算效率高等特点。但由于其单向序列化学习过程易造成长期信息的丢失,为解决此问题,学者们采用双向学习以缓解信息丢失的情况,而基于双向长短期记忆机制的Bi-LSTM和Bi-GRU也具有更出色的预测表现[33-34]。尽管记忆力机制网络对文本序列数据有不错的学习能力,但学习文本重点信息以及信息相互关系的能力有所欠缺,采用多头自注意力机制的神经网络模型可弥补这一不足。
Vaswani等[35]提出了基于多头自注意力机制的BERT模型(Bidirectional Encoder Representation from Transformers)。得益于其多头自注意力机制,BERT模型被广泛应用于各种领域,尤其在自然语言处理(Natural Language Processing, NLP)领域中大放异彩,对各项NLP任务的预测效果均有出色表现[35-38],包括情感分类、命名实体识别、文章总结、智能问答、知识图谱以及推荐系统方向等等[35]。
综上所述,本文提出基于多头自注意力机制和双向长短期记忆神经网络的MABM模型,以探讨两种深度学习机制组合下的神经网络模型(MABM)对影评情感倾向的分类识别能力。同时,本研究将MABM模型与机器学习算法进行对比分析,以验证模型的有效性和稳健性。
2 研究框架
2.1 特征工程
本文通过爬虫获得豆瓣影评数据,然后进行特征建构,主要包括对影片文本数据进行评论情感标签转换与文本数据的预处理。在评论文本的情感标签转换时,将评分不小于3的评论样本标注为积极情感(y=1),评分小于3的样本标注为消极情感(y=0);而在评论文本的预处理时,主要包括了繁简体转换、分词、去除停用词、去除标点符号等非中文字体等一系列数据预处理操作。
对于机器学习模型,本文采用423 804条评论语料数据训练基于CBOW的Word2Vec模型,将对预处理后的评论文本数据进行词向量转化和平均池化,从而得到评论文本向量。而对于深度学习模型,本文首先对预处理后的评论文本进行编码,然后通过Embedding层得到评论文本向量。最后,将整合评论向量化数据与情感标签得到标准化的全数据集,共计12 222个样本,按照8:2划分为训练集(9 777)和测试集(2 445)。
2.2 MABM模型
本文提出基于多头自注意力机制和双向长短期记忆神经网络的MABM模型,以识别用户在评论中表达的情感倾向模型。由图1可知,MABM模型结构可分为4个部分,分别为输入层,BERT多头注意力层、双向记忆层以及输出层。首先,通过Embedding层将用户评论转化成输入向量;其次,使用多头注意力机制的BERT层提取输入向量的信息;再次,利用双向记忆神经网络(Bi-LSTM和Bi-GRU)深化对关键信息的提取;最后,由MLP层输出用户情感倾向识别结果。

图1 MABM模型结构图Fig.1 Structure of the MABM model
2.3 模型交叉验证和测试集对比分析
为了验证MABM模型的有效性,本文将10个机器学习模型、4个深度学习模型作为对照组进行交叉验证对比实验。在模型的交叉验证上采用5折交叉验证,并以准确率(Accuracy)、精准率(Precision)、召回率(Recall)、曲线下面积(ROC-AUC)和F1值等5个指标作为模型稳定性评价。模型描述如下:
机器学习模型包括(模型1~10):模型1(逻辑回归LR)、模型2(决策树DT)、模型3(随机森林RF)、模型4(极端随机树ET)、模型5(BP神经网络-MLP)、模型6(K近邻KNN)、模型7(朴素贝叶斯NB)、模型8(自适应增强算法Adaboost)、模型9(PCA+SVM)、模型10(PCA+RF+SVM);
对照组深度学习模型包括(模型11~14):模型11(2-Bi-LSTM+MLP)、模型12(BERT+MLP)、模型13(BERT+2-Bi-LSTM+MLP)、模型14(BERT+2-Bi-GRU+MLP);
本研究提出模型MABM(模型15):BERT+Bi-(2-LSTM-GRU) +MLP。
综上所述,本文研究框架如图2所示,整个框架分为两个部分:特征工程,模型交叉验证和模型测试集验证。
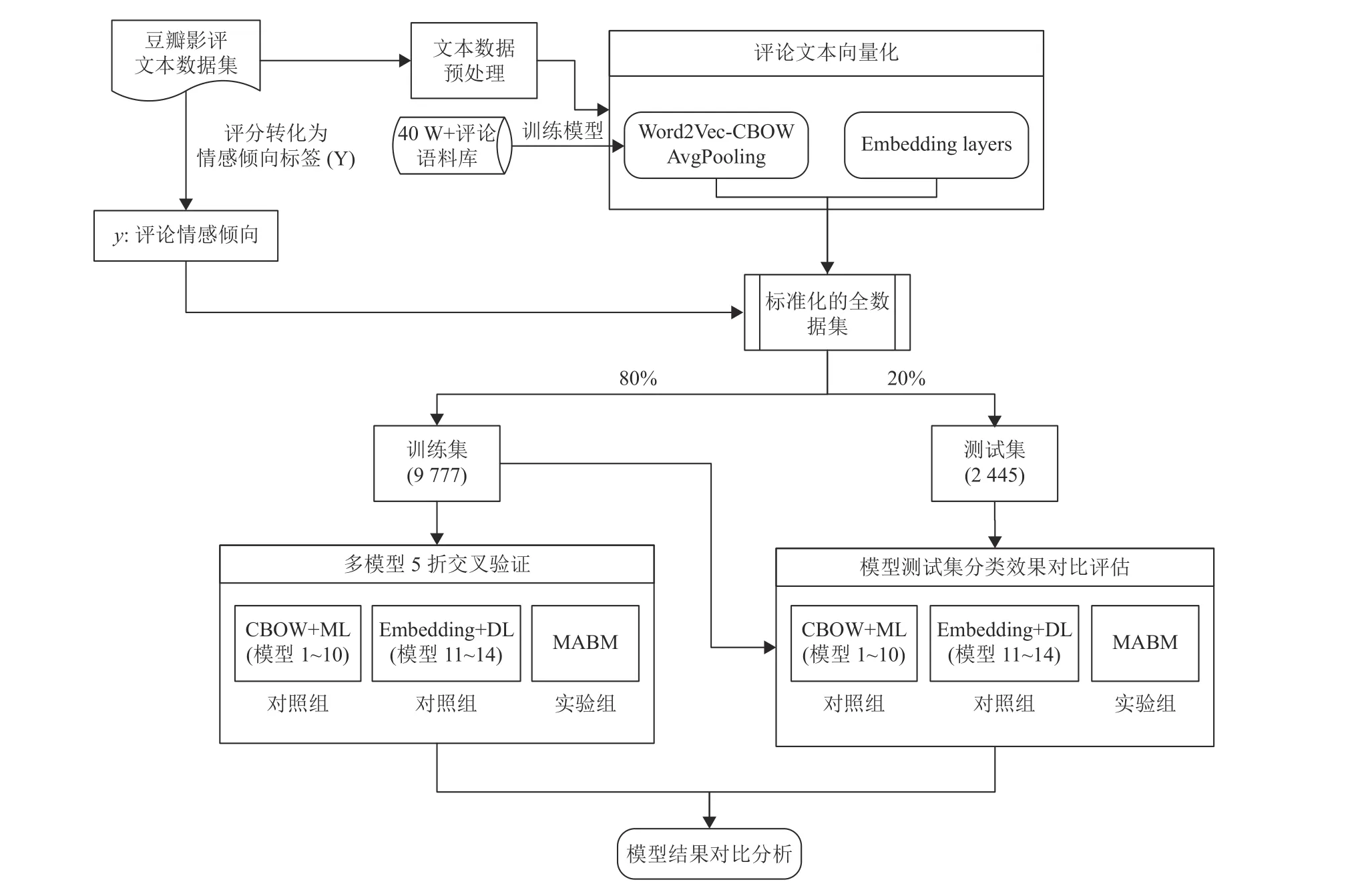
图2 研究框架Fig.2 Research framework
3 实证研究
3.1 数据描述
本研究的数据爬取自豆瓣影评2007-08-08 17:57: 00至2021-05-31 22: 57: 00期间6 989个用户对113部热门电影的12 222条电影评论,按照数据集、用户与电影3个层级进行电影评论情感倾向的描述性统计(见表1)。从评分角度发现,数据集、用户和电影3个层级的均值分别为3.04、3.02和3.07,中位数分别为3.00、3.00和3.05,评分呈正态分布。其中,按照1~5星打分标准,电影最低评分为2.43,最高评分为4.11。假设将评分不小于3视为积极倾向,从情感倾向角度分析,则 68%的评论为积极评论,66%的用户倾向于发表积极看法,69%的电影口碑积极。
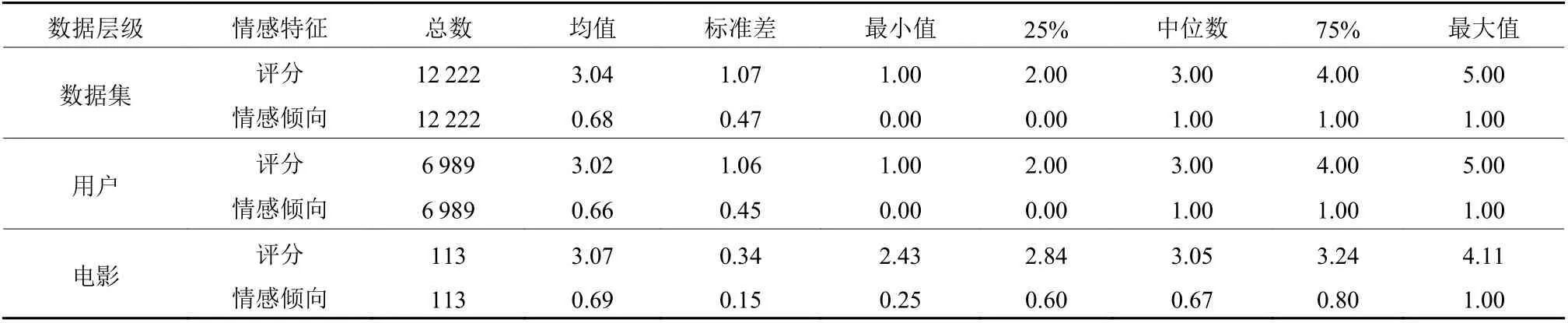
表1 描述性统计Table 1 Descriptive statistics
3.2 模型识别效果分析
本研究将数据按照8:2将数据集划分为训练集(9 777)和测试集(2 445),且训练集(0.684 9)和测试集(0.678 1)中不同情感倾向类别样本比例相似。为了验证MABM模型的有效性,分别训练10个机器学习模型、4个深度学习模型作为对照组进行对比实验。为保证结果的稳健性,采用多种评估指标衡量模型分类表现,并设计了两组对比试验:
(1) 所有模型在训练集上进行5折交叉验证(见表2~3);
(2) 所有模型在测试集上分类表现(见表4~5)。
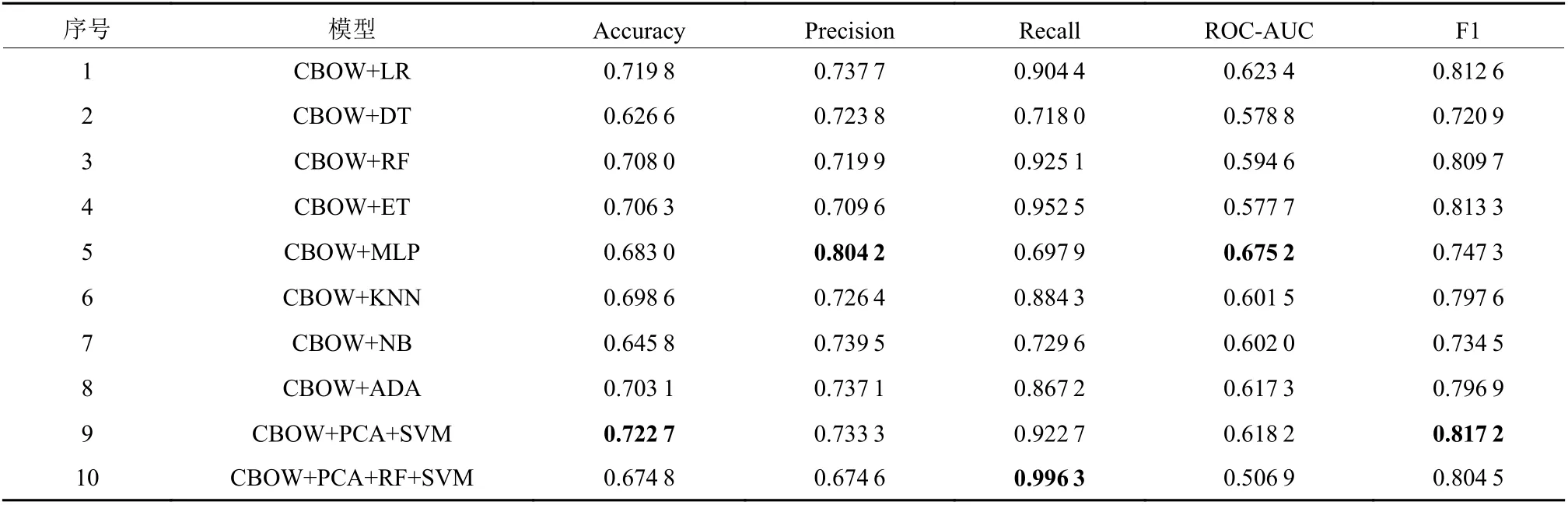
表4 CBOW+机器学习模型测试集分类效果Table 4 Classification results of the CBOW+ machine learning model test set
3.2.1 模型交叉验证结果对比分析
对比10个机器学习模型发现(见表2),模型9支持向量机 (CBOW+PCA+SVM)在训练集上交叉验证表现效果最佳(准确率74.03%,ROC-AUC=0.776 2,F1=0.831 0),其次是逻辑回归(准确率73.95%,ROCAUC=0.776 2,F1=0.831 0)和随机森林(准确率73.06%,ROC-AUC=0.776 2,F1=0.831 0)。机器学习模型1~10的F1均值为0.800 2。
根据表3可知,相比于模型11~14,MABM模型的交叉验证评估表现显著提升且效果最佳(准确率78.58%,ROC-AUC=0.696 6,F1=0.857 2),并且所有深度神经网络模型的F1均值为0.828 1。
综合对比表2和表3可知,基于多头自注意力机制和记忆力机制的深度神经网络模型预测效果(F1均值=0.828 2,准确率均值73.81%,ROC-AUC均值=0.629 6)整体优于机器学习模型(F1均值=0.800 2,准确率均值70.51%,ROC-AUC均值=0.693 9),并且本文提出的MABM模型在训练集的交叉验证分类表现最佳。

表3 Word-Embedding +深度学习模型交叉验证Table 3 Cross-validation of Word-Embedding + Deep Learning Models
3.2.2 模型测试集分类效果对比分析
为检验不同模型在训练集样本外的测试集的分类表现,本研究在测试集上对模型进行对比实验(见表4~5)。根据表4可知,在所有机器学习模型中,表现最佳的是支持向量机SVM(准确率72.27%,ROCAUC=0.618 2,F1=0.817 2),其次是极端随机树ET(准确率70.63%,ROC-AUC=0.577 7,F1=0.813 3),第三是逻辑回归LR(准确率71.89%,ROC-AUC=0.623 4,F1=0.812 6)。表4中所有机器学习模型的F1均值为0.785 4,准确率均值为0.688 9,ROC-AUC均值为0.599 6。
表5表明,相比于模型11~14,本研究提出的MABM模型的测试集分类效果提升明显且表现最佳(准确率85.15%,ROC-AUC=0.832 5,F1=0.890 0),随后分别是模型14、模型12以及模型13,并且MABM和模型11的F1差值为0.092,这说明基于Embedding层、多头自注意力机制的BERT和长短期记忆神经网络(LSTM和GRU)的组合模型对于识别评论文本的情感倾向的能力更强。表5中所有机器学习模型的F1均值=0.828 0,准确率均值为74.27%,ROC-AUC均值为0.653 9。

表5 Word-Embedding +深度学习模型测试集分类效果Table 5 Classification results of the Word-Embedding + Deep Learning model test set
通过对比表4和表5的模型测试集评估结果,基于Embedding层、多头自注意力机制和长短期记忆力机制的深度神经网络模型(模型11~15)预测效果(F1=0.828 0,准确率为74.27%,ROC-AUC= 0.653 9)整体优于机器学习模型(F1=0.785 4,准确率68.89%,ROC-AUC=0.599 6),MABM模型在测试集上分类表现最佳。
根据所有模型在测试集上分类的F1值进行排序(见表6)。根据表6可知所有模型的分类预测表现排序为:模型15(MABM)>模型14(BERT+2-Bi-GRU+MLP)>模型12(BERT+MLP)>模型9(PCA+SVM)>模型4(极端随机树ET)>模型1(逻辑回归LR)>模型13(BERT+2-Bi-LSTM+MLP)>模型3(随机森林RF)>模型10(PCA+RF+SVM)>模型11(2-Bi-LSTM+MLP)>模型6(K近邻KNN)>模型8(自适应增强算法Adaboost)>模型5(BP神经网络-MLP)>模型7(朴素贝叶斯NB)>模型2(决策树DT)。
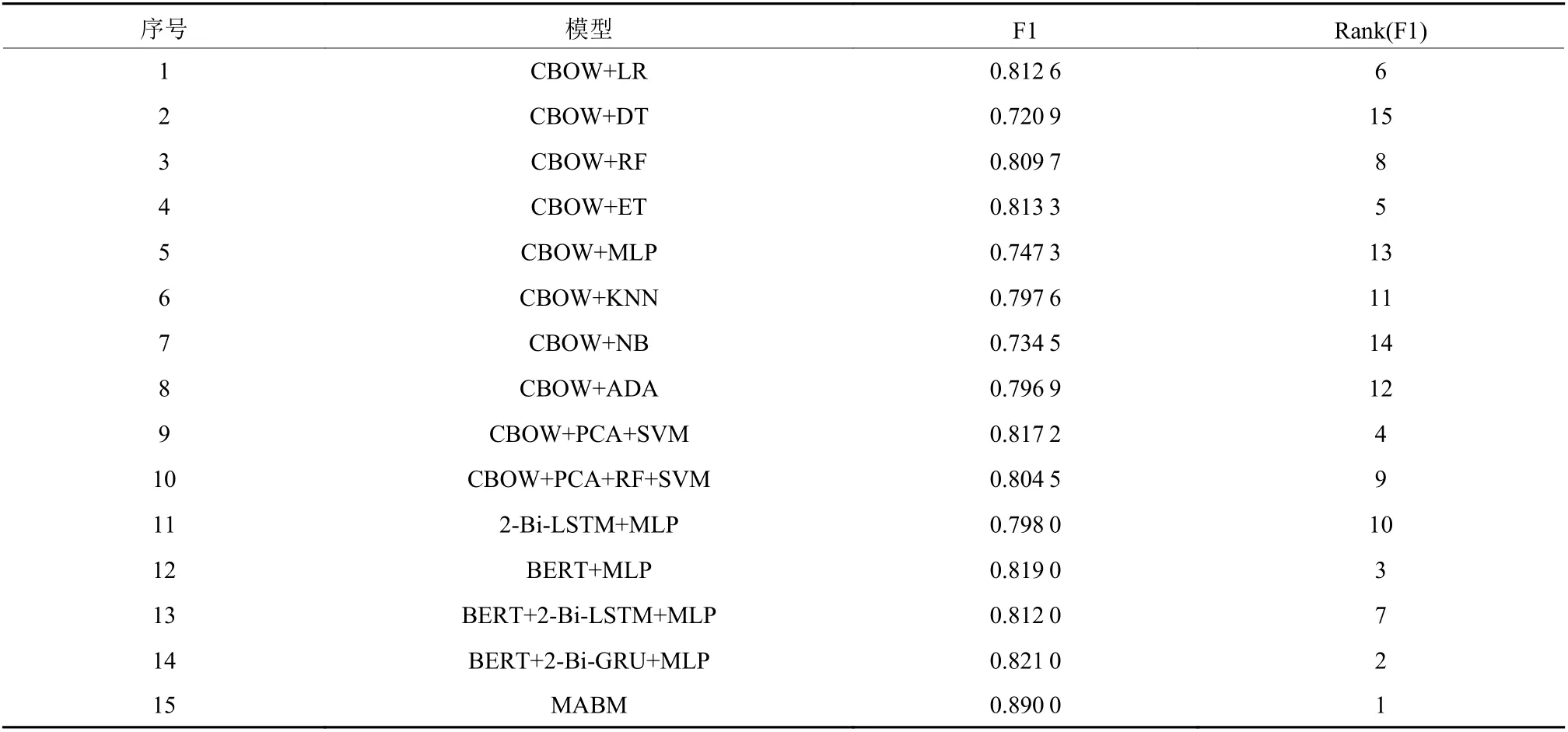
表6 模型测试集评估排位Table 6 Model test set assessment ranking
综上所述,本研究采用多种模型评估指标,对MABM模型、10个机器学习模型,以及4个深度学习模型进行交叉验证和测试集评估对比实验分析发现,基于Embedding层、多头自注意力机制和长短期记忆机制的神经网络模型,能够更好地学习电影评论文本中所蕴含的情感倾向信息,并且本文提出的MABM模型与其他同类模型相比,在训练集交叉验证和测试集评估表现最佳(准确率85.15%,ROCAUC=0.832 5,F1=0.890 0)。
4 结论
本研究在对比各类常见情感分析算法的基础上,提出了一种MABM算法,将使用基于词袋模型(CBOW)算法的决策树、随机森林、ExtraTree、Adaboost等在内的10个机器学习模型和基于多头自注意力机制与长短期记忆神经网络的5个深度学习模型进行了对比,在交叉验证的基础上依据准确率(Accuracy)、精准率(Precision)、召回率(Recall)、曲线下面积(ROC-AUC)和F1值等多指标对这些机器学习模型和深度学习模型进行了对比与模型效能评估。研究结果表明,在模型的整体分类与预测效果最佳的模型排序为:模型15(MABM)>模型14(BERT+2-Bi-GRU+MLP)>模型12(BERT+MLP)>模型9(PCA+SVM)>模型4(极端随机树ET)>模型1(逻辑回归LR)>模型13(BERT+2-Bi-LSTM+MLP )>模型3(随机森林RF)>模型10(PCA+RF+SVM)>模型11(2-Bi-LSTM+MLP)>模型6(K近邻KNN)>模型8(自适应增强算法Adaboost)>模型5(BP神经网络-MLP)>模型7(朴素贝叶斯N B)>模型2(决策树D T),基于Embedding层、多头自注意力机制和长短期记忆力机制的深度神经网络模型(模型11~15)预测效果在整体上要优于机器学习模型,并且本文提出的MABM模型在测试集上分类表现最佳。
本文的研究证实了深度学习模型在影评情感分类的任务上比起常规的机器学习模型有着更好的效能,深度学习模型比机器学习模型要更加适合高通量数据的复杂情感分类任务。其中,本研究提出的基于多头自注意力机制和记忆力机制的深度神经网络模型(MABM)有着最佳的影评情感分类效能,其模型准确率可以达到0.851 5,精确率0.894 1,召回率0.886 0,ROC-AUC值为0.832 5,而反映模型整体预测质量的F1值为0.890 0,表明MABM模型在影评的情感分类与预测中都表现出极佳分类效能与模型稳健性,能够适用于电影影评的情感分类任务。在具体的电影发行与平台消费者推荐上,可以根据本文模型对电影情感的分类来向有相同偏好的消费者进行智能匹配,提升电影购买或观影转化率,为电影运营商带来更多可能的盈利。
综上所述,本文将机器学习算法和深度学习模型进行了横向对比,验证了深度学习模型在影评情感分类任务上的适恰性,由于本文训练的模型使用的影评语料库,该模型更多地适用于电影影评的情感分类任务,对于音乐音评、书评等其他品类的适恰性还有待验证,同时尚未考虑评论真实性以及评论数据范围的局限性。未来在训练评论情感分类模型时,将各类书评、影评等要素与虚假评论情况纳入模型训练过程是下一步研究的方向。
