基于YOLOv5的安全帽检测研究
2022-11-18史德伟郭秀娟
史德伟,郭秀娟
吉林建筑大学 电气与计算机学院,长春 130118
0 引言
随着我国基础设施的快速发展,建筑工地事故也逐渐有所增加.在安全生产规范中,明确指出进入施工场地必须佩戴安全帽.佩戴安全帽可以在工程作业中有效保护施工人员头部,故佩戴安全帽是进入建筑工地的关键.常用的安全帽佩戴检测方法主要使用人工巡查以及视频监控等方式,在实际操作中,因施工环境复杂以及人员走动,只依靠人工巡查不仅会加大成本,还存在效率低、出现漏检等情况.就目前建筑工地的视频监控来看其识别率低且实时性差.目前,针对这些问题使用监控摄像头,通过传统的人工智能算法实现对建筑工地未佩戴安全帽人员监测可以有效抑制安全帽漏检的问题.但因环境复杂导致现阶段安全帽佩戴检测准确率较低,不符合实际生产环境的监测需求.因此,应用现代人工智能技术,实现安全帽戴检以确保施工人员安全,对提高安全生产治理具有重要意义.
1 安全帽识别现状
随着人工智能算法的发展,深度学习在各个领域有着广泛的应用.因此,在安全帽检测应用领域中,学者们应用深度学习的方法对其展开了研究.Kelm 等[1]人通过移动射频识别人员的个人防护设备是否合规.但是射频识别阅读器具有一定的局限性,能检测到安全帽与工人,不能确定工人是否正确佩戴安全帽.刘晓慧等[2]人以支持向量机(SVM)为模型,通过肤色检测定位和Hu矩阵为特征向量来实现安全帽检测.Wu 等[3]人提出了一种由局部二值模式(LBP)、Hu矩阵不变量(HMI)和颜色直方图(CH)组成的基于颜色的混合描述子,用于提取不同颜色(红、黄、蓝)头盔的特征.施辉等[4]人基于YOLOv3,利用图像金字塔结构获取不同尺度的特征图进行位置和类别预测,对目标帧参数进行聚类用这种方法实现安全帽佩戴的检测.
本文以YOLOv5 网络模型为主体,将是否佩戴安全帽作为检测任务.实验表明,该模型下的检测具有良好的鲁棒性以及较高的准确度.
2 YOLOv5
YOLO网络是为目标检测而设计的网络.由于其较比大多深度网络计算速度更快,且具有良好的实时性,故在工业中有良好的应用前景.而YOLOv5是YOLO系列经过迭代更新的最新版本,所以本文选择YOLOv5进行研究.YOLOv5的网络结构如图1所示,它是由主干网络(Backbone)、颈部(NECK)以及输出(Output)3个部分组成.其目标检测原理可以概括为通过主干网络提取特征值,将特征值进行融合,再对图像特征进行预测,最后生成预测类别,并返回目标位置的边框坐标[5].
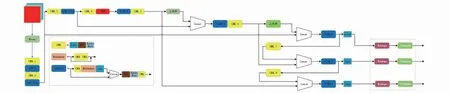
图1 YOLOv5的网络结构Fig.1 Network structure diagram of YOLOv5
主干网络主要包括切片结构(Focus)、卷积模块(Conv)、瓶颈层(C3)以及空间金字塔池化(SPP)[6].切片结构是将高分辨率图像中抽出像素点重新构造到低分辨率图像中,该模块主要是用来加快计算速度.SPP模块分别采用5/9/13的最大池化,再进行concat融合,提高感受野.在颈部网络中使用了FPN+PAN的结构,较比之前版本,虽然总体结构没有改变,但其增加了sp2结构,加强了特征融合的能力.最后在输出端使用了损失函数GIOU_Loss,GIOU函数同时包含了预测框和真实框的最小框的面积,其计算如公式(1)所示.该函数可以增强其检测能力.
CIOU_Loss=1-(IOU-Distance_22Distance_C2-v2(1-IOU)+v)
v=4π2(arctanwgthgt-arctanwphp)2
(1)
3 实验过程
首先准备数据集,通过网上采集以及拍摄整理得到,然后对其筛选和标记,达到实验要求.通过YOLOv5算法进行训练,得到最优的检测模型,由最优的检测模型对测试集数据进行测试,最终得到结果.
3.1 实验数据集制作
数据集的制作主要分为数据采集和整理、数据的预处理、数据的筛选和数据集标注[7].本实验使用labelImg标注图片.本次实验将数据集分类为训练集和测试集,其中训练集为5 000张图片,测试集为1 212张图片.标注类别分为两类,包括佩戴安全帽的施工人员与未佩戴安全帽的施工人员.图2为数据集的分析可视化结果图,图2(a)为施工人员和戴安全帽的施工人员的分布图;图2(b)是中心点分布图;图2(c)是数据集宽高分布图.
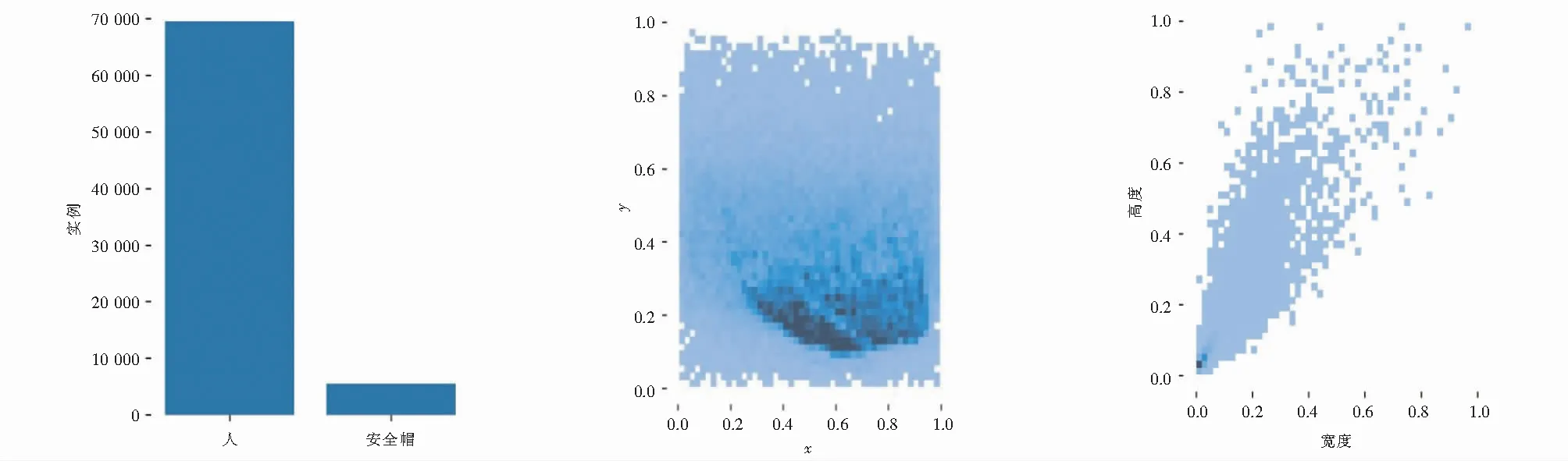
(a) (b) (c)
3.2 实验平台
本文的实验环境为:Intel(R) Xeon(R) Gold 6130H CPU @ 2.10GHz,32GB运行内存,Nvidia Geforce 2080ti,ubuntu16.04,64位操作系统 , Pytorch1.9.0.编程语言为 Python3.8,GPU 加速软件Driver Version: 495.46 ,CUDA Version: 11.5.共训练200轮.
4 实验结果分析
如图3所示,图3(a)代表训练集位置损失;图3(b)代表训练集置信度损失;图3(c)代表训练集类别损失.由图3可知,训练效果达到了较好的拟合状态,训练集位置损失稳定在0.032左右,置信度损失稳定在0.049左右,类别损失稳定在0.002左右.
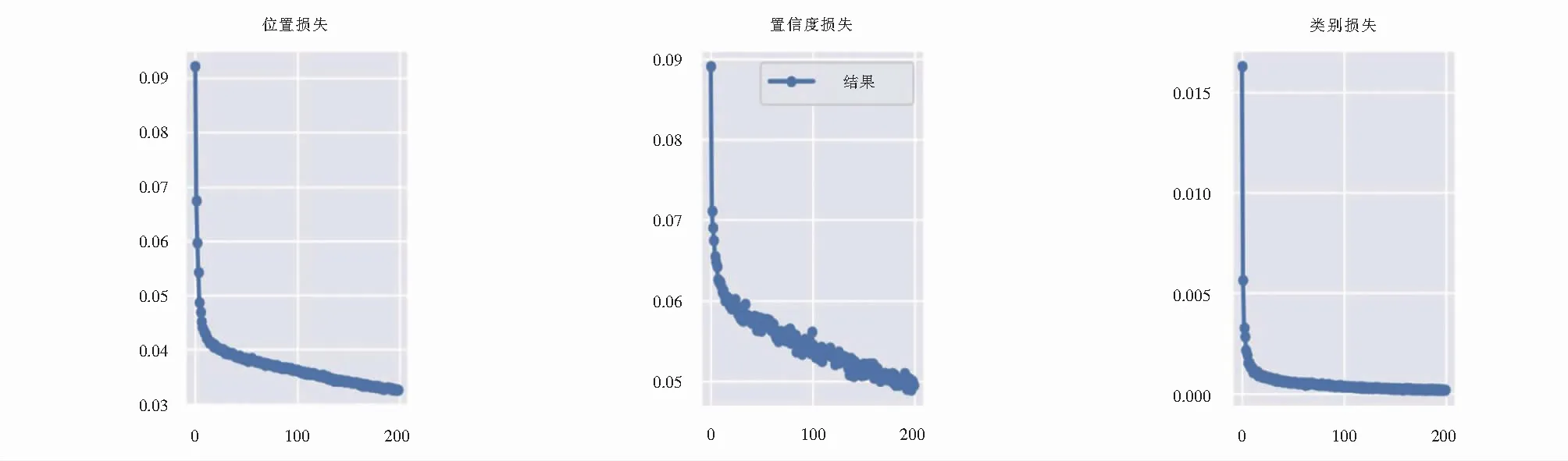
(a) (b) (c)
在目标检测中,均值平均精度(Mean average precision,MAP)是评估训练模型性能和可靠性的常用指标[8].本文将通过均值平均精度评价指标评估实验模型的性能,可得到两类结果图像,包括佩戴安全帽的施工人员和未佩戴安全帽的施工人员,如图4所示.

图4 实验模型结果Fig.4 Results of experimental model
正类正样本(True Positive,TP)、正类负样本(True Negative,TN) 、负类正样本(False Positive,FP)和负类负样本(False Negative,FN)是用来计算精度的关键.其中,hatTP是未佩戴安全帽的人,并且检测正确,hatTN,hatFP,hatFN以此类推.AP值表示评价精确度,其计算公式见式(2).Hat precision表示安全帽的精确度,其计算公式见式(3).hatrecall表示安全帽召回率,其计算公式见式(4).图5 Precision-recall蓝色曲线下方面积代表本次实验所有类别AP的值.
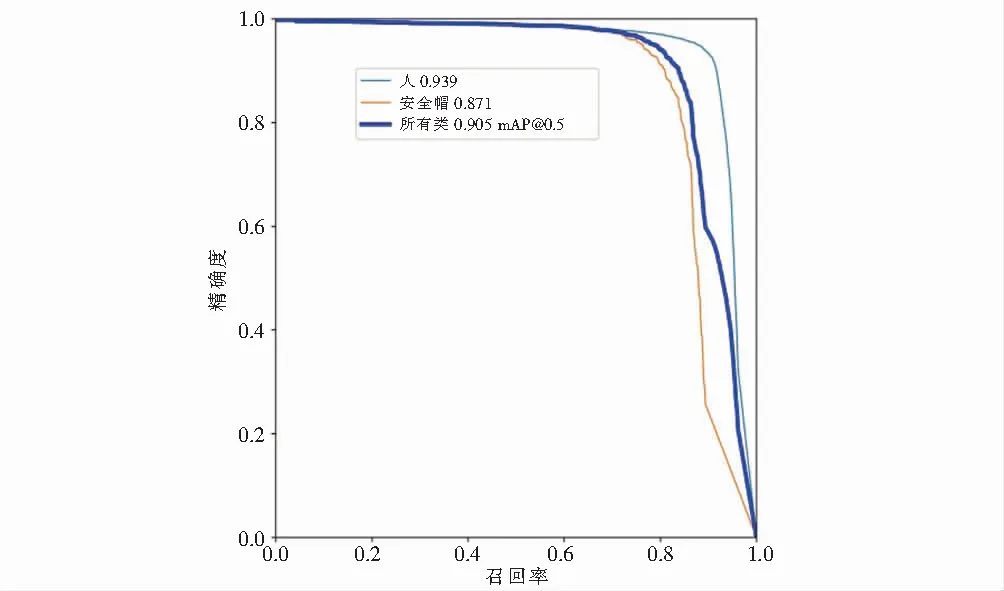
图5 Precision-recall曲线Fig.5 Precision-recall curve
APhat=TPhat+TNhatTPhat+TNhat+FPhat
(2)
Recallhat=TPhatTPhat+FNhat
(3)
Precisionhat=TPhatTPhat+FPhat
(4)
MAP=1Q∑q∈QAP(q)
(5)
其中,mAP@0.5代表IOU阈值取0.5时对应的mAP值.均值平均精度(mAP)为AP值在所有类别下取平均,计算公式见式(5).其中,Q为总类别数量.本次实验person类别mAP值可达93.9 %,hat类别可达87.1 %,所有类别mAP可达90.5 %.
5 结论
本文对使用YOLOv5网络解决安全帽佩戴检测的方法进行了研究,通过最终的实验数据表明,本文算法中工人头部检测的均值平均精度达到了93.9 %,工人佩戴安全帽的均值平均精度达到了87.1 %.该算法在复杂环境下准确率、检测速率仍具有良好的表现,因此YOLOv5算法可以适用于实际施工场地中.
