基于注意力机制的航空图像旋转框目标检测
2022-11-20常洪彬李文举李文辉
常洪彬, 李文举, 李文辉
(吉林大学 计算机科学与技术学院, 长春 130012)
航空遥感图像目标检测作为遥感图像分析中的一种基本技术方法广泛应用于城市规划、 土地利用、 交通引导和军事监控等领域[1-3]. 早期的航空遥感图像目标检测算法依赖于人工设计特征. 文献[4]基于区域建议法提取目标的潜在区域; 文献[5-6]利用滑动窗口提取特征, 最后选取得分较高的图像区域作为候选区域; Cheng等[7]利用选择性搜索法减少滑动窗口暴力搜索的时间消耗, 但算法的复杂度较高, 难以满足实时性要求. 随着深度学习的发展, 由海量数据驱动的深度学习提取到的特征具有更强的语义表示能力, 与人工提取方法相比, 性能有较大提升. 同时, 在神经网络正向传输过程中, 避免了大量窗口的冗余计算, 提高了检测速度. 针对航空图像的特点, 目前已有许多有效提高航空图像目标检测性能的改进方案. 为解决图像尺度过大的问题, 文献[8]采用分块切割的方法将大图像分割成小图像, 然后对每张小图像分别进行后续的检测和识别, 最后将所有检测结果进行拼接. ORSIm方法[9]和FMSSD方法[10]通过引入旋转不变量子模块, 削弱了卷积神经网络特征提取对角度的敏感性, 缓解了方向多样化对检测的影响; 文献[11]通过引入浅特征和深特征上采样提高特征图像的尺寸, 这类方法虽然改善了小目标检测的问题, 但也增加了检测过程的时间消耗; Yang等[12]通过引入注意力机制弱化背景, 增强目标信息, 但引入了额外的掩码计算, 导致网络计算量增加.
为解决上述问题, 本文提出一种基于注意力机制的航空图像旋转框目标检测方法. 以RetinaNet[13]为基线网络, 提出一个新的通道语义提取注意力模块, 用于提取全局语义特征和通道关系, 突出前景并抑制背景噪声, 利用特征对齐方法[14]和改进的Fast R-CNN[15]检测头微调分类和回归分支, 得到更精确的结果. 实验结果表明, 本文设计的模型能有效克服背景复杂图像的特点, 提高了在航空图像上的目标检测能力.
1 算法设计
1.1 算法框架结构
本文算法以RetinaNet为基线, 应用ResNet-50骨干网络和特征金字塔网络(feature pyramid networks, FPN)提取基本特征. 由于航空图像中存在大量小目标, 周围环境复杂, 因此与RetinaNet不同, 本文算法选择FPN的P2~P6层提高模型对小目标的识别能力. 为适应定向目标的检测, 本文在RetinaNet的基础上增加了一个额外的参数θ∈[-π/4,π/4], 表示包围盒从水平线到边框宽度方向的夹角. 基本特征图先利用通道语义提取注意力模块(channel semantic extracting, CSE)突出前景、 抑制背景噪声, 再经过无锚点旋转框目标检测模块得到粗略的分类分数和包围盒. 将输入特征图和粗糙包围盒一同作为角度精化模块(angle refinement module, ARM)的输入, 再经过改进的Fast R-CNN检测头模块得到最终精确的检测结果. 算法网络结构如图1所示.

图1 本文算法网络结构
1.2 通道语义提取注意力模块
卷积神经网络[16-20]中特征图的每个通道都被视为一个特征检测器, 所以使通道注意力更集中在对任务有益的特征提取上能极大提升模型性能. 本文利用特征通道相互关系生成通道注意力图, 并对特征进行通道自注意力重分配, 如图2所示.

图2 通道语义提取注意力模块
平均池化广泛用于聚集空间信息中, 但本文通过实验证明最大池化能更好地提取图片的纹理特征, 消除不必要的背景信息. 目前几乎所有的通道注意力工作都是将输入特征图直接聚合成一维的通道注意力图, 但这样会丢失重要的全局信息. 为保留全局语义特征并有效计算通道注意力, 本文对输入特征图X∈C×H×W, 使用自适应最大池化(adaptive max pooling, AMP)下采样到X′∈C×K×K, 其中K×K表示压缩后每个通道的特性图大小.本文设K=7.自适应最大池化操作Fmax可表示为
X′=Fmax(X).
(1)
为提高模型效率, 本文将压缩后的特征图X′进行分组卷积操作.与标准卷积操作相比, 分组卷积的参数量为标准卷积的1/G, 可以用等量参数生成更多的特征图, 而特征图的数量可反映编码的信息量.对于X′中的每组特征Zg∈C/G×K×K, 均有n个特征图Xgn, 其中gn是g组中的第n个特征映射, 本文使用一个卷积核对其进行卷积操作, 其长宽大小与Xgn相同, 以增加特征图的感受野, 提高模型的全局特征提取能力, 从而生成更高级的语义信息.卷积结果定义为

(2)
其中:kgn表示输入特征图Xgn的卷积核, 大小为K×K;Mgn∈K×K表示特征图上的一个位置;λ为自适应超参数, 用于减少与分组卷积相关的较大值.通过对比实验, 本文设λ=0.1K2.之后,Xg经过Sigmoid函数激活, 得到该模块的最终输出. CSE通道注意力计算公式为

(3)
其中σ表示Sigmoid函数,ω表示进行卷积核大小为k的分组卷积操作.本文设分组个数G=16.通过映射Φ, 通道具有更广泛的交互范围, 并可使用更少的参数提取到等量的特征, 从而极大提高了模型的检测效率.
1.3 无锚框目标检测
本文采用无锚框目标检测生成粗糙定向包围盒和分类分数.粗糙定向包围盒包括距离和角度, 分别用d和θ表示, 分类分数用c表示.设Bk=(xk,yk,wk,hk,θk)是类别为ck的对象k的真实边界框, 其中Bk∈5×C.用xk和yk表示该物体的中心坐标,wk和hk分别表示宽和高,θk表示包围盒的旋转角度,C表示类别数.在分类分支中, 对于每个位置(x,y), 如果位于真实框的中心区域Bδ=(xk,yk,δwk,δhk,θk)中, 则将该位置标为正样本, 其中δ表示中心率.每个位置与真实位置之间的距离为


图3 定向包围盒
在回归分支中, 对于每个正样本, 均有dk=(l,t,r,b), 表示从(x,y)到左、 上、 右、 下边界框的距离,dk=(l,t,r,b)的值计算公式为

(5)
1.4 角度精化模块
为得到高质量的旋转框, 本文应用角度精化模块(ARM)进行特征对齐, 以精细化粗糙包围盒结果, 如图4所示.

图4 角度精化模块
ARM的输入是输入特征和预测的粗糙包围盒. 与标准的二维卷积不同, 对于一个在特征图Y上位置p∈{0,1,…,H-1}×{0,1,…,W-1}的对齐卷积计算公式为
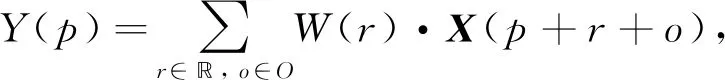
(6)
其中W表示卷积权重,X表示输入特征,r表示正则网格中的向量R={(-1,-1),(-1,0),…,(0,1),(1,1)},o∈O是在偏移域O中对于每个位置p的偏移程度.对于每个粗糙包围盒B=(x,y,w,h,θ)和r∈, 样本位置可定义为

(7)
其中s表示特征图的步长,Θ=(cosθ,-sinθ,sinθ,cosθ)T表示旋转矩阵.在位置p的偏移域计算公式为
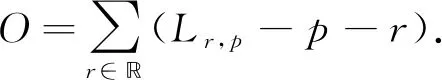
(8)
通过计算得到在位置p的卷积特征X(p), 并在任意方向上提取更精确的卷积特征, 用以精细化粗糙包围盒.对于每个粗糙包围盒, 本文采样9个点(即3行3列), 以获得通道为18的偏移字段(即9个点的水平和垂直偏移).角度精化操作在偏移场计算中是一个速度延迟可忽略不计的轻卷积层.最后, 本文使用两个1×1卷积分别生成分类和回归图, 用于识别对象并细化定向包围盒.
1.5 改进的Fast R-CNN检测头
本文使用改进的Fast R-CNN检测头预测分类分数并得到最终的回归包围盒. 在该模块中, 输入特征图经过两个全连接层(fully connected layers, FC)映射到一个特征向量中, 并分成分类分支和回归分支. 分类分支通过一个全连接层预测分类分数; 回归分支中, 除在Fast R-CNN中的(x,y,w,h)边界框外, 本文还增加了另一个参数θ进行角度的回归, 即回归的边界框表示为(x,y,w,h,θ), 其中θ∈[-π/4,π/4], 以便得到旋转的包围盒, 回归分支与分类分支类似, 即经过一个全连接层得到最终的回归结果.利用该模块可预测出更精确的分类分数和定向包围盒.
1.6 损失函数
由于定向包围盒的角度处于对称区间, 本文直接使用真实角度作为目标训练角度分支, 因此, 本文算法的损失函数可表示为

(9)

2 实 验
本文实验使用预训练的ResNet-50模型进行初始化. 对于FPN(P2~P6)中的每层, 将对应的归一化因子设为{16,32,64,128,256}. 无锚框目标检测模块中的中心率δ设为0.2. 实验使用NVIDIA RTX 2080 Ti进行训练和测试. 在数据集DOTA上进行多尺度实验, 首先将原始图像大小调整为3个尺度, 分别为0.5,1.0,2.0, 然后将这3个尺度的图像全部裁剪为1 024×1 024大小, 步长为200, 训练12个epoch. 模型使用SGD(stochastic gradient descent)优化器, 初始学习率设为0.005, 每个衰减步骤的学习率为0.1倍. 权重衰减是0.000 1, 动量参数为0.9. 非极大值抑制(non-maximum suppression, NMS)阈值设为0.8.
2.1 评价指标
为更好地评估改进后的网络模型, 采用目标检测领域中通用的平均精度均值(mean average-precision, mAP)作为评价指标. 在目标检测中, 通常会有3种检测结果: 正确检测框(true positives, TP); 误检框(false positives, FP); 漏检框(false negatives, FN). 针对这3种情况, 为验证目标检测算法的性能, 采用准确率(Precision)和召回率(Recall)检验标准. 准确率和召回率的计算公式为

(10)

(11)
mAP是检测出所有类别的平均准确率再取平均值得到的结果. 在检测过程中, 计算出每个预测框的准确率和召回率, 并得到点(P,R), 将每次得到的R值作为阈值, 当R大于阈值时, 计算对应的最大准确率, 通过计算这些准确率的平均值得到AP, 最后将所有类别的AP取平均值, 得到mAP.
2.2 数据集
数据集DOTA共有2 806张航拍图像, 包含不同场景大小分辨率从800×800到4 000×4 000的图像, 包括15个类别的188 282个实例. 其标记方法是一个由4个点决定任意形状和方向的四边形, 可应用于水平包围盒(HBB)和定向包围盒(OBB)的检测任务. 数据集DOTA的类别为: 平面(PL)、 桥梁(BR)、 港口(HA)、 田径场(GTF)、 小型车辆(SV)、 大型车辆(LV)、 环形交叉路(RA)、 游泳池(SP)、 船舶(SH)、 足球场(SBF)、 网球场(TC)、 篮球场(BC)、 储油罐(ST)、 棒球场(BD)和直升机(HC).
2.3 实验结果
数据集DOTA目标上的检测结果如图5所示. 在数据集DOTA上, 将本文模型与其他定向检测器的性能进行比较, 结果列于表1. 为排除主干网络对结果的影响, 从而体现模型结构的有效性, 本文所有对比模型都将Resnet-50和FPN作为特征提取网络. 由表1可见, 本文方法的mAP达到77.71%, 在桥梁类、 大型车辆类和环形交叉路类等分类中, 本文方法比其他方法AP约提升8%, 在田径场类和港口类中, AP提升9%以上, 足球场类甚至约提升18%.

表1 不同算法在数据集DOTA上的结果
综上所述, 本文提出了一种基于注意力机制的航空图像旋转框目标检测模型, 用于航空和遥感图像中的定向目标检测. 首先设计了一种新的通道语义提取注意力模块, 该模块能自适应地获取大尺度图像的全局信息并学习通道之间的关系, 抑制背景, 增强对前景对象的特征提取, 提高模型在复杂背景中的检测能力; 然后用无锚框目标检测模块以较少的计算量预测出粗略的分类分数和包围盒; 最后经过角度精化模块和改进的Fast R-CNN检测头, 通过特征对齐方法调整包围盒的角度, 并经过分类回归分支预测出精确的分类分数和定向包围盒. 本文方法在公共航空数据集DOTA上达到了77.71%的平均检测精度, 较其他航空图像目标检测模型相比精度优势明显, 并获得了比基线方法更好的效果.
