基于数据挖掘的重大错报风险识别和评估研究
2022-11-28李俊林
徐 静,李俊林
(北京联合大学 管理学院,北京 100101)
一、引 言
审计在维护资本市场秩序和社会公众利益、提升会计信息质量和经济效率等方面发挥着重要作用。为全面提升注册会计师行业服务国家建设的能力,国务院办公厅于2021年印发了《关于进一步规范财务审计秩序促进注册会计师行业健康发展的意见》,要求切实加强会计师事务所监管,遏制财务造假现象。同时,相关的法律、法规和准则体系逐步完善。如中国证监会制定了《监管规则适用指引——审计类第1号》,就注册会计师对上市公司财务报表发表非标准审计意见作出明确规范;中国注册会计师协会对《中国注册会计师执业准则》进行了多次修订;财政部正在开展对《中华人民共和国注册会计师法》的修订工作。在政策引导下,注册会计师行业迫切需要提高审计质量,从而更好地发挥审计鉴证作用。就财务报表审计业务而言,现代风险导向审计是以审计风险模型为基础的审计,即在重大错报风险识别和评估的基础上采取恰当应对措施,对财务报表是否在所有重大方面按照适用的财务报告编制基础编制发表审计意见。其中,重大错报风险识别和评估作为风险导向审计的起点,是财务报表审计中的核心程序。实务中,注册会计师通过了解被审计单位及其环境识别和评估重大错报风险,往往需要运用职业判断。然而,职业判断通常具有主观性,且会受到时间、压力、知识和经验不足以及所获取信息有限等因素的影响,职业判断可能因发生判断偏差而影响审计结果。
所谓重大错报风险,是指财务报表审计前存在重大错报的可能性。关于重大错报风险及其产生的动因,以往文献通常运用舞弊三角理论进行解释,即认为影响错报的因素主要包括三个方面:压力、机会和借口[1,2]。首先,财务困境和业绩压力是引致错报的内在动因。实证研究表明,当企业面临财务困境和业绩压力时,财务报表重大错报风险大大增加[3]。其次,股权结构[4]、薪酬契约安排[5]、审计委员会特征[6]、社会责任履行[7]、员工检举揭发[8]等公司治理在抑制财务报表错报方面发挥了积极的作用;审计透明度[9]、分析师关注[10]、法律环境[11]等外部监管对财务报表错报具有事前震慑和事后纠偏作用。最后,合理化因素潜藏于组织和生活环境中的各个层面,潜移默化地影响着行为人对错报自我合理化的态度[12]。因此,当企业具备以上要素时,很可能引发错报行为。如果错报单独或汇总起来可能影响财务报表使用者依据财务报表作出的经济决策,则通常认为错报是重大的。
基于对错报来源及其影响因素分析,注册会计师依据被审计单位及其环境信息识别和评估重大错报风险。关于重大错报风险识别和评估的研究,学者们从不同方面进行了探讨。根据审计准则,注册会计师通常运用询问、分析程序、观察和检查等方法,根据风险来源以固有风险和控制风险表示重大错报风险;或者根据风险类型以错误风险和舞弊风险表示重大错报风险,据此作出审计规划判断[13]。随着研究的深入,逻辑回归模型被用于重大错报风险识别和评估。如利用反映盈利质量的财务指标建立逻辑回归模型,能够较为正确地将公司划分为重大错报可能性高或低的公司[14];应用横截面、时序逻辑回归模型,与基于异常应计项目检查的预测模型相比,能够更有效地识别欺诈风险[15]。除广为采用的财务比率外,审计师在识别和评估审计期间发生的重大错报风险时,会适度利用非财务信息,如真实生产活动[16]。然而,审计师似乎更倾向于依赖财务信息,而不是非财务信息,或者说一些非财务指标在错报检测中的作用并不显著[17,18]。近年来,大数据技术在审计范围、风险评估程序理念、进一步审计程序以及审计证据等方面对风险导向审计产生影响,数据挖掘、机器学习、可视化等一些新方法逐渐被用于识别、评估和检测财务报表错报[19]。如针对前期会计差错调整,运用决策树、判别分析和逻辑回归等数据分析模型能实现更准确的预测[20];以多项逻辑回归、支持向量机和贝叶斯网络等多类分类器作为预测工具,能够根据欺诈意图对错报进行检测和分类[21];基于会计、资本市场、治理和审计数据,运用机器学习方法有助于发现并解释持续会计错报中存在的模式[22];基于审计报告中的关键审计事项信息识别出的重大错报风险,能够运用可视化技术实现更直观的展现研究[23]。得益于现代审计技术的发展,越来越多的审计软件被用于检测重大错报、控制缺陷和欺诈,发现重大错报则是衡量通用审计软件信息质量的重要标准[24]。
审计的价值在于能够发现和纠正财务报表中的错报,从而提升财务报表预期使用者对财务报表的信赖程度[25]。实证研究表明,审计风险模型的应用对财务报表错报的发现产生了显著影响,风险导向审计通过发现审计实践中的错报减轻了虚假财务报告的程度[26]。因此,审计师应将注意力集中在可能导致财务报表重大错误的各种症状、迹象或警示信号上,评估财务报表重大错报风险有助于审计师在审计过程中实现审计目标[27,28]。通过实施风险评估、控制测试和实质性程序,审计师对被审计单位财务报表整体是否不存在重大错报获取合理保证,为发表审计意见提供基础。 财务报表重大错报风险越高,被出具非标审计意见的概率也越高[29]。在无保留意见的审计报告中,包含解释性语言的财务报表比没有解释性语言的财务报表更容易进行后续重述[30]。如果审计师在执行审计业务时发生失误而签发了不适当审计意见,视为审计失败;未发现审计客户财务报表中存在舞弊或重大错报的审计机构将导致其声誉损失,可能会受到实质性的罚款和负面宣传[31]。因此,准确识别和评估重大错报风险是促进审计高质量发展的必要前提,也是学术研究中亟待攻克的难题。
结合当前的商业环境,企业数据呈现爆炸式增长的态势,面对海量大数据资源,注册会计师很可能淹没在数据的海洋里。但是,财务报表之间有着严密的勾稽关系,财务报表重大错报是有迹可循的。企业的每一笔交易和事项都具有较为完整的线索链条,任何问题都会在电子数据中留痕并呈现出一些特征[32]。与自然形成且符合逻辑的真实财务数据相比,存在重大错报的数据很可能有着数据结构上的缺陷,这种缺陷往往会导致异常[33]。重大错报公司与正常公司在盈利能力、偿债能力、成长能力和现金流量方面存在显著差异,会计信息的异常程度越大,公司进行财务报告舞弊的可能性越大[34]。因此, 通过分析不同财务数据之间以及财务数据与非财务数据之间的内在关联,注册会计师能够发现与其他相关信息不一致或与预期值差异重大的波动或关系,从异常特征的角度识别财务报表重大错报,并结合询问、观察和检查等程序进行调查取证。数据挖掘作为深层次的数据信息分析方法,能够对各种因素之间隐藏的内在联系进行深度探索,为重大错报风险识别和评估提供新的思路和方法。
综上所述,数据挖掘技术有助于注册会计师从大数据中找出财务报表重大错报的规律、关系和模式。为此,本文以因重大错报被出具保留和否定意见的上市公司为研究对象,基于注册会计师在实施风险评估程序时常用的指标,构建基于CHAID算法的财务报表重大错报分类预测模型,探索存在重大错报样本和不存在重大错报样本的基本特征及其决策规则,旨在更有效地识别、评估和检测财务报表重大错报,为注册会计师作出更准确的职业判断提供决策支持。
二、研究设计
(一)样本选择与数据来源
通过对近年来我国上市公司财务报表审计意见类型的分析,发现在所有被出具非标审计意见的上市公司中,超过半数的企业属于制造业,并且又以计算机、通信和其他电子设备制造业最多。因此,考虑到行业的差异性和数据间的可比较性,以2001—2020年我国深沪两市计算机、通信和其他电子设备制造业上市公司为研究对象,从中选取财务报表存在重大错报的样本。
1. 错报样本。取自因财务报表存在重大错报被出具保留意见和否定意见的上市公司。由于导致注册会计师发表保留意见的事项也可能源于无法获取充分、适当的审计证据,因而在数据处理时,剔除掉因审计范围受到限制被出具保留意见的上市公司。
2. 正常样本。取自财务报表不存在重大错报的上市公司,即其审计意见类型为标准无保留意见。并且,剔除掉被实施ST/*ST、曾被监管机构处罚的上市公司,进而按照隶属同行业、资产规模接近的原则,对数据进行清洗后,与错报样本组成配对样本。
依据上述原则和方法,因重大错报被出具保留和否定意见的错报样本共53条,为其一一配对正常样本后,共获得有效样本106条。上市公司基本信息、审计意见、监管处罚和相关的财务数据来自国泰安(CSMAR)和锐思(RESSET)数据库。
(二)变量定义
审计意见类型反映了财务报表经注册会计师审计后是否存在重大错报,因而,以“是否重大错报”为输出变量,被出具保留和否定意见审计报告,表示财务报表存在重大错报,以T表示;被出具标准无保留意见审计报告,表示财务报表不存在重大错报,以F表示。根据审计准则应用指南,分析程序是注册会计师识别和评估重大错报风险的重要程序之一。注册会计师在实施分析程序时常用的比率主要涉及五个方面的内容,即流动性比率、资产管理比率、负债比率、盈利能力比率、生产能力比率。据此,输入变量包括五大维度,共26个指标,见表1。
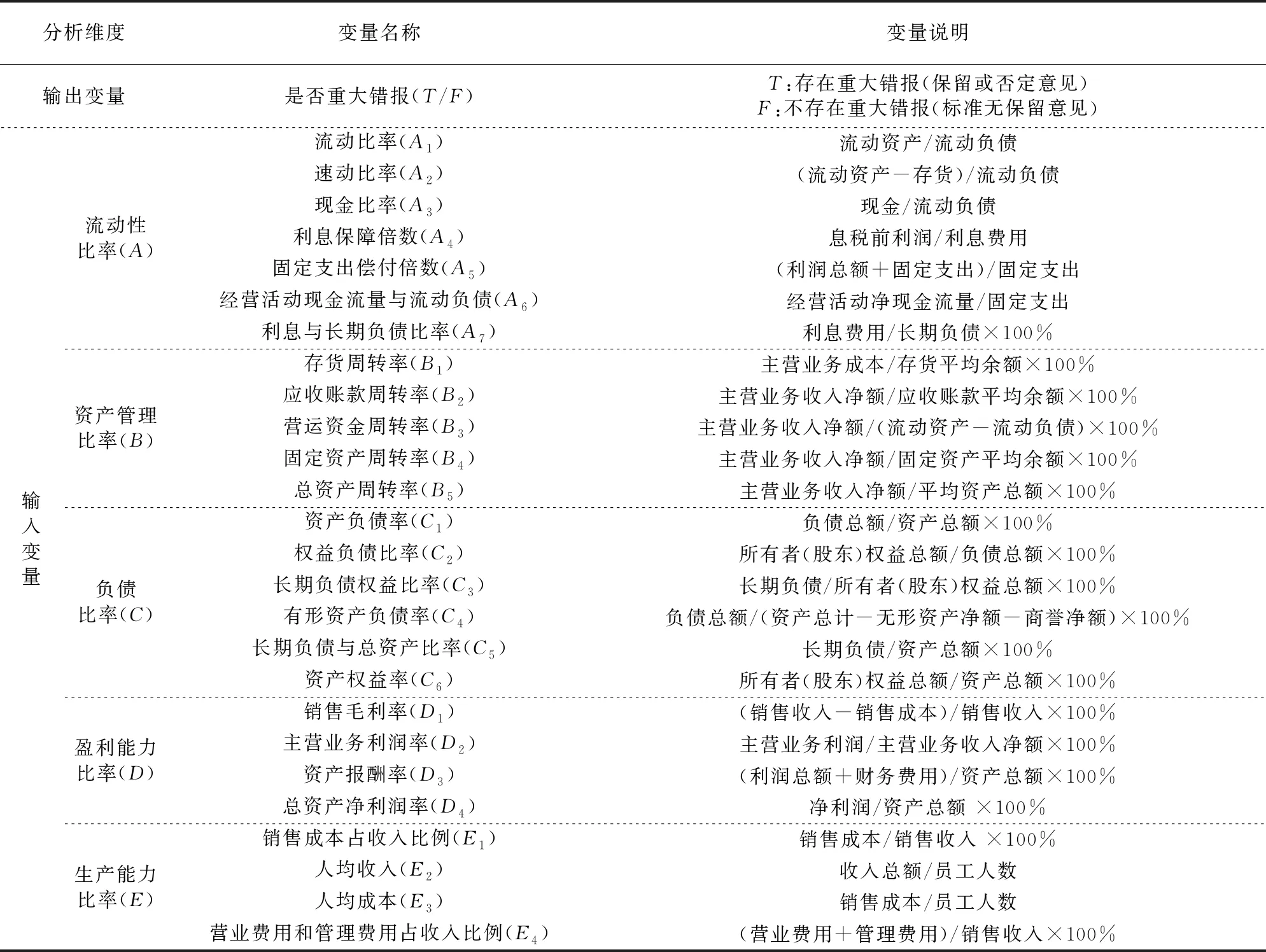
表1 变量设计
(三)模型构建
财务报表是否存在重大错报可视为一个二分类问题,为了挖掘上市公司相关数据中所蕴含的规律,构建基于CHAID算法的重大错报分类预测模型。CHAID是卡方自动交互诊断器(Chi-squared Automatic Interaction Detector)的简称,属于决策树算法的一种,其核心思想是确定决策树的分支准则,解决最佳分组变量和分割点的确定问题。CHAID建模过程主要包括两个步骤:
1. 对输入变量进行预处理,即对数值型输入变量值进行分箱处理,合并分类型输入变量的取值形成超类,以此减少输入变量的取值个数和决策树的分支。重大错报分类预测模型的输出变量“是否重大错报”为分类型,26个输入变量为数值型,针对这类问题采用ChiMerge分组法。ChiMerge分组的方法是按分位点分箱,然后根据统计检验结果合并对输出变量取值没有显著影响的组,因此,它是一种在输出变量指导下的分组,注重分析分组结果与输出变量间的相关性。
2. 对于经过预处理的输入变量,计算与输出变量相关性检验中的统计量及概率P值,依据统计显著性检验角度确定最佳分组变量和分割点。输出变量“是否重大错报”为分类型,采用卡方或似然比卡方。概率P值最小的输入变量与输出变量的相关程度最大,应作为最佳分组变量。CHAID算法自动将分组变量的各个类别作为树的分支,长出多个分叉,并通过采用预修剪策略控制决策树生长。上述过程反复进行,直到决策树生长完毕为止。
三、研究发现与结果分析
(一)参数设置
以“是否重大错报”作为目标变量,输入变量为反映上市公司流动性、资产管理能力、偿债能力、盈利能力、生产能力的各项指标,决策树生长采用CHAID算法,模型输出结果为财务报表重大错报分类的正确性,以及判断财务报表是否存在重大错报的规则集。
(二)特征变量选择
特征选择算法用来识别对给定分析目标最为重要的变量,即利用样本均值和方差分析,筛选出存在显著差异的指标。基于我国计算机、通信和其他电子设备制造业上市公司的错报样本和正常样本数据,对判断财务报表“是否重大错报”有积极贡献的主要特征变量如表2所示。
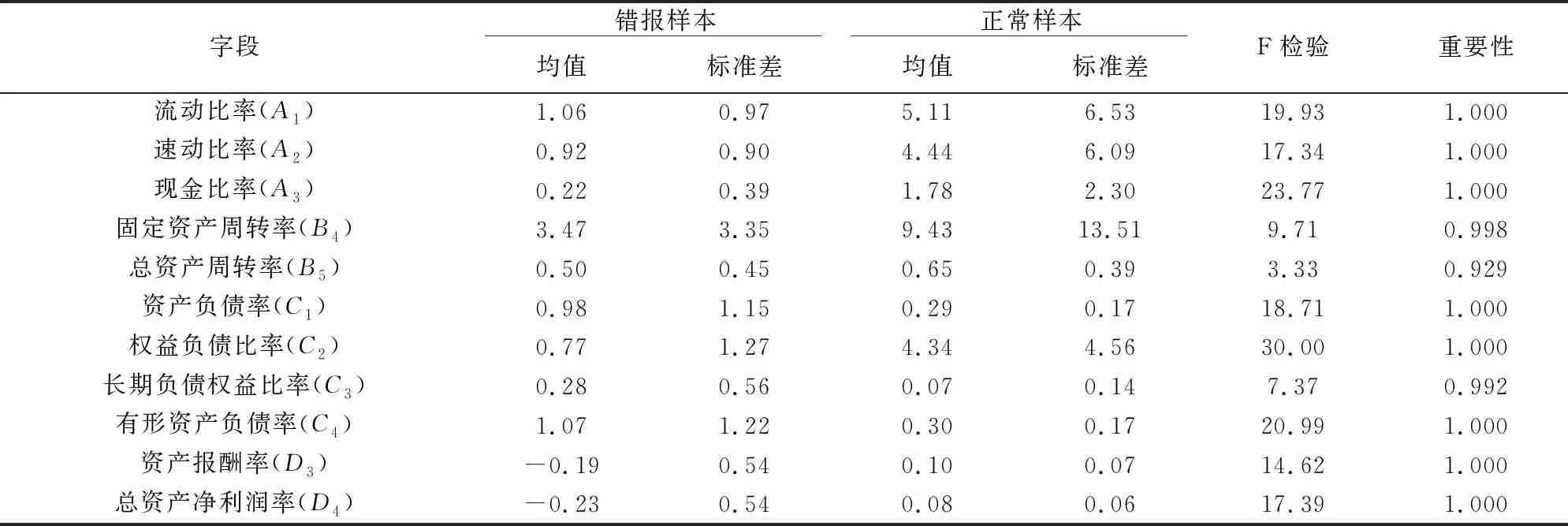
表2 样本均值比较
经过筛选、排序和选择发现,流动比率(A1)、速动比率(A2)、现金比率(A3)、固定资产周转率(B4)、资产负债率(C1)、权益负债比率(C2)、长期负债权益比率(C3)、有形资产负债率(C4)、资产报酬率(D3)、总资产净利润率(D4)这10个变量的重要性大于0.95,对识别财务报表重大错报均很重要;总资产周转率(B5)的重要性介于0.9~0.95之间,对识别财务报表重大错报的作用也较为重要。
(三)运算结果分析
基于表征财务报表是否重大错报的主要特征指标,运行CHAID模型,从错报样本和正常样本数据集中挖掘“是否重大错报”的规则集。按照规则的实例数和置信度,选取具有较高实例支持和置信度的3个有效规则,包含2个用于判断重大错报为T的规则和1个用于判断重大错报为F的规则,如表3所示。

表3 规则列表
从规则列表可以看出:(1)流动比率(A1)用来衡量企业流动资产在短期债务到期以前可变为现金用于偿还负债的能力,是识别财务报表重大错报的关键指标,相较正常样本,错报样本的流动比率更小,说明企业资产的变现能力更弱,面临更大的短期偿债压力。(2)总资产净利润率(D4)作为衡量企业盈利能力的综合指标,为判断上市公司财务报表是否存在重大错报提供重要依据,财务报表存在重大错报的上市公司总资产净利润率较低,说明企业获取利润的能力明显不足。(3)长期负债权益比率(C3)反映狭义的资本结构情况,用于评估财务风险和杠杆率,财务报表不存在重大错报的上市公司长期负债权益比率更低。具体就计算机、通信和其他电子设备制造业的行业特点而言,较低的流动比率和总资产净利润率以及较高的长期负债权益比率,意味着企业在较高的置信水平上具有高错报风险。
根据导致财务报表重大错报的动因分析,以上关键指标的恶化将使管理层面临偿债或盈利方面的压力,从而可能引发重大错报风险。换言之,流动性差、盈利能力不足、长期偿债能力弱的上市公司,其财务报表重大错报风险较高,符合上市公司财务报表发生重大错报的内在逻辑。
(四)模型评估
根据模型运行结果,“是否重大错报”预测的总体正确率为97.17%。具体来说,106个样本中分类正确的为103个,占比97.17%;分类错误的为3个[其中:1个不存在重大错报(F)被分类为存在重大错报(T),2个存在重大错报(T)被分类为不存在重大错报(F)],占比2.83%。如表4所示。
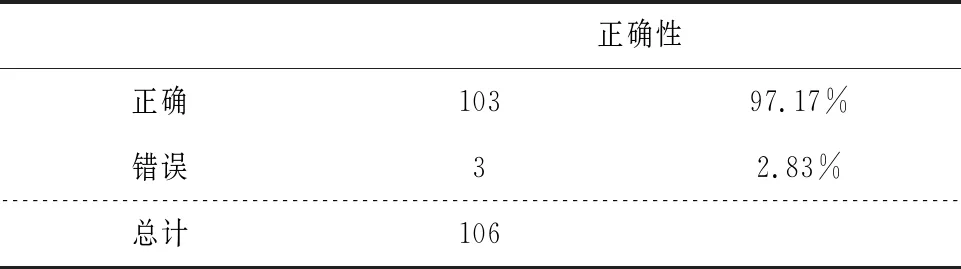
表4 分类结果
总的来看,基于CHAID算法的分类预测模型在财务报表重大错报识别中体现出良好的性能,正确分类的平均置信度超过90%,如表5所示。

表5 置信度报告
分类预测模型的性能优劣可以利用增益图(gain chart)、接受者操作特性曲线(receiver operating characteristic,ROC)等来进行评估,如图1、图2所示。
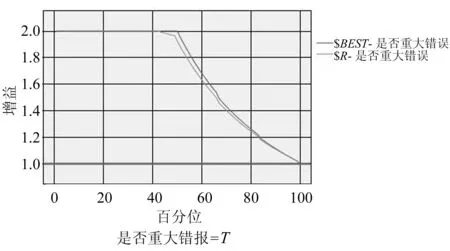
图1 带有最佳线的利润图
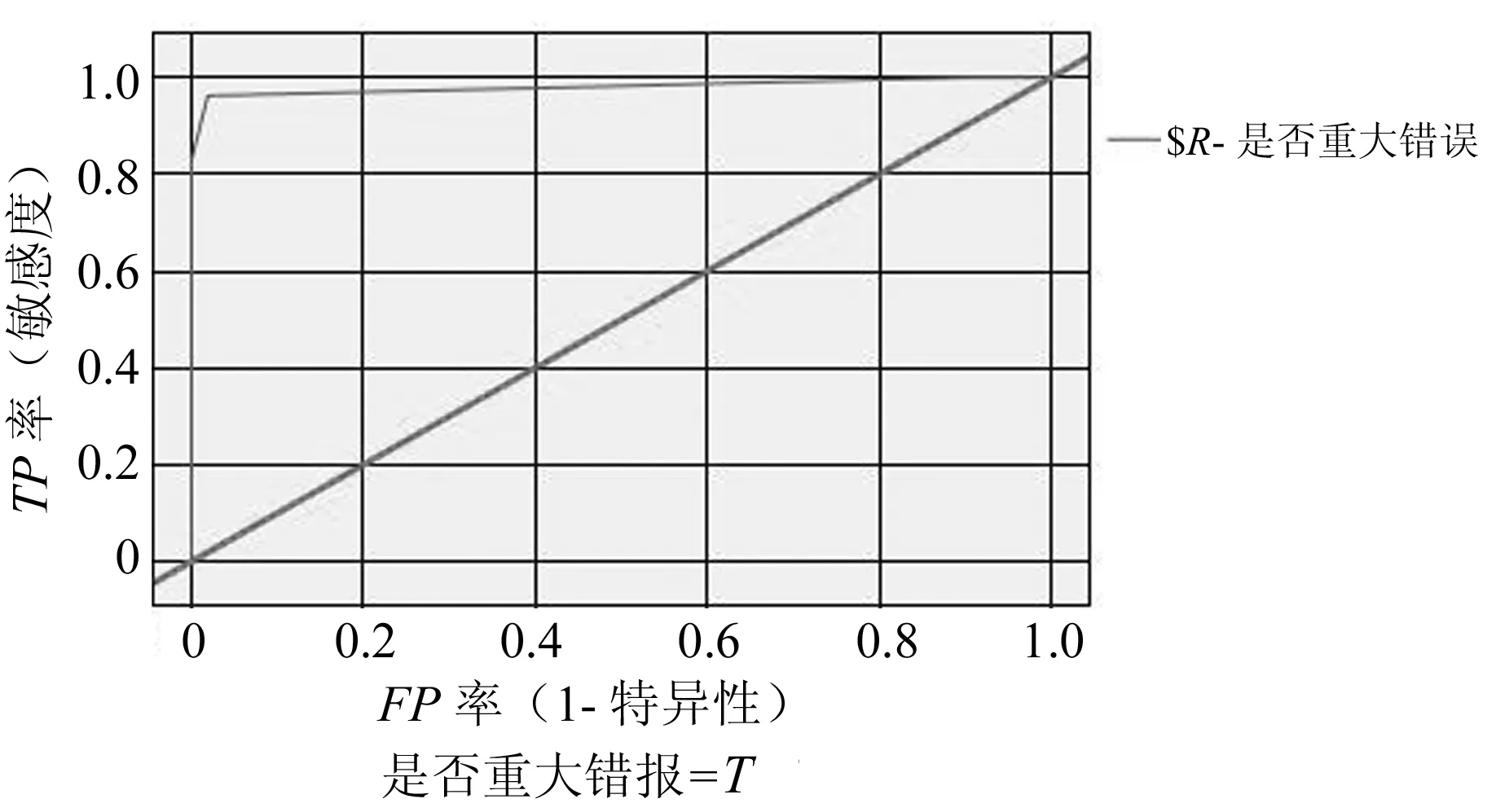
图2 ROC曲线图(AUC=0.98)
根据模型评估分析,在关于财务报表“是否重大错报”的分类预测中,模型增益图显示的分类结果与最佳线非常接近,ROC线下面积AUC值为0.98,接近1,表明该模型的分类效果较为理想。
四、研究结论与启示
针对风险导向审计中的重大错报风险识别和评估问题,基于我国计算机、通信和其他电子设备制造业上市公司跨越20年的财务、审计和监管等信息,运用数据挖掘技术研究了财务报表重大错报的特征及其决策规则。主要研究结论如下:(1)财务报表之间有着严密的勾稽关系,与自然形成且符合逻辑的真实财务数据相比,存在重大错报的上市公司在流动性、盈利能力、偿债能力的指标取值上存在显著差异。(2)基于CHAID算法挖掘出3条用于判断财务报表重大错报与否的关联规则,其中2条用于识别存在重大错报,1条用于识别不存在重大错报,揭示了重大错报与关键特征指标之间的关系,这些规则符合错报动因理论的基本逻辑。
将数据挖掘方法应用于财务报表重大错报风险识别和评估研究,通过构建分类预测模型对重大错报与否的决策规则进行挖掘,是对传统重大错报风险识别和评估方法的有效补充。研究结果能够辅助注册会计师发现财务报表重大错报的线索,为识别、评估和预测上市公司财务报表重大错报风险提供参考,从而降低发生判断偏差的可能性,大幅提高审计效率和效果。
