基于几何特征枝干点云骨架提取最短路径算法
2022-11-29温小荣汪求来叶金盛
杨 杰,温小荣*,汪求来,叶金盛
(1.南京林业大学 南方现代林业协同创新中心,江苏 南京 210037;2.南京林业大学 林学院,江苏 南京 210037;3.广东省林业调查规划院,广东 广州 510520)
经过近50 a的研究,树木建模已广泛应用于多个领域的活动中,如电脑游戏和林业信息化。不断地提高树木建模的精度,可以增加游戏场景的沉浸感;同时,又极大地促进林业信息化,实现精准林业[1-2]。激光雷达技术(light detection and ranging,LiDAR)正逐步成为林业调查的重要手段,其扫描得到的点云数据具有精度高、时效性好等特点,因而成为林业信息化中的研究热点[3-4]。点云数据可把现实世界原子化,是将现实世界中以大量且密集的点的形式将被测量区域内物体的表面表达出来,因此通过高精度的点云亦可以还原现实世界,通过研究某一研究目标在点云中的信息来反演其现实世界的信息[5],利用点云数据进行树木建模的意义也正是如此。通过点云数据进行测量与传统的人工测量相比,生物量、产量、叶面积指数等相关参数获得的更加准确[6]。基于点云、基于图像、基于规则或过程和基于草图共同构成现在树木建模的4大主要方法。
单木建模由枝干建模和叶片建模两部分构成,其中,枝干模型表达的一种方法是骨架,此外比较常见的方法还有Delaunay三角网等。石银涛[7]指出,现有的研究中点云树木枝干模型骨架的提取算法主要基于3类——体素空间(voxel space,VS)、点云收缩(point clouds contract,PCC)、几何特征(geometrical characteristic,GC),其中,GC算法仅在运算效率中未达到最优,次于PCC算法,而在此外的各个方面均达到最优或并列最优,包括处理细小枝、模型拓扑、整体效果、处理邻近分支和中心偏差。以牺牲较小的时间代价换取更高的建模精度满足大部分研究者的研究需求,以中国知网为例,搜索关键词“点云树木建模”,最早一篇发表于2011年12月1日,截至2021年10月24日共计40篇文章中,排除4篇文献综述、未直接指明骨架提取方法(包括直接使用三维建模软件的3篇)、非骨架提取(17篇)的文献以外,剩余16篇中,有2篇是VS算法,1篇是PCC算法,其余共13篇均为GC算法,可见其研究与应用之多。
GC算法的思路是将枝干点云按照一定规则分成若干bins,再将每个bins通过聚类拆分成1个或多个bin,对每一个bin求出中心点,按照真实关系将点连接即可得到枝干点云[8],bin有文献译作枝干段,但bins却无对应的翻译,根据实际意义可解释为“枝干段集”,bins、bin与最后建立的骨架的示意图如图1(a)-图1(c)所示。
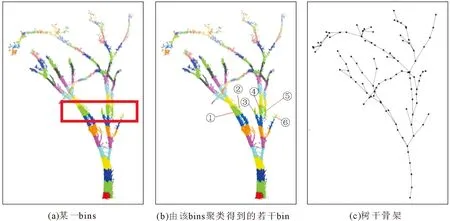
图1 bins、bin和枝干骨架
目前GC算法采用的规则分为2种:以根节点距离相似归类和以高度归类。生态学研究表明,树木在水分养分的传输中趋向使用最短路径来达到资源配置的最优化[9-10],而以根节点距离相似归类的思想正是量化各点与根节点的最短路径长度按距离“相似”地划分成各个区域,以此作为bins。其中,根节点是指经过校正后的枝干点云中z轴高度最低的点,它代表在地面之上树根的位置;相似指的是按照距离的大小进行分组。而以高度归类是直接以根节点和树冠最高点的高度差直接分段。记N为bins分成的数量,分别取N=20、50、100比较2种规则分段后的结果以及N=100时得到的骨架,如图2所示。
由图2可以看出,以根节点距离相似归类区别于以高度归类之处在于以根节点距离相似归类得到的bins以根节点向外呈现辐射状;当N增大时,根处的bins的形状呈现单侧塌陷,并在N充分大时直观上不闭合,这将会导致根节点明显偏移树木根部中心位置,产生这一问题原因是点云获得的是树木表面的信息,因此根节点在树木表面上,并非树根处的中心位置,现已有研究对这一问题进行了改进[11],然而目前很多使用了以根节点距离相似归类方法的文献未注意到这一问题,未改进时在根节点处存在明显的劣势,但以N=100时的2种规则建立出来的骨架进行对比,可见其在枝条分叉处的处理更加合理,分叉处得到的骨架中心点更靠近枝条真实的中心位置,有利于后续骨架的优化。
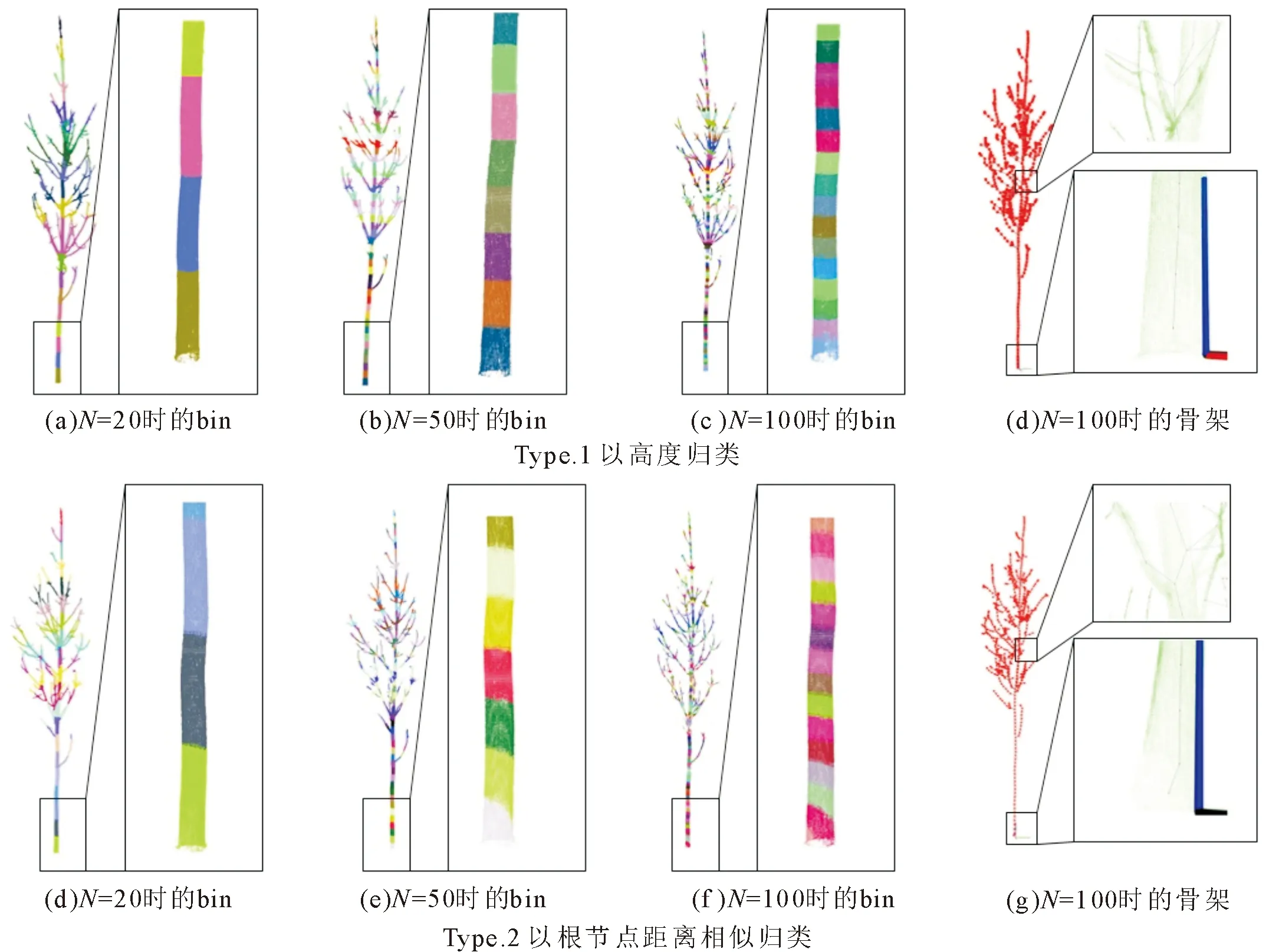
图2 2种规则的bins效果及骨架建立效果
现有的大多数文章虽然介绍了以根节点距离相似归类并提及了Dijkstra算法求解最短路径,但通过前面介绍的2种规则得到的bin的差异,可以判断出其中由很多文献仍然使用的是以高度归类的规则来建立骨架,一方面可能是由于采用了不合适的数据结构,另一方面是Dijkstra算法本身计算复杂度高,因而在处理海量点云时执行速度较慢。
本研究主要针对基于几何特征的树木枝干点云骨架提取时,考虑到枝干点云数据量大,讨论了图的表达方式,对经典的最短路径算法及其改进的适用性进行了讨论,并对适用的最短路径的算法各自作一定的改进以适用于枝干点云且满足内存节省与快速处理的需求。试验使用C++编程实现,以真实树木点云比较若干算法的实际效果。
1 相关研究
图G=(V,E)的典型表示方法包括邻接矩阵与邻接表2种方法[12-13],性能复杂度如表1所示。

表1 性能复杂度对比
对于枝干点云,若点数非常大,采用邻接矩阵会对内存的需求非常大,以本研究将使用的杨树的点云为例,枝叶分离后得到的枝干点云点数为|V|=198 500(后文使用|P|),邻接矩阵所需的理论内存为198 5002×sizeof(double)≈293.57 GB,这远远超过了一般设备的承受范围,而且由于并不是任意两点均可达,事实上每一个点只和本身附近很小范围内的点可达,因而该矩阵中很多元素都是∞,占用了过多不必要的空间。
求解图的最短路径问题的常用算法包括Floyd算法、Dijkstra算法和Bellman-Ford算法。由于Floyd算法中需要存储最短距离矩阵所需空间为T(|V|2),因而不适用于海量点云,不再进一步讨论。另外2种算法适用于海量点云,但仍有一定的改进空间,对于Dijkstra算法,用堆进行优化;对于Bellman-Ford算法,用队列进行优化得到SPFA算法,而SPFA算法可进一步优化,可采用3种策略,包括Small Label First(SLF)、Large Label Last(LLL)、SLF与LLL结合(SLF+LLL)[14],若干算法的时间复杂度如表2所示。

表2 最短路径算法时间复杂度对比
由于从LiDAR设备获取的枝干点云是以无序点云的形式保存的,点云中的点的序号并不能反映出一定的规律。由枝干点云建立的边是每一个点与其附近一定范围内的点的直线距离,并不是负数,因而不存在负权边。这些算法现有的实现中所使用的邻接表并不全都满足可处理无向图,无须考虑负权边或尽可能节省内存使用,即仍然使用邻接矩阵实现,或应用于点云时算法有不必要的判断增加了时间消耗,或采用的邻接表存放的数据结构不够精练,因而在获取枝干点云的最短路径方面,若干算法需要进一步地改进。
2 方法
2.1 初始化阶段
首先,对获得的树木点云枝叶分离,利用kd-tree以半径R进行最近邻检索,得到枝干点云,半径的选取应当以保证枝干上的每个点都应当至少有一个邻近点且足够小为宜。其次,使用kd-tree以半径为r进行最邻近检索以获取图,其中,务必保证r≥R,且考虑到枝干点云中每个点只能和附近一定范围内的点可达,因而r不宜太大。表3给出使用的符号及其含义,获取边和参数初始化的算法如算法1所示。

表3 符号及其含义
算法1 邻接表的建立及参数初始化
Algorithm 1 Establishment of adjacency table and parameter initialization
E.resize(|P|)
D.resize(|P|)
F.resize(|P|)
kdtree.init()
kdtree.setInputCloud(P);
fori:=1→|P| do
Si(r):=kdtree.radiusSearch(Pi,r)
foreach 序号j∈Si(r) do
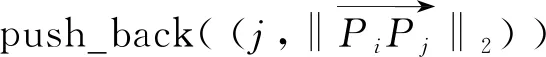
end for
ifi≠xthen
Di:=+inf
Fi:=NULL
else
Di:=0
Fi:=i
end if
end for
2.2 适用于枝干点云的最短路径算法
2.2.1 Dijkstra算法 Dijkstra算法基于广度优先搜索思想,从选定的源节点开始,跟踪每个节点到源节点当前已知的最短路径距离,如果发现比当前更短的路径,则更新最短路径距离值。一旦找到源节点和某一节点间的最短路径,就标记该节点为“已访问”,并在路径表中添加到该节点的最新路径。持续该过程直至所有节点都在路径表中有路径,此时的路径表中每一条路径遵循了源节点可能到达的每个节点的最短路径。
实际对路径的存储时,只需存放与每一节点相连接的那一段路即可。一方面,由前述的r≥R保证,图势必是连通的,通过逆向查找就可以回溯得到完整路径;另一方面,能够节省空间并提升算法的执行速度。
算法2 适用于枝干点云的Dijkstra算法
Algorithm 2 Dijkstra’s algorithm for branch point cloud
初始化标记序列B,其中Bi:=false,i=1,2,…,|P|
fori:=1→|P| do
v:=NULL
forj:=1→|P| do
ifBj=false and (v=NULL orDv>Dj) then
v←j
end if
end for
ifv=NULL then
break
end if
Bv←true
foreach 元组e∈Evdo
w:=e[0]
d:=e[1]
ifBw=false andDw>Dv+dthen
Dw←Dv+d
Fw←v
end if
end for
end for
2.2.2 堆优化的Dijkstra算法 Dijkstra算法的一个缺点是遍历计算的节点很多,因而效率低,尤其在面对节点多或者边多的大图的处理时。堆(heap)优化是利用1个每次弹出其中最小元素的优先队列(priority queue)来代替最近距离的找查,堆优化的Dijkstra可以大幅节约时间开销。
算法3 适用于枝干点云的堆优化的Dijkstra算法
Algorithm 3 Dijkstra’s Algorithm implemented with a Min-Heap for branch point cloud
初始化优先队列Q,比较方式为升序
Q.push ((x,0))
whileQ不为空 do
q:=Q.top()
Q.pop()
v:=q[0]
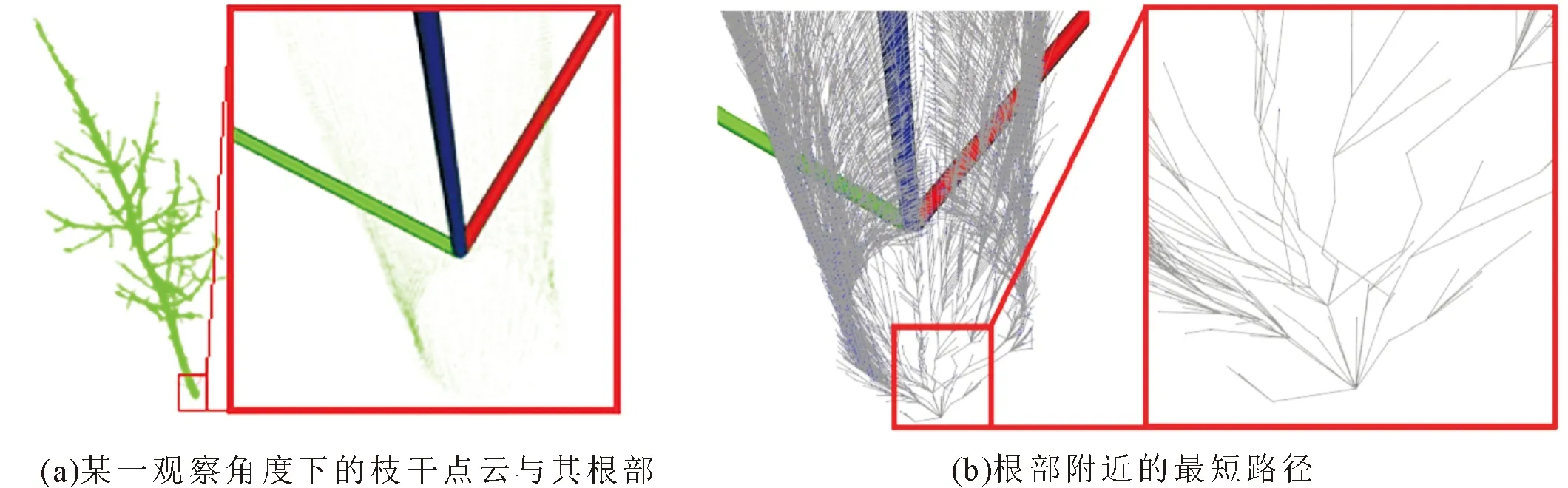
ifDv continue end if foreach 元组e∈Evdo w:=e[0] d:=e[1] ifDw>Dv+dthen Dw←Dv+d Fw←v Q.push((w,Dw)) end if end for end while 2.2.3 Bellman-Ford算法 Bellman-Ford算法(或称Bellman-Ford-Moore算法、距离向量算法)通过简单地对所有边松弛,以自下而上的方式搜寻最短路径。首先寻找路径中只有1条边的距离,之后增加路径长度以找到所有可能的解决方案。 算法4 适用于枝干点云的Bellman-Ford算法 Algorithm 4 Bellman-Ford algorithm for branch point cloud while true do b:=false fori:=1→|P| do foreach 元组e∈Eido w:=e[0] d:=e[1] ifDi≠+inf andDw>Di+dthen Dw←Di+d Fw←i end if end for end for end while 2.2.4 SPFA算法 SPFA(shortest path faster algorithm)算法采用对1个队列进行维护以使在1个节点当前的最短路径更新后无须立即更新其他节点,大大减少了重复的操作次数。但是在最坏情况下,每一个节点都入队|V|-1次,此时也就退化成了Bellman-Ford算法[15-16]。 算法5 适用于枝干点云的SPFA算法 Algorithm 5 SPFA for branch point cloud 初始化标记序列B,其中Bi:=false,i=1,2,…,|P| Bx←true 初始化队列Q′ Q′.push(x) whileQ′不为空 do v:=Q′.front() Q′.pop() foreach 元组e∈Evdo w:=e[0] d:=e[1] ifDw>Dv+dthen Dw←Dv+d Fw←v ifBw=false then Q′.push(w) Bw←true end if end if end for end while 2.2.5 SPFA算法的3种优化 SLF策略即把较小的元素提前,利用双端队列,如果新入队的元素比队首的元素更小,则加入到队首,否则排到队尾。 LLL策略则通过比较队列中元素的最短路径距离的平均值和待压入队列的元素的当前最短路径长度,如果大于平均值,则压入队尾。 SLF与LLL策略并不冲突,因而又可以同时被采用。在某些图求解最短路径的问题上,SPFA算法的SLF优化比SPFA算法快10%~20%,而SPFA算法的SLF+LLL优化甚至能比SPFA算法快近50%。 算法6 适用于枝干点云的SPFA算法的SLF优化 Algorithm 6 The SLF algorithm for branch point cloud 初始化标记序列B,其中Bi:=false,i=1,2,…,|P| Bx←true 初始化双端队列Q″ Q″.push_back(x) whileQ″不为空 do v:=Q″.front() Q″.pop_front() Bv←false foreach元组e∈Evdo w:=e[0] d:=e[1] ifDw>Dv+dthen Dw←Dv+d Fw←v ifBw=false then Bw←true ifQ″不为空 andDw Q″.push_front(w) else Q″.push_back(w) end if end if end if end for end while 算法7 适用于枝干点云的SPFA算法的LLL优化 Algorithm 7 The LLL algorithm for branch point cloud 初始化标记序列B,其中Bi:=false,i=1,2,…,|P| Bx:=true 初始化队列Q′ Q′.push(x) dQ′:=0 %队列中所有序号的最短路径距离总和 nQ′:=1 %队列中序号个数 whileQ′不为空 do v:=Q′.front() whileDv·nQ′>dQ′do Q′.pop() Q′.push(v) v←Q′.front() end while Q′.pop() nQ′←nQ′-1 dQ′←dQ′-Dv Bv←true foreach元组e∈Evdo w:=e[0] d:=e[1] ifDw>Dv+dthen Dw←Dv+d Fw←v ifBw=false then Q′.push(w) nQ′←nQ′+1 dQ′←dQ′+Dw Bw←true end if end if end for end while 算法8 适用于枝干点云的SPFA算法的SLF+LLL优化 Algorithm 8 The (combined) SLF/LLL algorithm for branch point cloud 初始化标记序列B,其中Bi:=false,i=1,2,…,|P| Bx:=true 初始化双端队列Q″ Q″.push_back(x) dQ′:=0 %队列中所有序号的最短路径距离总和 nQ′:=1 %队列中序号个数 whileQ″不为空 do v:=Q″.front() Q″.pop_front() ifDv·nQ′>dQ′do Q″.push(v) continue end if nQ′←nQ′-1 dQ′←dQ′-Dv Bv←true foreach元组e∈Evdo w:=e[0] d:=e[1] ifDw>Dv+dthen Dw←Dv+d Fw←v ifBw=false then ifQ″不为空 andDw Q″.push_front(w) else Q″.push_back(w) end if nQ′←nQ′+1 dQ′←dQ′+Dw Bw←true end if end if end for end while 本试验使用的树木位于江苏省宿迁市泗洪县陈圩林场马浪湖分场(33°15′N,118°18′E),树种均为美洲黑杨(Populusdeltoides)中南林797杨,使用RIEGL VZ-400i地基激光雷达扫描仪对树木所在样地进行多站扫描[17],扫描模式设置为Panorama40,详细参数如表4所示。 表4 RIEGL VZ-400i扫描模式Panorama40 将项目文件从设备导出,使用RiSCAN Pro 2.7多站拼接后导出为las文件格式,然后在LiDAR360软件中去噪、去除地面点、根据地面点归一化后导出las文件,导入到Cloud Compare中先切成单排点云后再进行单木分割并将每木点云导出成pcd文件格式得到了本试验所用的树木点云,最后,在Visual Studio 2019+PCL 1.11.0内去除重复点,将单木点云进行适当变换使树干点云的根部切面与平面xOy尽可能重合,所有点均在平面xOy上或上方,并使根部中心尽可能靠近原点(0,0,0)处,以此作为试验数据,如图3所示。 图3 试验数据 试验环境如表5所示。 表5 试验环境 对试验所用的树木点云以参数R=0.05枝叶分离得到枝干点云,此时的枝干点云点数|P|=198,500,按照算法1以参数x=0构建邻接表和初始化需要的参数。比较枝干点云获取最短路径长度进行优化的若干算法的实际运行时长。以r=R,r=2R,r=3R并各自进行10次试验测试,结果如表6所示。 表6 若干算法的执行时间 由表6可知,采用邻接表所使用的内存远远小于邻接矩阵所需要的。同样是邻接表来表示图,传统使用的Dijkstra算法速度远远慢于其他所有算法,而SPFA及其优化相比之下更快。在求解枝干点云的最短路径问题上,SPFA的3种优化并不如在某些图的求解上非常显著且稳定地比SPFA更快,因此,在枝干点云获取最短路径长度方面,选用适配后的SPFA算法是理想方案,对SPFA的3种改进则不一定需要。图4是建立的最短路径的在根部附近的展示,为了便于展示,调整了枝干点云的观察角度。 图4 根部附近的最短路径 本研究简要介绍了树木建模中利用点云以及基于几何特征的枝干点云的骨架提取的意义,对比了以根节点距离相似归类和以高度归类2种规则的优劣,前者在树干分叉处鲁棒性较好,但现有研究中大多采用的Dijkstra算法处理枝干点云的速度较慢,抑或采用了不合适的表达图的数据结构因而实际使用的较少。针对这一现象,本研究首先采用了邻接表的形式作为图的数据结构的表达,并将现有的若干求解最短路径的算法进行改进以应用于枝干点云,结果表明,采用枝干点云的SPFA算法是理想方案,大大减少了执行时间。本研究能够为精细化点云树木建模提供一定帮助。3 试验验证
3.1 数据来源与预处理


3.2 试验环境

3.3 结果与分析

4 结论
