面向内存受限设备的新型卷积计算方法
2022-11-23孙雁飞王子牛董振江
孙雁飞,王子牛,孙 莹,亓 晋,董振江
(1.南京邮电大学物联网学院,江苏 南京 210003 2.南京邮电大学江苏省高性能计算与智能处理工程研究中心,江苏 南京 210023 3.南京邮电大学自动化学院、人工智能学院,江苏 南京 210023 4.南京邮电大学计算机学院,江苏 南京 210023)
卷积神经网络因其出色的特征提取能力,在图像分类、目标检测、语义分割等计算机视觉领域被广泛应用并发挥重要作用[1-2]。但卷积神经网络需要较高的计算复杂度和内存消耗量,通常部署在云端进行计算,这在一定程度上限制了卷积神经网络的应用场景。近年来,随着物联网设备的普及,这些设备产生的数据量呈现爆炸式增长,给云端计算带来极大的负担。此外,将数据传输到云端进行计算也带来了数据安全和响应延迟等问题[3]。为解决上述问题,边缘智能的概念被提出[4-5],并广泛应用于预测性维护、精准农业、智慧城市等领域。
边缘智能是边缘计算和人工智能的结合,当前研究主要集中在轻量级推理框架[6-7]和轻量级卷积神经网络[8-9]。轻量级推理框架提供了在边缘设备上部署卷积神经网络的方法;轻量级卷积神经网络研究高效的网络结构,降低卷积神经网络对算力和内存的需求。因此,如何将卷积神经网络部署在边缘设备并进行低复杂度、小内存计算,已成为当前的研究热点。
尽管在边缘设备上部署卷积神经网络成为可能,但对于内存受限的边缘设备如微控制器、数字信号处理器等,其内存小于1 MB,难以满足卷积神经网络的内存需求。此外,内存使用量的增加使得SRAM(Static Random Access Memory)的漏电流增大[10],从而缩减这些设备的续航时间。因此,有必要进一步研究降低卷积神经网络内存使用量的方法,从而满足边缘设备的内存约束条件。因此,本文旨在面向内存受限设备,提出一种低内存使用的新型卷积计算方法。
1 相关工作
目前降低卷神经网络内存使用量的研究主要集中在轻量化卷积神经网络,通过设计特殊的卷积操作,降低网络结构的冗余,从而减少内存使用量。然而,卷积神经网络的内存使用量不仅取决于卷积神经网络结构,还取决于组成卷积神经网络的卷积算子计算方法,不同计算方法的内存使用量可以相差数十倍,有必要研究降低卷积计算内存使用量的方法。现有卷积计算方法主要包括直接卷积、im2col+GEMM卷积和快速卷积等。
(1)直接卷积:直接卷积根据卷积算子的定义,通过几层嵌套循环进行计算,输入矩阵中灰色窗口与卷积核的内积即为输出的一个元素,存放在输出矩阵中对应位置。灰色窗口按照步长参数从左到右,从上到下滑动,依次计算出对应位置输出结果,直至计算完全部数据。使用该方法卷积时只需分配存放输出矩阵的内存空间,如图1所示。

图1 直接卷积
文献[11]通过动态编译方法在x86架构上优化直接卷积实现,其性能接近于理论水平;文献[12]通过优化直接卷积数据布局和计算中的循环顺序,提高了直接卷积的计算速度。然而上述方法并未降低直接卷积的内存使用,难以部署在内存受限设备上。
(2) im2col+GEMM 卷积:该方法依靠 im2col转换将卷积问题转化为通用矩阵乘(General Matrix Multiplication,GEMM)问题,利用高度优化后的线性代数库,如 MKL、BLAS等加速卷积计算[13]。 该方法被主流深度学习框架如 TensorFlow、Pytorch、Caffe、MxNet等深度学习框架采用作为卷积计算方法[14]。im2col将输入矩阵中滑动窗口内元素展开成行向量,将卷积核展开成列向量,分别存储在两个中间矩阵中,这两个矩阵的乘积即为输出矩阵,如图2所示。
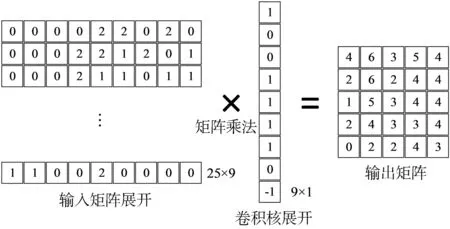
图2 im2col+GEMM 卷积
基于im2col+GEMM的方法需要构造中间矩阵,空间复杂度为 O(K2CHW), 其中 K、C、H、W 分别表示卷积核高或宽、输入通道数、输出矩阵高、输出矩阵宽。对于3×3的卷积核,输入矩阵中每个元素被复制9次,即输入矩阵转换后的中间矩阵内存使用量变为原来的9倍。基于im2col+GEMM改进的方法,如 MEC[15]、MFCA[16]等,有效降低了中间矩阵的大小,但相较于直接卷积方法仍需要大量额外内存空间存放中间矩阵,因此并不适用于内存受限设备。
(3)快速卷积:该类方法主要包括FFT(Fast Fourier Transform)[17]和 Winograd[18]方法,通过将输入矩阵和卷积核映射到对应的FFT空间和Winograd空间,将计算转换成对应元素相乘,再将结果逆线性变换映射到原空间即可得到卷积计算输出,从而减少卷积计算的计算量。然而此类算法由于其内在的数值不稳定性,导致计算精度降低,仅适用于单位步长和卷积核小的情况。文献[19]在Winograd的基础上提出使用超线性多项式来构造变换矩阵,提高了计算精度,缓解数值不稳定性。但基于快速卷积的方法仍需额外的内存存储输入矩阵和卷积核映射后的空间以及映射空间中的计算结果,同样也不适用于内存受限设备。
此外,内存共享优化[20]被广泛用于TensorFlow、Caffe、MXNet等深度学习框架,通过记录卷积神经网络中间各层输出的大小和生命周期,回收不再使用中间结果的内存并用于其他层,从而降低卷积神经网络的内存消耗。内存共享优化属于卷积神经网络中不同层之间的内存优化,并不涉及层内卷积计算方法,本文方法属于层内的卷积计算优化方法,两者可以组合使用,进一步优化内存使用量,即混合内存重用策略[21]。
综上所述,现有卷积计算方法主要对卷积计算速度进行优化,通过使用额外的内存空间加速卷积计算过程,在此基础上研究降低卷积内存使用量方法,但对于内存资源受限的设备来说,无法承担这种优化带来的额外内存开销。针对上述问题,本文提出一种面向内存资源受限设备的新型卷积计算方法,与直接卷积方法类似,根据卷积算子的定义直接进行卷积计算,但计算结果存放在输入矩阵中,从而降低卷积计算的内存使用量;与im2col+GEMM卷积和快速卷积不同,本文方法无需构造中间矩阵,避免大量的内存使用,大幅降低卷积计算的内存使用量。
2 算法实现
针对现有卷积计算方法内存使用量大,难以满足内存受限设备的内存约束的问题,本节将对卷积计算内存使用量进行优化,阐述通过复用输入矩阵内存从而降低卷积计算内存使用量的一种新型卷积计算方法,并给出以下几种卷积计算的具体实现方法。
2.1 标准卷积
该算法对输入矩阵滑动窗口对应的部分与卷积核直接进行卷积计算,并将计算结果存放在输入矩阵中,避免或减少分配输出矩阵的内存。如图3所示,对于输入矩阵 I(ih×iw×ic=6×6×1),卷积核K(kh×kw×kc=3×3×1),其中下标h、w、c分别表示对应矩阵高、宽和通道数。滑动窗口每次滑动计算完结果后,窗口左上角元素在后续计算中不会被再次使用,因此可将计算结果存放在对应窗口左上角位置,继续滑动窗口直至计算完全部输入矩阵,此时输入矩阵中存放着输出矩阵的内容,输入矩阵变为输出矩阵,不再需要额外分配内存存放输出矩阵,从而降低卷积过程内存使用量。图中浅灰色部分表示尚未计算的区域,深灰色部分表示正在计算的区域。

图3 标准卷积计算方法示意图
在更一般的情况中,若输入矩阵为I(ih×iw×ic),卷积核为 K(kh×kw× kc),输出矩阵为O(oh×ow×oc)时,可以分为两种情况讨论,用Mem表示矩阵占用内存的大小。
情况一:MemI≥MemO,此时输入矩阵可以存放全部计算结果,按照如下步骤计算卷积。
①分配内存空间m,大小为h×ow×oc(h≥「kh/2⏋), 临时缓存计算结果,如图 4(a)所示。
②计算输入矩阵中深灰色行卷积,计算结果存放在m中,如图4(b)所示,其中第一行虚线框表示卷积计算时padding填充部分示意,并不占据实际内存空间。
③此时输入矩阵中白色行的输入数据将不再被后续计算使用,将m中对应行的计算结果复制到该位置,如图4(c)所示,白色部分存放卷积计算结果。值得注意的是,当kh>1时,输入矩阵中深灰色行除了参与以当前行为卷积中心的计算外,还会参与以相邻行为卷积中心的计算,因此不能直接将深灰色行的输入数据直接覆盖。
④ 重复步骤②、③,如图 4(d)、(e)所示,直至计算完全部输入矩阵。
⑤计算结束后的结果如图4(f)所示,此时卷积后的结果全部存放在输入矩阵中,卷积计算完成。

图4 标准卷积计算方法情况一
情况二:MemI<MemO,此时输出矩阵通道数大于输入矩阵通道数,按照如下步骤计算卷积。
①分配内存空间m,大小为h×ow×oc(h≥「kh/2⏋);分配内存空间 M, 大小为 Memo- Memi,如图 5(a)所示。
②计算输出矩阵比输入矩阵多出来的通道,采用直接计算方法,计算结果存放在M中,如图5(b)所示。
③忽略多出来的通道数和内存空间M,按照情况一的步骤②~④执行,如图5(c)所示。

图5 标准卷积计算方法情况二
④最终计算结果结果如图5(d)所示,此时计算结果分为两部分存放,分别存放在输入矩阵和内存空间M中,卷积计算完成。
标准卷积计算方法的算法描述如算法1所示。
算法1 标准卷积计算方法

2.2 深度卷积
深度卷积的输入通道个数与卷积核数量一致,输入通道与对应卷积核进行卷积计算,结算结果为对应输出通道,输入输出通道数保持一致。深度卷积计算可以看作多个通道数为1的标准卷积组合,因此可以使用上述提出标准卷积的计算方法。使用深度卷积时,输入通道数和输出通道数相等,输出尺寸小于或等于输入尺寸,因此并不需要分配内存空间M,即深度可分离卷积只需要采用标准卷积中情况一的计算方法。
2.3 点卷积
点卷积可以看作标准卷积中kh=kw=1的情况。点卷积计算不涉及输入矩阵中相邻行列的值,输入矩阵中对应位置数据计算完后将不再使用,因此,与标准卷积计算不同,点卷积计算时不再额外分配内存空间m,计算结果可以直接存放在输入矩阵中。点卷积计算方法如图6所示,左上角元素与点卷积核计算后计算结果直接存放在原来位置,图中输入输出矩阵为同一块内存空间。当MemI<MemO时,仍需分配内存空间M存放额外的输出结果,其大小为MemO-MemI。
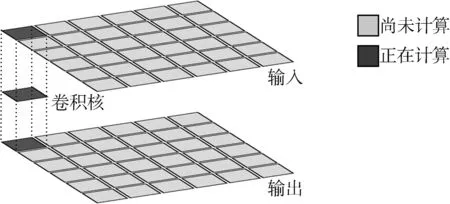
图6 点卷积计算方法
除了上述几种卷积计算外,本节还提出一种降低卷积神经网络中池化计算内存使用量的方法。池化计算方法如图7所示,上层矩阵为输入矩阵,下层为输出矩阵,池化窗口每次移动计算后的结果依次存放在输出矩阵对应的位置上。由于计算后输入空间中对应区域的数据将不再被后续计算用到,即图中白色区域,因此该区域可以依次存放其他位置的池化结果。值得注意的是,图7中上下两层矩阵实际上是同一块内存不同时间上的状态,在池化计算前代表输入矩阵,池化计算结束后代表输出矩阵,因此本节提出的池化计算方法不需要使用额外内存。

图7 池化计算方法
3 实验分析
实验测试硬件平台选择在内存资源受限的微控制器上进行,选用微控制器的型号为STM32H750VBT6,主频为480 MHz,测试内存包括DTCM(Data Tightly⁃Coupled Memory)和 SRAM,其中DTCM大小为128 KB,与微控制器内部CPU直接连接,访存速度较快;SRAM大小为512 KB,通过AXI总线与CPU相连,访存速度较慢。使用C++实现本文提出的卷积计算方法和其他对比方法。由于这类内存资源受限的设备通常没有GPU等硬件加速功能,因此基于im2col+GEMM方法的卷积实验和其他方法均使用微控制器内部CPU进行计算。
3.1 实验设置
实验测试数据包括单个卷积测试和LeNet[22]卷积神经网络测试,并分别对其进行内存使用量分析和性能分析,验证本文提出方法的有效性。其中单个卷积测试集参考文献[15]给出的测试集,测试集信息如表1所示。

表1 测试集信息
3.2 内存使用量分析
单个卷积测试集内存开销大小如表2所示,其中内存使用量包括卷积计算过程中的额外内存使用量和输出矩阵的内存使用量,不包含输入矩阵和卷积核的内存使用量, Mim2col、MMEC、Mdirectconv和 Mours分别表示im2col+GEMM、MEC、直接卷积和本文方法内存使用量大小,单位为字,即单个float32类型参数的内存大小。
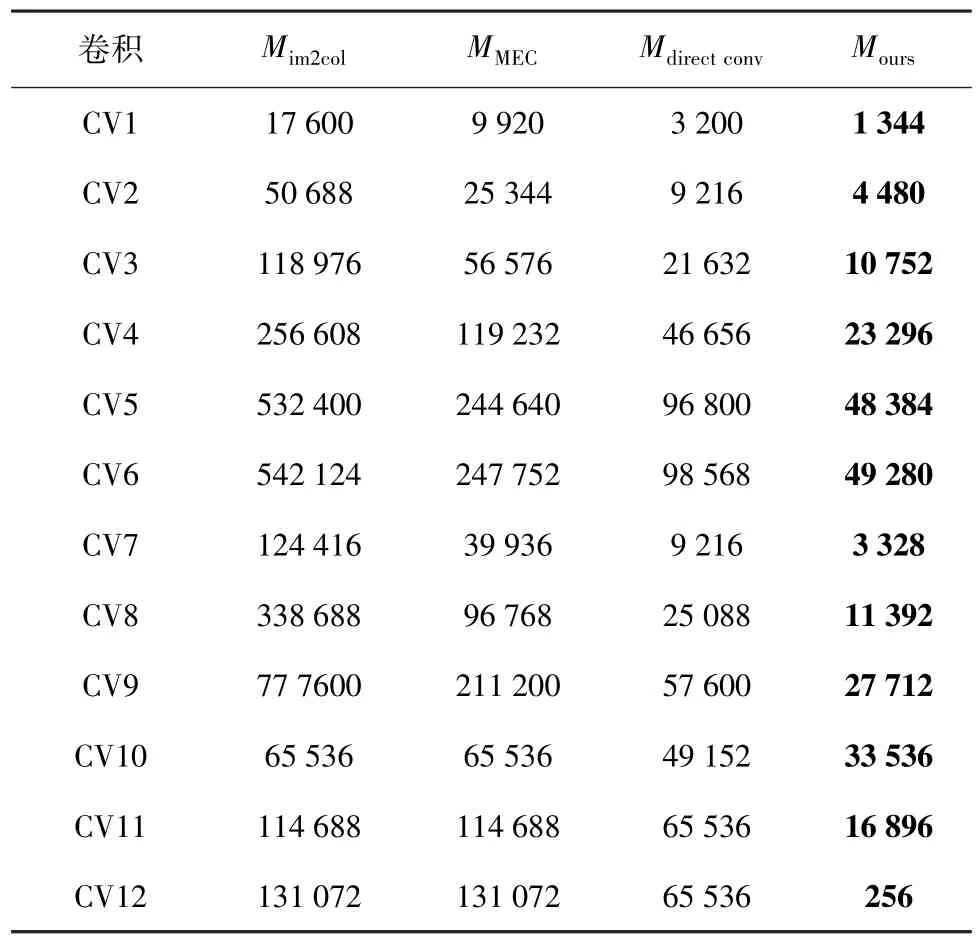
表2 单个卷积计算内存使用量对比
从表2中可以看出,本文方法明显优于其他几种卷积方法,大幅减少卷积的内存使用量。对比其他几种方法,本文方法的平均内存使用量分别下降89.29%、82.60%和57.15%,减少的内存使用量主要是由于对输入矩阵内存空间进行复用,减少分配输出矩阵内存大小,同时避免构造中间矩阵使用量额外内存。以CV1为例,im2col+GEMM方法需要构造输入矩阵的中间矩阵,内存大小为14 400字(oh×ow×kh×kw×ic),分配输出矩阵,内存大小为3 200字(oh×ow×oc),共计需要17 600字内存;MEC方法需要构造输入矩阵的中间矩阵,内存大小为6 720字(oh×kh×ih×ic),分配输出矩阵,内存大小为3 200字,共计需要9 920字内存;直接卷积方法无需构造中间矩阵,仅需分配3 200字的输出矩阵;本文方法需要分配内存空间m,大小为1 280字 (「kh/2⏋× ow× oc), 此外还需要分配内存空间M,大小为64字(Memo-Memi),共计需要1 344字内存。为方便对比,对表2中几种方法内存的使用量用直方图进行比较,以im2col+GEMM算法的内存使用量为基准,结果如图8所示。

图8 几种卷积方法的内存开销柱状图比较
除了对单个卷积进行实验分析外,本文还对经典卷积神经网络LeNet进行实验分析。LeNet是一种用于数字识别的卷积神经网络,其结构简单,内存消耗少,方便对不同的卷积计算方法进行分析。表3为LeNet卷积神经网络结构参数及不同卷积计算方法的内存开销对比。
由于卷积神经网络输入为图片,第一层卷积无法使用输入空间存放卷积结果,因此本文方法在第一次卷积时和直接卷积采用相同的方式,分配输出矩阵,大小为4 704字(oh×ow×oc)。 池化计算采用本文提出的池化计算方法,因此该网络中池化计算并不使用额外的内存。从表3中可以看出对于LeNet卷积神经网络,本文方法相较于上述其他几种方法内存使用量分别下降89.90%、82.21%和28.07%。

表3 LeNet卷积神经网络的内存使用量对比
3.3 性能分析
为验证本文算法对卷积计算性能的影响,本文还对不同卷积计算方法的计算时间实验测试,分别对单个卷积和LeNet卷积神经网络进行实验测试,测试结果分别如表4和表5所示。
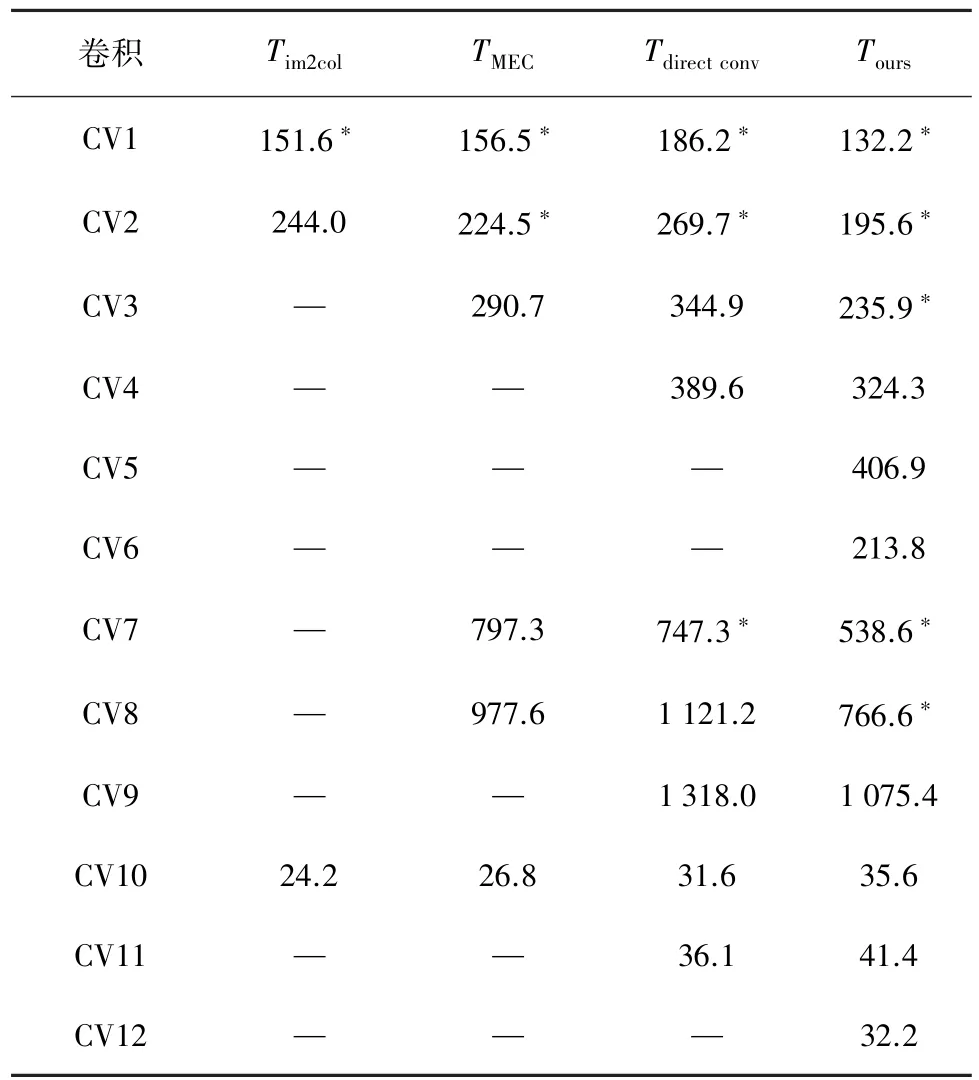
表4 单个卷积计算时间对比 ms

表5 LeNet卷积神经网络的计算时间对比 ms
表4 中 Tim2col、TMEC、Tdirectconv和 Tours分别表示im2col+GEMM、MEC、直接卷积和本文方法计算单个卷积的时间,时间单位为ms。对于测试集中单个卷积计算内存使用量小于128 KB的卷积,放在访存速度较快的DTCM内存中计算,即表4中标记“∗”的位置;若卷积计算内存使用量大于512 KB则无法在该设备上进行计算,在表4中以“—”表示;其他情况下均在SRAM内存中进行卷积计算。虽然本文方法需要额外复制数据造成时间上的开销,但得益于使用较少的内存提高缓存命中率和更有效利用DTCM内存,从表4中可以看出,实际平均计算时间相较于其他方法较快。此外其他卷积计算方法内存使用量部分超出实验设备限制,无法完成全部计算,而本文方法能够完成测试集中全部卷积计算,为内存资源受限设备运行卷积神经网络提供更多的选择。
表5为LeNet卷积神经网络各层计算时间的对比,单位为ms,其中直接卷积和本文方法内存使用量均小于128 KB,在DTCM中进行计算,用“∗”表示;im2col+GEMM和MEC方法内存使用量均大于128 KB,在SRAM中进行计算。
综合表3和表5可以看出,虽然使用本文方法计算LeNet卷积神经网络相较于im2col+GEMM和MEC方法计算时间分别增加2.31%和19.93%,但内存使用量分别下降89.90%和82.21%;而对于直接卷积方法,本文方法计算时间在下降6.98%的同时,内存使用量下降28.07%,优势较为明显。此外本文提出的池化层计算方法较标准池化计算方法计算时间增加14.29%,但总计仅增加0.04 ms的计算时间,对整个卷积神经网络而言可以忽略不计。综合以上实验分析,验证了本文提出的卷积计算方法的有效性,大幅降低了卷积计算的内存使用量。
4 结束语
本文提出一种面向内存资源受限设备的卷积计算方法,卷积计算时对输入矩阵计算后不再使用的内存空间进行复用存放计算结果,从而减少分配新的内存空间存放计算结果,达到降低内存使用量的目的,使得在内存资源受限的设备上可以运行更复杂的卷积神经网络。实验结果验证了本文方法的有效性,相较于其他方法均大幅降低内存使用量,对于一些内存使用量较大的卷积,其他方法均无法在有限的内存中完成卷积计算,而本文方法可以完成卷积计算,对于卷积神经网络在内存受限设备上的部署运行具有重要意义。
