基于深度学习的驾驶舱面板字符识别
2022-11-24彭卫东李娜魏麟
彭卫东,李娜,魏麟
中国民用航空飞行学院 航空电子电气学院,四川广汉,618307
0 引言
随着深度学习技术的发展,其已在智能语音识别、自然语言的处理、计算机视觉、图像识别与视频分析及多媒体等诸多新兴领域中应用。字符识别技术也随着深度学习技术的不断发展逐渐成熟,其应用范围也逐渐扩展,未来在各领域中将会扮演重要角色[1]。传统的字符识别流程包括对字符进行预处理、识别阶段和进行后处理三个部分,其中识别阶段对每个字符进行分割、单字符处理和单字符轮廓查找,再进行后处理得到比对结果。在对字符组进行单个分割操作时产生的误差积累[2],使得传统方法对字符识别速度和精度效果不佳。随着深度学习技术的发展,针对字符分割累计误差,以及特征提取依赖人工、识别速度慢等缺点,提出了深度学习端对端字符识别方法,即单阶段算法,对整个字符一次性进行检测识别,减少了由于字符分割造成的误差累积[3-4],由数据驱动进行特征提取,模型泛化能力更好,且检测识别速度和精度有大幅度提升。单阶段主要识别算法有Yolov1[5]、Yolov2[6]、Yolov3[7]、SSD[8]等,其中Yolo系列算法是采用回归思想检测识别,SSD取卷积神经网络不同的特征层检测输出,是一种多尺度的检测方法。本实验在考虑面板字符特征的基础上,选用Yolo系列端对端深度学习方法[9],并结合OpenCV的深度神经网络(deep neural network,DNN)模块调用训练好的模型来识别面板字符。
1 总体设计方案
将检测识别设计分为数据预处理、数据训练以及目标检测识别三个阶段。使用公开字符数据集中图片和自收集图片组成本实验的整体数据集,数据标注软件将数据集标注成训练所需要的文件格式,数据进行迭代训练使用的是轻量级Yolo-Fastest算法,收敛生成针对字符识别的权重文件,检测识别部分选择OpenCV开源库的深度学习DNN模块,调用部署训练好的深度学习模型来检测面板字符,使其运行效率更高。
1.1 Yolo算法介绍
Yolo算法是单阶段目标检测网络,其算法采用回归思想,将目标检测转成回归问题。如图1所示为Yolo算法基本检测流程,使用卷积神经网络得到一个固定大小的特征图,接着CNN将输入图像划分成S×S网格,每个单元格负责预测中心点落在该格子内的目标,每个网格预测B个边界框(bounding box)和边界框位置(x,y,w,h)及置信度(confidence score),用非极大值抑制算法得到最后的目标结果。在Yolo系列算法中,Yolo-Fastest模型尺寸最小,检测精度优于Yolov1、Tiny Yolov2 和 Tiny Yolov3,检测速度优于Yolov2,能够支持PyTorch、Tensorflow、Keras、Caffe等深度学习库,且在硬件设备上更容易部署[10]。本次实验类别只有一类Text类,在考虑精度和速度的同时,选择Yolo-Fastest为本次实验的算法模型检测面板字符,使用OpenCVDNN深度学习模块调用训练好的模型最后识别面板字符。
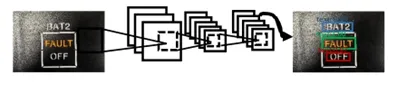
图1 Yolo检测流程
1.2 Yolo-Fastest网络结构介绍
Yolo-Fastest是一种开源的基于Yolov3框架的轻量级目标检测算法,传统Yolov3基于Darknet53网络,共有73层,其中卷积核大小为3*3和1*1的卷积层有53层,其余为残差层。Yolo-Fastest网络由主干网络和深层网络层组成,主干网络用于提取图像特征,深层网络层的作用是提取目标物的边界框,Yolo-Fastest为减少模型的参数量和运算量,在主干网络中大量采用深度可分离卷积并减少了网络的层数,主干网络由27个层组成,第一层为标准卷积层,其余层均为深度可分离卷积层,深度可分离卷积极大减少了计算量,缩小了网络模型[11]。Yolo-Fastest的损失函数是在Yolov3损失函数的基础上将x,y,w,h的坐标损失从交叉熵损失换成了CloU[11],式(1)-(3)为其损失函数计算公式,公式中的损失函数考虑了重叠面积、中心点距离和长宽比。其中v是长宽比的相似性,c是对角线距离,a是权重参数。

2 实验设计
2.1 数据预处理
Yolo-Fastest使用VOC数据集框架模型,所以需要根据VOC数据集的框架构建数据集。本实验使用ICDAR2013公共数据集以及自收集图片共同组成实验数据集,选用VOC2007数据集制作软件对原图片统一命名,处理生成xml格式标注文件,文件内容有图片文件名、尺寸大小以及图片中包含的目标以及目标信息,其中xmin和ymin分别为每个目标框的左上角坐标,xmax和ymax为右下角坐标;xml格式转换成Yolo使用的标注txt格式文件,标注后的每个txt文件包含5个数值,分别是所标注内容的类别、归一化后的中心点x坐标、归一化后的中心点y坐标、归一化后的目标框宽度w、归一化后的目标框高度h[12],本实验的实验数据集类别只有text类,标注内容的类别显示为0。
2.2 数据训练
数据集进行训练时,需要对配置文件进行修改,根据硬件配置和数据集类型修改Yolo-Fastest的配置文件中相关参数,将类别classes设置成1,图片输入信息为416*416*3,权重衰减系数为0.0005,防止过拟合,初始学习率为0.001,执行指令生成预训练权重文件,生成的预训练权重文件大小为821kB。开始正式训练,将训练次数设置成35000,每训练1000次,保存一次权重。
2.3 OpenCV-DNN模块调用Yolo-Fastest
OpenCV开发的DNN模块可以专门用来实现深度神经网络的相关功能。OpenCV无法训练模型,但可以载入训练好的深度学习框架模型,用该模型做预测,OpenCV在载入模型时会使用DNN模块对模型进行重写,使得其运行效率更高。
OpenCV的DNN模块做Yolo-Fastest的前向推理时,所需要调用的是训练数据集时的配置文件和训练数据集最后生成的权重文件。DNN模块重新部署深度学习模型时,需要用到如下关键函数处理,OpenCV的DNN模块通过读取输入的配置文件和训练好的权重文件来初始化Yolo-Fastest网络。detect函数对输入的图像做目标检测,画出图中物体的类别和矩形框,其中dnn.blobFromImage实现了每一帧图片的预处理,dnn.NMSBoxes根据给定的检测boxes和对应的scores进行非最大抑制处理,目标检测算法会给图片上所有物体产生多的候选框,候选框可能会相互重叠,非最大抑制就是保留最优的候选框。
3 结果分析
用A320飞机驾驶舱静态模型图片和计算机摄像头动态识别模型图片进行对比测试。先使用OpenCV的DNN模块加载Darknet模型配置和已经训练好的权重文件来做测试,检测识别单张图片所需要的时间约为16.01ms,如图2所示。用计算机摄像头近距离实时识别驾驶舱面板模型,截取随机一帧图片识别的时间约为13.74ms,如图3所示。用Yolo-Fastest模型进行检测识别单张图片需要438.992ms。可以看出,使用OpenCV的DNN模块部署深度学习模型识别面板字符的速度更快。

图2 OpenCV-DNN识别结果

图3 截取某一帧图片识别结果
4 结论
本文使用主流的Yolo系列目标检测算法,制作字符数据集并用Yolo-Fastest算法生成模型权重文件,在图片检测识别部分使用OpenCV实现神经网络的DNN模块,部署调用训练好的配置文件和模型权重文件,识别驾驶舱面板字符。从实验结果可以看出,该方法识别字符的速度较快,能够满足驾驶舱字符识别的实时性,具有一定的应用价值。
