基于Hadoop的果园农情信息大数据平台 设计*
2022-11-28陈娟刘伟康尧港东
文/陈娟 刘伟康 尧港东
0 引言
随着信息化技术的发展以及传感器技术 的进步,信息化技术在农业中的应用越来越广泛,国内越来越多的果园正在使用基于农业信息化技术构建农情信息采集系统、灌溉控制系统等,数字果园技术取得了巨大的进展,久而久之,这些系统上储存的数据量也将越来越大,超出了单台机器能够存储和处理的能力,因此,如何高效存储和管理这些数据成为了当前农情信息数据存 储研究的核心问题。
果园农情信息中存在海量小文件,包括图片、视频及传感器文本等格式。随着智慧农业的发展,小文件存储逐渐成为农情信息存储的主要方式,小文件数量的累计以及目前的存储方式大多存在容灾性能差、数据读取写入缓慢等问题,难以支持大数据的海量写入与读取。
基于上述现状,本文通过分析试验提出一种基于Hadoop的果园农情信息大数据平台,以期解决三方面问题:一是利用Hadoop生态系统中的高可用机制解决传统数据存储系统容灾性能差的问题;二是采用MySQL+HBase的混合存储方式解决系统数据读取写入缓慢的问题;三是设计基于贪心算法的 多级处理框架解决系统小文件存储的问题。
1 材料与方法
1.1 试验材料
设置果园农情信息大数据平台系统(以下简称“系统”)的硬件环境为3台虚拟机的Hadoop集群,采用该集群进行分析试验。其中,1台作为主节点、2台为从节点,每个节点分配2GB内存,硬盘40G,搭载64位的Centos7操作系统,Hadoop版本为Hadoop2.6.0,HBase版本为HBase1.1.12。
1.2 系统设计
1.2.1 总体结构设计
基于Hadoop的果园农情信息大数据平台可用于管理多个果园,使用无线传感器网络、大数据等技术构建。从果园农情信息数据的特征出发,结合Hadoop生态系统,考虑系统的高容灾性、高效读写、小文件处理等因素,自上而下将系统分为应用层、服务层以及存储层。系统总体架构如图1所示。
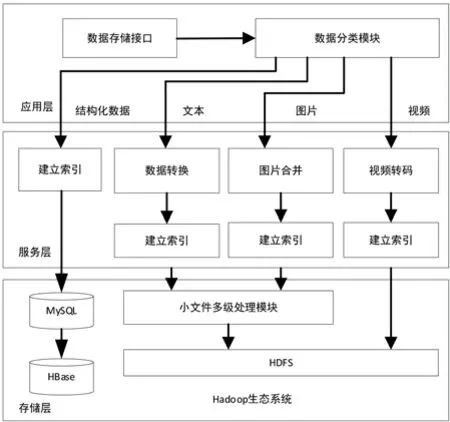
图1 系统总体架构
1.2.2 系统功能设计
系统功能可根据需求而不同,以试验中所涉及的果园为例,系统主要功能包括实时信息、历史信息、设备状态、统计分析、环境警报、系统管理(见图2)。
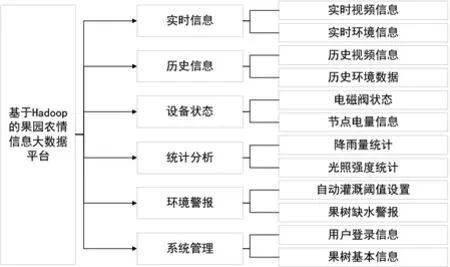
图2 系统功能模块
其中,实时信息模块主要负责展示果园内土壤的温湿度、光照强度以及现场视频等实时信息;历 史信息模块主要用于存储果园中历史数据,如历史环境数据及历史图像采集数据;设备状态信息主要包括果园中各个电磁阀状态信息以及各个节点的电池电量信息,可以方便地查看果园中各个采集节点的在线状态;统计分析模块主要负责对采集到的环境数据进行分析,允许用户进行多点查询以及多日查询,而且数据可通过曲线图表进行个性化展示,使得果农可以直观地了解果园的环境变化趋势,一定程度上为果农管理果园提供了便捷;环境警报模块主要负责监控果园环境是否出现异常情况,当某项环境数据不在预设好的阈值空间时,该模块将直接通过手机APP推送报警信息;系统管理模块主要负责设计用户的登录信息以及果园的基本信息,用户的登录信息包括用户账号密码的存储设计以及新增用户的功能设计,果园基本信息主要负责描述果树的基本信息。
1.3 关键技术设计
1.3.1 基于MySQL+HBase的混合存储方式设计
系统采取双数据库互补的存储方式存储结构化的数据。其中,MySQL数据库负责存储短期内的数据;HBase数据库负责存储采集的所有数据。将实时数据同时存储在MySQL和HBase,近期数据存储在MySQL数据库中,并提供实时的访问接口;当MySQL数据库中的数据超过一定的阈值时,对数据进行更新。
1.3.2 MySQL数据库存储表设计
为方便环境数据的查询及存储,同时考虑到果农对于环境数据的查询多为根据具体采集点及采集时间进行单项或多项参数值的范围查询,因此根据需求,在MySQL数据库中设计并实现二维数据表如表1所示。具体需要采集的环境数据包括网关号、节点号、节点经纬度坐标、采集时间及各种环境参数值。
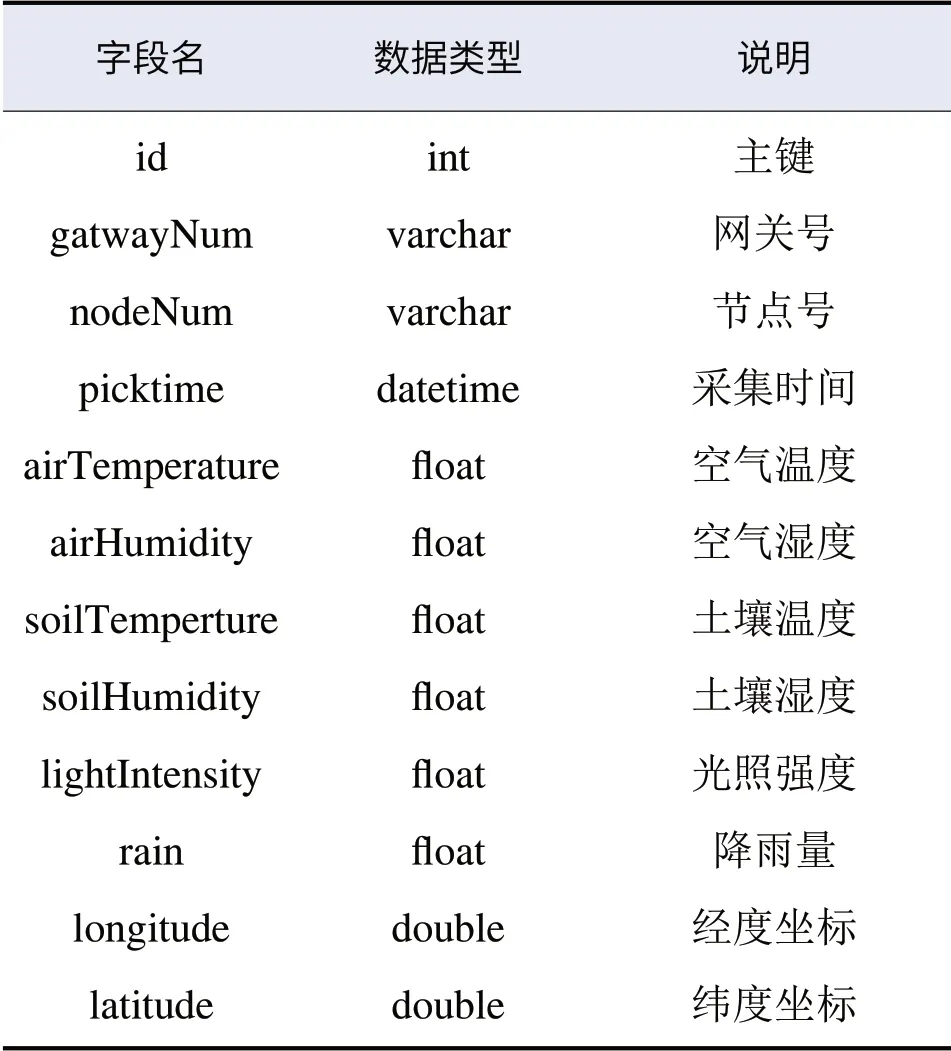
表1 NySQL环境监测数据存储表
1.3.3 HBase数据库存储表设计
HBase数据库存储表的设计主要分为行键(RowKey)的设计以及列族的设计。RowKey的设计是指HBase中的存储表位于Region块中,Region的范围由StartKey和EndKey确定,当一个Region中的空间存储不了整个表时,会自动进行分裂产生下一个Region块,但是每个自动分裂会消耗很多时间,所以需要对存储表进行预分区,规划好多个Region块给用来存储一个表的数据。预分区后的Region块中没有EndKey,数据会根据HBase中RowKey的位置插入不同的Region。但是,RowKey的默认设计是按照字典顺序进行递增,Flume监听的数据会不断地插入Region中,造成写热点问题。为了解决这个问题,本文所用RowKey格式为“果园ID+网关号+节点号+采集时间”,既能保证RowKey的唯一性,又能保证RowKey的固定长度。
列族的设计:根据远程服务器中的数据表设计,HBase的列族包括用户信息、生长环境信息、地理位置信息。列族用户信息的列名包括用户名称、果园名称等;列族生长环境信息包括列名土壤温度、土壤湿度等;列族地理位置信息包含列名经度、纬度等。
1.4 基于贪心算法的小文件多级处理模块设计
果园农情信息大数据平台在长期运行后积累了大量的小文件数据,严重影响了系统的性能。为了解决大量小文件存储带来的问题,Hadoop社区提出了三种解决方案:Hadoop Arichive、Sequence File、MapFile,但是这几种方案的实现原理都是将小文件按照顺序合并成大文件,再将合并后的大文件存放到HDFS中,尽管可以促使系统中文件数量大大减少,从而降低存储文件所需要的节点内存和元数据数量,以此实现提升系统性能的目的,但是目前的合并方式会导致诸多新的问题,例如跨块储存、合并效率不高等。针对这些问题,本文提出了一种新的小文件多级处理模块。
1.4.1 基于贪心算法的文件合并方法设计
在传统的文件合并方式中,文件大都按照顺序合并,一旦合并后文件的大小超过了block块的大小就停止合并,这种合并方式会使得每个block块都没有得到充分的利用。图3(a)所示为传统合并方式的效果,其中,浅色部分为一个空的block块,深色部分A-G表示6个文件块。按照顺序合并的方式,最终可以将6个文件块合并到4个block块中,每个block块都会有很大的空间没有得到使用。
为了改善传统合并方式的存储性能,本文设计了基于贪心算法的文件合并方式。贪心算法是指在对一个问题进行求解时,每一步都做作出在当前看起来是最好的选择。图3(b)为基于贪心算法的文件合并方式,在存入文件A之后,计算A所在block块剩余的内存空间,然后寻找剩余文件中大小合适的文件存储到该block块中;同理依次完成其他文件的存储。与传统文件合并方式相比,基于贪心算法的文件合并方式用了更少的块存储同样大小、数量的文件。
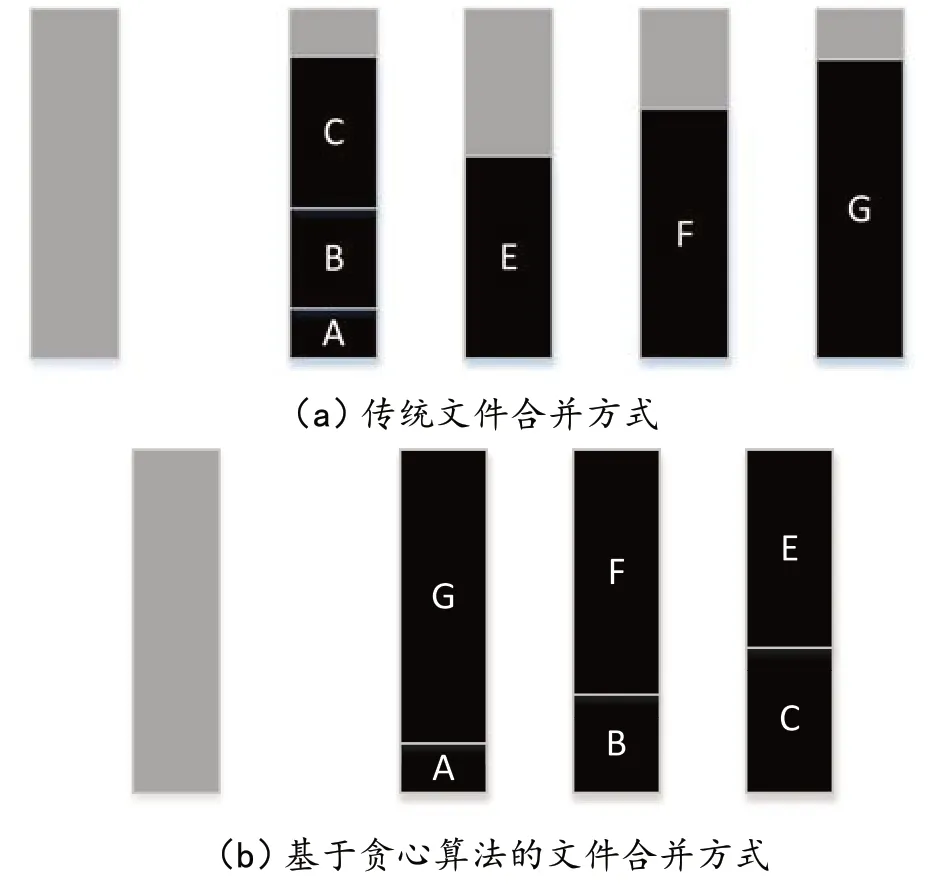
图3 系统内的文件合并方式
利用贪心算法的思想,在对文件进行合并时,先获取所有文件的大小作为value值与文件序列号组成key-value对缓存在Redis数据库中,当一个block即将填满,对后续的小文件进行遍历,找到最适合该block块存储的文件。
1.4.2 小文件多级处理模块设计
小文件多级处理模块的作用是在把文件存进Hadoop的分布式文件系统(HDFS)前,对文件所进行的多级处理。主要有以下几个部分组成(见图4)。
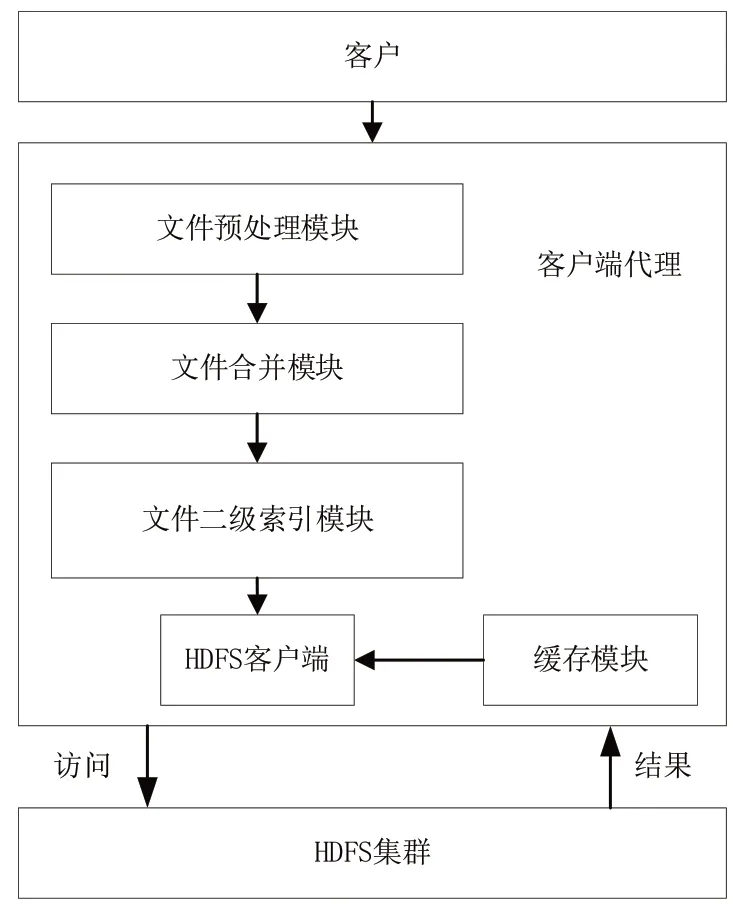
图4 加入了小文件处理模块的HDFS系统架构
(1)文件预处理模块。该模块主要对文件进行预处理操作:以4.3MB为分界线,将文件分成小文件和非小文件,并将小文件按照文件大小进行排序。
(2)文件合并模块。引入基于贪心算法的文件合并方式对文件进行合并,使得HDFS上的每个块文件能够得到最大程度的利用,避免块文件留下太多空白区间。
(3)文件二级索引模块。以文件存储日期为依据设置一级索引,以文件名和文件大小设置二级索引。与HAR归档不同的是,二级索引存储在DataNode节点上,减小NameNode内存的占用。
(4)缓存模块。在用户进行文件的读取操作时,为了加快读取速度,设置缓存模块。这部分统计用户操作文件的次数,并按次数从高到低将文件存储在缓存区。
1.4.3 小文件多级处理模块文件读写流程设计
由于在原生的HDFS架构前增加了新的文件处理层,原始的HDFS读写流程对于新的系统架构不再适用,本文针对新的系统架构设计了文件读写流程。
文件读取的具体操作步骤包括从用户执行读取文件操作到文件读取结果返回给用户等,直到读取文件操作完成,相应数据流关闭。操作流程见图5(a)。
文件写入具体操作步骤包括从用户执行写入文件操作、发出文件写入请求到文件处理层到文件写入结果返回给用户等,直至写入文件操作完成,相应数据流关闭。操作流程见图5(b)。
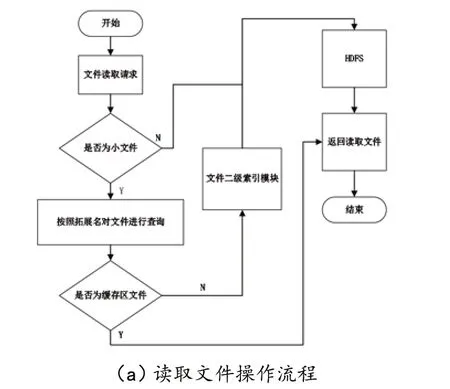
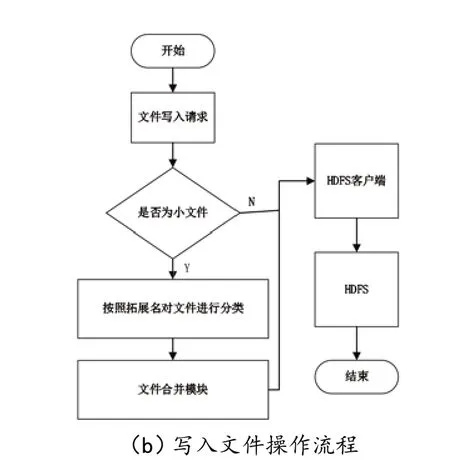
图5 系统内的文件操作流程
1.5 试验方法
在果园农情信息大数据平台中存储了从网站http://www.meteomanz.com/上爬取的果园当地气象数据,爬取的数据是2017年1月1日至2020年1月1日广西壮族自治区梧州市昭平县北陀镇的气象数据,以及广东省惠州市龙门县的气象数据,共约70000个文件做存储试验,对比HDFS原生存储方式、Hadoop社区提出的三种改进方案以及本文提出的小文件多级处理设计方案(MFM)在不同文件数量存储时所占用的NameNode内存、小文件合并后大文件的个数。
试验步骤如下:首先启动Hadoop集群,在HDFS上创建一个空目录,记录此时的NameNode内存占用storage00,然后存入1000个小文件,记录NameNode内 存 占 用storage01,storage01与storage00相减得到大致的HDFS原生存储方式的内存消耗。
然后在虚拟机中执行HAR归档的命令,得到归档后的文件,记录此时NameNode内存占用storage02,与storage01相减得到HAR归档方式下NameNode的内存消耗。在虚拟机中执行SequenceFile、Map-File、MFM的Jar包程序,以存储小文件的目录作为输入,输出到新的目录下面,记录两个Jar包执行后的NameNode内存,最终得到SequenceFile、MapFile、MFM方式下NameNode的内存消耗。
当在HDFS上依次存储1000、5000、10000、20000个文件时,重复试验步骤,记录试验数据。
2 结果与分析
2.1 数据查询试验结果与分析
将系统前期运行所采集的5000万条数据同时存入MySQL及HBase数据库中,对其进行数据查询并分析。
(1)在MySQL及HBase中存入1万条到200万条不同规模的相同数据,在两种数据库中对同一种数据查询5次,将查询时间进行平均,得到查询时间如表2所示,绘制存储规模为1万条至200万条的折线图,如图6所示。
由表2、图6可知,随着存储数据量的增加,MySQL数据库查询耗时也不断增加,当存储的数据量大于50万条时,MySQL的查询速度已经远远地慢于HBase的查询速度。MySQL查询在数据规模较小时表现出了良好的查询性能,而当存储数据量接近50万条时,其查询速度被HBase赶超。HBase查询时间随存储规模增加也逐渐增加,但增长较为缓和。
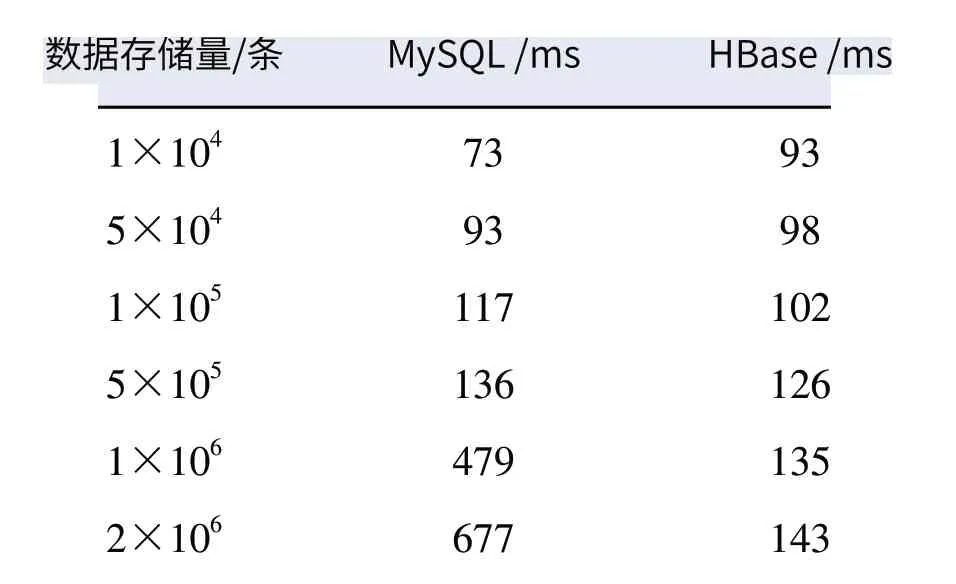
表2 不同存储规模下NySQL及HBase查询耗时
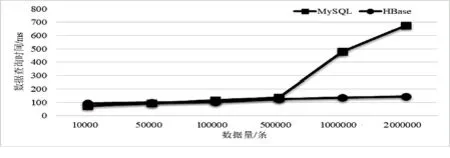
图6 系统不同存储规模查询耗时对比
(2)选择不同查询结果数据量,考虑到查询结果可能也存在数据量的差异,对存储规模为200万条的MySQL及HBase分别随机进行查询,每个数据量查询5次并将结果取平均,得到查询时间如表3所示,1千条至50万条查询量耗时情况如图7所示。
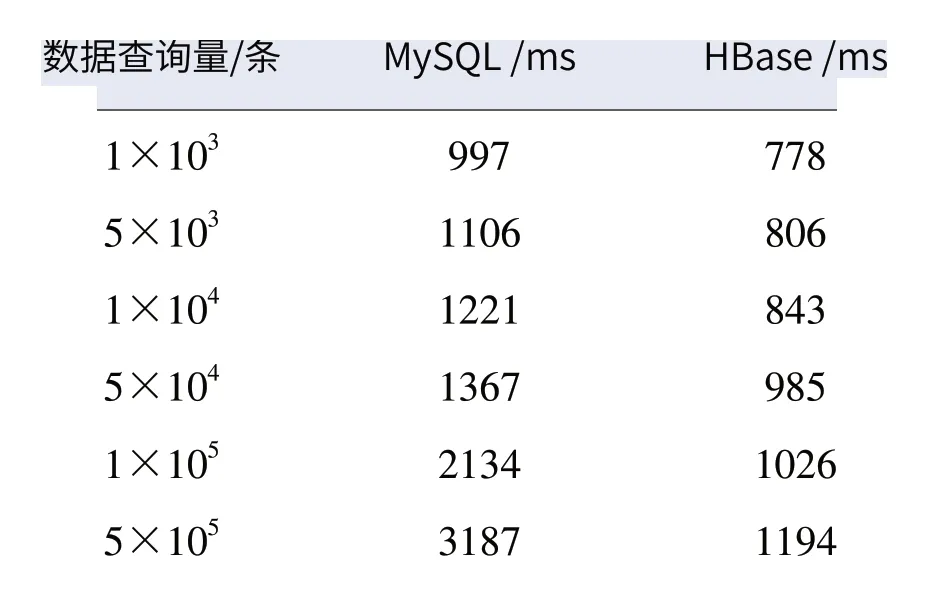
表3 不同查询规模下NySQL及HBase查询耗时
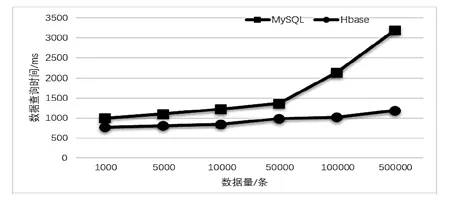
图7 系统不同查询量耗时对比
在存储数据量达到200万条时,MySQL数据库的查询速度已经整体差于HBase数据库;当数据查询规模大于5万条时,两者查询速度差距迅速拉大。因此,对历史数据存储选用HBase比较合适。试验结果表明,在对数据存储和查询的问题上,50万条以下的数据量,MySQL数据库优于HBase数据库;当数据量大于50万条时,HBase数据库更优。在数据存储前根据数据量大小选择优势互补的混合存储方式,而不采用单一数据库进行存储,通过此类方式可以更好地应对数据量的增加,尤其是农业生产中存在大量数据量的情况。
2.2 小文件存储试验结果与分析
小文件存储试验最终得到的结果如表4所示;不同存储方案对应在集群中NameNode消耗的内存上如图8所示。随着集群上小文件数量成倍增加,HDFS原生存储方式下NameNode内存的消耗也成倍增加。Hadoop社区推出的小文件处理方案(HAR,SF,MF)在处理20000个小文件的存储时,分别减小了内存占用77.5%、77.8%、78.2%;而本研究所提出的小文件多级处理方案在处理20000个小文件的存储时,减小80%内存占用,内存占用率明显低于其他方案,更加适合农业生产中海量小文件存储的应用场景。
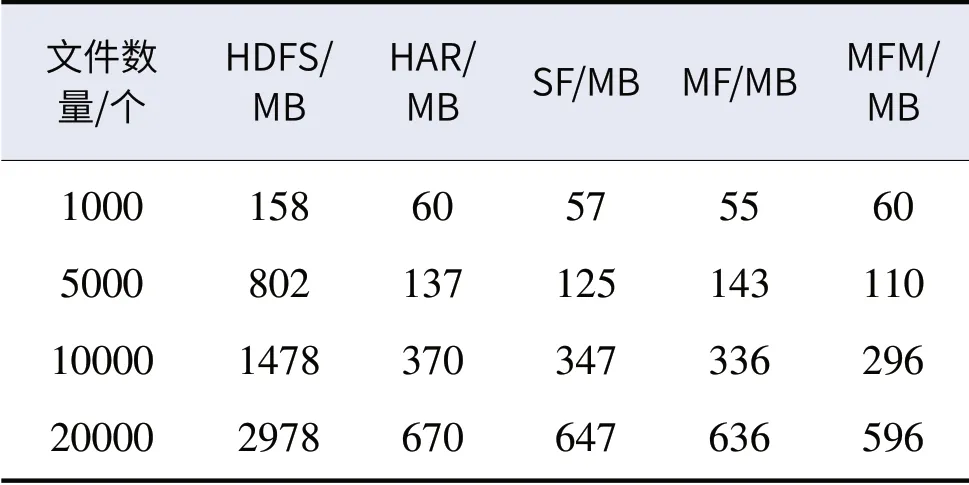
表4 不同储存方式下的NameNode内存消耗

图8 不同方案下的NameNode内存消耗对比
3 结论与讨论
为解决数字果园因海量数据衍生的问题,本文提出“MySQL+HBase”的混合存储方式及基于贪心算法的小文件多级处理方案,并在广西梧州柑橘园以及惠州龙门柑橘果园进行了示范应用,结论如下:
(1)在优化数据存储查询方面,与传统的MySQL数据库存储方式相比,“MySQL+HBase”的数据存储方式能够保持在百万条以下数据查询速度变化不大的情况下有效地提升百万条级别以上的数据查询速度达2倍以上。
(2)在小文件存储方面,小文件多级处理方案能够有效减小Namenode内存占用80%以上。
综上,本文认为,大数据平台致力于为果园信息的存储及查询服务只是果园生产、管理中的重要环节,尚不能达到智慧果园的全部要求,因此,下一步重点将大数据平台与专家系统、决策系统等结合起来,建立果园大数据的模型,实现由大数据驱动的智慧果园管理,为果园生产、管理提供可实际应用的解决方案。
