基于单目视觉与深度神经网络的行为识别研究
2022-11-24刘兰淇刘钟涛
刘兰淇,刘钟涛
(河南财经政法大学 现代教育技术中心,河南 郑州 450046)
0 引言
随着互联网信息化时代的到来,光学图像处理及识别技术在人们日常生活与社会生产的多个领域表现出巨大的发展潜力。行为检测[1]是近年来目标检测领域的一个重要方向,吸引了大量研究人员的关注。目前,科研工作者在老人跌倒行为检测[2]、异常行为检测[3]、人群行为检测[4]以及驾驶行为检测[5]等任务上取得了一定的进展,这些解决方案大多基于视频序列而提出。传统基于视频序列的行为检测模型大多重点分析视频序列的关键帧,并结合光流法[6]提取目标的移动轨迹,可实现较高的行为检测准确性。随着深度学习技术的发展,许多研究人员利用深度神经网络模型学习视频序列的时域信息,进一步提高了基于视频序列的行为检测性能,其中较典型的神经网络模型有长短期记忆(Long Short-Term Memory,LSTM)[7]、循环神经网络(Recurrent Neural Network,RNN)[8]、门控循环单元(Gate Recurrent Unit,GRU)[9]等。
随机移动互联网的普及,单目视觉采集的单幅光学图像是目前常见的数据格式之一,相较于视频序列,检测单幅光学图像中的人体行为具有更广泛的应用空间。基于视频序列行为检测与基于单幅图像行为检测之间存在2个不同之处[10]:① 视频序列提供关键帧,而单幅图像中行为的显著性差异较大。② 视频序列可同时提取时域信息与空间信息,而静态图像仅能捕获二维空间有限的视觉信息。上述2点差异导致基于单幅图像的行为检测精度低于视频序列。
为提高基于单幅图像的多人场景行为检测精度,文献[11]从图像局部区域提取姿态特征,从整体图像中提取深度视觉特征,通过混合姿态特征与深度特征极大地提升了行为识别性能。该模型存在2点局限性:① 图像中需要包含完整的人体才可准确提取姿态特征;② 所提取的深度视觉特征容易受背景影响。文献[12]利用Kinect采集的关节点数据提高了姿态特征的鲁棒性,再分析5个重点区域的向量夹角离散化以表示不同的行为状态。该模型解决了使用单幅图像进行特征提取时容易受背景因素干扰的问题,但需要额外增加Kinect设备。文献[13]提出了一种由3个子网络构成的深度网络模型来挖掘单幅图像有限的视觉信息,通过多个代价函数训练深度神经网络,所提取的特征具有互补性,提高了基于单幅图像的行为检测精度。虽然该模型无需额外增加成像设备,但容易受背景干扰。文献[14]采用卷积神经网络(Convolutional Neural Network,CNN)提取图像中的成对目标关系,结合图像中目标特征与关系特征判断图像中的行为。该方法的优势是无需先验条件即可捕捉每对目标之间的潜在关系,该关系包含了目标的重要性与移动特征。文献[15]提取了人体的关节关键点与人体轮廓特征,该方法还考虑了目标的局部特征与强度变化信息以及目标间的距离关系,将多种特征融合来提高行为检测的性能。文献[16-17]提出了一种分层LSTM网络与并发LSTM网络,这2种网络均通过建模多人之间的交互关系,通过多人的关联关系来检测图像中的主要行为。分层LSTM网络重点关注目标间交互的动态变化信息,并发LSTM网络则重点关注目标间交互的静态信息。文献[18]提出了一种基于视觉特征词袋的行为检测模型,以检测出的时空兴趣点为中心建立基于多面体模型的时空梯度描述子,深入挖掘人体动作在时空上的视觉特征。文献[14-18]均通过CNN提取整个图像或视频帧的视觉信息,一些复杂的背景信息可能对前景目标产生干扰,进而导致目标行为识别性能下降。
本文提出了一种新的深度网络模型,该网络由3个子网络模块组成。通过神经网络提取单幅图像中的感兴趣区域(Region of Interest,RoI),且通过注意力机制筛选出最显著的RoI集。将RoI集与人体骨架关节点结合来表示单幅图像的行为,采用融合特征集训练CNN作为单幅图像的行为分类器。本文行为检测模型有2个优点:① 模型提取了行为相关的空间特征,排除图像中不相关信息对行为检测的影响,因此对背景变化具有鲁棒性。② 模型无需额外增加Kinect等设备来采集辅助信息,因此具有更广的应用范围。
1 模型总体结构
行为检测模型的主要框架如图1所示。

图1 模型总体结构
输入图像分别传入姿态估计模块与RoI检测模块,前者采用OpenPose网络输出图中所有人体的骨架关键点向量;后者提取图中所有的目标特征向量。最终,将2种特征向量聚合成特征矩阵传入CNN,CNN根据输入的特征矩阵预测输入图像中包含的人体行为。
2 多特征提取网络
2.1 姿势特征提取
光学图像传感器采集的单幅RGB图像传入姿势估计的OpenPose神经网络[19],该网络计算人体骨架的二维关节关键点。人体骨架25个关节关键点的位置如图2所示。

图2 人体骨架的25个关节关键点
2.1.1 基于OpenPose的姿势估计
采用开源的OpenPose网络估计单幅图像中的人体关节关键点,主要处理过程如图3所示。假设输入图像的大小为W×H,网络输出图中每个人体的关节关键点信息。OpenPose网络主要包含2个阶段:① 产生图像中的二维置信图集S;② 生成部件关联场(Part Association Field,PAF)向量集L。最终,通过分析置信图与PAF输出人体的二维关节关键点向量。OpenPose网络输出每个人体骨架的25个关节关键点,每个点包含了关节关键点在图像中的x和y坐标。

图3 基于OpenPose的姿势估计主要流程
2.1.2 置信图
输入图像传入CNN VGG-19生成特征图集合F,再将F传入CNN输出置信图集S与PAF集。可将置信图S表示为:
S=(S1,S2,…,SJ),
(1)
式中,J为OpenPose模型默认的身体部位总数量。置信图反映了指定身体部位出现在各像素的概率。如果输入图像中包含一个人体,那么每个置信图中应当存在一个峰值;如果包含多个人体,那么每个置信图中每个人体均存在一个峰值。
2.1.3 部件关联场
PAF集L保留了RoI的位置与方向信息。可将PAF集L表示为:
L=(L1,L2,…,LC),
(2)
式中,C为OpenPose模型默认的肢体总数量。元素Li为一个大小为W×H的特征图,包含了每对元素的方向信息。
2.2 目标特征提取
单幅图像中前景目标也包含人体行为相关的信息,本文设计了新的目标RoI检测网络模型,其主要结构如图4所示。

图4 RoI检测网络
2.2.1 区域候选网络
将区域候选网络(Region Proposal Networks,RPN)重新在实验数据集上训练,通过VGG-16网络模型提取图像的深度特征,这些特征输入RPN生成初始化区域候选(Region Proposal,RP)。
2.2.2 方向感知分类网络
训练阶段将每个RP与一个正定边框关联:如果RP与正定边框之间交并比(Intersection of Union,IoU)大于等于0.5,那么认为该RP为前景目标,并将其属性设为正定边框的类标签与边框偏差值;如果0.1≤IoU<0.5,那么认为该RP为背景。本文模型对RP的分类标签有人体、目标与背景。
采用RoI池化机制将所有特征池化成固定大小,然后将特征输入2个全连接层,全连接层分别负责目标分类与边框回归。
(1)目标分类。采用交叉熵代价函数作为目标分类的代价函数,该代价函数可表示为:
(3)
式中,pf为该RP预测为目标的概率;uf(i,j)为类标签,uf(i,j)={1,0,0}表示人体,uf(i,j)={0,1,0}表示RoI,uf(i,j)={0,0,1}表示背景;nf=3为分类数量;nb为每个batch包含的RP数量。
(2)边框回归。通过边框回归来确定目标的位置,边框回归的代价函数可表示为:
(4)
式中,pb=(px,py,pw,ph)为预测的边框偏差;ub=(ux,uy,uw,uh)为正定边框偏差;δi为指示变量,其值等于1与0分别对应目标与非目标,该指示变量的作用是在训练过程中忽略背景与人体部分;S()为平滑函数,定义如下:
(5)
将上述2个代价函数结合成神经网络的总代价函数,可表示为:
(6)
式中,α与β为权重因子,决定了2个子代价函数的重要性,本文取α=β=0.5。
2.2.3 注意力机制
采用自下而上(Bottom-up)的注意力机制为每个RP产生一个空间注意力图,该注意力图有助于利用与人体行为相关的信息,忽略不相关的信息,引入注意力机制有助于提高行为检测的准确性。自下而上注意力机制的网络结构如图5所示。

图5 自下而上注意力机制的网络结构
每个输入图像经过RPN生成若干个RP,假设生成的RP数量为N,通道数量为K,每个区域的大小为M×M,每个图像生成N×K×M×M的数据量。自下而上注意力机制使用1×1卷积层将每个RP的所有通道融合,1×1卷积层的运算可表示为:
sk=wT⊙Xk,
(7)
式中,Xk为池化的RP特征;wT为注意力权重;sk为自下而上的注意力图。
注意力机制通过训练学习最优的特征通道组合,最终产生一个空间注意力图sk;然后将sk与每个通道相乘获得一个加权的RP特征集:
X′k=sk·Xk,i,
(8)
式中,Xk,i为RP特征集的第i层;X′k为空间加权的RP特征集。
3 卷积神经网络
由于骨架关节点向量(姿势特征提取)的维度为25,因此将RoI目标向量(包含目标分类与边框信息)的末尾元素填充0,将RoI向量维度扩展成25。将聚合后大小为25×n的特征矩阵传入CNN进行处理,识别单幅图像中的行为。
CNN各神经层的参数如图6所示。

图6 行为识别的CNN结构
第1层卷积层的大小为25×16,dropout=0.5;第2层最大池化层对特征图进行正则化并减少数据量;第3层卷积层的大小为12×128,dropout=0.4;第4层最大池化层对特征图再次进行正则化并减少数据量;第5层卷积层的大小为6×50;第6层平均池化层将特征图平坦化成一维数据;最终,Softmax层预测输入图像中包含的人体行为。
4 实验结果与分析
4.1 实验环境与参数设置
实验环境为Intel i7 6700HQ处理器,16 GB内存与NVidia GTX 960M GPU,操作系统为Ubuntu 14.04。
本文3个网络模型的相关参数设置如下:
① 姿势估计网络:采取OpenPose作者推荐的参数配置,采用训练好的VGG-19[20]作为骨干网络,图像输入VGG-19网络,将网络前10层产生的特征图作为OpenPose网络的输入特征图。
② 目标检测网络:采用训练好的VGG-16[21]作为骨干网络,图像输入VGG-16网络,将网络第5个block、第3个卷积层输出的特征图作为目标检测网络的特征图。
③ CNN:隐藏层的激活函数为线性整流函数(Rectified Linear Unit,ReLU)。
4.2 行为检测实验数据集
在4个不同的单目图像行为识别数据集上验证本文模型的有效性,分别为Pascal VOC 2012数据集、Stanford40数据集、VCOCO数据集与MPII数据集。
① Pascal VOC 2012数据集共有4 588幅图像。该数据集为平衡数据集,共包含10个行为分类,每个分类均包含500幅图像。该数据集提供了推荐的训练集、验证集与测试集的版本,且提供了正定的类标签。
② Stanford40数据集共有9 532幅图像。该数据集为不平衡数据集,共包含40个行为分类,每个分类包含数量不等的图像。该数据集提供了推荐的训练集与测试集的版本,且提供了正定的类标签。
③ VCOCO数据集共有18 787幅图像。该数据集为不平衡数据集,共包含22个行为分类,每个分类包含数量不等的图像。该数据集提供了推荐的训练集与测试集的版本,且提供了正定的类标签。
④ MPII数据集共有15 181幅图像。该数据集为不平衡数据集,共包含398个行为分类,每个分类包含数量不等的图像。该数据集提供了推荐的训练集与测试集的版本,且提供了正定的类标签。
部分行为检测数据集的单幅图像实例如图7所示。图7(a),(b),(c)为单一行为检测图像数据,行为标签分别为drinking,feeding hourse,fixing car;图7(d),(e),(f)为多行为检测图像数据,行为标签分别为take photo,play instrument,Drink。

(a)图像1
4.3 神经网络训练
使用TensorFlow的Keras API搭建文中的神经网络模型,3个网络的参数设置方法如下:
① 姿势估计网络(OpenPose神经网络)的参数为关节关键点数量,实验将该参数设为25。该网络的复杂度为5层卷积层。
② 目标检测网络(RPN网络)的参数包括RoI数量、epoch数量、patch size和学习率参数。实验采用SGD优化器训练该网络模型,所有数据集训练的epoch数量均设为200。训练中采用64的patch size,Pascal VOC 2012数据集与Stanford40数据集的初始化学习率设为0.001,VCOCO数据集与MPII数据集的初始化学习率设为0.000 1,衰减因子为0.000 5。该网络的复杂度为5层卷积层。
③ CNN的参数包括epoch数量与patch size。实验采用SGD优化器训练该网络模型,所有数据集训练的epoch数量均设为100。训练中采用16的patch size。该网络的复杂度为3个卷积层与3个池化层。
4.4 模型参数设置
采用平均精度均值(mean Average Precision,mAP)作为行为检测的性能评估指标,计算式为:
(9)
式中,K为数据集的分类数量;APk为第k个分类的检测精度,计算式为:
(10)
式中,TP表示正类别判断为正类别的数量;FP表示负类别判断为正类别的数量。
为观察目标检测网络中的RoI数量对图像行为检测性能的影响,将RoI数量分别设为{5,10,15,20,25,30,35,40,45,50,55,60,65,70},观察本系统在各训练数据集上训练的mAP性能。各训练数据集上不同RoI数量所获得的mAP结果如图8所示。由图8可以看出,Pascal VOC 2012数据集、Stanford40数据集、VCOCO数据集以及MPII数据集分别在RoI数量为20,30,45,40时取得最佳的mAP性能。究其原因:Pascal VOC 2012数据集中的目标数量较少,大多图像中仅有单一人体,因此RoI池化所需的区域较少;Stanford40数据集中大多的图像也包含单一人体,而背景中包含复杂的纹理信息与视觉信息,因此RoI池化所需的区域多于Pascal VOC 2012数据集;VCOCO数据集与MPII数据集中大量的图像包含了多个目标,且包含体育馆、广场以及音乐会等常见地点,因此感兴趣目标数量较多,进而RoI池化所需的区域数量较多。实验将本文模型在各数据集上的RoI数量分别设为上述最优值。

图8 各数据集上不同RoI数量的训练结果
4.5 测试集实验结果与分析
4.5.1 对比模型介绍
本文行为检测模型与POHA[14],RSTF[15],HLSTCM[16],CLSS[17],FeatureBag[18]检测模型进行了比较实验。
4.5.2 量化实验结果
Pascal VOC 2012数据集每个行为类别的检测精度结果如图9所示。可以看出,POHA,RSTF,HLSTCM,CLSS与FeatureBag对“usecomputer”行为类别的检测精度较低,而本文模型对该行为的检测精度达到0.82,明显高于其他5种对比模型。HLSTCM网络与CLSS网络均通过建模多人之间的交互关系,通过多人的关联关系来检测图像中的主要行为,然而Pascal VOC 2012数据集的图像大多为单一受试者,所以难以发挥这2种网络的优势,因此其检测精度较低。

图9 Pascal VOC 2012测试数据集各类别的检测精度
4.5.3 消融实验结果
首先,通过消融实验评估2种特征对行为检测性能的影响,表1比较了RoI特征、姿态特征与融合特征3种网络模型在4个测试数据集上的mAP。由表1中结果可知,姿态特征的mAP较低,可见仅通过人体骨架特征难以准确检测人体行为。RoI特征包含了图像中前景目标丰富的视觉信息,因此RoI特征的mAP优于姿态特征。RoI特征与姿态特征融合的特征集不仅包含了人体骨架的特点,也包含了前景目标的视觉信息,所包含的行为相关信息更丰富,有利于提高行为检测的准确性。

表1 消融实验的mAP结果
4.5.4 对比实验结果
Pascal VOC 2012数据集行为检测的mAP如表2所示。观察表2中结果可以发现,HLSTCM网络与CLSS网络对单一受试者的检测精度较低,POHA,RSTF与FeatureBag对单一受试者的检测精度则较高。本模型通过神经网络提取了行为相关的空间特征,排除图像中不相关信息对行为检测的影响,本模型在Pascal VOC 2012数据集上的平均检测精度达到0.954,高于其他5种对比模型。

表2 Pascal VOC 2012数据集的检测结果
Stanford40数据集行为检测的mAP如表3所示。观察表3中结果可以发现,HLSTCM网络与CLSS网络在Stanford40数据集上的平均检测精度较低。因为Stanford40数据集的图像大多为单一受试者,难以发挥这2种网络的优势,所以检测精度较低。POHA,RSTF与FeatureBag对单一受试者的检测精度则明显高于HLSTCM网络与CLSS网络。本模型在Stanford40数据集上的平均检测精度达到0.927,高于其他5种对比模型。

表3 Stanford40数据集的检测结果
VCOCO数据集行为检测的mAP如表4所示。观察表4中结果可以发现,POHA,RSTF与FeatureBag在VCOCO数据集上行为检测的mAP较低。VCOCO数据集的图像中包含多人,且拍摄场景较大。HLSTCM网络与CLSS网络均通过建模多人之间的交互关系,通过多人的关联关系来检测图像中的主要行为,对多人场景的检测精度则较高。本模型通过神经网络提取单幅图像中的RoI,且通过注意力机制筛选出最显著的RoI集,通过结合人体骨架关节点与显著RoI集能更准确地表示图像中的行为。本模型在Pascal VOC 2012数据集上的平均检测精度高于其他5种对比模型。
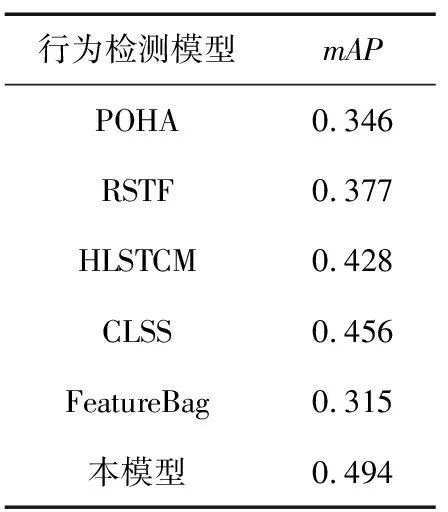
表4 VCOCO数据集的检测结果
MPII数据集行为检测的mAP如表5所示。观察表5中结果可以发现,POHA 在MPII数据集上行为检测的mAP较低。MPII数据集同时包含单人图像与多人图像,其行为类别数量高达398个,且该数据集为不平衡数据集,因此该数据集的检测难度极大。各检测算法在该数据集上的平均检测精度均大幅降低,本模型的平均检测精度为0.363,略高于其他5种对比模型。

表5 MPII数据集的检测结果
本文方法也存在识别失败的情况,MPII数据集包含398个行为分类,每个分类包含数量不等的图像,并且分类之间的相似性较高。图10(a),(b)分别为“Bicycling”与“Unicycling”分类中的一幅图像,图10(c),(d)分别为“aerobic”与“Irish step dancing”分类中的一幅图像。因为图10(a),(b)的相似性较高,本文方法将图10(a)错误识别为“Unicycling”分类,将图10(c)错误识别为“Irish step dancing”分类。

(a)Bicycling分类
5 结束语
本文提出一种新的行为检测模型,用以提高多人场景下的行为检测精度。该模型通过神经网络提取单幅图像中的RoI,借助注意力机制筛选出最显著的RoI集,结合人体骨架关节点与显著RoI集来提高对图像中行为的表达能力。本文模型无需额外增加Kinect等设备来采集辅助信息,因此具有更广的应用范围。该模型在4组不同场景的数据集上完成了训练实验与测试实验,均获得了较高的行为检测精度。
