Python文本分析技术在建设项目招投标审计中的应用
2022-11-24武琼卢婧襄阳市审计局
◆武琼 卢婧/襄阳市审计局
在政府投资审计中,建设项目招投标环节的审查是一项重点内容。传统的审计方法是人工比对非结构化招投标文件,查找围标串标问题线索,不仅耗费大量人力、时间,而且比对结果主观性较强,缺乏数据支撑。襄阳市审计局在某政府投资审计项目中,运用OCR文字识别技术将非结构化招投标文件转化为结构化文本数据,并使用Python进行文本分析比对,精准定位疑点线索,高效解决审计难题。本文以该审计项目为例,介绍Python文本分析技术在建设项目招投标审计中的具体应用。
一、文本数据转换
根据项目特性,确定目标文本。经初步审查,该政府投资审计项目招投标环节可能存在围标串标的问题。因文件综合报价未呈现规律性差异,审计人员选取投标文件中项目实施方案作为目标文本,比对是否存在投标文件雷同的情况,精准定位疑点线索。首先扫描文档,进行图像预处理和必要的修正,然后使用OCR文字识别系统提取文本数据,将图像批量转换为文本文件,最后进行数据清洗,校核文本数据逻辑性、准确性,并整理为格式统一、规范的电子文档。
二、Python文本分析
使用Python进行文本分析步骤如图1所示。
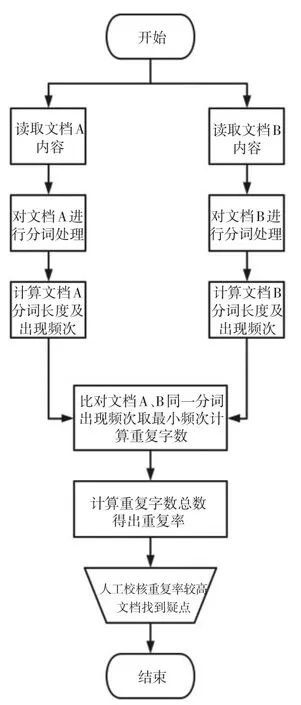
图1 文本分析流程图
(一)文本数据分词
该政府投资审计项目招投标环节的审查需分析12个投标文件中的项目实施方案,进行66次两两对比,算出相似比。因每份实施方案均在1万字以上,文本数据体量大,使用传统审计方法比对投标文件是否存在雷同,工作量大、难度高、主观性强、效率低下,因此考虑利用Python进行批量自动化文本比对。为实现文本数据分词和统计,首先利用docx模块,获取文档中的文本数据,再利用jieba模块对文本进行分词,将文档内容分割为若干词组、短语。一般认为,单字组成的词(如虚词“的”“了”)没有比对意义,因此我们只统计所有长度大于1的词组出现次数。其主要代码如下:

(二)文本数据分析
审查不同投标单位投标文件是否存在雷同,需计算文本数据两两之间相似比。相似比采用如下方式计算:假设比对的文档分别为A和B,如果某词组长度为2,在A文档中出现3次,B文档中出现5次,则该词组造成A、B文档间的重复字数为词组长度乘以两篇文档出现次数的最小值,即重复字数为6(2×3)个字。遍历比对A、B两个文档中所有出现过的词组,将所有重复出现词组字数累加,即得到总重复字数。用总重复字数作分子,取A、B文档总字数的最小值作分母,两者相除,得到最终的相似百分比。算法公式如下:

通过OS模块获取12个文档的文件名,即可实现对所有文档的批量读取和循环比对,得到66组文档的相似百分比。主要实现代码如下:


三、应用效果
在本次政府投资审计项目中,审计人员对投标文件中项目实施方案运用Python数据分析方法计算相似比,结果发现,相似比率50%以上的有16组,最高达65.82%。对这16组文档进行人工核实后发现,均存在文件雷同的问题,该算法的问题定位精准率达100%。
本次审计项目中对Python数据分析方法的尝试,是做实研究型审计的一次探索和实践,丰富了审计工具库,降低了人工成本,提升了审计工作质效,并为今后类似工作的开展提供了借鉴意义。
