基于改进YOLOv3 融合特征的火焰目标检测方法
2022-12-01杨天宇王海瑞
杨天宇,王海瑞
(650000 云南省 昆明市 昆明理工大学 信息工程与自动化学院)
0 引言
火灾多发于森林、工业生产、居民住宅等场景。小的起火点如果未被及时发现便会发展为火灾,造成巨大的经济损失,威胁人们的生命财产安全。对于火灾防控,重要任务是及时发现、及时扑灭。基于这一目标,各种火焰检测系统相继诞生。
传统的火焰检测使用基于光学或温度传感器对火灾进行预警[1-2],此类方法稳定性较差,会出现误报情况,且应用场景有限。鉴于此,Lasaponara[3]等人提出了基于AVHRR(Advanced Very High Resolution Radiometer)的改进自适应火焰检测算法;Celik[4]等人提出了一种将目标前景信息与颜色像素统计相结合的实时火焰检测算法;Zhou[5]等人提出了一种基于火焰轮廓的火焰检测,根据检测到目标的轮廓面积、边缘、圆度3 个特征判断是否为火焰目标。由于火焰目标特征受颜色、轮廓变化及复杂场景影响较大,传统火焰目标检测易出现误检和对小尺寸目标的漏检问题。
现阶段对火焰目标的检测多被归为计算机视觉领域的目标检测任务。随着深度学习的发展,卷积神经网络被应用于目标检测任务,取得了极好的效果,也衍生出许多目标检测算法如YOLO[6]、Faster R-CNN[7]、SSD(Single Shot MultiBox Detector)[8]等。此类算法被应用于各类目标检测任务。卢鹏[9]等人使用MobileNet[10]替换SSD 的特征提取网络VGG16[11],使用深度可分离卷积构建复杂背景环境下的火焰目标检测模型,使得检测精度高于原SSD 模型;刘鸣瑄[12]等人基于SSD 网络模型通过残差模块设计了特征融合结构,使其对远距离车辆检测有更好的效果;侯易呈[13]等人使用ResNet50[14]作为Faster R-CNN 的特征提取网络,添 加SENet(Squeeze-and-Excitation Networks)模块[15],将多个尺度的特征融合,提高了模型的检测精度;曹红燕[16]等人在原YOLOv3[17]算法的基础上增加特征尺度,改进BN[18]层并与卷积神经网络层相融合,相比原算法取得了更高的检测精度。
本研究基于YOLOv3 算法,在损失函数、特征融合方面提出改进策略,加入通道注意力机制,使得改进后的算法更适用于火焰目标检测。
1 火焰目标检测方法
1.1 YOLOv3
YOLOv3 是Redmon 等人于2018 年提出的目标检测算法,是对YOLO 和YOLOv2 的改进,结构如图1 所示。
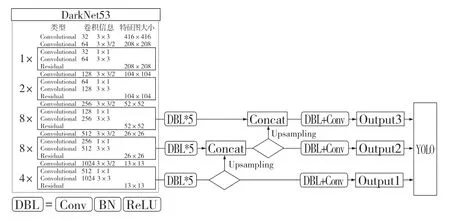
图1 YOLOv3 网络结构图Fig.1 Network structure of YOLOv3
使用DarkNet53 作为特征提取网络,借鉴了ResNet 的结构,在多个卷积层之间设置捷径层(shortcut),将之前层的输出和指定层的输出结合得到本层的输出,实现了残差网络结构,以此加深了网络层数。使用FPN(Feature Pyramid Networks)将特征提取网络3 个尺度13×13、26×26、52×52 的特征相融合,实现了多尺度特征的预测。之后将3 个尺度的特征输入YOLO 层,进行边界框(Bounding box)回归和目标类别的预测。YOLO 使用锚点框(Anchor box)预测边界框,锚点框是一组预先设定的超参数。由于YOLO 对3 个尺度的特征进行预测,因此分别为每个尺度特征设置3 个锚点框,通过特征图谱预测目标在原图像中的位置和目标的具体大小,锚点框与真实边界框的重叠区域大小使用交并比(Intersection over Union,IOU)判定。
2.2 损失函数
YOLOv3 的损失函数如式(1)所示,分为中心坐标定位损失、宽高损失、置信度损失、分类损失4 部分。

(1)lossxy指中心坐标的均方误差,如式(2)所示:
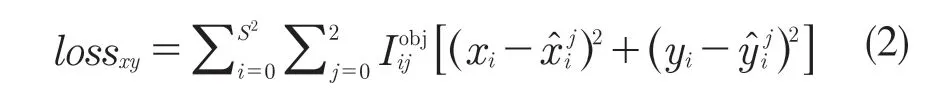
式中:xi,yi——真实目标框中心点的横纵坐标;,——预测目标框中心点的横纵坐标;S2——特征图谱的尺寸,即13×13、26×26、52×52;——预测第i 个特征图谱网格的第j 个锚点框是否预测到真实目标。
首先计算锚点框与真实边界框的交并比,计算方式如式(3)所示。
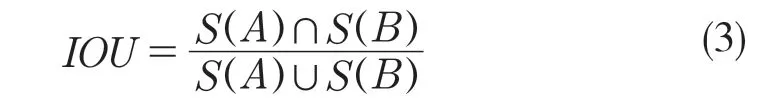
式中:S(A)——真实边界框区域的面积;S(B)——锚点框的面积;∩——交集;∪——并集。
因此IOU 的值就等于真实边界框与锚点框交集的面积与两者并集的面积之间的比值。预先设定一个IOU 阈值,通过计算每个网格的锚点框与真实边界框的IOU 值,若大于预先设定的阈值,则认为此锚点框可预测到真实目标,=1;若小于阈值则认为此锚点框为预测到真实目标,=0。


在原损失函数中,使用IOU 并预先设定阈值作为筛选锚点框的标准,舍弃低于此阈值的锚点框,对满足条件的锚点框使用lossxy与losswh进行损失回归。IOU 只考虑了两框的重叠面积,而没有考虑到两框的重合情况,且忽略了两框没有重叠的情况,使得部分锚点框没有被用于损失回归,造成漏检的问题。
基于以上损失函数,使用lossdiou[19]替换其中的定位损失lossxy和宽高损失losswh。lossdiou的计算方式如式(7)所示。
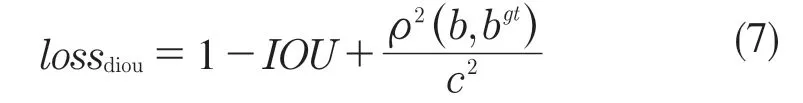
式中:b,bgt——真实边界框和锚点框的中心点;ρ2——计算2 个中心点欧氏距离的平方;c——能够同时包围真实边界框和锚点框的最小矩形的对角线距离。具体展示如图2 所示。
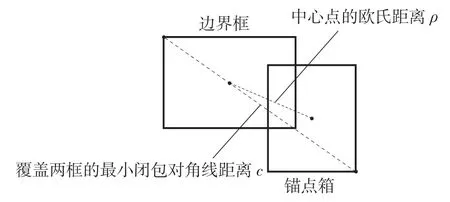
图2 DIOU 损失函数示意图Fig.2 Diagrammatic sketch of DIOU loss function
由于lossdiou直接对锚点框与真实边界框的直接距离进行损失回归,收敛速度要比lossxy+losswh更快,既作为锚点框的筛选标准使得获得的锚点框更合理有效,同时又可对满足条件的锚点框进行优化使其能够预测真实边界框。它将两框之间的距离、重叠情况和尺度都考虑进去,使得损失回归更稳定。
2.3 空洞卷积融合模块
随着特征提取网络深度加深,可以获得图像更深层次的语义特征。浅层次的特征包含了更多的细节信息,深层次的特征包含更丰富的语义信息。浅层次的特征和深层次的特征都是后续目标分类和目标位置回归的基础。因此,YOLOv3 选用特征提取网络获得的3 个不同深度的特征图谱,分别为52×52×256、26×26×512、13×13×1 024。通过特征金字塔网络FPN 以自底向上的顺序将深层次特征上采样与浅层次特征融合,实现了多尺度特征融合。多尺度特征融合对目标检测效果有着显著的提升,但由于经过一定深度卷积和下采样的深层特征丢失了图片的细节信息,因此对小尺寸目标的检测具有一定的影响。本文基于空洞卷积提出空洞卷积融合模块,使用不同膨胀率的卷积核对融合后的特征进一步特征提取。空洞卷积通过在卷积核添加0 权重,在不增加额外参数的情况下,扩大了卷积的感受野,提升了空间分辨率。空洞卷积融合模块的结构如图3 所示。
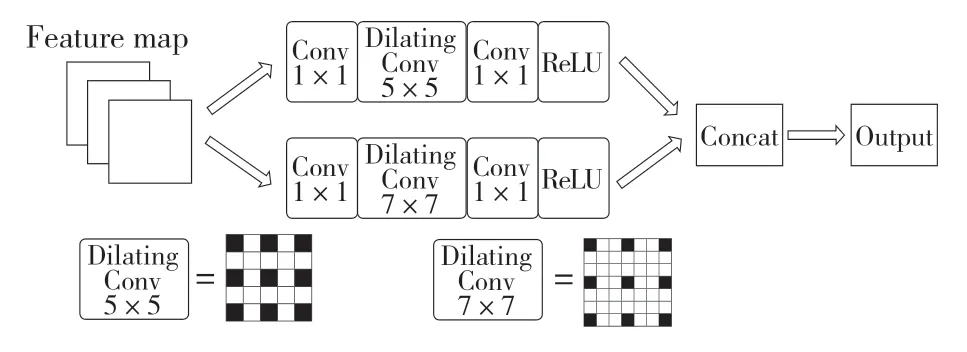
图3 空洞卷积融合模块Fig.3 Dilated convolution fusion module
首先使用大小为3×3、步长为1、膨胀率为2的空洞卷积核、2 个1×1 卷积核和ReLU 激活函数,构成第1 个卷积层作为其中一个分支,这一层拥有5×5 的感受野。第2 个卷积层由大小为3×3、步长为1、膨胀率为3 的空洞卷积核、2 个1×1 卷积核和ReLU 激活函数组成,这一层拥有7×7 的感受野。将特征金字塔获取到的3 个尺寸的特征分别输入2 个空洞卷积分支,将输出特征以矩阵拼接的方式得到最终输出。
2.4 通道注意力机制模块
注意力机制一般分为通道注意力、空间注意力和通道空间混合注意力,其中通道注意力机制将特征图谱逐通道调整其权重,使其自适应地增强包含重要信息的通道权重,抑制无关信息的通道权重,从而避免特征中的干扰信息对目标检测的影响。由于此前的输出特征经过特征金字塔网络多尺度特征融合和空洞卷积模块的特征融合,产生大量的冗余信息,因此引入通道注意力机制,具体结构如图4所示。
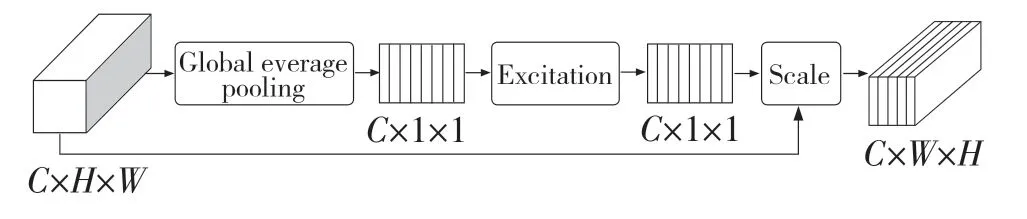
图4 通道注意力机制模块Fig.4 SENet module
图4 中特征图谱的尺寸为H×W,通道数为C。进入此模块的特征图通过全局平均池化(Global average pooling)使得每一个通道得到一个标量,后经过激活层(Excitation)使用sigmoid 激活函数将此标量的范围控制在0 到1 之间,作为每个通道的权重,将原特征图谱与权重进行Scale 操作,即将对应通道的每个元素与权重相乘,得到加权特征。通过调整权重使得特征图更关注重要的信息,从而减少信息冗余,进一步加强有效特征。
3 实验与结果分析
3.1 实验数据
现有的经过标注的火焰目标数据集较少,本实验选择公开数据集BoWFire 和从互联网搜集的包含有火焰目标的1 814 张图片构成,使用labelImg 工具对图片中的火焰目标标注。从而获取到由2 040张图片构成的实验数据集,按91 的比例随机分为训练集和验证集。部分数据集如图5 所示。

图5 数据集部分数据Fig.5 Parts of datasets
实验引入ImageNet 数据集训练好的DarkNet53权重参数,通过迁移学习调整新模型的参数,使其更快收敛。学习率初始设定为0.001,学习率策略选用余弦退火方式,batchsize 设为4,如图6 所示。经过50 个epoch 损失趋于稳定。

图6 模型训练过程Fig.6 Process of model training
3.2 实验评价指标
深度学习模型的评价指标一般使用精确率(Precision)和召回率(Recall),其中精确率用于评估预测结果中对正样本预测正确的情况,计算公式如式(8)。召回率用于评估预测的正样本在所有正样本中所占的比率,计算公式如式(9)。
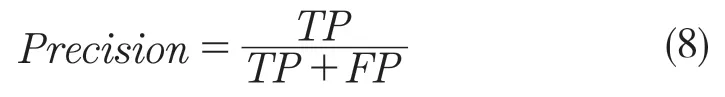
式中:TP——真阳率,即将正样本预测为正的个数;FP——假阳率,即将负样本预测为正的个数。

式中:FN——假阴率,既将正样本预测为负的个数。
目标检测任务基于以上精确率和召回率引入平均精度均值mAP(mean Average Precision)作为评估模型性能的指标,计算公式如式(10)。
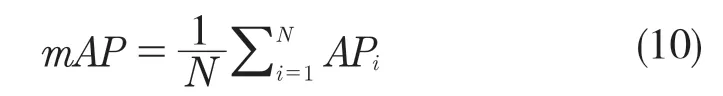
式中:APi——以精确率和召回率为横纵坐标的PR曲线与坐标轴区域的面积;N——目标类别数。因此mAP 即为取每个类AP 值的平均值。
本实验采用mAP 值作为模型检测精度的衡量标准,值越高则模型检测精度越高。采用每秒传输帧数FPS 作为衡量模型检测速度的标准,值越高则模型检测速度越快。
3.3 实验环境与实验结果
本实验所使用的实验环境配置为Windows10操作系统、16 GB内存、RTX2060GPU 和AMD Ryzen7 CPU;软件平台包括深度学习框架Pytorch1.7.0 和Python3.8。
实验通过以上环境使用同一组数据集对YOLOv3、Faster R-CNN、以VGG16 为特征提取网络的SSD、以MobileNet 为特征提取网络的SSD 和本文算法相对照。实验结果如表1 所示。
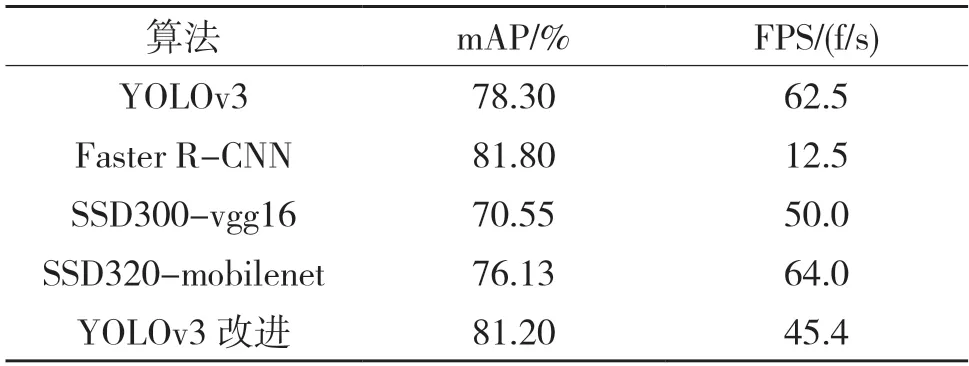
表1 模型效果对比Tab.1 Comparison of model performance
实验结果表明,改进后的模型整体检测精度达到了81.2%mAP,相比原YOLOv3 模型提升了2.9%。与两种SSD 模型相比,在检测精度上分别提升了10.65%和5.07%。与Faster R-CNN 模型检测精度相差0.6%,检测速度达到了45.4 f/s,相比Faster R-CNN 提升了32.9 f/s。使用训练好的模型对测试集进行测试标注,部分结果如图7 所示。

图7 测试结果Fig.7 Experimental results
图7(a)是YOLOv3 模型的检测结果,图7(b)为本文改进模型的检测结果。实例中YOLOv3 模型对图片中的小尺寸目标存在漏检的情况,而改进后的模型成功检测到了小尺寸的火焰目标。通过以上测试实例的对比,可以证明改进模型对小目标的检测有更优秀的效果,更适合于火焰目标检测任务。
4 结语
本文基于YOLOv3 算法提出改进策略并将其应用于火焰目标检测任务,实现了对火焰目标检测效果的提升以及对小目标检测的适用性。通过实验分析证明改进模型在目标检测精度和检测速度上都有优秀的表现。
实验存在的不足之处为所用数据集较小,后续工作将会继续扩充数据集,以及获取不同背景条件下火焰目标图片。通过图像增强方法降低复杂背景条件对检测任务的影响。使得模型能够适应不同的应用场景,提升模型的泛用性。
