面向地震数据交互分析场景的高效分布式缓存框架
2022-12-03许自龙朱海伟陈海洋邵志东
庞 锐,许自龙,朱海伟,陈海洋,邵志东
(中国石化石油物探技术研究院有限公司,江苏南京211103)
随着“两宽一高”地震采集技术的发展应用,采集得到的原始地震勘探数据呈指数级增长,数据规模越来越大[1]。对于大数据,麦肯锡全球研究院给出的定义是:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合[2-3]。以炮集记录为例,采集覆盖次数由几十次增至几千次,单炮记录可超过万道,数据量由10MB增至250MB,每天产生的数据量达到了TB级别[4]。
采用二维图形显示的方式对单炮记录进行交互分析[5],需要频繁地在单炮记录间切换,因此对实时响应要求较高,一般希望地震数据浏览延迟不超过1s。但在面对单炮记录超过万道的大规模数据时,通常地震数据处理软件由于本身内存限制,无法直接缓存大量单炮记录,必须反复从底层物理存储中读取数据,因而数据实时访问时间延迟变长,从而导致交互操作出现卡顿,影响交互分析的流畅性,降低了工作效率。
中国石化自主研发的大型地震一体化软件平台(π-Frame)是地震数据处理的专业应用平台,目前平台底层使用Hadoop分布式文件系统(HDFS)存储大规模叠前地震数据,HDFS是一种具有高可靠性的分布式文件系统,能够存储PB级别的大规模数据[6]。在进行单炮交互分析时,需要反复从HDFS底层文件系统中读取数据,当单炮记录超过万道时,读取一炮记录的时间延迟甚至超过2s,因而交互操作卡顿,降低了用户体验。
为此,本文针对大规模数据交互分析的场景,研究设计了一套面向地震交互分析专用的高效数据缓存框架,利用分布式内存技术预先缓存关键地震数据,从而提高数据实时访问性能,减少交互操作卡顿,提高工作效率。
1 不同存储系统下地震数据读取性能对比分析
用于二维图形显示的地震数据可以抽象为数据道的集合。以叠前炮集为例,由多个单炮记录组成,单炮记录由多道采样数据组成。每一道数据包含N个浮点类型的采样值,这样的一道数据称之为一个Trace,由多道相关数据组成的集合称之为TraceSet。本文工作的数据缓存结构以一个TraceSet为最小单位来进行,数据读写的最小单位是一个TraceSet,实际应用中,将炮集、共中心道集、共偏移距道集等统一转换成抽象的二维TraceSet对象进行管理。
HDFS是一种可以运行在通用硬件上的分布式文件系统,它和早期的分布式文件系统有一些共同点,同时,相比其它分布式文件系统,它有很多自己的特点。HDFS是一个高度容错性的系统,适合部署在廉价的机器上,HDFS能提供高吞吐量的数据访问,非常适合大规模数据集的应用[7-8]。
Alluxio是一种以内存为中心的分布式存储系统,提供内存级别的数据读写,非常适合多次读写以及读写性能要求较高的场景,热数据的读取速度比磁盘高一个量级[9-10]。
为了对比HDFS和Alluxio的性能差异,本文针对单炮数据读取场景,分别评估了HDFS和Alluxio在同一种读取方式下的性能差异。测试数据共3000炮,每炮规模为3000道×6000采样点,总体数据的物理大小约为201GB。
本文的不同存储性能评估实验使用的集群共有5个物理节点,其中1台机器作为主节点(Alluxio-Master,HDFS-Namenode),3台作为从节点(Alluxio-Worker,HDFS-DataNode),1台作为客户端节点用于执行实验程序。实验环境的软硬件信息如表1 所示。

表1 不同存储性能评估实验环境配置
读取性能测试结果如图1和图2所示,可以看出:HDFS的读取耗时在300~500ms波动(图1);Alluxio的第1次读取耗时较长,主要是因为第1次读取需要将数据从磁盘加载到内存中,磁盘IO导致耗时较长,后续读取,由于数据已经在内存中,可以直接从内存中读取,耗时基本稳定在100ms左右,数据规模一旦上升,Alluxio的性能会更好并且更稳定[11-12](图2)。

图1 HDFS读取数据耗时
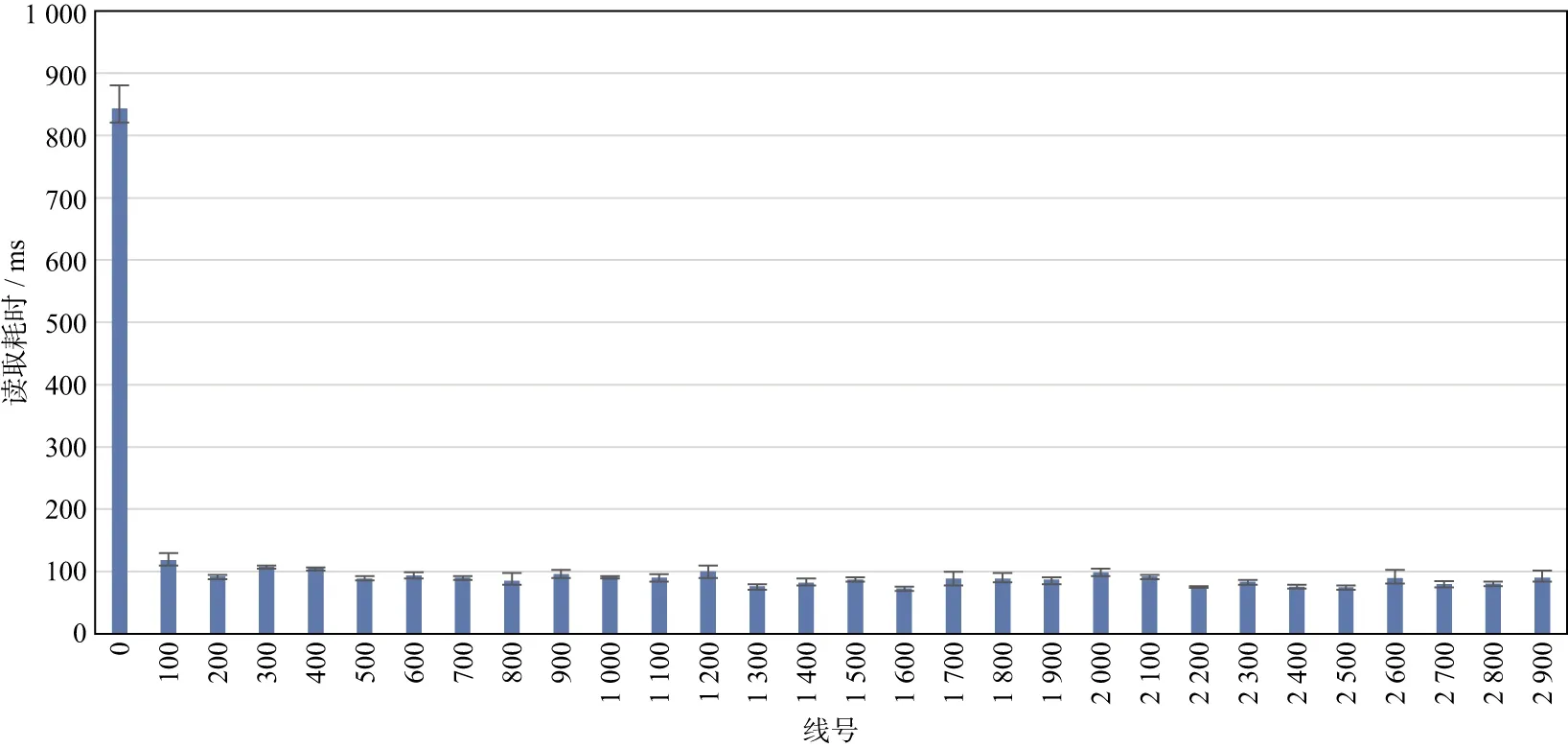
图2 Alluxio读取数据耗时
由上述HDFS和Alluxio的性能评估实验可以发现,Alluxio读取剖面的性能优于HDFS。究其原因是因为,TraceSet存储在HDFS中时,每读取一个Trace都需要寻道一次,导致读取一个TraceSet需要寻道多次,磁盘级别的多次寻道造成了大量性能开销,导致TraceSet读取时间较长,难以满足交互式场景下的性能需求。
2 高效分布式缓存框架
前文综合对比分析了HDFS和Alluxio两类数据存储框架的数据读取性能,发现Alluxio更适合TraceSet的读写。然而,原生Alluxio的数据块会分布在多个节点上,对于1个TraceSet,会出现跨节点的寻道操作,这会降低读取性能。为保证从Alluxio-Worker读取数据的本地性,本文提出在每个Alluxio-Worker节点上部署一个代理服务,用于直接与本地的Alluxio-Worker进行数据交换,这样既利用了Alluxio内存存储利于读写的特性,也降低了多次网络传输的开销。
2.1 系统架构
综上所述,本文提出了一套基于Alluxio的分布式缓存框架,系统架构如图3所示,主要包括3个模块:CacheClient,CacheMaster,CacheHandler,图3中虚线为元数据路径,实线为数据路径。
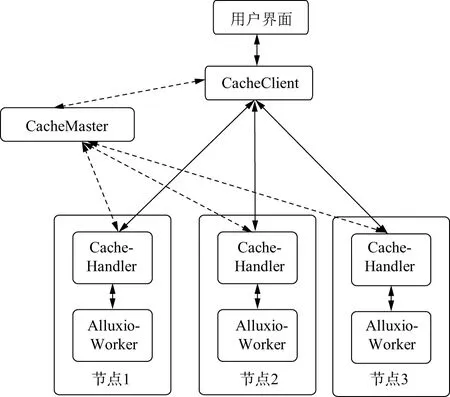
图3 基于Alluxio的分布式缓存框架整体结构
该架构基本满足了分布式缓存框架的重要功能需求,包括:多用户场景下的可用性、保存所有TraceSet的元数据信息、支持覆盖写、异步加载数据、数据的负载均衡等。
2.2 CacheMaster模块
CacheMaster是整个分布式缓存框架的核心模块,负责管理整个框架的数据调度、数据管理、状态监控等功能。具体包括:
1) 将要写入的TraceSet以文件的形式,存储到分布式缓存框架中;
2) 存储TraceSet时,会根据所有节点的可用内存来均衡调度,达到负载均衡的效果;
3) 保存所有已存储的TraceSet的元信息,包括所在节点、文件大小等;
4) 支持TraceSet的覆盖写,方式为写临时文件→删除旧文件→重命名;
5) 支持数据生存周期(TTL)策略,到设定时间后,内存中的数据自动释放;
6) 支持监控所有存储节点的服务状态,通过心跳机制来收集存储节点的状态信息。
2.3 CacheHandler模块
CacheHandler负责具体执行分布式缓存框架的读写功能,需要与Alluxio-Worker部署在同一台节点上,用于直接操作本地的内存数据,包括读取、写入、删除、加载等操作,保证本地性。
同时为了增加系统的可靠性与可扩展性,CacheHandler会主动向CacheMaster发送心跳信息,一方面可用于CacheMaster对所有CacheHandler服务状态的监控;另一方面,当系统需要扩容时,直接新增一个CacheHandler服务,可以方便灵活地加入集群中提供服务。
2.4 CacheClient模块
CacheClient模块部署在用户端,直接向用户的客户端提供服务接口,处理用户请求,如:数据读取、写入、删除等。CacheClient目前提供表2所示的6种接口方法。

表2 分布式缓存框架接口方法
2.5 重要功能介绍
当前的分布式缓存框架提供的主要功能包括:读数据、预加载数据、写数据、覆盖写数据、清除数据、读元数据。
2.5.1 读数据功能
读数据功能具体包括两种。对于TraceSet的多维数据结构体来说:支持x方向的全量读取、间隔读取;也支持设置x和y方向的起止范围。读数据流程如图4所示,其中①,②,③,④代表4个步骤:①CacheClient发起读请求,从CacheMaster获取文件所在节点的信息;②CacheMaster将文件所在节点的IP返回给CacheClient;③CacheClient拿到IP后直接去对应的节点请求CacheHandler服务读取数据;④CacheHandler读取内存中的数据后返回给CacheClient。

图4 读数据流程
2.5.2 预加载数据功能
预加载数据功能支持在读取之前先将指定的数据缓存到内存中,加载时支持批量加载,以加速后续的数据读取。预加载数据流程如图5所示,其中①,②,③代表3个步骤:①CacheClient发起加载请求到CacheMaster,CacheMaster计算得出可用节点的IP,同时记录TraceSet和IP的映射关系;②CacheMaster通知对应的CacheHandler加载数据;③CacheHandler接收到请求后向底层存储请求读取数据,收到底层存储返回的数据后将其写入内存中。

图5 预加载数据流程
2.5.3 写数据功能
写数据功能支持客户端在图形页面上选中数据后,将数据写入到分布式缓存中,下次读取时直接从内存中读取,从而缩短读取时间。写数据流程如图6所示,其中①,②,③代表3个步骤:①CacheClient向CacheMaster发起写请求,CacheMaster计算可用IP,记录TraceSet和IP的映射关系;②CacheMaster返回IP地址给CacheClient;③CacheClient得到IP后将数据发送到对应的CacheHandler服务上,CacheHandler再将数据写入内存中。

图6 写数据流程
2.6 特性介绍
2.6.1 负载均衡
负载均衡的原则是让TraceSet数据集尽可能地均匀分布在多个存储节点上,目的是为了降低单个节点的读写压力,这样读写性能会更好。如果系统的负载不均衡,首先会造成多个节点之间的数据存储量大小不同,部分节点压力过大;其次会造成部分节点内存空间不足而频繁出错,造成系统可用性和稳定性下降。因此负载均衡在分布式系统中是非常必要的。
当前分布式缓存框架实现负载均衡策略的具体流程为:CacheClient发起写请求到CacheMaster,CacheMaster计算出当前剩余内存最大的节点IP,将IP返回给CacheClient,CacheClient得到IP后将数据发送到对应的CacheHandler,CacheHandler接收到数据后将数据写入本地的Alluxio-Worker中。
2.6.2 多级数据TTL策略
数据TTL的用途是到期后自动删除分布式缓存中的文件,其目标主要是减轻集群压力。如果没有TTL策略,用户也没有及时删除一些不用的数据,就会造成系统内存中大量无用数据的堆积,浪费资源,并且大量无用文件或目录也会占用系统的元数据空间,对系统性能有一定的影响。
分布式数据缓存的TTL包括两级:一是针对单个文件的TTL,二是针对所有空目录的TTL。如要用到被删除文件,可以重新加载。其具体的流程为:CacheMaster根据配置的TTL来定期删除文件,策略是以最近一次使用开始计时,到期后自动删除元数据以及Alluxio-Worker中的数据,用户目录下的文件因为TTL策略被删除后,则该用户的所有空目录也会被删除。
2.6.3 节点状态监控
在一个分布式系统中,主节点一般需要监控所有从节点的状态,如果没有监控机制,就会出现如下问题:当某个从节点由于网络或硬件故障导致无法正常提供服务时,主节点仍然继续向这个节点进行数据读写,从而造成读写失败。
在当前分布式缓存框架中,CacheHandler会定时通过心跳信息向CacheMaster上报自己的状态,然后CacheMaster也会定期检查所有的状态信息,根据一定的规则来判断CacheHandler是否失效。具体的流程为:所有CacheHandler会通过心跳定期向CacheMaster上报状态信息,CacheMaster会定时轮询每个CacheHandler上报的状态信息,如果发现某个CacheHandler最近一次上报时间超过设置的超时阈值,则认为该节点失效,然后将不再从该节点读写数据。
2.6.4 元数据备份
元数据的备份可以有效防止主节点即CacheMaster的失效而导致元数据丢失的错误。
本文实现方式是CacheMaster会定期将内存中的元数据序列化到磁盘上,在CacheMaster失效后,下次重启时,会自动反序列化备份文件,恢复元数据。其具体流程为:CacheMaster接收CacheClient的操作请求,保存元数据到内存映射中,定期序列化元数据到文件中,防止由于CacheMaster的失效而导致元数据丢失,CacheMaster重启时会自动反序列化元数据到内存中,继续提供服务。
2.6.5 灵活扩展性
当前分布式缓存框架具有一定的灵活扩展性,可以根据数据量的不断增加而动态扩充节点,并且可以在不重启服务的情况下完成。当前框架下,CacheHandler采用主动上报的机制来注册自己,具体流程为:每个CacheHandler启动时,都会主动通过心跳信息向CacheMaster上报自己的状态信息,CacheMaster中维护有一个所有可用从节点的列表,接收到CacheHandler的心跳后就将该CacheHandler加入到可用列表,完成扩容。
3 分布式缓存框架与地震处理软件平台的对接
中国石化自主研发的大型地震一体化软件平台(π-Frame)是处理地震数据的专业应用平台,目前π-Frame平台底层使用HDFS来存储大规模叠前数据,通过平台提供的IOService数据访问接口访问平台管理的地震数据,如图7所示。

图7 π-Frame平台数据读取示意
为了验证基于Alluxio的分布式缓存框架的有效性,将其与π-Frame平台进行初步对接集成,交互应用通过分布式缓存框架获取数据,缓存框架通过IOService到底层存储获取数据,π-Frame平台集成分布式缓存框架(层次调用关系)如图8所示。

图8 π-Frame平台集成分布式缓存框架示意
面向地震数据的交互应用场景,整体按数据存储大小分为3个层级(图9)。
1) 应用层:内存有限,仅管理当前使用的地震数据;
2) 分布式内存层:利用分布式内存的大容量优势,缓存于当前操作相关的更大范围的地震数据;
3) 平台物理存储层:存储全部地震数据。

图9 数据存储层级
4 实验
4.1 实验环境
本文搭建的分布式缓存框架实验环境与表1一致,只是在主节点增加CacheMaster服务(Alluxio-Master,HDFS-Namenode,CacheMaster),在从节点增加CacheHandler(Alluxio-Worker,HDFS-DataNode,CacheHandler),客户端节点用于部署CacheClient服务。分布式缓存框架实验环境配置如表3所示。

表3 分布式缓存框架实验环境配置
4.2 分布式缓存框架性能实验
分别对Alluxio原生的性能和TraceSet不同的分布策略下的性能进行对比,一个TraceSet总共包含1×104道(每道6000采样点)数据,分别测试了一次读取其中的500道(12MB)、1000道(23MB)、2000道(46MB)、4000道(92MB)的性能。
4.2.1 Alluxio原生性能对比实验
在Alluxio原生情况下,对比Alluxio-Worker节点本地读取和非本地读取两种方式的读取性能。读取方式如图10所示,其中,本地读取是指客户端与存放数据的Alluxio-Worker在同一节点,数据读取时直接在节点内部流动,省去了网络传输耗时;非本地读取是指客户端与存放数据的Alluxio-Worker不在同一节点,数据读取时在节点间流动,读取性能会受带宽和RPC(Remote Procedure Call)调用次数等因素影响。

图10 本地读取与非本地读取示意
图11展示了本地读取与非本地读取的性能对比结果,可以看出,在读取1个TraceSet时,本地读取的性能比非本地读取的性能好很多,甚至可以达到7倍的加速比,性能最优时可以在102ms内完成数据读取。但在实际集群的部署应用中,客户端和要读取的数据一般不会在同一节点,难以做到本地读取。在使用Alluxio原生的情况下,数据读取如图11中非本地读取所示,读取4000道数据需要1354ms,频繁交互时会有一定时间延迟。

图11 本地读取与非本地读取性能对比结果
4.2.2 并行强扩展性实验
将10个TraceSet分别放在一个节点和平均分布在3个节点来进行并行强扩展性的性能对比,结果如图12 所示,可以看出,在并发同时读取10个TraceSet的测试条件下,TraceSet分布在3个节点时,其性能比集中在一个节点上好,最快可以达到2.4倍的加速比,性能最优时可以在302ms内完成10个TraceSet的并发同时读取,可以满足交互式场景的性能需求。
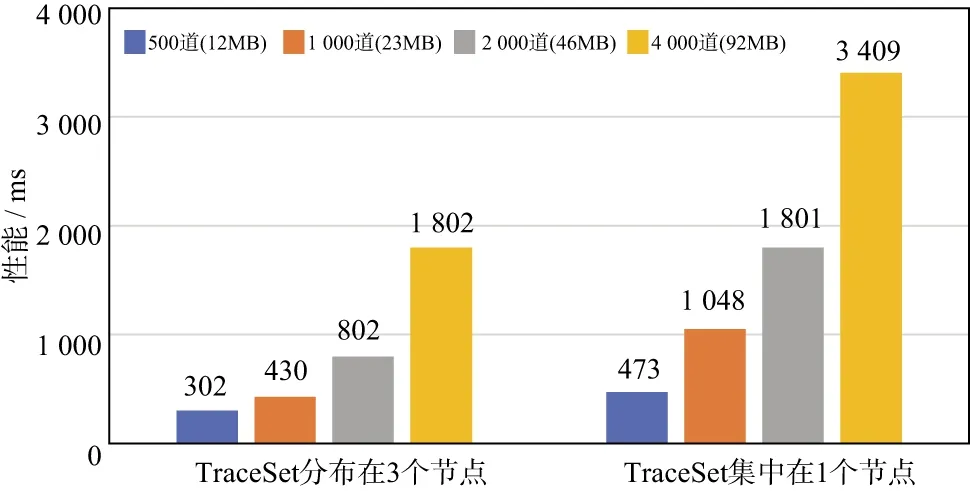
图12 并行强扩展性的性能
基于Alluxio的分布式缓存框架可以提供较好的访问速度,满足交互式操作的性能需求。此外,数据尽可能地均匀分布对读取性能有一定的提升,在数据规模不变的情况下,增加服务节点数可以提升读取性能。
4.2.3 并行弱扩展性实验
同时增大数据规模和服务节点数,考察数据的读取性能变化。我们测试了3个TraceSet在1个节点以及9个TraceSet分布在3个节点时的性能,结果如图13所示,可以看出,采用这2种方式读取同样大小的数据,性能变化不大,其中的差异主要是因为采用多个节点时需要将数据从多个节点传输到客户端,增加了一些网络传输消耗。可以得出结论:当数据规模随着服务节点数等比增大时,缓存框架的读取性能基本不变。
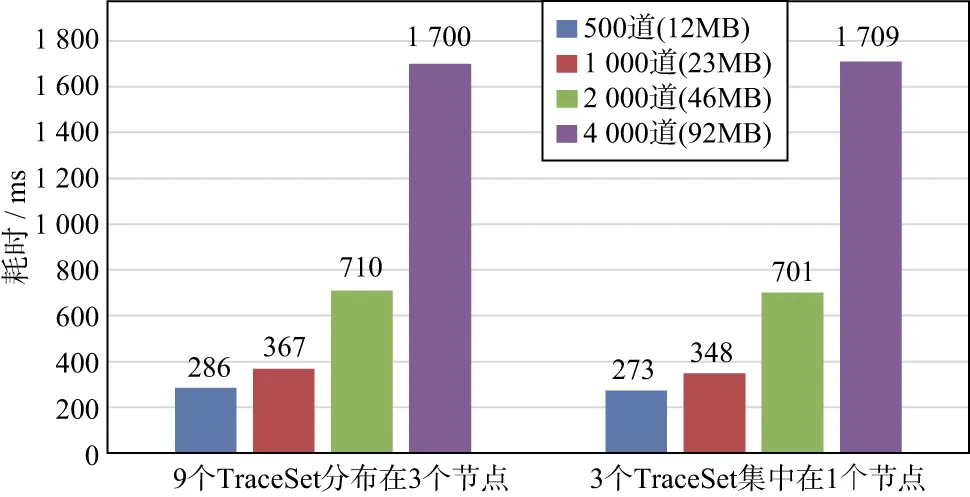
图13 并行弱扩展性的性能
4.3 正确性实验
采用分布式缓存框架和π-Frame平台改进前底层接口两种方式读取较大数据规模的TraceSet,读取的数据分别如图14a和图14b所示,可以看出,分布式缓存框架的数据读取是正确的。
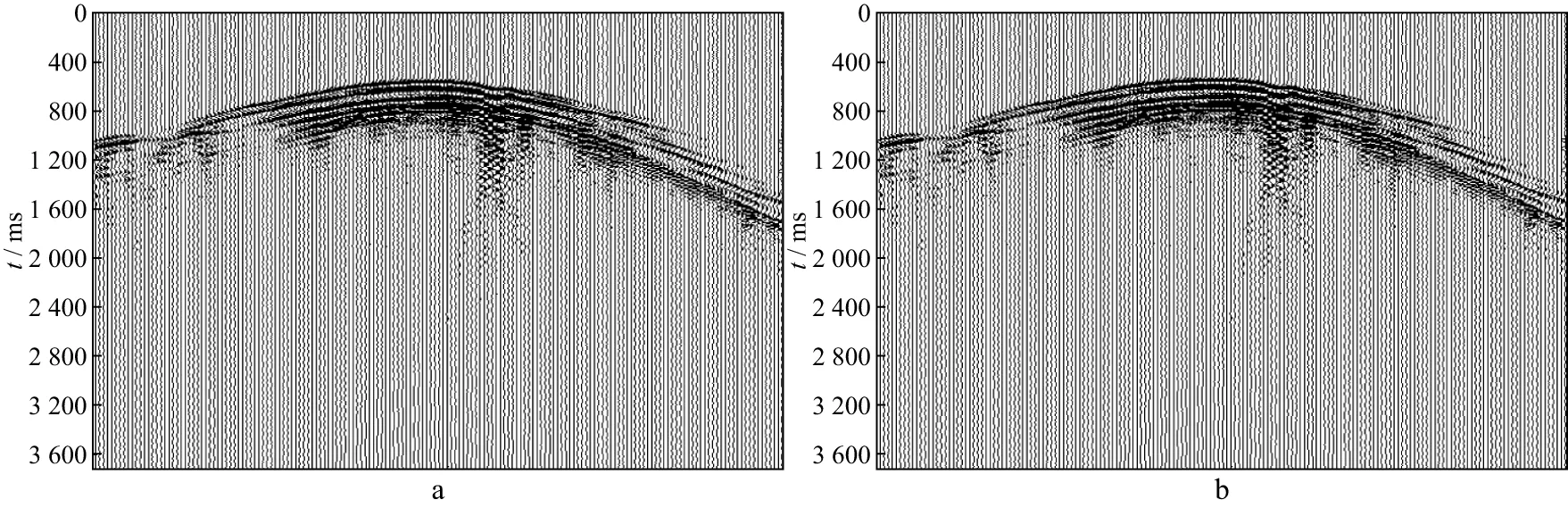
图14 两种方式读取大规模数据正确性对比(3360道×6000采样点)a 分布式缓存接口; b 平台底层接口
4.4 生产环境性能对比实验
在本缓存框架的设计中,将炮集、共中心点道集、共偏移距道集等统一抽象为二维的TraceSet进行管理,内存缓存框架在进行缓存时,不区分TraceSet的专业含义,缓存效率提升主要和TraceSet的大小有关。TraceSet包含的数据规模越大,则缓存后的数据访问性能提升越大。
在进行实际生产环境性能对比实验时,工区中存放的最大规模TraceSet为炮集,每个TraceSet总道数最多只有8067道,每道采样点为7001,8067道×7001采样点×4B=215MB。在4.2节分布式缓存框架性能实验中,使用的数据规模是每个TraceSet为10000道×6000采样点×4B=218MB,与上述215MB的TraceSet基本相同,所以可以认为使用该炮集数据进行实验,实验结果是可靠的。
4.4.1 读数据性能测试
测试不同数据规模TraceSet的读性能,测试数据分别为:16MB(2880道×1500采样点)、92MB(6912道×3501采样点)、215MB(8067道×7001采样点)。在保证了分布式缓存框架数据读取正确的前提下,测试结果如图15所示。

图15 分布式缓存的读性能
由图15可以看出,不同数据规模下,分布式缓存框架读取优于从平台IOService底层接口直接读取,且性能提升了至少30%。
4.4.2 写数据性能测试
测试不同数据规模TraceSet的写性能,测试数据分别为:91MB(4000道×6000采样点)、160MB(7000道×6000采样点)、228MB(10000道×6000采样点),测试结果如图16所示。

图16 分布式缓存的写性能
从图16可以看出,分布式缓存的写性能优于平台IOService原生接口的写性能,写大数据规模的TraceSet时有较好的性能提升,写小数据规模的TraceSet时性能在500 ms左右,能够满足交互式操作需求。
分布式缓存的使用对π-Frame平台现有架构的改动很少,而且可以快速灵活地部署。经过对比测试,分布式缓存的读写性能优于IOService,并且在一定的场景下能达到1倍的加速比,对提升交互式场景的响应效果较好。
在本缓存框架的设计中,外部访问需要炮集、共中心点道集、共偏移距道集等数据时,统一转换为对TraceSet的获取,系统立刻自动去服务后台查询,如果TraceSet已经在缓存中,立即从缓存中返回数据,如果TraceSet不在缓存中,则后台服务自动将其先加载到缓存中,再返回给外部。当缓存容量足够大时,通过加大预加载TraceSet数量,缓存直接获取率可以接近100%。
5 结论
分布式技术在地震数据处理计算方面已经取得很好的应用效果,但在地震软件系统交互方面的应用研究还处于探索阶段。本文针对大规模地震数据交互分析场景,引入分布式缓存技术,提出了一套针对地震数据交互的分布式缓存框架,提升了交互过程中的数据实时访问效率。通过实验分析对比,得出以下结论:
1) 该缓存框架可以有效提升交互场景下大规模地震数据的读写速度,满足交互分析应用的实时性能需求;
2) 该缓存框架利用分布式大内存优势,可以解决运行地震交互软件的机器内存有限,无法存放大规模、多种类地震数据的问题;
3) 通过地震一体化专业软件平台(π-Frame)验证了分布式缓存框架的可行性和有效性,认为在其它类似软件的大数据交互场景下,分布式缓存框架也可以高效地读取地震数据,在专业领域应用中具有一定的通用性。
本文设计的分布式缓存框架提供了一个高效的数据共享、交换机制。在交互应用之外,下一步研究方向是如何与地震数据批处理场景结合,在处理作业运行期间,通过分布式缓存技术在作业和质控界面间进行中间数据的共享交换,实现处理过程中间结果的实时质控分析。
