基于隐式最大似然估计的风电出力场景生成
2022-11-19廖文龙杨文清
廖文龙,任 翔,杨 哲,杨文清,魏 超
(1. 奥尔堡大学 能源系,丹麦 奥尔堡9220;2. 国网冀北电力有限公司电力科学研究院,北京 100045;3. 哥伦比亚大学 统计学院,美国 纽约NY 10025;4. 国电东北新能源发展有限公司,辽宁 沈阳 110000)
0 引言
场景分析法是表征风电出力不确定性的重要方法之一,即通过对历史功率和点预测值进行概率建模,生成大量可能出现的随机场景,用来描述风电出力的不确定性[1]。通常,场景分析法产生的最恶劣场景可以被用于建立配电网的鲁棒优化模型并进行求解,从而得到一个保守的调度方案,以保证配电网的安全运行。因此,掌握风电出力潜在的变化规律,并基于点预测值生成一系列可能的风电出力场景,对配电网的调控、运行及优化具有重要的理论研究意义和实际应用价值。
现有风电出力场景生成的方法主要包括显式密度模型和隐式密度模型2 类。显式密度模型需利用历史风电出力曲线来拟合人为假设的概率密度函数,并通过蒙特卡罗法对该概率密度函数进行采样,从而获得风电出力随机场景,现有大部分风电出力场景生成的方法属于显式密度模型。文献[2]以威布尔分布表征风机输出功率的概率分布特征,利用蒙特卡罗抽样法生成风速的随机场景,并通过输出功率和风速间的函数关系获得风电出力场景。文献[3]采用Copula函数近似估计多座相邻风电场的联合概率密度函数,利用历史出力曲线拟合概率分布中的参数,并通过蒙特卡罗法抽样获得多座相邻风电场的随机场景。总体而言,显式密度模型过度依赖人为假设的概率密度函数[4],限制了生成的风电出力场景质量,这是由于大部分风电出力服从的实际概率密度函数难以用数学公式进行精确解析。此外,风电出力曲线服从的概率密度函数随着时间和区域的变化而呈现出较大的差异,这也导致显式密度模型存在无法大面积普及的问题[5]。相对而言,隐式密度模型无需显式地假设风电出力服从的概率密度函数,经过无监督学习和训练后,仅输入随机噪声就能产生服从潜在分布特征的风电出力曲线,通过微调模型的结构和参数,可以将模型迁移到不同区域风电出力场景的生成任务[6]。在可再生能源的出力场景生成领域中,现有的隐式密度模型主要包括隐马尔可夫模型HMM(Hidden Markov Model)、变分自动编码器VAE(Variational Auto-Encoder)、生成矩匹配网络GMMN(Generative Moment Matching Network)以及生成对抗 网 络GAN(Generative Adversarial Network)[7-9]。HMM 的优势在于推理过程具有清晰的物理含义,而且结构简单、算法复杂度低,但其对于输出变量的独立性假设导致其无法兼顾时间序列的上下文信息,从而难以计及风电出力曲线的时间相关性。VAE仅能近似估计风电出力曲线的对数似然的下界,这导致其生成的出力场景质量不高。GMMN的最大平均差异损失函数难以高效地处理高维的风电出力曲线,且其存在调参难度大等问题。GAN 在训练过程中容易出现生成器梯度消失以及梯度爆炸等现象,这些问题目前还没有有效的解决方案[6,10]。
隐式最大似然估计IMLE(Implicit Maximum Likelihood Estimation)是继VAE、GMMN 和GAN 之后,在计算机视觉领域中被广泛使用的一种深度生成模型[11]。相较于其他3 种方法,IMLE 以实际场景和其最近的生成场景为基础,构建平均距离最小的损失函数,不仅训练过程非常稳定,还能产生高质量的随机场景[12]。目前,IMLE 在风格迁移、图像修复以及数据增强等不同领域取到了较好的应用效果[13],但在风电出力场景生成中的应用仍处于起步阶段。理论上,IMLE 可以通过无监督训练学习到风电出力曲线的潜在规律,并生成大量可能出现的风电出力场景,为配电网的随机优化或鲁棒优化提供足够的数据支撑,但在实际应用中如何针对风电出力曲线的高维数据特征,设计出一种能够生成高质量预测场景的IMLE结构,还有待进一步研究。
在上述背景下,本文提出一种基于IMLE的风电出力场景生成方法。首先,针对风电出力曲线的数据特征,设计IMLE的损失函数和网络结构;然后,将风电出力场景的建模过程转化成一个非线性约束最优化问题,并通过遗传算法求解优化模型,从而获得一组可能的场景来表征未来风电出力的不确定性;最后,通过实际算例验证所提方法的有效性。
1 基于IMLE的场景预测
1.1 IMLE的优化损失函数
基于IMLE 的场景生成过程如附录A 图A1 所示,其主要思路是基于历史风电出力曲线训练出一个场景生成器,将服从先验分布的随机噪声映射成服从实际分布的风电出力场景,即场景生成器可视为随机噪声和风电出力场景之间的一种复杂映射函数。需要注意的是,本文先验分布不是预测误差服从的实际分布,而仅仅是一种容易采样的分布,如常见的高斯分布。本文将损失函数定义为实际风电出力曲线和生成场景之间的某种相似度,用于更新场景生成器的权重。
不失一般性,本文先验分布选择简单、容易采样的高斯分布,采样过程和映射过程表示如下:

式中:Z为高斯噪声;X′为新生成的风电出力场景;g(· )为风电出力场景的生成器。
利用分布的形式表征生成模型中高斯噪声Z和实际的风电出力场景X之间的关系:

式中:q(X)为生成器产生的场景服从的分布;q(Z)为高斯分布;q(X|Z)为任意的条件高斯分布或者狄拉克分布。
显然,式(2)的积分形式可以表征很多复杂的分布,理论上而言,它能拟合任意分布[14],其中也包括风电出力曲线服从的概率分布。在得到q(X)的分布形式后,只需要利用最大似然估计求出未知的参数,就可以完成风电出力场景的生成任务。
令实际的数据分布为p(X),则最大似然估计的目标可以表示为:

特别地,当q(X|Z)为狄拉克分布(狄拉克分布可视为一个方差趋于0 的高斯分布)时,可以将式(2)改写成以下形式:

IMLE 的目标是最大化式(2),但是神经网络的损失函数往往采用梯度下降法进行优化,因此,令IMLE 的损失函数为式(2)的相反数。进一步,将式(4)代入式(2)中,并忽略对训练结果不产生影响的常数,得到损失函数的分布形式为:
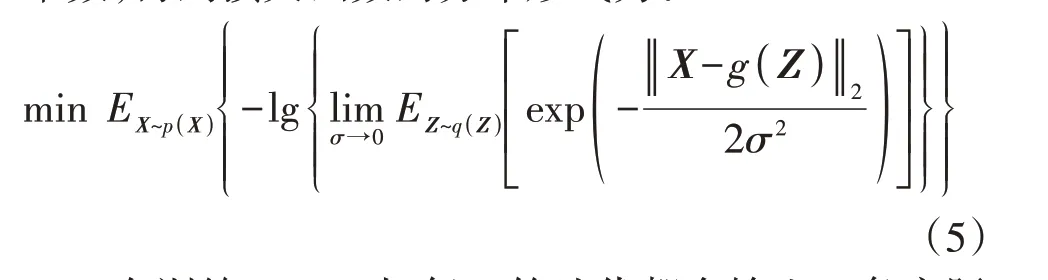
在训练IMLE时,每一轮迭代都会输入m条实际风电出力曲线X1、X2、…、Xm和n个高斯噪声样本Z1、Z2、…、Zn,将其代入式(5),得到损失函数Lloss的最终计算公式为:
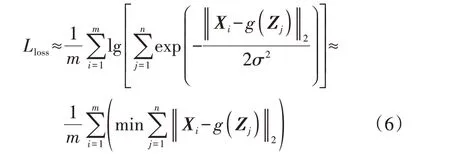
1.2 场景生成器的组成结构
卷积神经网络是一种利用卷积运算提取数据特征的前馈神经网络,它的出现极大地推动了深度学习的进步,在人工智能技术的发展中有着重要地位。卷积神经网络由于具有强大的特征提取和表征能力,被广泛地应用于文本分类、异常检测、稳定评估和语义分割等领域中。本文利用卷积神经网络来构建IMLE 的场景生成器结构。场景生成器的主要功能是将低维的高斯噪声映射成高维的风电出力曲线,它主要由反卷积层和全连接层组成。反卷积层的可视化如附录A图A2所示。
首先,对输入特征Xtran和权重矩阵Wtran执行反卷积运算,获得一个混合特征矩阵,然后,将该矩阵和偏置向量Btran进行求和,并通过激活函数ftran(·)处理后得到该层的输出向量Ytran,如式(7)所示。
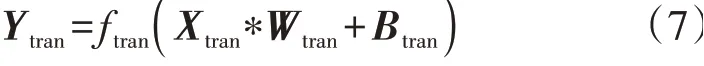
式中:“*”表示反卷积运算。
全连接层的运算过程与反卷积层相似,即将权重矩阵Wdense和输入特征Xdense相乘,再将该乘积和偏置向量Bdense进行求和,并通过激活函数fdense()· 进行非线性变换获得输出向量Ydense,如式(8)所示。

1.3 优化风电出力场景的建模过程
显然,将高斯噪声输入1.1 节的IMLE 中所得到的大量风电出力场景是无序的,即生成的风电出力曲线和传统点预测模型得到的预测值没有相互关联。为了充分利用过去t-h时刻到t时刻之间的历史风电出力以及基于传统点预测模型获取的未来t+1时刻到t+k时刻之间的风电出力预测值,本文建立一个优化问题。令Xhist=(xt,xt-1,…,xt-h)为过去t-h时刻到t时刻之间的历史风电出力,Xpred=(xt+1,xt+2,…,xt+k)为基于传统点预测模型获取的未来t+1 时刻到t+k时刻之间的风电出力预测值,xs(s=t-h,t-h+1,…,t+k)为s时刻的风电出力。优化问题的目标是通过一个生成模型(本文的生成模型是IMLE)产生N个可能出现的风电出力场景S=(X′1,X′2,…,X′N)来表征风电出力曲线的不确定性,X′i(i=1,2,…,N)为第i个可能出现的风电出力场景。为了方便描述,将生成的每个风电出力场景拆分成X′former和X′latter这2个部分:

式中:X′former、X′latter分别为t-h时刻到t时刻、t+1 时刻到t+k时刻之间生成的风电出力场景;x′s(s=t-h,t-h+1,…,t+k)为s时刻生成的风电出力场景。
一般情况下,生成模型产生的风电出力场景S需要满足以下2 个条件,才能用于表征风电出力曲线的不确定性:过去t-h时刻到t时刻之间的历史风电出力Xhist和IMLE 生成的风电出力X′former要足够相似;生成的风电出力X′latter在未来t+1时刻到t+k时刻之间要围绕在基于传统点预测模型得到的风电出力Xpred的周围。
需注意的是,风电出力场景S一般不从历史风电出力曲线上直接筛选,而是利用历史风电出力曲线训练一个生成模型产生,其主要原因在于历史风电出力曲线的数据量往往难以全面覆盖未来风电出力曲线可能出现的变化情况,而生成模型通过学习历史样本的特征,不仅可产生和训练集有相似特征的风电出力曲线,还具备一定的泛化能力,即可以产生训练集中没有但未来可能出现的风电出力场景。
为了从IMLE 生成的大量场景中筛选出满足上述2 个条件的风电出力场景,可以构建一个非线性约束最优化问题:
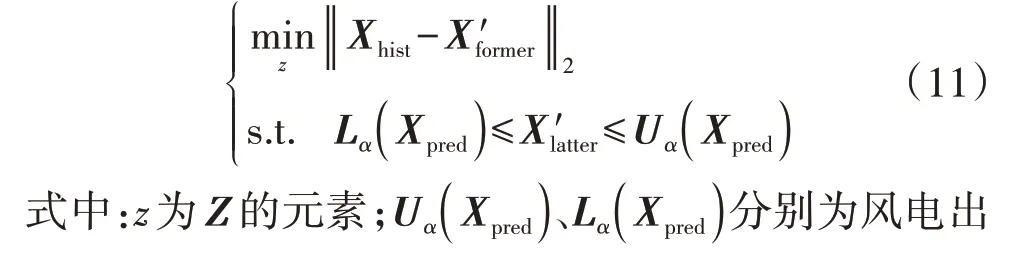
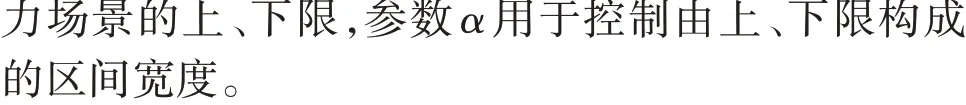

2 本文方法主要流程
基于IMLE 的风电出力场景生成流程如附录A图A3所示。具体步骤如下。
1)划分和规范化原始数据。随机选取80%和10%的风电出力曲线,分别作为训练集和验证集,剩余部分作为测试集,用于评估IMLE的性能。在将风电出力曲线用于训练IMLE 的场景生成器和点预测模型之前,将风电出力曲线和对应的气象因素进行标准化处理,以避免场景生成器和点预测模型的损失函数出现无法收敛的问题,本文利用离差标准化法对原始的数据进行线性变换,使其落在[0,1]区间。

3)训练点预测模型。考虑到未来t+1 时刻到t+k时刻的风电出力预测值和过去t-h时刻到t时刻的风电出力曲线以及相应的环境因素(如风速、气温和压强等)具有较强的相关性[15],将过去t-h时刻到t时刻的风电出力曲线和相应的环境因素作为输入数据,训练一个点预测模型来获取未来t+1 时刻到t+k时刻的风电出力预测值。经过多次重复实验发现,长短期记忆LSTM(Long Short-Term Memory)网络对于短期风电出力预测具有较高的精度[16],因此,本文选择LSTM 网络作为点预测模型来获取未来k个时刻的短期风电出力预测值。利用试探法调整网络的结构和参数,确定LSTM网络的结构如下:隐含层由4个LSTM 网络层组成,输出空间的维度分别为20、15、10 和10;将神经元个数为1 的全连接层作为输出层,输出层的激活函数为S型函数(Sigmoid),其他层的激活函数均为修正线性单元ReLU(Rectified Linear Unit)函数。
4)利用遗传算法优化获取风电场景。遗传算法是根据生物进化过程的规律开发出来的一类种群进化算法,由于其具有很强的全局寻优能力,被广泛应用于信号处理、组合优化及机器学习等不同学科领域,因此,本文利用该算法来优化式(13),得到一组可能出现的风电出力场景,用于表征风电出力曲线的不确定性。利用试探法调整网络参数,确定遗传算法的结构和参数如下:优化变量为高斯噪声z,适应度函数为式(13),染色体的种群大小为50,交叉运算概率为0.9,变异运算概率为0.1,算法迭代次数为400。
5)评价算法的性能。本文借鉴区间预测的相关指标来评估生成的风电出力场景效果。
预测区间覆盖率FICP(Forecasting Interval Coverage Percentage)为实际风电出力落在由生成场景集组成的预测区间内的概率,表达式如式(14)所示。当参数α固定时,FICP越大,算法的性能越好。

式中:FFICP为FICP;Ntest为测试集中的样本数;ci,j为布尔型变量,当第i个样本的第j个预测值落在区间内时,其值为1,否则为0。
显然,FICP和参数α呈正相关,为了避免单一追求FICP,而无限制地增大参数α,考虑预测区间平均宽度FIAW(Forecasting Interval Average Width)的限制,表达式如式(15)所示。当FICP 固定时,FIAW越小,算法的性能越好。
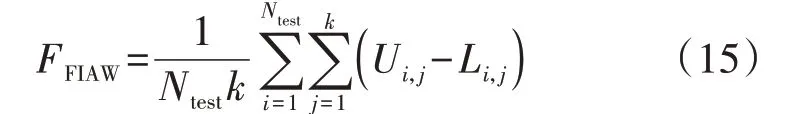
式中:FFIAW为FIAW;Ui,j、Li,j分别为第i个样本的第j个预测值对应的上、下界。
3 算例分析
3.1 数据和仿真平台
为了验证IMLE 对于风电出力场景生成的有效性,利用美国可再生能源实验室收集的某地区风电场实际运行数据进行仿真和分析[17]。该风电场的经度为-124.37°,纬度为40.50°。数据集记录了2009年1 月1 日到2012 年12 月31 日期间该风电场的风电出力、风向、风速、空气温度和压强,它们的时间分辨率均为10 min,即数据集共有1 460 个样本,每个样本包含5 条维数为1×144 的时间序列曲线。相较于现有研究[6,8-10],本文所用的数据量更加充足,可以确保训练的生成模型具有一定的泛化能力。
所提方法的集成开发环境为Spyder 3.6,编程语言为Python,用到的深度学习框架为Keras 2.0 和Tensorflow 1.0。计算机硬件配置为:Intel(R)Core(TM)i3-3110M,双核CPU,主频为2.4 GHz,内存容量为6 GB。
3.2 IMLE的结构和参数
以单座风电场出力场景生成为例来说明IMLE的网络结构和参数特征。针对风电出力曲线的数据特点,利用文献[18]中的试探法进行多次实验,找到适合的场景生成器网络结构,见附录A图A4。
场景生成器的输入数据是维数为1×32 的高斯噪声向量。首先,经过神经元个数为288 的全连接层和Python 自带的Reshape 函数处理后,输出一个维数为3×3×32 的张量。然后,依次连接卷积核个数为32、16和1的3个反卷积层,其中,前2个反卷积层的卷积步长和卷积核个数均为2×2,最后1个反卷积层的卷积步长和卷积核个数均为1×1。为加速收敛和减缓过拟合,在各反卷积层后面加入一个动量为0.8 的批量规范化层。最后,利用Reshape 函数将卷积层输出的数据转换成一条维数为1×144 的风电出力曲线。关于激活函数,除最后一个反卷积层采用tanh函数外,其他层均采用ReLU 函数。值得一提的是,附录A图A4的场景生成器结构有一定的扩展性,当风电出力曲线的采样时间分辨率不是10 min 时,可对IMLE的结构和参数进行微调,使其适用于不同采样时间分辨率对应的风电出力场景生成任务。
在训练过程中,IMLE 的目标是通过不断改变网络权重,使得场景生成器能够对输入的高斯噪声进行各种非线性变换,从而映射实际的风电出力曲线,因此,在初始化场景生成器的网络结构后,需要选取一种合适的梯度下降算法(优化器)对损失函数进行优化,常见的优化器包括SGD 算法、RMSprop 算法、Adagrad 算法、Adadelta 算法、Adam 算法、Adamax 算法和Nadam算法。为了选取适合风电出力场景生成的优化器,设置最大迭代次数为800,分别对带有不同优化器的场景生成器进行30 次独立重复实验,并统计验证集的平均损失函数值,见附录A 图A5。由图可知:以SGD 算法、RMSprop 算法、Adamax 算法、Nadam 算法和Adam 算法作为优化器时,IMLE 的场景生成器均可获得较好的性能,其中,Adam 算法得到的验证集损失函数值略小于其他优化器,风电出力场景生成的性能最好;Adagrad 算法和Adadelta 算法对应的验证集损失函数值明显大于其他优化器,训练过程中损失函数值难以收敛,这表明这2 种优化器不适用于基于IMLE的风电出力场景生成任务。
在训练神经网络前,需要设置合适的学习率来控制场景生成器的权重更新速度,为此,分别使不同学习率的场景生成器迭代800 次,并对验证集的损失函数值进行可视化,结果见图1和附录A图A6。
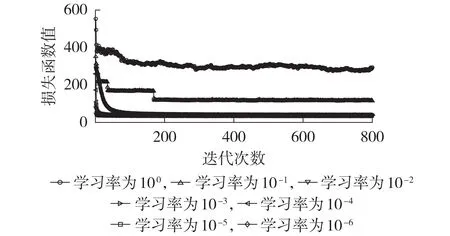
图1 不同学习率的训练过程Fig.1 Training process of different learning rates
由图1 和图A6 可知,随着学习率的下降,IMLE的损失函数值先减小后增大,当学习率为10-3时,IMLE 对应的损失函数值最小,这表明此时的场景生成器性能最好,当学习率大于10-1时,损失函数值明显大于极小值,且损失函数值出现一定的波动性而无法收敛,当学习率小于10-6时,虽然能保证算法的收敛性,但会极大降低优化速度,因此,对于风电出力的场景生成任务,IMLE 的学习率取值一般在10-5~10-2之间。此外,由图1 可知,生成器的损失函数值随着迭代次数的增加而快速减小,在选取合适的学习率的前提下,在迭代次数大于50 后,IMLE的场景生成器的损失函数值趋于一个常数,这说明IMLE 已经训练成熟,总体而言,IMLE 的收敛速度非常快,而且整个训练过程非常稳定,不会存在GAN的损失函数值难以收敛的问题[6]。
3.3 IMLE的性能分析
为验证所提方法对于不同时间尺度的有效性,参考文献[7,10]的仿真框架,从风电出力场景的覆盖情况及自相关函数两方面对所提方法进行验证。
自相关函数描述同一时间序列信号在不同时刻的相关性,其常被用于表征风电或光伏出力曲线的时间相关性。首先,随机选取一个测试集样本,利用遗传算法优化高斯噪声,得到一组由IMLE生成的风电出力场景(本文以50 个场景为例)。然后,利用自相关函数来评估实际场景和生成场景的时间相关性。未来8 h 的风电生成场景和自相关函数如图2所示,其他时间尺度的仿真结果如附录A 图A7和图A8所示。其中,自相关函数的数学公式为:
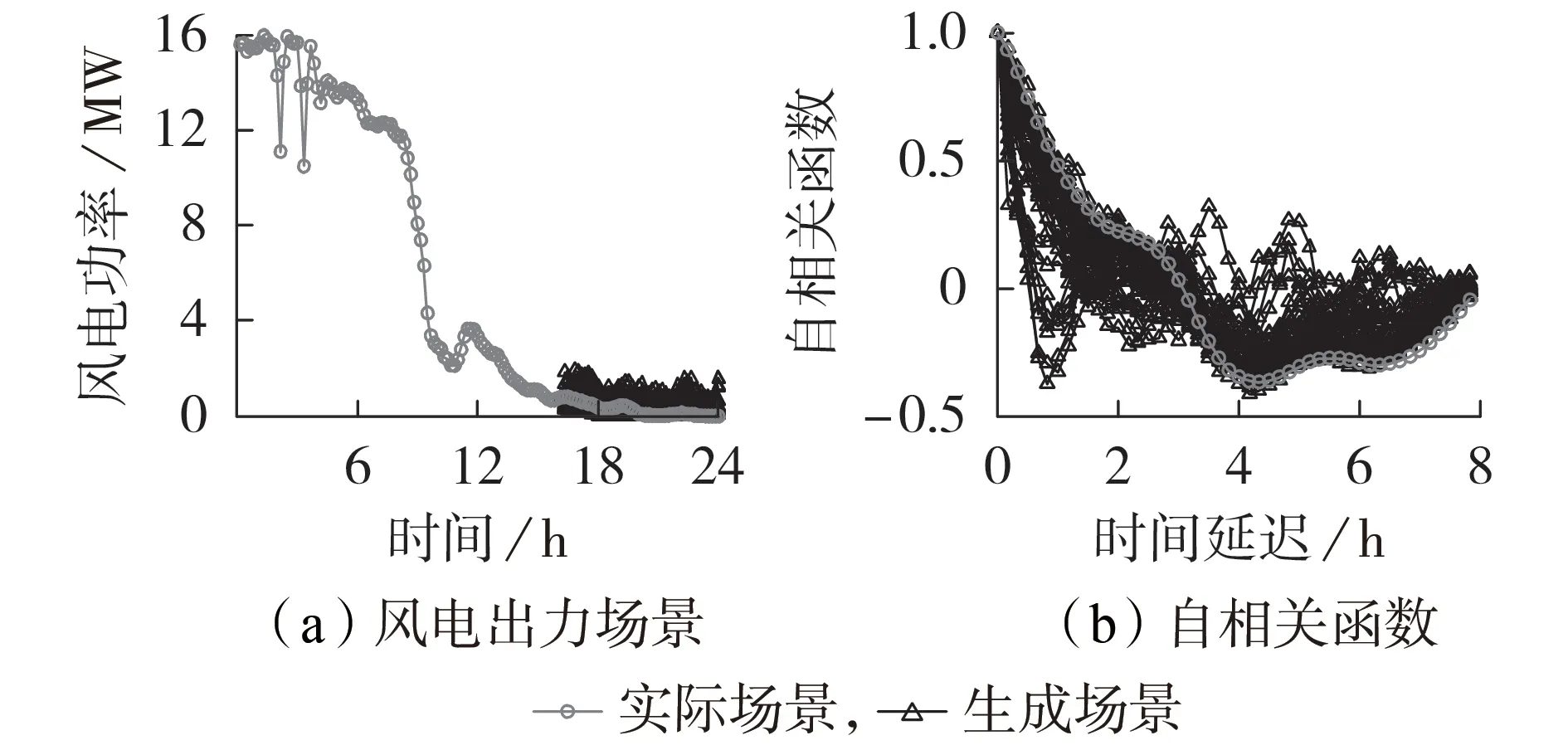
图2 未来8 h的风电生成场景和自相关函数Fig.2 Wind power generation scenario and auto-correlation function for next 8 hours

式中:E[ ·]表示求期望值;τ为时间延迟(2个不同时刻风电出力间的时间间隔);σx为风电出力xt的标准差;μ为风电出力xt的均值。
由图2、附录A 图A7 和图A8 可知:只需要调节模型中的参数k,采用所提方法就能够生成不同时间尺度的风电出力场景,这些生成场景覆盖了实际的风电出力曲线,这说明生成场景包含了可能出现的随机场景;对比不同时间尺度的风电出力场景发现,风电出力场景的预测区间随着时间尺度的变长而加宽,这是由于时间越长,点预测模型的预测精度越低,风电出力的不确定性越大,为了覆盖实际的风电出力曲线,往往需要加宽风电出力场景对应的预测区间;在信号不存在自相关的情况下,每个数据点会完全独立于之前的值,数据点会随机上、下跳跃,图2 中实际场景对应的自相关函数曲线比较光滑,且变化趋势较为平缓,这是由于风电出力曲线具有很强的时间相关性,当前时刻的出力值会受到之前时刻出力值的影响;生成场景和实际场景对应的自相关函数非常接近,这表明生成场景和实际场景在不同尺度范围具有相似的时间相关性。
皮尔逊相关系数[8]常用于分析IMLE 生成的风电出力场景和实际场景是否具有相似的时间相关性,本文选用皮尔逊相关系数来度量风电功率在不同时刻的线性相关性,其数学公式为:

式中:pxy为风电出力在2 个时刻之间的皮尔逊相关系数为其中一个时刻风电出力x的平均值;yˉ为另一个时刻风电出力y的平均值。
首先,以测试集的全部风电出力曲线为基础,计算风电出力在不同时刻之间的皮尔逊相关系数,从而得到一个维数为144×144 的皮尔逊相关系数矩阵。然后,将和测试集样本数量相同的高斯噪声向量输入IMLE 中,生成相同数量的风电出力场景,并计算它们对应的皮尔逊相关系数矩阵。最后,分别利用热力图对2 个皮尔逊相关系数矩阵进行可视化分析,如附录A 图A9 所示。由图可知:相邻时刻风电出力间的皮尔逊相关系数较大,而时间间隔较长的风电出力间的皮尔逊相关系数较小,这说明风电出力之间的线性相关性会随着时间间隔的变长而减弱;虽然生成风电出力场景的时间相关性比实际场景的时间相关性稍有提高,但整体符合历史数据的相关性规律,这进一步地验证了IMLE生成的风电出力场景可以捕获实际风电出力曲线的时间相关性。
除直接对比风电出力曲线的时间相关性外,还可从统计学角度对IMLE 生成的风电出力场景进行关于概率分布特征的对比。将足够数量(以1600个为例)的高斯噪声向量输入IMLE 中,生成相应的风电出力场景,并对比数据集中的1460个实际场景(若仅用测试集中的样本,则会因样本数过少而导致无法完全表征风电出力曲线的概率密度,因此,此处使用数据集的全部样本)和IMLE生成的1600个风电出力场景对应的概率密度函数和累积分布函数,见图3。
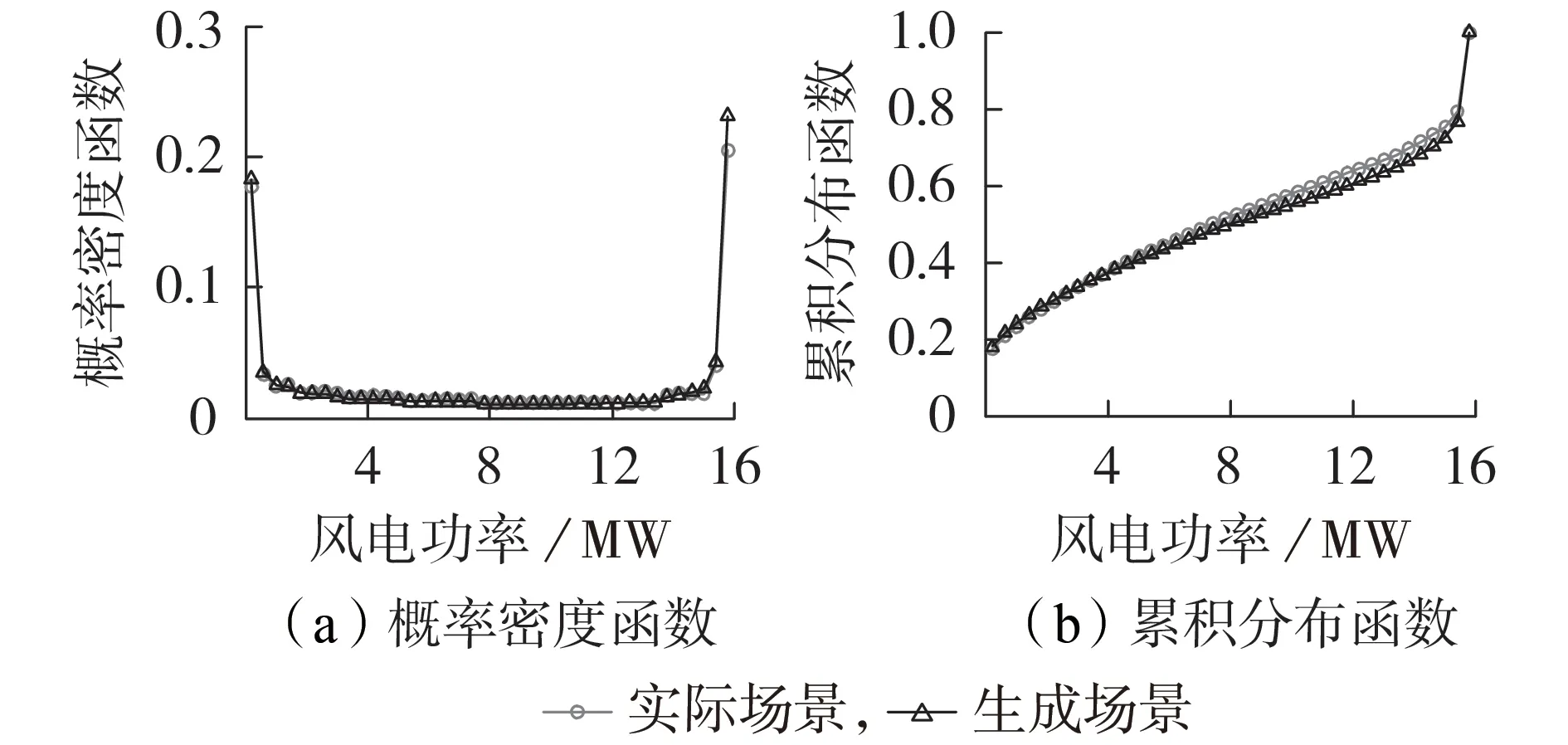
图3 不同场景的概率分布Fig.3 Probability distribution of different scenarios
由图3 可知,对于风电功率较大的情况(即大风的场景),IMLE 的概率密度函数值略小于实际值,这说明IMLE偏向于生成常见的风电出力场景,对于大风的场景,IMLE 生成的数据稍微少于实际情况。总体而言,IMLE 生成的风电出力场景的概率分布和实际场景的概率分布基本相同,这表明IMLE除了可以学习到实际风电出力场景的形状特征和时间相关性以外,还能兼顾其分布规律,以无监督学习的形式实现风电出力场景的概率建模过程。
3.4 不同方法的对比验证
为了进一步验证所提方法的有效性,以生成未来24 h的风电出力曲线为例,利用LSTM网络获得未来24 h的点估计值,并以遗传算法来搜寻合适的风电出力场景。参数α=1.1 时的风电出力场景见图4,α为其他值时的仿真结果见附录A图A10和图A11。
由图4、附录A 图A10 和图A11 可知:所提方法可以通过对参数α的合理调整,实现对FIAW 和FICP 的平衡。α越小,FIAW 也越小,但FICP 不高,随着α的增大,FIAW 随之增大,但FICP 也会有所提高,具体地,当α=1.3 时,生成的风电出力场景接近于点预测值,但未能覆盖实际情况,而当α=1.5 时,预测场景可以覆盖实际风电出力曲线,但曲线的集中性较低,即FIAW较大。

图4 α=1.1时的风电出力场景Fig.4 Wind power output scenarios when α is 1.1
进一步,本文将IMLE 与常用的显式密度模型(本文选取高斯Copula 函数模型)和隐式密度模型(本文选取GAN)进行对比分析。高斯Copula 函数模型和GAN 的结构和参数也利用文献[18]中的试探法进行多次实验确定。GAN 由场景生成器和场景判别器组成[6],其中,场景生成器的结构和参数与IMLE 相同,如附录A 图A12 所示,场景判别器的输入数据是维数为1×144 的风电出力场景,然后利用Reshape 函数对其进行格式变换,并经过4 个卷积层、1 个平坦层和全连接层处理后,输出1 或者0,分别表示输入的场景为真或假,优化器为Adam 算法,迭代次数为10 000。采用高斯Copula 函数模型建立风电功率相关性模型,风电功率相关性模型的参数和原理可参考文献[19]。
计算不同时间尺度以及不同参数α对应测试集的平均FICP和FIAW,如表1所示。
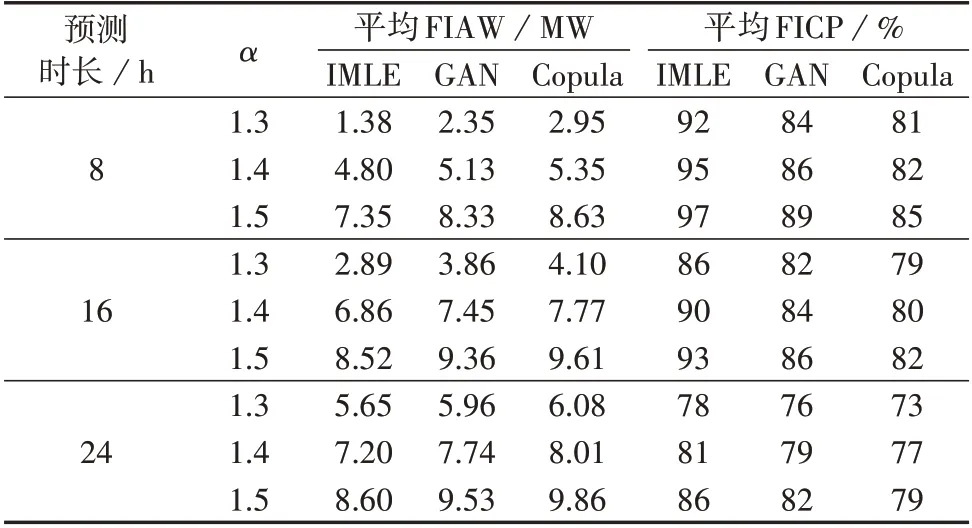
表1 不同参数对应的平均FICP和FIAWTable 1 Average FICP and FIAW for different parameters
由表1 可知:在同一参数α取值下,预测时长越短,平均FIAW 越小,平均FICP越高,因此,当预测时长较短时,在平均FICP 足够高的前提下,参数α可以设置得小一些,以减小平均FIAW;比较不同时间尺度对应的平均FICP 和平均FIAW 发现,随着预测时长的增长,平均FIAW 增大,平均FICP 降低,这是由于预测时长越长,点预测模型的预测误差越大,尤其是预测时长大于12 h后(以预测时长为16 h为例),在确保平均FICP 大于90%的前提下,平均FIAW 在6.86 MW 以上,已较大程度地偏离了实际风电出力曲线,出现这种现象的主要原因是本文使用的数据集仅包含同一风电场的历史出力曲线和对应的环境因素,未能计及相邻风电场对点预测模型的影响,因此,为了使IMLE能够准确地表征更长时间尺度范围的风电出力的不确定性,可以考虑利用相邻风电场的历史数据来提高点预测模型的精度;对比3 种模型在不同时间尺度和不同参数α下的平均FIAW 和平均FICP 发现,相较于GAN 和高斯Copula 函数模型,IMLE 的平均FIAW 要小,而平均FICP 要高,如当预测时长为8 h 且α=1.3 时,IMLE 的平均FIAW 仅分别为GAN 和高斯Copula 函数模型的58.72 % 和46.78%,而平均FICP 却比GAN 和高斯Copula 函数模型分别高出8%和11%。上述结果表明IMLE 比GAN 和高斯Copula 函数模型更加适用于风电出力场景生成的任务。
3.5 不同风电场的对比验证
为验证所提方法对不同风电场的适应性,选用美国可再生能源实验室收集的另外一个风电场数据集进行仿真和分析。该风电场的经度为-122.33°,纬度为37.19°。数据集的其他参数和3.1 节中风电场数据集相同。以24 h 的时间尺度为例,IMLE、GAN 以及高斯Copula函数模型在不同参数α下测试集的平均结果如表2所示。

表2 不同参数对应的平均结果Table 2 Average results for different parameters
由表2 可知,IMLE、GAN 以及高斯Copula 函数模型对该风电场的预测结果指标波动不大,而且相较于GAN 和高斯Copula 函数模型,IMLE 在不同参数α下的平均FICP 均较高,平均FIAW 也均较小,这说明所提方法对不同风电场具有一定的适应性。
4 结论
为了提升风电出力场景生成的精度,本文提出一种基于IMLE 的风电出力场景生成方法。利用美国可再生能源实验室收集的实际风电场运行数据进行仿真,得到如下结论。
1)IMLE 的优化器和学习率等参数对风电出力场景生成的性能有较大影响。Adagrad 算法和Adadelta 算法不适用于IMLE 的风电出力场景生成任务,以Adam 算法作为优化器,可以使得IMLE 风电出力场景生成的性能最好。此外,学习率太低会导致损失函数值出现一定的波动性,甚至无法收敛,同时也会降低优化速度。对于风电出力场景生成任务,IMLE的学习率取值一般在10-5~10-2之间。
2)IMLE生成的风电出力场景不仅可模拟实际风电出力曲线的概率分布特征,还可兼顾风电出力曲线的时间相关性。只需调节模型中控制时间尺度的参数,所提方法就能生成不同时长的风电出力场景。
3)所提方法可以通过对参数α的合理调整,实现对FIAW 和FICP的平衡。相较于Copula函数模型和GAN,IMLE 具有更小的FIAW 和更高的FICP,这说明IMLE 比现有方法更加适用于风电出力场景生成的任务。此外,算例分析结果表明,所提方法对不同风电场具有一定的适应性。
本文初步探索和分析了IMLE 在风电出力场景生成中的应用。关于IMLE的扩展工作,一方面可尝试将所提方法扩展至光伏出力和电力负荷的场景生成任务,并将所提方法生成的随机场景应用于配电网的鲁棒优化问题中[20],另一方面,可利用相邻风电场的历史数据来提高点预测模型的性能,使得所提方法适用于长时间尺度的风电出力场景生成任务。
附录见本刊网络版(http://www.epae.cn)。
