基于深度强化学习的微电网优化运行策略
2022-11-19赵鹏杰吴俊勇张和生
赵鹏杰,吴俊勇,王 燚,张和生
(北京交通大学 电气工程学院,北京 100044)
0 引言
微电网是由分布式发电、负荷、储能装置等组成的小规模电网,可以有效提高电网中分布式电源渗透率,是实现“双碳”目标的有效途径[1]。然而,分布式发电的间歇性和不稳定性使得微电网能量管理变得更加困难[2]。
微电网能量管理问题的求解算法包括经典优化算法和启发式算法。经典优化算法主要包括线性规划、混合整数规划等,面对复杂的高维非线性、不连续的目标函数和约束时,该算法存在求解困难的问题[3]。启发式算法对数学模型的依赖性较小,更容易处理非线性问题,但该算法的寻优结果具有随机性,通常为次优[4]。上述2类算法能够解决确定性微电网优化问题,但实际微电网中的可再生能源出力、负荷等因素均是不确定因素,不确定性问题主要采用随机规划和鲁棒优化方法[5-7]进行求解。随机优化方法的难点是如何保证概率分布准确刻画实际不确定性因素的变化规律[8]。鲁棒优化方法采用不确定性集描述不确定性因素的变化范围,但所得优化结果较为保守[9]。
近年来,人工智能技术获得了极大的发展,其中深度强化学习DRL(Deep Reinforcement Learning)算法因具有解决序贯决策问题的能力而受到电力系统研究人员的关注[10],目前主要包括基于值函数和基于策略梯度2类算法。
在基于值函数的DRL 算法研究中:文献[11]建立包含蓄电池和储氢装置的微电网复合储能模型,采用基于值函数的深度Q 网络DQN(Deep Q Network)算法解决储能装置的协调控制问题;文献[12]针对社区微电网储能系统,提出Q-learning的能源管理策略,提高了储能的效率和可靠性;文献[13]提出采用DQN 和深度双Q 网络DDQN(Double Deep Q Network)算法解决家庭家电优化调度问题,并证明DDQN 算法比DQN 算法更适合求解最小化成本问题;文献[14]提出一种基于DQN 算法的微能源网能量管理模型,通过与遗传算法进行对比,验证了DQN 算法在解决能量管理问题时的有效性。基于值函数的DRL 算法将微电网连续变量离散化,导致寻优结果不精确。
在基于策略梯度的DRL 算法研究中:文献[15]建立含有空调系统和储能系统的智能家居能源成本最小化模型,证明了深度确定性策略梯度DDPG(Deep Deterministic Policy Gradient)算法可有效处理模型的不确定性;文献[16]考虑居民行为、实时电价和室外温度的不确定性,建立实时需求响应模型,提出一种基于信赖域策略优化的需求响应算法,实现了不同类型设备的优化调度;文献[17]采用双延迟深度确定性梯度算法解决了光储电站储能运行问题。
本文针对含有风机、光伏、燃气轮机、储能设备和负荷的典型微电网架构,首先详细描述将微电网运行优化问题转化为马尔可夫决策过程MDP(Markov Decision Process)的方法及步骤,然后采用DDPG算法求解微电网连续变量优化问题,为提高DDPG算法的收敛性,设计一种优先经验存储的深度确定性策略梯度PES-DDPG(Priority Experience Storage Deep Deterministic Policy Gradient)算法,最后基于某微电网2018 年的风机、光伏及负荷数据[18]进行算例分析,验证了PES-DDPG 算法能够提高DDPG 算法的收敛稳定性以及该算法处理微电网能量优化问题时的有效性和优越性。
1 微电网系统及优化模型
1.1 微电网结构
本文微电网模型如图1 所示,包括风机、光伏、燃气轮机、储能设备、负荷以及与外部电网接口。微电网运营商的职责是调节各节点的功率流动,实现微电网经济运行。
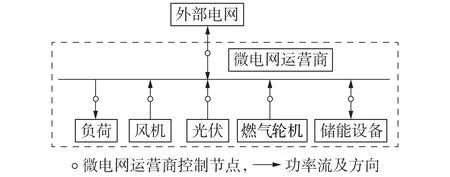
图1 微电网模型Fig.1 Model of microgrid
1.2 微电网设备模型
1)燃气轮机。
燃气轮机通过燃烧天然气为微电网提供可调节的电力供应,有效降低微电网对外部电网的依赖,其燃料成本以二次函数表示,如式(1)所示。

2)储能设备。
储能设备由蓄电池组成,其可与具有随机性和波动性的可再生能源协调运行,发挥“削峰填谷”的作用,保证微电网的可靠性和经济性。考虑蓄电池的充放电功率和储能荷电状态SOC(State Of Charge),储能设备充放电表达式为:


3)需求响应负荷。
微电网运营商可通过电价或其他需求响应手段调节居民负荷的消费特性,为微电网调度运行提供辅助服务,但需求响应不能一味改变用户的用电行为,造成用户体验下降。微电网运营商在执行调度指令时应考虑用户满意度因素。用户满意度有如下特性[19]:用户倾向于消耗更多的能量直至达到目标用电计划;当用户消耗的能量接近目标计划时,用户满意度将逐渐饱和。用户满意度ULt表达式为:

4)微电网母线。
微电网中含有大量以风机、光伏为代表的分布式电源,为实现可再生能源的完全消纳,默认风机、光伏功率全部并网。微电网中母线要保持功率平衡,可建模为:

1.3 微电网优化模型
微电网运营商通过求解以下优化问题来确定运行方案:

以式(14)为目标函数,式(1)—(13)为约束条件,形成混合整数二次规划MIQP(Mixed Integer Quadratic Programming)问题。
2 微电网MDP
强化学习的本质是使智能体和环境交互,智能体基于观察到的环境状态选择动作,环境对该动作作出响应,智能体获得环境的反馈后调整下一步动作,最终实现智能体对环境的最优响应。
假设未来奖励在每个时段的折扣因子为γ,在T时段终止,累积奖励定义如式(15)所示。强化学习的目标是找到最优策略μ*,使得所有状态的预期回报最大,如式(16)所示。
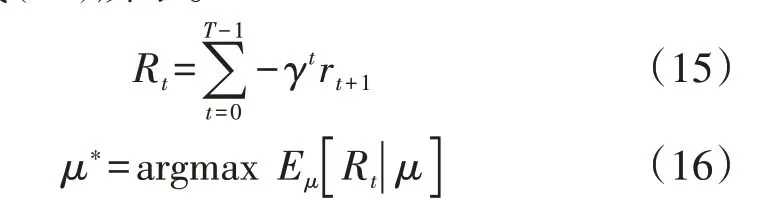
式中:Rt为t时段的累积奖励;argmax 表示求解最大化问题时对应的参数;Eμ[·]表示变量的期望值。
定义策略μ的动作值函数为:
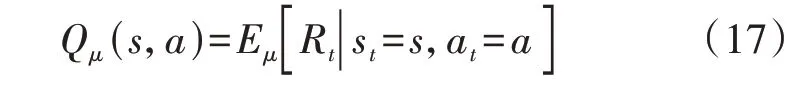
式中:Qμ(s,a)为从状态s开始采用动作a后遵循策略μ的预期回报。
利用强化学习寻找最优策略μ*的问题可等价转化为寻找最大的动作价值函数问题,最大的动作价值函数Q*(s,a)对应的策略就是最优策略μ*,如式(18)所示。

微电网MIQP 问题转化为MDP 进行求解的关键是:环境状态S、动作A、奖励r的表达式;策略μ的获取。
1)状态空间。
微电网运行优化过程中所需的环境信息共同组成智能体状态空间。环境信息可分为时变信息和时不变信息。为简化状态空间,将时不变信息设定为智能体自身的已知信息,将时变信息作为本文模型的状态信息,时变信息包括用户预测负荷、风机预测出力、光伏预测出力、储能状态、分时电价,因此,状态空间可以描述为:
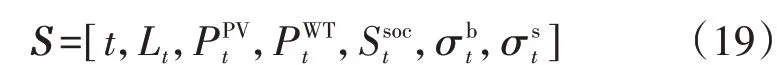
2)动作空间。
在微电网中,控制动作包括实际负荷功率、燃气轮机输出功率和储能充放电功率,智能体动作空间可定义为:

3)奖励函数。
智能体选择任一动作后,环境会给予奖励,一般为正,而惩罚成本为较大的负数,智能体为了获得最大奖励,会逐渐约束动作满足动作变化率。惩罚成本表达式为:
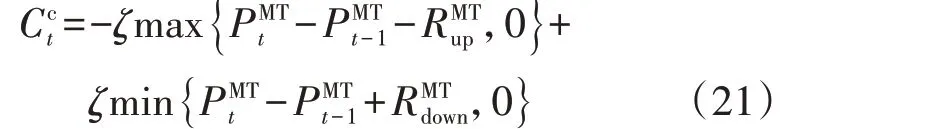
式中:ζ为较大的正数。
奖励函数由微电网运行收益、用户满意度和惩罚成本组成:
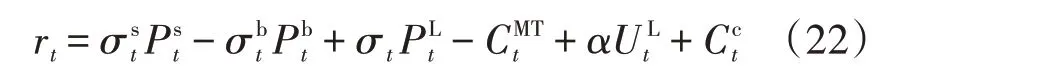
3 PES-DDPG算法
本节介绍策略μ的求解算法,即PES-DDPG算法。
3.1 DDPG算法
DDPG 算法的基本思想是,给定状态和参数,则只输出1 个确定的动作。显然,对于微电网优化问题,针对确定的运行状态,只有唯一的最优调度策略,因此,本文选择DDPG 算法作为求解微电网连续变量优化问题的基础算法。
DDPG算法的网络架构如附录A图A1所示。定义确定性动作策略为μ,每步动作at可通过at=μ(st)计算得到。采用神经网络对μ函数以及Q函数进行模拟,分别称为Actor 策略网络(θ μ)和Critic 价值网络(θQ)。定义函数Jπ(μ)衡量策略的好坏,Jπ(μ)的表达式为:
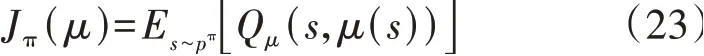
式中:pπ为概率分布函数;Qμ(s,μ(s))为智能体按照策略μ选择动作产生的Q值。Jπ(μ)等价为状态s服从pπ分布时,按照策略μ得到的Qμ(s,μ(s))的期望值。
智能体通过与微电网环境的交互积累丰富经验后进入网络更新阶段。在更新阶段,首先得到式(24)所 示 目 标 奖 励yi、Critic 价 值 网 络 实 际Q值QθQ(st,i,at,i),根据式(25)所示误差方程得到Critic 价值网络误差L,并最小化误差实现Critic 价值网络的更新,然后通过求取式(26)所示策略梯度∇θμJ(μθμ)确定Actor 策略网络的更新方向,实现Actor 策略网络的更新。其中,下标“i”表示样本经验编号。

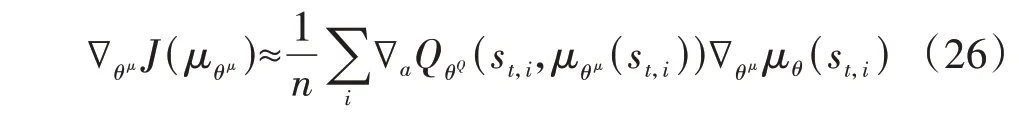
式中:QθQ′(st+1,i,μθμ′(st+1,i))为目标Critic 价值网络得到的Q值,μθμ′为目标Actor 策略网络得到的策略;n为样本经验数;∇aQθQ(st,i,μθμ(st,i))、∇θμ μθ(st,i)分别为Critic价值网络和Actor策略网络的梯度。
DDPG 算法的特点主要有:采取随机策略进行动作的探索,采取确定性梯度策略进行策略的更新;采用Actor-Critic 结构,将其分为Actor 策略网络和Critic 价值网络,并为其创建备份网络,称为目标网络,解决更新不稳定的问题;利用DQN 算法的经验回放对网络进行训练,最小化样本的相关性。本文分别对DDPG 算法的动作探索机制和经验回放机制进行改进,使该算法更适用于优化问题的求解。
3.2 动态噪声搜索策略
搜索策略是为了搜索到完整的动作状态空间,本文在DDPG 算法的训练过程中引入高斯噪声,将动作的选择从确定性过程变为随机性过程,并在随机过程采样得到动作。
动态噪声策略是指,在每次训练过程中,智能体通过策略网络at=μ(st)生成动作并叠加随机噪声时,噪声幅值随着训练的进行而逐渐变小,使智能体动作完全符合策略μ。噪声幅值εk的表达式如式(27)所示。
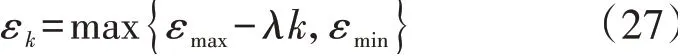
式中:εmax、εmin分别为随机选择动作概率的最大值和最小值;λ为衰减系数;k为训练时的迭代轮数。
3.3 经验优先存储策略
在DDPG 算法中,将智能体探索到的数据组合(st,at,rt,st+1)作为经验并将其存在经验复用池中,随机抽取一批经验对Actor策略网络和Critic 价值网络进行训练,由于经验池大小固定,随着训练的进行,新获取的经验不断覆盖旧经验,只有新获取的经验逐渐一致时,才能得到算法收敛结果。
实际应用过程中发现,在探索初期,智能体得到高奖励经验的概率远低于得到低奖励经验的概率,该时期即使获得了奖励极高的经验,随着智能体趋向探索行为,低奖励经验大量进入经验复用池,也会导致高奖励经验的丢失,训练过程中波动性较大,收敛结果不理想。
考虑微电网能量优化问题的特点,一天24 个不同时段之间的调度结果和收益存在较大差异,而同一时段的调度结果和收益具有相似性。在同一时段内,如果智能体搜索到的经验比之前的经验奖励高,则将其视为优秀经验,并存储到经验复用池中,否则将其视为普通经验,并按照一定概率存储到经验复用池中。
定义经验池中t时段的经验平均奖励rmeant为:

式中:m为训练时的最大迭代轮数;rt,k为t时段第k轮训练时的奖励值。
经验优先存储策略流程图如图2所示。
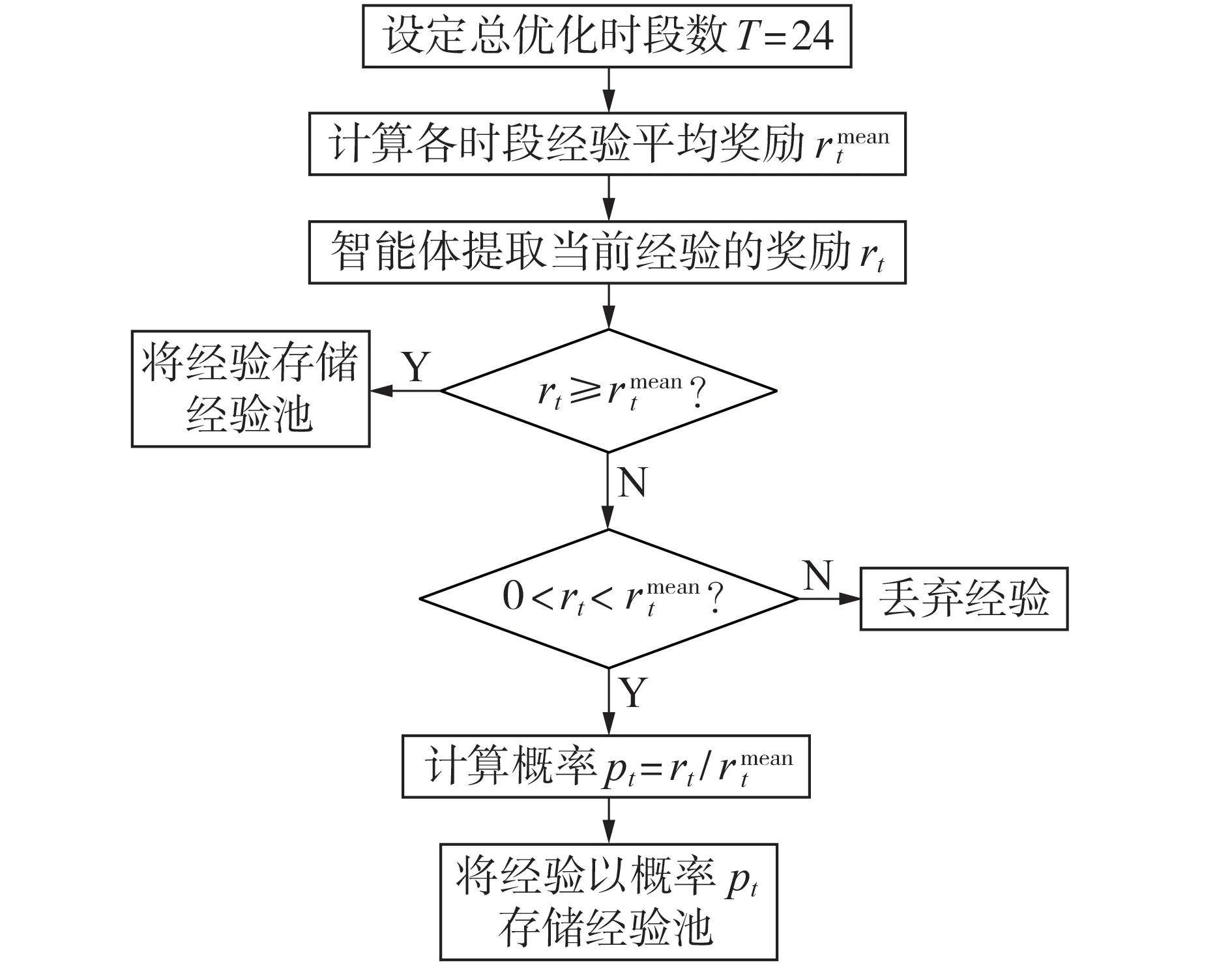
图2 经验优先存储策略流程图Fig.2 Flowchart of priority experience storage strategy
结合动态噪声搜索策略和经验优先存储策略,本文提出的PES-DDPG 算法伪代码如附录A 表A1所示。
4 算例分析
4.1 微电网场景设置
本文建立的微电网各设备主要参数如附录A 表A2 和表A3 所示。微电网中负荷最大值为400 kW,风机安装容量为250 kW,光伏安装容量为150 kW。用户满意度系数vt、zt分别为2.2、2.5。
4.2 算法及算例设置
本文分别采用PES-DDPG 算法、传统DDPG 算法、DDQN 算法和MIQP 算法求解微电网优化运行方案并对结果进行对比。基于微电网马尔可夫模型,PES-DDPG 算法和传统DDPG 算法的状态空间大小为7,动作空间大小为3。设计的Actor策略网络结构如附录A 图A2 所示。输入层为7 个神经元,对应输入7个环境状态;隐藏层为3层全连接层,各层分别有128 个神经元,采用线性修正函数ReLU(Rectified Linear Unit)作为激活函数;输出层为3个神经元,对应模型中的3 类动作,采用tanh 作为激活函数。对DDQN 算法的动作空间进行离散化,将燃气轮机、储能设备、负荷动作离散为9×4×2 种动作。强化学习算法的超参数设置如下:Actor 策略网络和Critic 价值网络学习率均为0.001,折扣因子γ=0.95,最大、最小噪声幅值分别为1和0.004,每批抽样数为128。
本文设置如下2 个算例:算例1,微电网环境变量均为确定值,即风机、光伏功率及负荷需求均可准确预测,在此基础上,采用4 种算法进行微电网日前运行优化;算例2,选取某地2018 年1 月1 日至3 月30 日的实际数据,将其进行标幺化处理后作为训练集,采用本文提出的PES-DDPG 算法训练智能体,假设微电网环境中不确定性参数分别存在5%、10%、30%的预测误差,面对不确定的环境变量,智能体进行在线优化。
4.3 算例1结果及分析
4.3.1 不同算法优化结果分析
微电网某日数据如附录A 图A3 所示。针对确定性环境,采用4 种算法进行微电网日前运行优化,各方案所得微电网运行收益如表1所示。

表1 微电网运行收益Table 1 Operation profit of microgrid
由表1 可知:由于算例中调用Yalmip 工具箱求解器进行求解,因此,MIQP 算法获得了理论上的最高收益,为最优的结果,但由于实际中未来24 h内的风机、光伏功率及负荷需求不可能准确预测,因此,MIQP 算法的求解结果难以直接应用;PES-DDPG 算法和传统DDPG算法的结果较接近最优的结果;由于动作离散,DDQN算法的效果不及传统DDPG算法。
图3 展示了PES-DDPG 算法、传统DDPG 算法和MIQP 算法的优化结果。PES-DDPG 算法和传统DDPG 算法的寻优结果基本一致,体现在:在低电价时,燃气轮机运行成本比电价高,因此燃气轮机仅保持最低出力;储能设备在夜间时段1—5 进行充电,在中午高峰期进行放电,通过低买高卖进行套利,在下午时段15—18中等电价时继续进行充电,并在夜间高电价时进行放电套利;在中午时段12—14,光伏出力较多,燃气轮机也保持高出力,微电网向电网反送功率获利。传统DDPG 算法与MIQP 算法理论最优结果的显著区别是:在传统DDPG 算法的结果中,微电网在时段12—14 向电网反送功率,而在MIQP 算法的结果中,微电网仅在时段12 向电网反送功率;在传统DDPG 算法的结果中,储能设备在高电价时(夜晚时段19、20)放电,而在MIQP 算法的结果中,储能设备不仅在时段19、20 放电,还在时段21—24 放电,满足夜间微电网内的功率缺额需求,减少向电网购电。
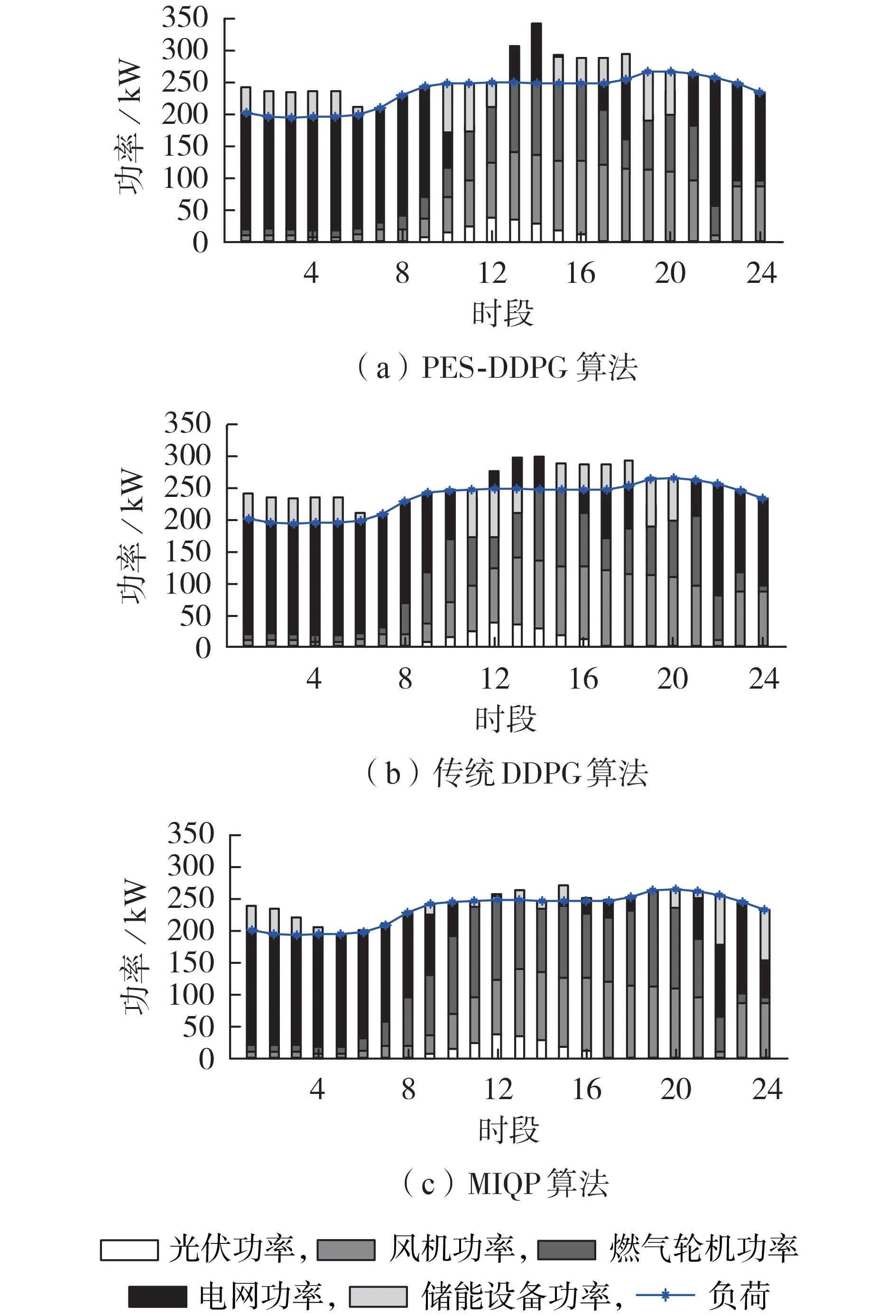
图3 3种算法优化结果Fig.3 Optimization results of three algorithms
4.3.2 优先经验存储策略分析
针对算例1 场景,PES-DDPG 算法和传统DDPG算法的收敛结果对比如图4 所示。由图可知,在传统DDPG 算法的训练后期,随机探索和经验池中的低奖励经验会导致算法收敛的不确定性,如果算法恰好在抽取到低奖励经验训练时停止,则可能无法得到满意的结果。

图4 PES-DDPG算法和DDPG算法的收敛结果对比Fig.4 Comparison of convergence results between PES-DDPG algorithm and traditional DDPG algorithm
在不同的初始条件下,采用传统DDPG 算法进行训练,其收敛结果如图5 所示。由图可知,在3 次训练中,算法均在训练1000轮左右取得了基本一致的奖励,但是随着训练次数的增加,经验池中随机抽取的普通经验改变了算法的收敛方向,当训练到1 500 轮时,训练结果变得更加糟糕,经验质量和训练终止的次数均会对算法的收敛结果产生随机性的影响。

图5 不同初始条件下传统DDPG算法的收敛结果对比Fig.5 Comparison of convergence results of traditional DDPG algorithm among different initial conditions
为进一步评估PES-DDPG 算法的收敛性,定义如下指标:
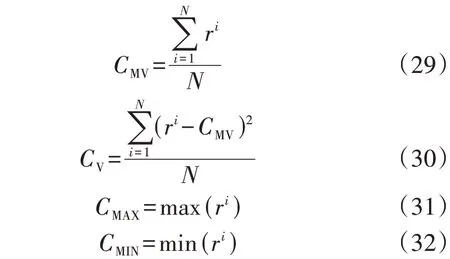
式中:CMV为收敛均值;ri为完成第i次训练时的奖励,在实际中可对奖励进行缩放;N为训练总次数,每次训练的初始条件不同;CV为收敛方差;CMAX为收敛最大值;CMIN为收敛最小值。
基于算例1的场景,分别采用PES-DDPG算法和传统DDPG算法进行100次训练,收敛性评价指标如表2所示。

表2 收敛性评价指标对比Table 2 Comparison of evaluation criteria for convergence
由表2 可知:在多次训练中,采用PES-DDPG 算法和传统DDPG算法得到的CMAX较接近,CMIN指标相同,这说明2 种算法的寻优能力相当,均能够找到最优解,同时也会陷入局部最优;采用PES-DDPG 算法得到的CMV大于传统DDPG 算法,这说明在多次寻优过程中采用PES-DDPG 算法取得较优结果的次数多于传统DDPG 算法;采用PES-DDPG 算法得到的CV约为传统DDPG 算法的70.2%,由于CV越大,寻优结果波动越大,因此,PES-DDPG算法的稳定性更高。
4.3.3 动态噪声搜索策略分析
本文应用动态噪声搜索策略设计对比策略,以验证搜索策略对PES-DDPG 算法收敛性的影响:静态策略,设置静态噪声,在前1 000 轮训练中噪声幅值保持不变,在后500 轮训练中噪声幅值为0;动态策略,设置线性动态噪声,参数λ=4×10-5。图6 为静态策略和动态策略下PES-DDPG 算法的收敛结果对比。由图可知:当在PES-DDPG 算法中采用静态策略时,训练至1 000 轮时噪声突然消失,改变了算法的收敛方向,有可能导致最终收敛到的策略比当前的策略差;而当在PES-DDPG 算法中采用动态策略时,在训练过程中噪声的影响逐步减弱,对算法收敛性产生的影响较小。
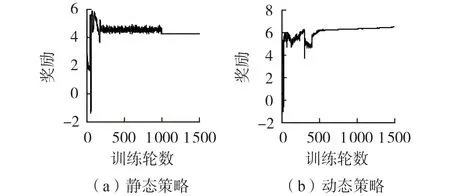
图6 静态策略和动态策略下PES-DDPG算法的收敛结果对比Fig.6 Comparison of convergence results of PES-DDPG algorithm between static strategy and dynamic strategy
此外,DDQN算法作为另一类基于值函数的DRL算法,本文探讨静态策略和动态策略对DDQN 算法收敛性的影响。该算法的静态策略是指在前1000轮训练中智能体以0.5 的概率随机选择动作,1 000 轮后智能体选择当前最大Q值所对应的动作;该算法的动态策略是指在训练开始时智能体按照动态衰减的概率随机选择动作,随着训练轮数的增加,随机选择动作的概率最终衰减为0.004,智能体不再随机选择动作,而是选择最大Q值所对应的动作。静态策略和动态策略下DDQN 算法的收敛结果对比如图7所示。由图可知:当在DDQN 算法中采用静态策略时,在前1 000 轮训练中奖励趋势几乎保持不变,每轮奖励在[-100,50]范围内波动;当在DDQN 算法中采用动态策略时,在前1000轮训练中获得的奖励逐渐提高,这说明算法逐渐寻找到了更好的策略,因此,在DDQN 算法中采用动态策略的搜索效果优于静态策略。
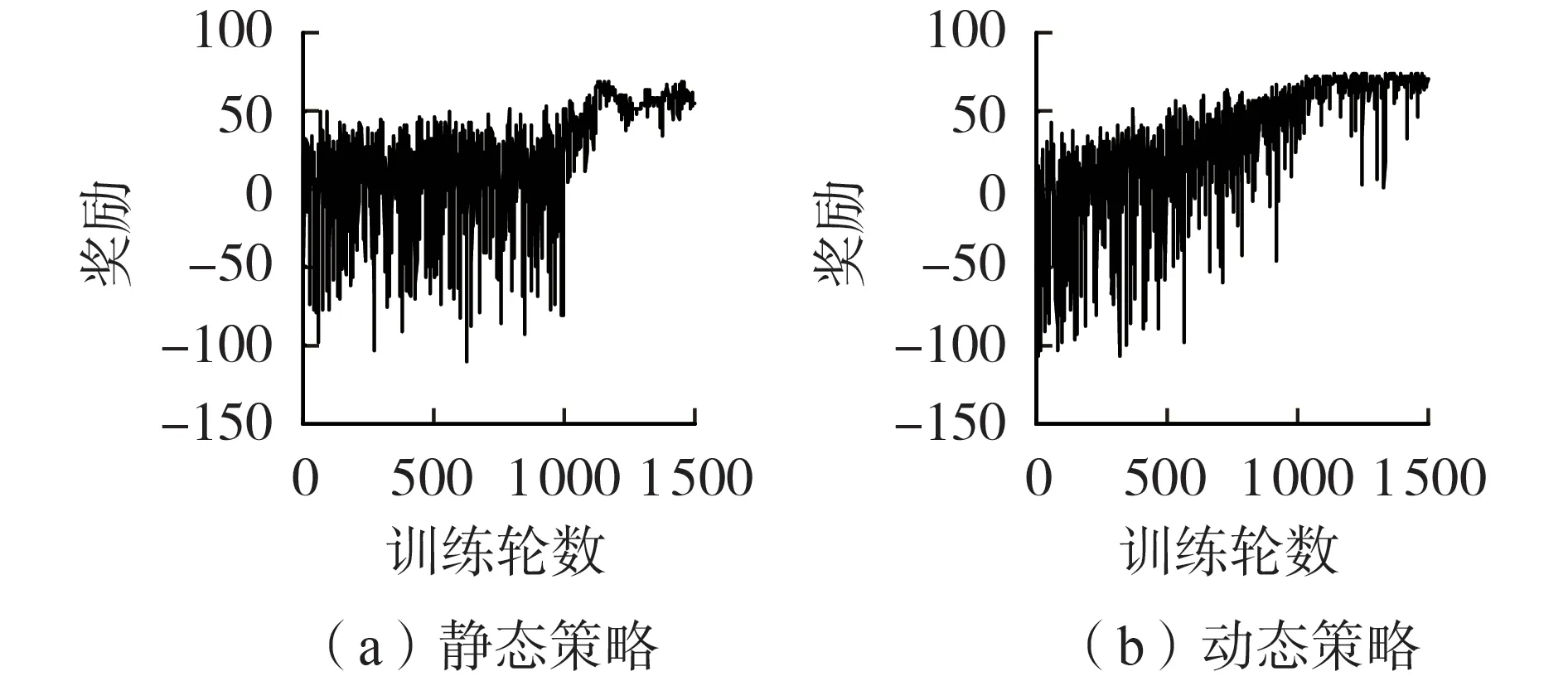
图7 静态策略和动态策略下DDQN算法的收敛结果对比Fig.7 Comparison of convergence results of DDQN algorithm between static strategy and dynamic strategy
分别在PES-DDPG 算法和DDQN 算法中采用静态策略和动态策略进行100 次训练,收敛性评价指标如表3所示。
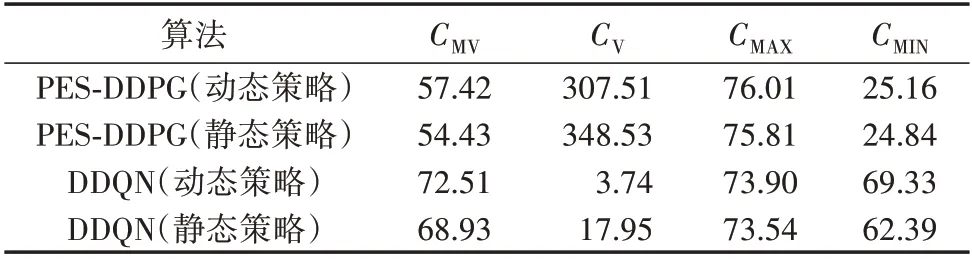
表3 静态策略和动态策略下的收敛性评价指标对比Table 3 Comparison of evaluation criteria for conver‐gence between static strategy and dynamic strategy
由表3 可知,在2 种算法中采用静态策略时,各项指标均比采用动态策略时的指标差,这说明动态策略提高了2 种算法的收敛性和寻优能力。值得注意的是,PES-DDPG 算法的收敛性更好,多次训练得到的奖励方差很小,而由于离散化动作空间,DDQN算法的寻优能力弱于PES-DDPG算法。
4.4 算例2结果及分析
鲁棒优化假设不确定性存在于不确定性集中,本文构造一种针对不确定性参数的最坏情况来实现最优求解。本算例中不确定集采用盒式形式,风、光、荷不确定集U的表达式为:
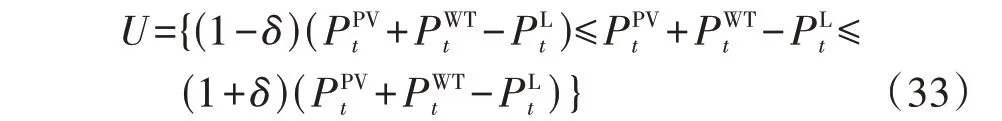
式中:δ为最大预测误差。
考虑风、光、荷不确定集下的系统能量优化,建立最恶劣的交互收益目标为:

当微电网内不确定性参数的预测误差分别为5%、10%、30%时,PES-DDPG 算法和鲁棒优化模型求解算法所得微电网收益如表4 所示,其中,鲁棒优化模型求解算法参考文献[20]。随着预测误差的增大,微电网收益均逐渐降低。采用PES-DDPG 算法比鲁棒优化模型求解算法得到的收益更高,且随着预测误差的增大,PES-DDPG 算法的优势更明显,其原因在于:预测误差越大,场景越极端,由于鲁棒优化最优解具有高度保守性,因此,极端场景降低了鲁棒优化性能,而PES-DDPG 算法是一种无模型和数据驱动的DRL 算法,其通过数据的训练学习最优控制策略,且可学习到封装在数据中的不确定性。在30%的预测误差下,采用PES-DDPG 算法可以比鲁棒优化模型求解算法提高约8.32%的收益。
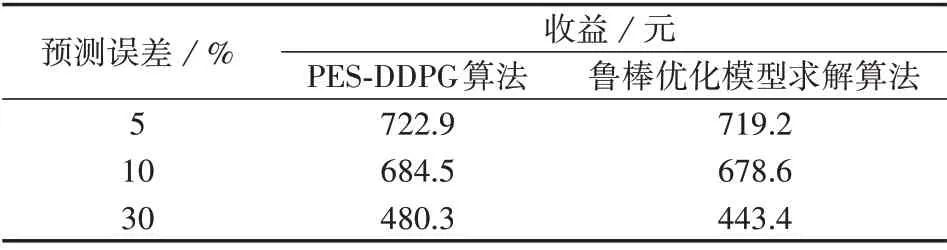
表4 不同预测误差下的优化算法结果比较Table 4 Result comparison between optimization algorithms under different prediction errors
2 种算法的平均计算时间如表5 所示。对于微电网设备优化问题,由于规模小以及复杂度低,求解器可以快速求解,但面对大规模变量及约束问题时,求解器的求解效率难以保证,而DRL 智能体具备实时优化的潜力。

表5 优化算法平均计算时间Table 5 Average calculation time of optimization algorithms
5 结论
本文采用DRL 算法求解微电网的优化运行问题,在算法层面,对传统DDPG 算法进行改进,提出PES-DDPG 算法,通过经验优先存储方法和动态噪声搜索策略提高了算法在训练过程中的收敛稳定性。训练完成的DDPG 智能体表现出了DDPG 算法处理连续变量的能力以及应对不确定问题时的优越性。通过算例验证了本文所提算法能够实现微电网的优化调度。
附录见本刊网络版(http://www.epae.cn)。
