新兴技术识别中的不均衡分类研究
——基于代价敏感的随机森林算法
2022-11-23卢小宾张杨燚杨冠灿行佳鑫
卢小宾,张杨燚,杨冠灿,行佳鑫
(中国人民大学信息资源管理学院,北京 100872)
1 引言
随着大数据的积累和全球化竞争的加剧,新兴技术识别(emerging technologies identification)对于科技创新、竞争情报等相关领域的战略意义日益凸显。专利通常是一项技术诞生时寻求垄断权利保护的有效和必要方式,大规模的专利数据包括了技术相关的各种关键信息,为新兴技术的早期预测与识别积累了丰富而有价值的数据基础。针对大规模的海量专利数据实现自动化的前瞻性预测逐渐成为新兴技术识别的研究重点和发展趋势,尤其是基于专利指标体系的机器学习分类预测,目前已被广泛地应用于新兴技术识别的各种场景。
然而,在新兴技术识别这一复杂问题中,多数研究都关注如何根据特征工程构建更完善的专利指标以捕捉新兴技术的特征信息,却忽略了以专利为代表的海量技术发明涌现为新兴技术这一事件往往具有小概率的特征,是一种典型的不均衡数据分类问题,其预测效果也会受数据集正负样本分布不均衡因素等影响,出现分类结果偏向多数类的现象,无法实现成功预测少数新兴技术涌现的理想效果。传统研究中,为了规避数据不均衡对新兴技术识别效果的制约,多在数据采集阶段通过一系列人工的操作,获取经人工筛选后的均衡数据集,使机器学习的过程可以运行。但随着当前自动化专利推荐、新兴技术识别趋势的兴起,如何改进与优化分类策略以提升机器学习面临新兴技术识别中不均衡分类问题的表现,实现在大规模数据上对新兴技术进行自动化的识别,成为制约基于机器学习的新兴技术识别效果的瓶颈。
本研究聚焦于机器学习方法在新兴技术识别中面临不均衡分类问题的应用,以预测癌症药物领域专利是否有成为新兴技术潜质的二分类场景为例,在数据层面比较渐进式采样思路对分类结果的影响,在评估层面引入代价敏感学习,探究在缺乏专家经验时的代价矩阵验证方式,并将其应用于算法层面和决策评估的改进。最终在此不均衡分类优化的研究框架下,通过对分类预测效果的有效评价,尝试在数据、算法和评估三个层面综合实现更好地处理不均衡问题的改进分类策略,解决新兴技术识别场景下不均衡分类的预测问题。
2 相关研究
2.1 新兴技术识别研究进展
新兴技术(emerging technologies)的概念最早由沃顿商学院Geroge等学者于2000年出版的Wharton on Managing Emerging Technologies中提出,该书将其明确归纳为“在科学理论或实践基础上,具有新兴行业开辟或者现有行业颠覆意义的创新型技术”[1]。早期的新兴技术研究多聚焦于文献或专利数据,但以往思路往往只能实现对已存新兴技术的事后评价而非预测性识别[2]。以德尔菲法(Delphi method)为典型的传统预测性研究也因对领域经验和精力的高要求以及缺乏直接数据支撑解释而不适用于当前大多数的预测情景[3]。当前,新兴技术识别的需求处于调整过程中,基于大规模数据的实时预测正在成为新兴技术识别的重点及趋势。目前,新兴技术识别的定量研究主要方法如表1所示。

表1 新兴技术识别的主要方法
2.2 机器学习中的不均衡分类问题
机器学习的分类方法能将新兴技术识别问题转化为分类预测问题,推动新兴技术由传统的回溯性分析转变为前向的预测性分析,已被广泛地应用于新兴技术识别的各种场景[9]。不均衡分类是数据分布复杂性导致的一种特殊分类场景[10],在不均衡分类问题中,原始数据里不同类别的样本比例差距很大,由于少数类通常反映出更受重视的信息,是研究的重点,因此,将少数类记作正类,多数类记作负类[11]。在机器学习模型的训练过程中,数据不均衡分类主要面临几个方面问题[12]:少数类样本的稀缺性,包括少数样本自身稀少的绝对稀缺和少数样本自身不少但多数样本过多的相对稀缺[13];难以区分噪声数据与少数类数据的特征及差异,去噪工作难度大[14];以总体分类效果为学习目标的分类器出现倾向于多数类的偏向性[15];以整体指标(accura‐cy)评估模型缺乏价值。
2.3 不均衡分类问题的优化研究
针对不均衡分类现象,目前主要从数据层面、算法层面和评估层面改进分类模型的少数类预测能力。
(1)数据层面。对于不均衡分类数据集,可在进行模型训练之前,将重采样方法用于数据预处理以更改数据分布比例,达到均衡数据集训练分类器的目标。目前,重采样方法主要有扩充少数类数据的过采样和减少多数类数据的欠采样。常见的过采样技术包括随机过采样方法(random oversampling)[16]、SMOTE(synthetic minority oversampling technique)算法[17]、边界过采样(borderline-SMOTE)[18]、自适应合成采样(adaptive synthetic sampling,ADASYN)[19]等。常见的欠采样技术有随机欠采样(random un‐dersampling)[20]、cluster centroids欠 采 样[21]、near miss欠采样[22]、Tomek links[23]。近年来,针对图像、视频方面的数据不均衡问题,生成对抗网络(gen‐erative adversarial network,GAN)可以被用于数据增强,如研究显示经过多重伪类生成对抗网络(multiple fake classes GAN,MFC-GAN)[24]、条件生成对抗网络(conditional GAN,cGAN)[25]数据增强后的分类效果都得到了显著提升。
(2)算法优化。常用的分类算法在不均衡分类中,往往由于不均衡分类的特征表现出对少数类较弱的预测能力。集成学习的思想是通过不同的选举方法,将多个弱分类器组合成一个最终学习效果显著提升的强分类器[26]。目前,提升(boosting)和装袋(bagging)是较为经典的两种技术手段[27],构建元模型来融合多个学习器的堆叠(stacking)思想也得到了部分应用。但集成学习的目标仍然是提升总体学习准确率,在极度不均衡分类中不能解决根本性问题[28]。深度强化学习模型(deep reinforcement learning,DRL)[29]通过设计给予少数类样本较大激励函数的方法是有益的尝试;图卷积神经网络(graph convolutional network,GCN)对于图数据、流数据等体现出拓扑不均衡特征的数据而言也具有显著优势,如双正则化GCN(dual-regularized GCN,DRGCN)[30]、重新加权GCN(re-weighted adversarial GCN,RA-GCN)[31]均能有效地防止基于图的分类器偏向任何特定类。最后,结合了主动学习方法的均衡分类算法,能通过结合少量专家智慧极大提升模型分类的效率[32-33]。然而,上述研究进展主要聚焦于具有特定数据结构的研究领域,在适用范围方面存在一定的局限性。因此,在解决不均衡分类场景时,还需要结合多层次多角度的尝试进行综合优化。例如,结合数据重采样,Wu等[34]基于改进的SMOTE和Ada‐Boost算法提出了客户留存及流失预测分类器;引入代价敏感[35],在AdaBoost样例权值更新中引入代价因子,构建基于代价敏感的AdaBoost算法[36-38]。
(3)评估层面。代价敏感学习[39]用于误分类代价不同的情况。其核心思想是利用代价矩阵(cost matrix)使不同误分类产生有差异的惩罚,即非均等代价(unequal cost),使分类器更关注误分类代价高的类别。目前,代价敏感信息的引入主要有以下类型[15]:①将代价敏感因子以权重的方式引入分类模型[40],如最经典的AdaBoost迭代改进就是Fan等[41]的基于代价权重的AdaCost;②将代价敏感作为结果处理阶段的元模型,以stacking集成学习方式结合入传统分类模型的输出结果,例如,Domin‐gos[42]提出的MetaCost基于stacking“元学习”通过最小期望代价作用于类别修正标签;③重新构建基于代价敏感特征的分类器,将代价敏感的特征直接拟合于分类器的基本逻辑,对其整体的损失函数、训练特征或内部机制进行优化,例如,在决策树的归纳过程中通过代价函数控制其剪枝规则[43]。
3 研究设计
本研究从数据、算法和评估三个方面综合考虑如何解决新兴技术识别中的数据不均衡问题,以期望获得更优的新兴技术识别的预测结果,为后续类似不均衡数据问题的解决提供参考。技术路线如图1所示。
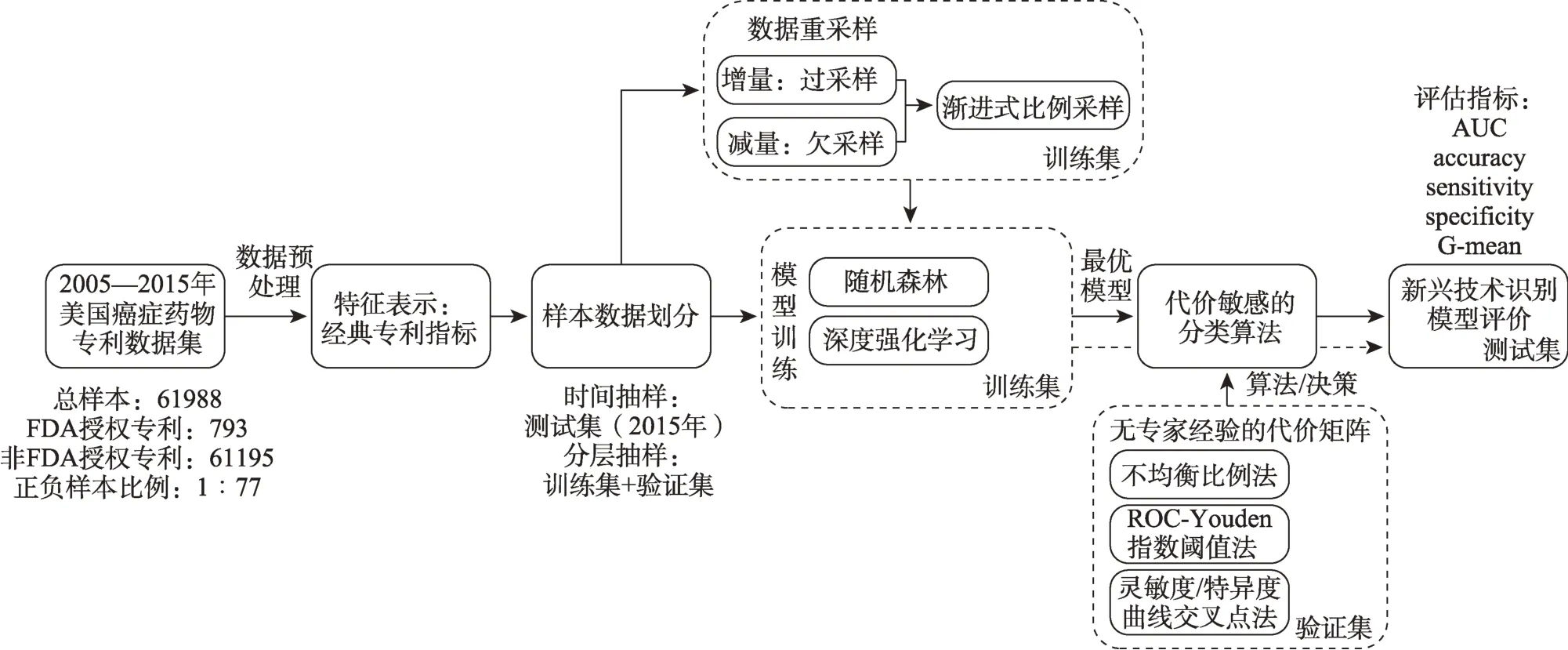
图1 技术路线
3.1 数据来源
在各高新技术行业中,制药领域的癌症药物研发专利一直受到广泛关注,选择该领域进行实证研究主要具有以下必要性和优势:药物专利数据集通常在全球范围内都有较好的开放共享性;涉及大规模投资和研发高风险,且技术价值与其商业价值直接相关,能较好地体现与之相关的新兴技术规划与布局等战略;药物研发的创新性即是否能够涌现为新兴技术,相比于其他领域容易评价,例如,在美国,获得专利颁发机构许可的癌症药物仅仅是获得技术的认证,只有当其同时获得了FDA(Food and Drug Administration,美国食品和药物管理局)授权许可,才意味着其成为满足上市要求的新药。因此,癌症药物专利集作为该领域技术的集合,预测此类专利是否有可能获得FDA授权可充分地作为新兴技术识别的目标。
数 据 集 采 用2016年USPTO(United States Pat‐ent and Trademark Office)癌症登月计划开放的癌症药物专利数据集(Moonshot Cancer Drug Patents)。该癌症药物专利数据集包含了已发表和已授权的癌症药物相关的专利记录及详细信息。同时,为了补充本研究目标所需要而该数据集尚不完整的信息,基于专利号码,进一步根据PatentsView API和EPO OPS API对需要的著录数据和家族数据进行补充。此外,该专利数据集中的FDA授权许可信息仅截止到发布日期,通过FDA发布的授权药品数据说明(即俗称的“橘皮书”)补充了部分遗漏的药物专利是否得到FDA授权的信息。
最终,经过数据预处理和筛选,得到2005年1月1日至2015年12月31日的癌症药物专利数据共61988条。其中,FDA授权的标签数据仅有793条,非授权的标签数据达到61195条,数据极不均衡,只有约1.28%的专利同时能得到FDA的授权,获得批准上市,正负类样本比例(imbalanced ratio,IR)约为1∶77.17,是典型的新兴技术识别中的不均衡分类数据集。表2展示了该数据集的统计信息。
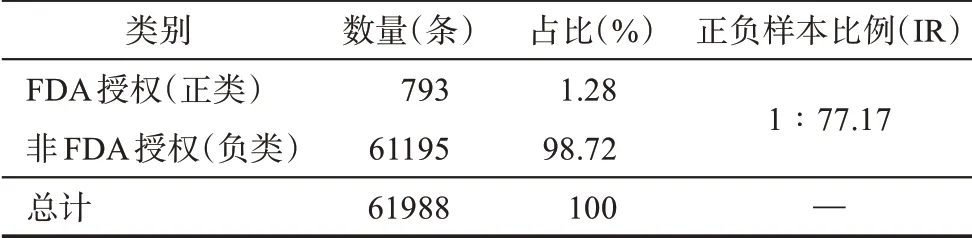
表2 数据集统计
3.2 专利特征指标
由于本研究的关注重点在于新兴技术识别过程中不均衡分类问题的解决,因此,在选取专利特征指标时,遵循简洁性、代表性和权威性的指导原则,采用经典研究中被广泛采用的专利指标作为专利特征的评价,重点在于体现出新兴技术的关键特征:创新性、相对增长性、连续性、社会经济影响力[44-47]。具体的专利特征变量及说明如表3所示。抽取并计算特征变量,表4汇总了本研究中所有专利特征指标的描述性统计量。
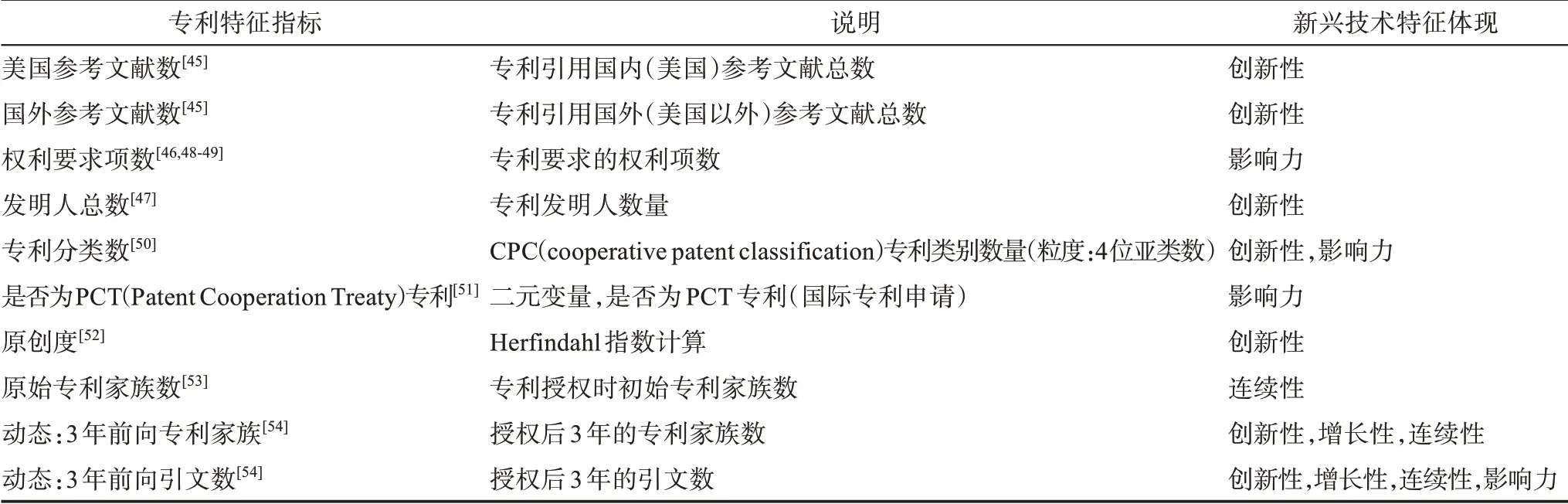
表3 专利特征指标及说明

表4 专利特征指标的描述性统计
3.3 数据集划分
采用时间抽样(out-of-time sampling)和分层抽样(stratified sampling)结合的方法将原始数据集抽分为三个互斥的样本集,分别用于训练、验证及测试。首先,利用时间抽样法将样本分割为训练集和测试集。时间抽样法是一种非随机的留出法(holdout sampling),其以时间为依据进行定向抽样,在模型的评估中会更关注模型对于现在乃至未来成功预测出FDA授权的目标表现,符合面向未来的预测识别需求;其次,采用分层抽样的方式进一步划分训练集和验证集。分层抽样能够在数据集分割的同时,保持其中正负类样本的比例不变,相当于分别对正负类样本进行等比例抽样,选取训练集和验证集的比例分别为80%和20%。最终,根据新兴技术识别的具体应用场景划分数据集,如表5所示,进一步印证了基于癌症药物领域专利的新兴技术识别是不均衡分类的典型问题。
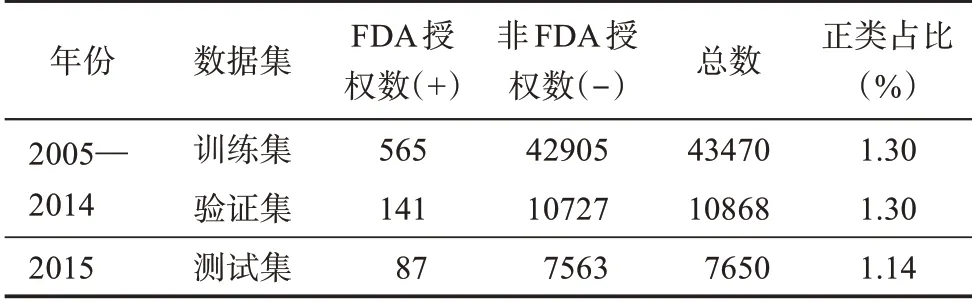
表5 数据集划分统计
3.4 基于代价敏感学习的随机森林构建
3.4.1 模型选择
随机森林(random forest,RF)是不剪枝的树集成分类器[55],将多个互相独立的决策树通过装袋(bootstrap aggregating,bagging)的形式构建出大规模的集成模型。因此,当决策树的总量足够大以及满足抽样随机性时,随机森林的多样性和泛化能力会增强。在具体的实验过程中,通过比较模拟确定以下综合较优的关键超参数:n_estimators设置为400,即采用400棵子树作为基分类器,此时模型的泛化能力饱和;max_features采用所有专利特征属性,本研究的特征属性仅11个,构建分类器时考虑所有特征的模型性能更优。在此基础上,袋外评估和随机性确保了随机森林模型的泛化能力,且由于训练集、验证集和测试集中正负样本的比例和完整数据集的比例较为一致,在模型结果评估时均采用测试集,不必再进行分层交叉验证。
3.4.2 改进思想
遵循代价敏感学习的理念,将代价矩阵引入随机森林的做法主要有三种:其一,以代价矩阵为基础对随机森林自主法采样进行改进[40];其二,构建基于代价矩阵的代价敏感基分类器[56];其三,在决策阶段针对决策树的叶结点和集成决策环节采用加权的多数投票。如图2所示。假定类别之间以代价矩阵的形式定义了不对称的错分成本,从而实现不同的错误分类惩罚项的方法被称为加权随机森林(weighted random forest)[57]。
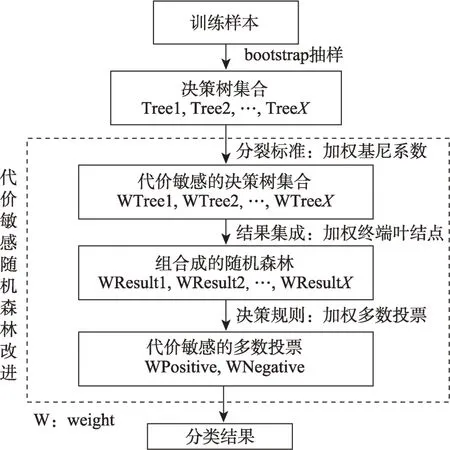
图2 代价敏感随机森林改进
3.4.3 分类训练:代价敏感的基分类器
传统随机森林算法使用的基分类器是决策树,随机选取属性进行分裂,而选择最佳分割的方式通常是计算划分后子结点的最低不纯度,因为不纯度越低,代表在此结点中的类分布就越有偏向性,越集中为某一类。不纯度的估计一般以最小基尼系数法作为切分节点的分割标准。
在代价敏感的随机森林中,针对单个基分类器的归纳过程,采用类权值计算用于选择分裂切分点的Gini(t)的加权最小Gini(t),寻找对应的代价不纯度最低的最佳分割标准。因此,Gini(t)的表达式转变为
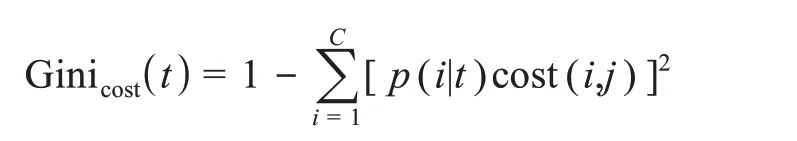
其中,i表示类别;C表示类别的个数。
3.4.4 决策规则:代价敏感的多数投票
除了修改作为基分类器的单个决策树的分裂标准,代价敏感信息也会被加入树的叶结点即终端决策规则中去。引入代价敏感思想后,每棵决策树终端叶结点的类别判定不再取决于该结点样本中数量居多的类别,而会纳入以权重表示的代价。对于单棵决策树来讲,在最后的分类决策中,叶结点t指派为正类的概率转变为
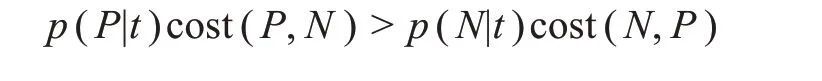
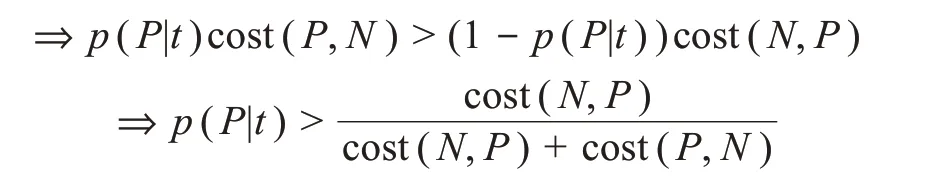
最后,每棵树终端叶结点的类预测均转为加权多数投票,随机森林最终预测类别就是所有树平均加权投票值高的类[57],提升了随机森林中对不均衡分类更为敏感的树在多数投票决策阶段的话语权。
3.5 模型评估及目标
在不均衡分类问题中,由于少数类通常反映更受重视的预测结果,是重点的研究对象,一般都将少数类作为正类(positive,P),多数类记作负类(negative,N)[11]。根据测试样本的实际归属类别与模型的预测结果输出,混淆矩阵能组合出如表6所示的真正例、假正例、真负例和假负例四类分类评价。基于二分类混淆矩阵,本研究所采用的评估指标计算方式和说明如表6所示。

表6 二分类混淆矩阵
(1)整体准确率(accuracy):表示模型预测正确的样本总和与所有样本总和之比,
accuracy=(TP+TN)/(TP+TN+FP+FN)
(2)灵敏度(sensitivity)和特异度(specificity):灵敏度表示模型的真正率(true positive rate,TPR),即被正确预测为正类的样本数量与实际所有正类样本的比例,体现出少数类被正确预测出的分类水平;特异度表示模型的真负率(true negative rate,TNR),即被正确预测为负类的样本数量与实际所有负类样本的比例,体现出多数类的正确分类水平。计算公式分别为
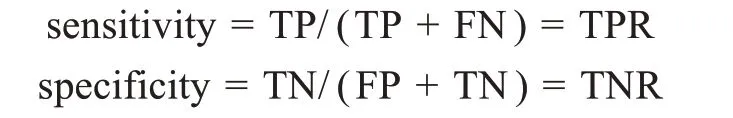
(3)ROC曲线与AUC值:ROC(receiver operat‐ing characteristic)曲线[58]根据混淆矩阵对所有可能的分类阈值效果进行综合衡量,本质上是不同分类阈值下分类结果(TPR、FPR)表现的集合,是兼顾正负分类效果的评估方式,其中纵坐标TPR与横坐标FPR(false positive rate)的计算方式分别为
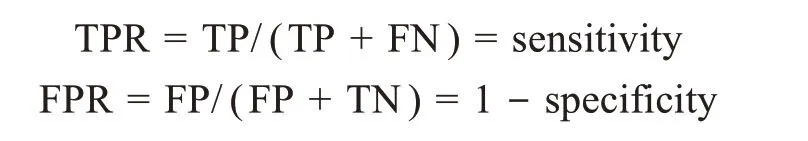
AUC值(area under curve)表示ROC曲线中TPR和FPR对应点的连线与坐标轴包围区域的面积,常被作为评价模型整体性能的测度指标。AUC数值越大,模型的整体预测能力就越理想。
(4)G-mean[59-61]:在不均衡问题中,同时优化多个指标是困难的,通常需要进行权衡。相较于传统的F1值可能会受到不均衡环境下高FP值的欺骗,产生误导[62],G-mean表示模型灵敏度(sensitivity)和特异度(specificity)的几何平均,能够综合体现有效识别的总体水平,
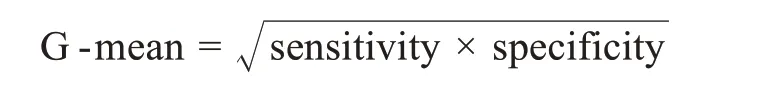
4 实证分析
4.1 渐进式采样方法
以训练集的完整数据为基础,重构多种重采样数据集,将其与完整的采样数据进行比较。其中包括四种常见过采样数据集:随机过采样数据、SMOTE过采样数据、borderline-SMOTE数据和ADASYN数据,以及四种常见欠采样数据集:随机欠采样数据、cluster centroids数据、near miss数据和Tomek links数据。图3展示了不同模型下各采样方式ROC曲线的比较。

图3 各采样方式ROC曲线的比较
该实验结果表明,尽管部分欠采样和过采样方法都可以有效地解决不均衡数据分类预测结果偏向多数类的问题,但其总体的性能表现却具有较大差异。随机欠采样表现出了整体更优的ROC曲线分布和AUC值,同时,不仅在预测建模上能够显著优化分类器的分类性能和少数类识别能力,更能大幅提升模型的计算效率,是本数据集最适宜的采样方式。
此外,将不均衡数据集均衡到什么程度能得到最佳的分类表现也是不均衡分类问题中值得探索的领域。例如,Kim等[63]通过逻辑回归、朴素贝叶斯、随机森林测试了负训练数据与正训练数据的比率如何影响机器学习算法在消除作者姓名歧义方面的性能;Peng等[64]在预测实时交通事故风险的研究中探索了不同比例过采样对实验结果的影响。在保证正负样本区分能力足够的基础上,不能简单将正负类别的均衡比例设置为1∶1,而应当通过进一步的实验结果,结合分类目标确定具体的均衡比例,注重数据均衡比例和原始样本空间改变的平衡。因此,继续采用随机欠采样,所有FDA授权的正类样本仍然保留在数据集中,按照一定的比例随机剔除整个样本中的非FDA授权的负类数据,使数据分布更加均衡。正负类样本比例分别从1∶1到1∶20用于形成重采样后的建模数据集。表7展示了不同随机欠采样比例下的训练集样本描述,不同正负类均衡比例的组合在测试集的预测结果如图4所示。
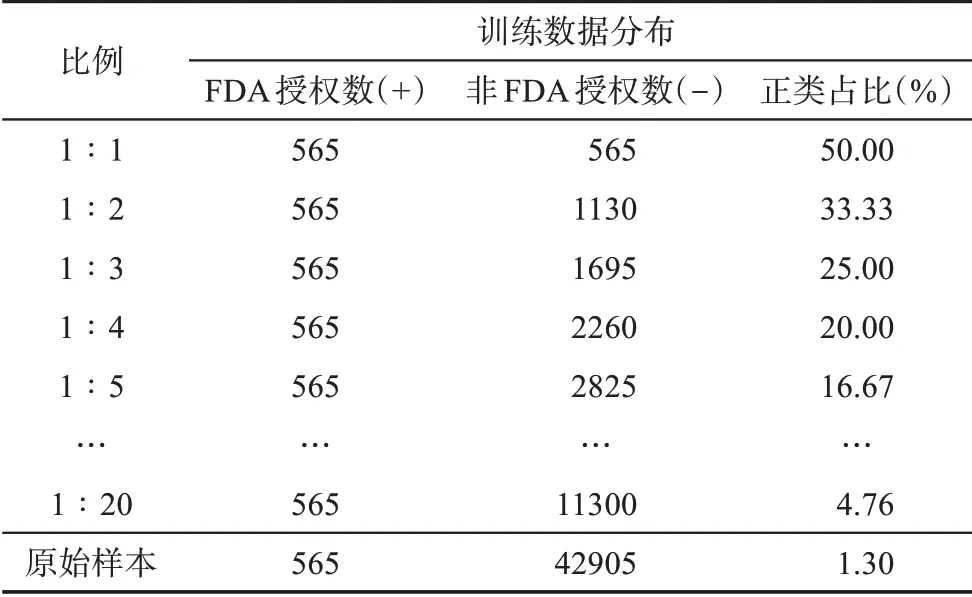
表7 渐进式随机欠采样的训练集分布描述
从图4可以发现,总体上看,1∶2时,随机森林的AUC值为各比例下的最高值(0.881),且在Gmean相比于1∶1损失仅约为0.015的条件下,保持了较高的整体准确率。因此,使用随机欠采样并以正负均衡比例1∶2构建的随机森林模型在大大减少了分析的数据量且保留相对更多原始多数类样本信息的基础上,取得了综合预测能力提升趋势较为饱和的不错的预测结果,更适合作为本研究后续代价敏感学习的基础。
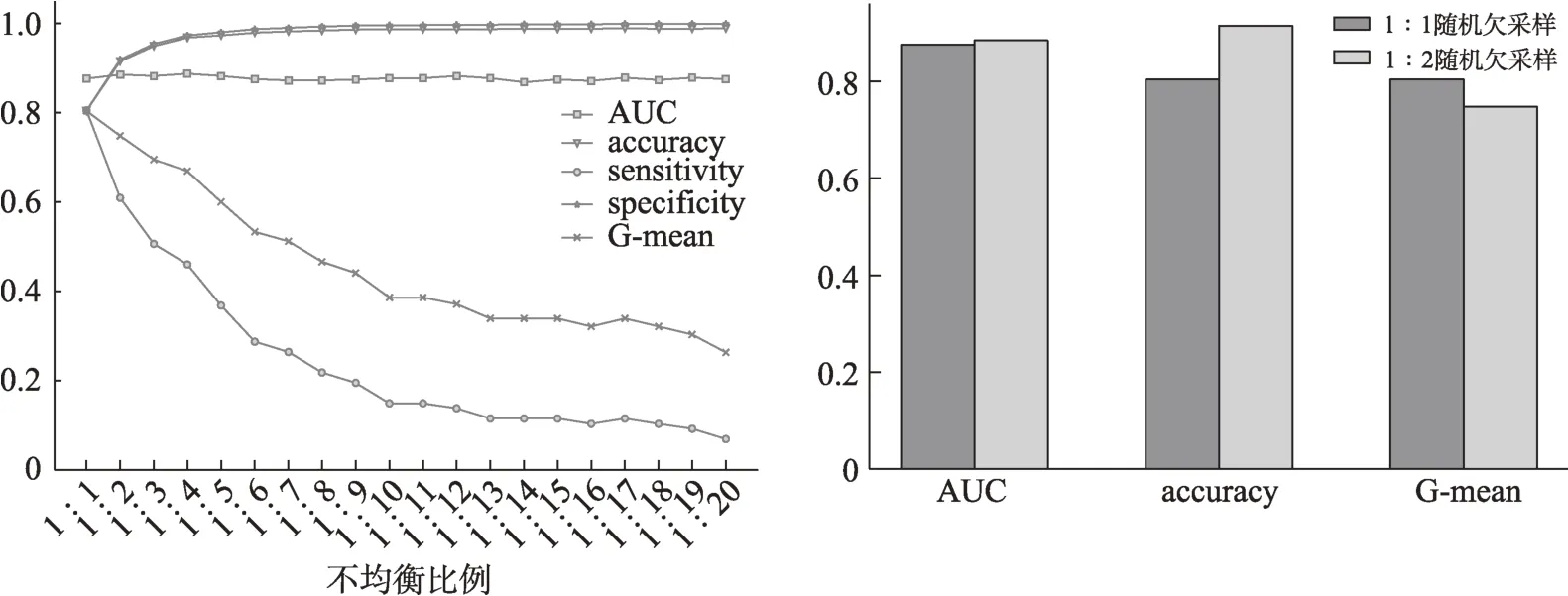
图4 渐进式随机欠采样的随机森林比较
4.2 代价矩阵的设定
代价敏感学习的有效性在很大程度上取决于代价矩阵的确定,错误的初始化成本会损害模型的学习过程。因此,代价矩阵提供的参数对于代价敏感学习至关重要。目前主要通过两种方式获得成本矩阵:领域专家提供经验和目标,或者采取不同的代价矩阵验证方法在分类器训练阶段学习获得。然而在实际的不均衡分类问题中,诸多情景并不能直观地依靠金钱损失、时间成本和发病率等就能得到较为可靠的代价矩阵。因此,更多地还是依靠后者来获取具体问题的最优代价矩阵。
4.2.1 不均衡比例法
目前,针对专家经验的较难获取性,许多研究都将其简化为利用不均衡比例(IR)作为估算成本的直接方法。IR方法直接根据不同类别的样本比例来设置少数类的权重。以二分类问题为例,假设完整的样本集为S,SP为少数类即正类数据的数量,SN为多数类即负类数据的数量,则数据集不均衡度IR的计算方式为
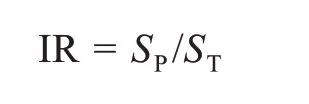
4.2.2 ROC-Youden指数阈值法
以ROC曲线的Youden指数作为选择阈值的标准,称为Youden指数阈值法[65]。Youden指数在ROC曲线上反映为点与对角交叉线(0,0)和(1,1)之间的纵向距离,Youden指数的计算公式为
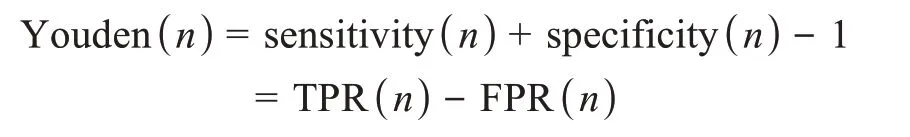
其中,n表示ROC曲线中点的集合;sensitivity(n)和specificity(n)分别为该点对应的分类阈值下模型的灵敏度和特异度。
4.2.3 灵敏度/特异度曲线交叉点法
由于灵敏度和特异度曲线交叉处代表同时较高的灵敏度和特异度,很多研究都通过选择灵敏度和特异度曲线交叉点的方法来确定分类阈值[66-67]。利用ROC曲线计算Youden指数阈值的方法,通过验证集采用灵敏度和特异度曲线交叉点法获取对应阈值就能推导出代价矩阵:
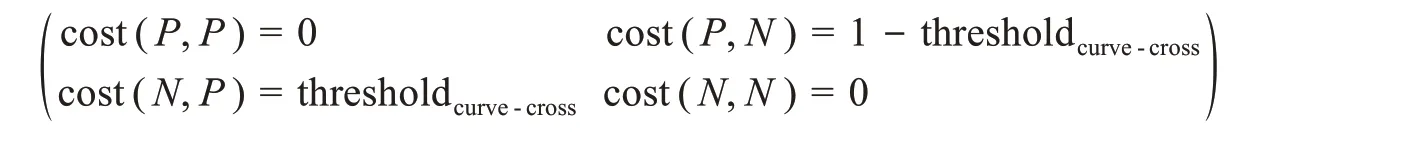
4.3 实验效果分析
最终,通过不均衡比例法,以及验证集基于ROC-Youden指数阈值法和灵敏度/特异度曲线交叉点法确定的代价矩阵,1∶2随机欠采样的代价敏感随机森林和两个对照实验组的预测结果如图5和表8所示。
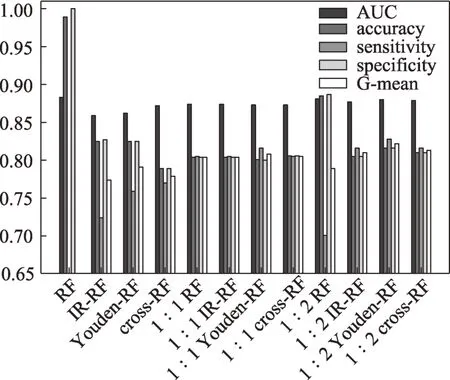
图5 不同策略组合的分类器比较
从图5和表8可发现,总体来看,采用三种方法确定代价矩阵的代价敏感随机森林对于新兴技术识别分类预测能力均有显著提升,表明代价敏感学习对于是否进行数据采样处理的分类算法均有提升少数类分类预测能力的作用。在未经任何数据重采样预处理的原始样本对照组中,代价敏感随机森林相对原始模型的提升效果极为显著,可以有效缓解模型无法预测出任何少数类的严重偏向性。而1∶1随机欠采样处理的对照组,则进一步验证了渐进式采样的必要性,因为代价敏感学习在此时仅能再有限地提升模型预测能力,过度的采样已经损失了较多的原始数据集分布信息,对于多数类预测能力和整体性能的降低已经无法通过代价敏感学习弥补提升。
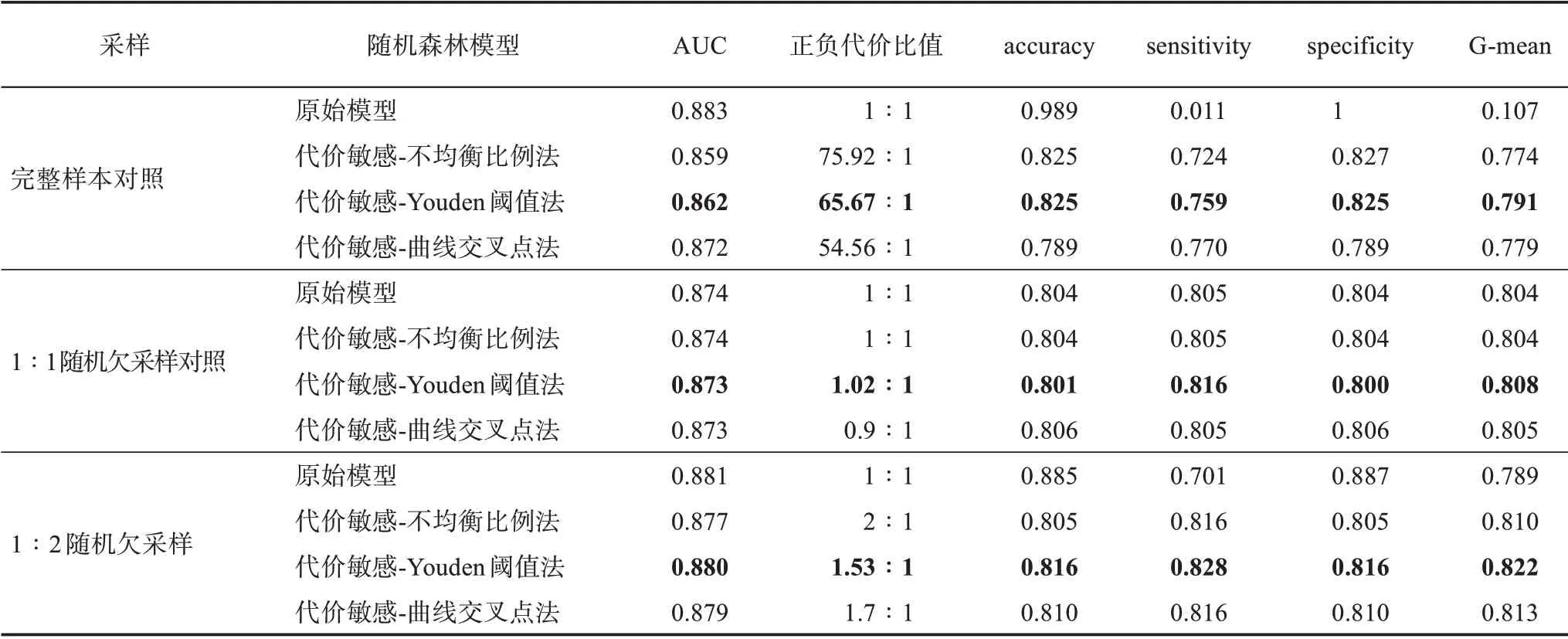
表8 不同策略组合的分类器预测结果统计
此外,通过计算分类结果的各项评估指标,发现其中最优的代价矩阵设定方式为ROC-Youden指数阈值代价矩阵,其各项性能表现均总体优于其他代价矩阵的改进。目前,最为常用的不均衡比例代价矩阵尽管很容易实现,不需要额外的模型计算成本,但具有结果不符合预期的重大局限性,因为数据集分布和实际错分代价并不是简单的直接关联,不均衡比例并非不均衡分类中的唯一困难,正负样本噪声问题、样本重叠等也会影响到其最优代价的变化,采用不均衡比例代价矩阵会对代价敏感问题过度简化。值得注意的是,由于在第一阶段代价未知时,训练的分类器是原始的损失函数驱动而没有引入代价敏感,因此,使用ROC-Youden指数阈值代价矩阵方法针对代价不敏感的算法来初始化代价矩阵参数的估计,然后通过估计的代价矩阵构建代价敏感学习算法,结果可能会存在一定偏差。尽管如此,该类方法实际上也包含了不均衡比例代价矩阵无法测度的正负样本重叠、类内不均衡等各类因素对最优代价变化的影响。因此,在缺乏特定先验矩阵的情况下,对比常用的不均衡比例代价矩阵,ROC-Youden指数阈值矩阵更能获取符合预测目标模型的更优错分代价,仍然为比较好的代价矩阵替代方案。
最后,基于1∶2均衡比例随机欠采样、以ROC-Youden指数阈值代价矩阵构建的代价敏感随机森林模型取得了最好的分类表现,其AUC、ac‐curacy、sensitivity、specificity和G-mean分 别 达 到0.880、0.816、0.828、0.816和0.822,意味着在对应的新兴技术识别目标中,采纳该模型能预测出82.8%的新兴技术,同时能正确识别81.6%的普通技术,实现仅17.2%的漏报率和18.4%的误报率,进一步验证了综合渐进式采样、算法优化和评估优化的分类改进策略为整体预测能力最好的策略组合。与其他对照组相比,其模型对于重点关注少数类预测能力的识别效果和平衡效果均较为良好,在此基础上构建的基于专利指标的机器学习新兴技术识别框架具有较强的前瞻性预测价值。
4.4 不均衡研究相关方法比较
为证明基于1∶2均衡比例随机欠采样、以ROC-Youden指数阈值代价矩阵构建的代价敏感随机森林模型具备优势,本研究选取不均衡分类研究中最近提出的相关方法——deep reinforcement learn‐ing(DRL)进行比较分析。以原始训练集为基础,通过随机欠采样构建出1∶1及1∶2重采样数据集,在该环境下验证DRL的性能指标,并选取最优的模型结果与本研究提出的基于代价敏感的随机森林模型进行比较,结果如表9所示。
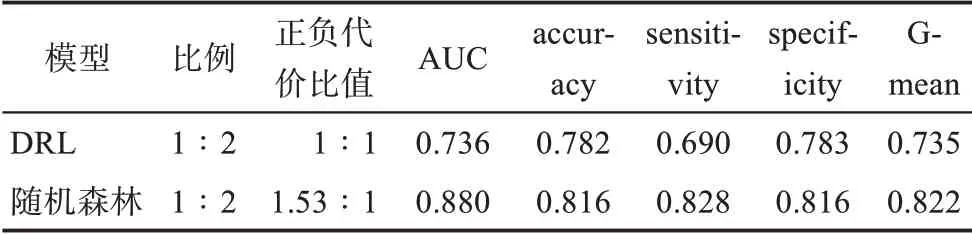
表9 deep reinforcement learning(DRL)与优化随机森林的对比
从表9可以看出,本研究提出的基于代价敏感的随机森林模型在各项指标上均显著优于DRL,其中代表FDA授权样本预测能力的sensitivity指标,较DRL模型高出13.8%,这一现象表明本研究提出的优化模型与现有的相关成果相比具备一定的优势。
5 总结与展望
本研究通过数据维度、算法维度和评估维度三个层次的综合优化策略组合,通过癌症药物领域专利的实证结果,验证了所提出的基于机器学习的新兴技术识别不均衡分类优化框架的可行性、有效性和价值意义。然而,本研究在研究思路、研究内容以及研究方法上存在一定的局限性与不足,在未来的深入研究中有优化和丰富的空间。
(1)本研究的核心为数据维度、算法维度和评估维度三个层次的综合优化框架,尽管其中通过各项实验组和对照组保证了最终模型组合策略的相对更优,验证了本文所提出框架的有效性,但最后基于1∶2均衡比例随机欠采样、以ROC-Youden指数阈值代价矩阵构建的代价敏感随机森林模型仍然为局部最优的方案,未来研究中可继续探索采样、算法及代价敏感学习的应用及组合。
(2)本研究尚未对不均衡数据集特征及不均衡分类面临的本质问题开展更为深入的研究。未来不均衡分类问题的研究中,除了关注正负样本类间不均衡比例造成的不均衡分类,还需要结合新兴技术识别问题中的实际数据集纳入更为细粒度的因素研究,如少数类噪声、多数类和少数类的类间样本重叠、类内不均衡以及概念漂移等问题,深入挖掘不均衡分类问题的本质。
