基于相似度均值的分类数据层次聚类分析算法
2022-11-25褚轲欣荀亚玲
褚轲欣,荀亚玲
(太原科技大学 计算机科学与技术学院,山西 太原 030024)
0 引 言
作为一种无监督学习方法,聚类分析是数据挖掘、机器学习等领域的主要研究内容之一。聚类分析根据某种相似性度量将数据对象划分为多个类簇,并使得在同一个类簇中的不同数据对象之间相似度较大,不同类簇中的数据对象之间相似度较小[1]。在商务智能[2]、图像处理[3]、市场分析[4]、模式识别[5]、基因研究[6]等领域应用广泛。但随着数据类型日益复杂化和多样化,人为设置参数,聚类效果对参数敏感且参数不易确定,成为当前聚类分析面临的主要挑战之一。
层次聚类分析是一类典型的聚类分析方法,通过某种相似性度量确定数据对象之间的相似性,并对数据集中的数据对象不断地合并或分裂,可识别任意形状的簇。但由于层次聚类的合并或分裂依赖于事先人为设定的相似度阈值,相似度阈值的取值直接影响最终的聚类簇个数与聚类质量[7];在没有先验知识的情况下,相似度阈值参数难以确定;分类数据作为一类重要数据类型,对其层次聚类分析研究较少。根据自适应阈值法的思想[8-11],该文提出了一种基于相似度均值的分类数据层次聚类分析算法。利用相似度均值,作为层次聚类簇合并或分裂的重要依据,解决了层次聚类分析中的参数人为设定问题。主要贡献如下:
·提出了一种基于相似度均值的分类数据相似度阈值自动选取方法;
·给出了一种边界数据对象分配策略;
·提出了一种基于相似度均值的分类数据层次聚类分析算法。
1 相关工作
聚类分析的目的是使得划分后的数据点簇内彼此相似,簇间彼此相异。目前,聚类算法主要包括密度聚类算法[12]、模型聚类算法[13]、网格聚类算法[14]、划分聚类算法[15]以及层次聚类算法[16-18]等。
层次聚类是一种基于原型的聚类方法,试图在不同层次对数据集进行划分,从而形成树形的聚类结构。通过绘制树状图,以可视化的方式来解释聚类结果,可解释性强[19-20],可以对任意形状的簇进行聚类[7]。层次聚类分析的典型成果主要包括:C-Ward[17]算法在Ward算法[21]的基础上,在层次聚类过程中依据聚类的中间结果动态更新必连和不连约束,以保证最终的聚类结果同时满足必连和不连约束。该算法保证了数据样本点获得更为合理的聚合顺序,从而得到更为准确的聚类结果。ROCK算法[7]是一种用于分类数据的层次聚类分析算法。该算法采用随机抽样技术与链接的相似性度量计算两个数据对象相似度,考虑了周围数据对象的影响,但要求用户事先选定聚类数,且相似度函数只考虑数据对象之间是否相似而未考虑相似程度,所以对阈值较为敏感。Similarity算法[22]提出了一种新的局部相似性度量,仅使用星型邻域子图,通过网络节点相似性度量的减函数来定义节点间的广义距离。相对全局的相似性度量,克服了传统局部相似性度量在某些情形下对节点相似性的低估倾向,但矩阵的存储形式难以适用于大型网络。DHCC算法[23]基于多重对应分析(MCA)初始化,提出了初始化和细化聚类分割的有效步骤,能够无缝发现嵌入在子空间中的集群。该算法不采用全局细化,对初始误差传播问题不敏感,但会受异常对象的影响。MGR算法[24]是一种基于信息论提出的算法,该算法利用信息论中的平均增益比(MGR)和簇熵概念确定聚类属性,并在属性定义的分区中选择等价类作为一个聚类簇,循环迭代直到输出所有的数据对象,其算法时间复杂度较低。MTMDP算法[25]采用概率粗糙集理论的分区属性选择方法TMDP与粒度概念相结合,根据等价关系,将数据对象划分为一组子集(粒子)。MTMDP算法的操作数是粒子而不是单独的数据对象,是一种鲁棒的聚类算法,用于处理分类数据聚类过程中的不确定性。MNIG算法[26]对现有的聚类方法进行了系统的分析,总结了各自的优缺点,建立了一个统一的分层聚类框架并对该框架的每一步进行了改进,得到了性能更好的MNIG算法。
综上所述,随着对分类数据层次聚类分析研究的逐渐深入,针对分类数据的层次聚类算法获得了较好的聚类效果。但其聚类分析算法大都需要人为设定终止条件与相似度阈值等参数,控制聚类簇的合并或分裂,从而导致聚类效果受人为设定参数的影响较大。
2 相似性度量与聚类分析
聚类分析是指将物理或抽象对象的集合分组为由相似的对象组成的多个类簇的分析过程,因此如何描述数据对象间的相似性是聚类分析的重要问题。相似性度量是度量数据对象之间相似性的重要方法,参照文献[27],相关概念定义如下:
设分类数据集D含有N个属性,其中属性Ai的取值集合记作:Dom(Ai),Dom(Ai)={ai,1,ai,2,…,ai,f},表示属性Ai具有f个不同的取值。属性值ai,j(ai,j∈Dom(Ai))关于属性Ai的支持度是数据集D中属性Ai取值等于ai,j的数据对象的个数,记作:
Sup(Ai|ai,j)=|{x|x∈D,xi=ai,j}|
1≤j≤f,1≤i≤N
(1)
其中,xi表示数据对象x在属性Ai上的取值。
相似度反映了数据对象之间的相似程度,取值区间为[0,1]。对于任意的x,y∈D,x与y的相似度Sc(x,y)、相似性度量θ(xi,yi)可定义为:
(2)
(3)
其中,Wi表示属性Ai所占的权重,即:
在公式(3)中,分类数据的相似度计算引入相似性度量θ(xi,yi),当xi≠yi时,θ(xi,yi)=0。代入公式(2)计算相似度Sc(x,y),若θ(xi,yi)=0,无论该属性维计算得到的权重值Wi多大,那么该属性维的相似程度Wiθ(xi,yi)都为0,相当于该属性维在计算相似度Sc(x,y)的过程中没有发挥作用。因此,最终计算得到的相似度并未准确代表各数据对象之间真实的相似程度。
3 分类数据的层次聚类分析
3.1 相似度均值与层次聚类分析
层次聚类分析作为一种典型的聚类分析方法,通过对数据集中的数据对象不断地合并或分裂,可较容易地发现类的层次关系,可聚类任意形状的簇[7]。目前,层次聚类分析算法主要是根据人为设定的相似度阈值参数,实现聚类簇的合并或分裂。因此,相似度阈值作为层次聚类分析中的唯一参数,受人为因素的影响,并影响着最终聚类簇个数与聚类质量[28-29]。
由公式(2)中属性Ai的权重Wi计算公式可知,将属性Ai的熵Hc(Ai)的累加和Soe重新定义如下:
(4)
其中,Hc(Ai)表示属性Ai的熵。

依据文献[30]中两次归一化过程,将较大数量级的值归一化到距离目的数量级相差不大的范围内的过程记为第一次归一化过程。根据Soe表示的相似度的数量级别,首先将Soe按缩放比例缩放到[1,10]之间。由于余数的取值会影响归一化值的准确性,对余数做四舍五入处理,即:余数小于5时,归一化缩放比例值不变;余数大于等于5时,归一化缩放比例值加一。因此,归一化缩放比例值scale_n,第一次归一化值r_nor定义如下:
(5)
(6)
其中:⎣」、「⎤表示向下、向上取整,Soe表示分类属性Ai的熵Hc(Ai)的累加和。
在公式(6)中,归一化的目是使预处理的数据被合理地限定在一定范围内,提高数据对象相似度的表现力,使数据对象的相似度值较平稳分布在[1,10]之间。四舍五入的思想能使被保留部分与实际值差值不超过最后一位的二分之一,使得误差和最小。因此,四舍五入的方法在第一次归一化过程中可以减少Soe缩放误差,提高第一次归一化值r_nor的准确性。
参照文献[30],将第一次归一化值归一化到目的数量级的过程记为第二次归一化过程。进一步采用归一化与四舍五入相结合的思想,将r_nor缩放到[0,1]的数量级,得到第二次归一化值f_nor。第二次归一化值f_nor定义如下:
f_nor=r_nor/20
(7)
其中,r_nor表示第一次归一化值。
在公式(7)中,归一化目的是使预处理的数据被限定在一定范围内,避免由于特征本身表达方式的原因而导致在绝对数值上的小数据被大数据“吃掉”的情况,以保证每个特征被平等对待并处于同一数量级,从而使不同维度之间的特征在数值上有可比性。第二次归一化在第一次归一化的基础上,得到了更准确的归一化值,并将第二次归一化值f_nor归一化到目标范围(即:[0,1])之间。第二次归一化值f_nor可以较准确地反映相似度总体水平,缩小相似度极端值的出现频率。
根据上述公式(7)所得f_nor,为缩小相似度差异,将公式(3)重新定义为平稳相似性度量,并描述如下:
(8)
其中,θs(xi,yi)称之为平稳相似性度量;f_nor表示属性值不相同(即:xi≠yi)时的第二次归一化值,取值范围为[0,1]。
在公式(8)中,θs(xi,yi)保持属性值相同(即:xi=yi时)的取值不变,等于1,属性值不同(即:xi≠yi)时的取值等于f_nor,f_norf是一个动态值。对于每个属性维,不会再出现Wiθ(xi,yi)=0,忽略相似度计算过程中丢失重要属性维的情况。f_nor近似反映了数据集中所有数据对象相似度的分布趋势,使得Sc(x,y)变化比较平稳,可以正确表示数据对象之间的相似度,为计算相似度阈值做准备。

(9)
其中,|x|表示任意数据对象x的编码,|D|表示数据集D的数据对象总数。
3.2 边界数据对象分配策略
由于层次聚类方法使得所有的数据对象在全部簇中有且仅出现一次,这样的合并方式使得边界数据对象无法被友好地确定属于哪一个簇的边界点或噪声点。针对以上两种边界数据对象的分布情况,边界数据对象分配策略如下:

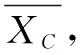
4 基于相似度均值的分类数据层次聚类分析算法HCAS
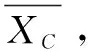
Algorithm:HCAS (Hierarchical clustering analysis for Classified data based on Average Similarity)
Input:分类数据集D
Output: Clusters
从数据集D提取N;//*N为属性个数
Fori=1 to|D|do //*依据公式(2),计算相似度Sc(x,y),并插入List_Sim中;
Forj=i+1 to|D|do //*x,y分别为第i个,第j个数据对象;
Forz=1 toNdo
利用公式(4)-(8),计算平稳相似性度量θs(xi,yi);
利用公式(1)-(2)计算相似度Sc(x,y)并插入List_Sim中;
End For
End For
End For
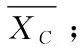
Clusters={ };
For allSc(x,y) in List_Sim do //*依据相似度均值,获得初始聚类簇,并标记边界数据对象
Switch(Clusters中的聚类簇Q)
Casex属于Q:Q=Q+{y},Break;
Casey属于Q:Q=Q+{x},Break;
Casex与y都不属于Q:
Clusters=Clusters+{x,y},Break;
End Switch
End If
将出现在两个以上初始聚类簇中的数据对象x,在List_B中,标记x为边界数据对象;
End For
For all 边界数据对象xin List_B do //* 按边界数据对象分配策略分配边界数据对象
依据3.2节中边界数据对象分配策略,将x重新分配到Clusters中的聚类簇;
End For
return Clusters
时间复杂性分析:

5 实验结果分析
实验环境:CPU Intel®酷睿TMi7-4710MQ,内存为12 GB,操作系统为Microsoft Windows 10,采用java语言,在jdk1.8、jre1.8、eclipse-jee-neon-3环境下,实现了HCAS算法与对比的分类数据层次聚类算法:ROCK[7]、MGR[24]、MTMDP[25]、MNIG[26]。
数据集:人工合成和UCI[32]数据集,详见表1。其中:Class表示聚类个数,Instance表示数据对象个数,N表示属性个数。
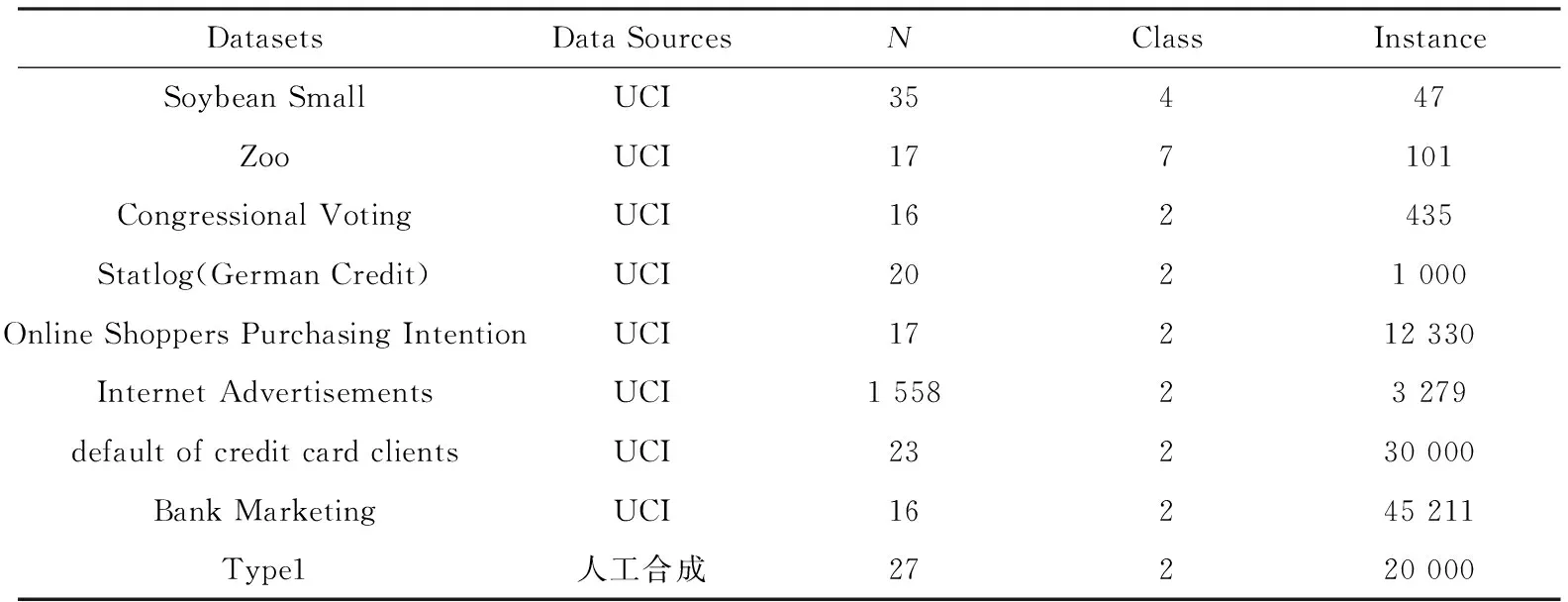
表1 数据集
评价指标:准确率Accuracy (ACC)、兰德指数Rand Index (RI)、Fowlkes and Mallows Index (FMI)、F1指数[33-34]四个评价指标,更客观地衡量聚类效果。ACC表示衡量分类正确的记录个数占总记录个数的比例;RI表示衡量聚类结果与真实簇标签之间的相似性;FMI表示两两精度和召回率的几何平均值;F1表示准确率与召回率二者的调和均值。
实验对比的分类数据层次聚类算法参数设置:将对比算法ROCK、MGR、MTMDP与MNIG的聚类个数参数设置为正确的聚类个数,然后设置ROCK算法参数θ的取值区间,运行多次,选择最优的聚类效果作为最终的结果[27]。实验数据集的预处理方式为:删除数据集中含有缺失属性值的记录;删除数据集中分布在不同类别中的相同数据对象。
5.1 相似度均值的稳定性分析
表2 相似度均值的稳定性

续表2
5.2 聚类效果分析
为了验证HCAS算法的聚类性能,在UCI数据集上,给出了ROCK、MGR、MTMDP、MNIG和HCAS算法性能比较,其实验结果详见表3,其中k表示聚类簇个数。

表3 UCI数据集上的聚类算法性能比较

续表3
由表3可知,HCAS算法在四种评价指标上的聚类性能都好于ROCK、MGR、MTMDP、MNIG算法。其主要原因是:在HCAS算法中,采用了平稳相似性度量,避免忽略重要属性维,使数据对象之间的相似度计算更加准确;HCAS由于采用了边界数据对象分配策略,使得模糊边界数据对象被最大概率分配到正确的聚类簇中,提高了层次聚类分析的聚类质量;ROCK算法对于相似度较小但属于一个聚类簇的边界数据对象不友好,从而导致边界数据对象分配不准确,聚类效果较差。MTMDP算法由于提高了每次分裂叶子节点选取的准确度,所以聚类效果较稳定。MGR算法用度量分区之间的相似性,来构造与每个属性关联的分区尽可能接近的分区,所以聚类效果较好。MNIG算法综合现有的聚类方法建立统一的分层聚类框架,并对框架的每一步进行改进,从MNIR选择的属性生成的分区中选择最好的分区,所以其聚类效果优于MGR算法。
5.3 抗噪性
为了验证HCAS算法的抗噪性,采用表1所示Type1数据集,分别添加5%、10%、15%的噪声数据,比较HCAS算法的聚类性能指标,其实验结果如图2所示。
由图2可知,随着数据集中噪声数据比例的增大, ACC、FMI、RI和F1都呈现降低趋势。其原因是:随着噪声数据的增多,噪声数据干扰了相似度计算的准确性,使HCAS算法错将一部分噪声数据对象当作边界数据对象添加到聚类簇中,造成了评价指标的下降。随着在数据集中每增加5%的噪声数据,评价指标降低约0.03到0.05之间,噪声数据对聚类结果影响不大,HCAS算法在有噪声的数据集中依然具有较高的聚类质量,说明HCAS算法具有良好的抗噪性。
6 结束语
针对层次聚类相似度阈值需要人为设定的问题,定义了一种相似度均值计算方法,并作为层次聚类簇合并或分裂的重要依据,有效解决了相似度阈值参数人为设定问题;采用相似度均值,给出了一种边界数据对象分配策略,并提出了一种基于相似度均值的分类数据层次聚类分析算法。该算法充分利用数据对象在数据集中的分布特点,自动确定相似度阈值,降低了人为因素的干扰,提高了聚类质量。下一步工作是针对混合属性数据层次聚类分析,研究相似度阈值的自动设定。
