Knox特征优化在网格化犯罪时空预测中的应用
2022-11-18张天祎
魏 东,张天祎
(北京建筑大学 电气与信息工程学院,北京100044)(北京市科学技术委员会 建筑大数据智能处理方法研究北京市重点实验室,北京100044)
1 引 言
犯罪严重威胁着人们的人身安全和财产安全,是影响社会安全与发展的心腹之患,及时有效地预测犯罪可以为公安部门提前防控及警力资源部署等工作提供科学可靠的依据.而犯罪本身作为一种普遍的社会现象,在其发展过程中表现出历史规律性,如“日常活动理论”指出,犯罪活动总是与周围物理环境紧密联系在一起.且随着经济改革的日趋深入,公安部门累积了大量犯罪案件数据,为犯罪预测研究提供了充足的数据基础.因此,针对频发案件的犯罪预测研究具有可行性,且具有重要意义.
迄今为止,国内外研究学者已从多方面提出多种不同类型的犯罪预测方法[1].Youngmi Lee等[2]考虑了犯罪整数值时间序列的因果检验方法,结合Poisson INGARCH模型的均值方程,构造了一种包含外生变量的犯罪回归分析算法,并利用最小二乘估计法检验最佳函数;Stevens Heather R等[3]考虑了新南威尔士地区全年气温变化对犯罪率的影响,分别对攻击案、盗窃案和欺诈案件案日、月和季度汇总,并通过时间序列分解图可视化,以确定夏季和冬季的案件数量差异;Caetano R等[4]构建了贝叶斯时空回归模型,实现了对不同季节特征下犯罪结果的预测.该文献在分析了小区域范围内的财产犯罪后,利用时变回归(Time-varying Regression)区分了时间常数和季节特性对犯罪的影响;Liu Ling等[5]对犯罪数据进行深度自编码表征,将无标签数据按概率形式标签化,以此为特征结合K-means算法进行聚类分析.
上述研究成果较好地解决了传统人工犯罪分析预测方法难以系统地分析实时数据的不足.然而上述成果仅通过在不同维度上计算离散案件点的间隔长度来进行统计分析,一定程度上忽略了犯罪特有的近重复属性[6].犯罪近重复性表示,过去犯罪率高的地区在一点时间内仍将如此.环境犯罪学家把犯罪聚集的原因归结为有动机的罪犯的存在、可能的目标的存在以及在这些地区缺乏足够的监护或威慑,这些因素在一段时间内基本保持稳定,时空格局持续存在[7].在重复受害中,最近的犯罪中受害的目标更有可能在不久的将来成为新的犯罪的目标;而在近重复的情况下,靠近最近犯罪地点或事件的合适目标将在不久的将来经历更高的受害风险.另一方面,研究学者们通常忽视犯罪数据在全局地理区域内的高度不均匀分布特性,导致输入特征中“零犯罪”的占比极大,使模型预测结果稀疏表现严重.
为解决上述问题,本文借鉴传染病研究中的时空聚集度计算方式,针对犯罪预测研究,提出了一种基于平均最邻近距离(Mean Nearest Distance)的改进Knox算法(本文将其命名为Mnd-Knox算法)的犯罪预测方法,明确犯罪案件自相关性的时空分布尺度,避免了传统犯罪研究对案件间自相关性分析不足的问题;通过网格化地理信息管理方法,构建权重矩阵,跨时空域的分析了案件间的依赖关系,缓解了现存犯罪数据分布不均衡问题;最后在模型输入中附加地理特征,集成犯罪发生时间地点和案发相关的地理环境,完善了模型对犯罪相关数据集的利用率,实现了对犯罪环境的模拟,以及识别案件时空分布格局的目的.此外,本文在数据挖掘部分,采用基于Adam改进的深度神经网络(Deep Neural Networks,DNN)模型,有效地捕捉和学习犯罪在微观尺度下时空分布特征的疏密度,借助Mnd-Knox算法选择合适的微观时空尺度,对具体实验区域的时空分布特征和犯罪近重复性进行分析.在上述方法研究基础上,本文将预测所得结果进行可视化展示,以利用犯罪热点信息地图对警务工作加以指导,更好地预防频发型犯罪案件的发生和提高治安防控管理水平.
2 犯罪预测框架结构
时空数据挖掘的关键在于抓取时空数据点间冗杂的自相关性.由于时空数据具有复杂的依赖关系,而传统的数据挖掘技术均采用统计方法,并假设数据点是独立的,因此将其应用于时空数据时,效果欠佳.本文将从以下3个步骤进行研究,捕捉时空数据点间的复杂自相关性:
1)通过采用Mnd-Knox算法分析不同类型犯罪案件间,自相关性表现显著的阈值,确定适用于分析时空分布特征和犯罪近重复性的时空预测尺度,处理得到频发型犯罪案件的时空影响因子,为建立犯罪案件时空分布预测模型,提供可用于研究犯罪近重复性的数据基础;
2)顾及频发型犯罪案件时空域中分布特征的稀疏性对犯罪预测模型训练学习过程的影响,通过网格化地理信息管理方法,构建时空网格交互结构,以网格为单位计算各类案件自相关性的影响权重,构建案件间的自相关性影响权重矩阵,研究跨时空域的离散案件间的时空依赖关系,探讨案件聚集性分布显著和分布稀疏性较高的区域位置,同时利用移除空网格方法优化犯罪数据,达到平衡样本比例的目的,避免了犯罪预测类别失衡的问题;
3)在第2)步所得数据的基础上,附加相关地理特征数据,深入探究犯罪周围地理环境对案件发生的影响.最后,将所得实验数据代入DNN模型中,以得到最终预测结果.
本文所提出的犯罪时空数据挖掘框架如图1所示,由确定时空阈值、建立时空网格框架、扩充数据集、数据挖掘4部分组成.

图1 犯罪预测框架图
在确定时空阈值部分,本文提出了Mnd-Knox算法,并将其与卡方检验相结合,来识别犯罪数据中给定时间段内共同出现在相同或邻近区域块的案件簇,以最早发生的案件点为首,确定犯罪链.假定犯罪数据集S={x1,x2,…,xn}含n条犯罪记录,每条记录可表示为:
xi={qi,pi,ti}
(1)
其中xi表示出现在时间ti地点pi的案件qi,则Mnd-Knox算法将S划分为m条相交且不相同的犯罪近重复链{Qi|j=1,2,…,m},每条犯罪链可表示为:
Qj={x1,x2,...,xnj}
(2)
式中nj表示时间阈值Nt内Qj的记录数.
在建立时空网格部分,本文基于网格化地理信息管理方法建立了犯罪空间影响权重矩阵,将将Mnd-Knox算法处理所得数据和空间影响权重因子均投放到h等分的时空交互网格结构中,所得到的网格化数据集D={D1,D2,…,Dk}包含k个网格,每个网格可表示为:
(3)
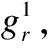
在扩充数据集部分,本文依据犯罪学环境理论,将天气数据集W={w1,w2,…,w366}缩放到单位范数,此时每条记录可表示为:
wi={tr,pi,ui}
(4)
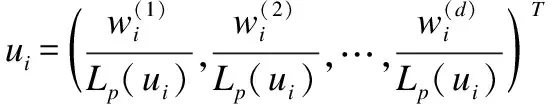
式中,ui表示在地点pi时间ti时的天气因子,然后再将其与其他犯罪相关位置数据投放在网格中,得到最终网格化数据集D′,此时每个网格可表示为:
(5)
式中,or表示在编号Gr网格中的警察局位置,er表示网络热点(即网络平台上评论数据量大、热门度高的地点)统计量.
在数据挖掘部分,本文基于Adam优化的DNN算法从数据集D′中挖掘犯罪发展规律,在兼顾犯罪近重复性的时间与空间特征的同时,捕捉时空自相关性尺度下的案件分布异常特征.
图1中3个数据特征优化处理模块分别对应后文中第4节3个小节的内容,该框架既满足宏观分析离散案件点的间隔长度,又可以微观剖析参数间的自相关性.
3 数据集
本文采用美国芝加哥地区的犯罪信息作为研究数据集.芝加哥地处北美大陆中心地带,是国际金融中心之一,也是美国第三大城市和美国最大的制造业中心.容纳270万人口的芝加哥市案件量远高于其他城市,故被冠以“犯罪之城”的称号.当地警察局数据统计结果表示,仅2016年一年各类犯罪案件高达25万余起.本文采用芝加哥地区2016年1月1日至2016年12月31日的犯罪数据用于犯罪预测实验研究.
本文首先对犯罪数据集进行初步预处理,如利用dropna()和fillna()函数删除并填充缺失数据和遗存数据、groupby()聚合分类等,最终获得251044条有效数据,部分数据见表1.其中盗窃犯罪占69243起,殴打犯罪占48667起,刑

表1 芝加哥地区部分犯罪数据信息
事损害犯罪占30185起,袭击犯罪占19333起,这4类犯罪案发次数远超其他类型案件,属于频发犯罪类型,故本文将以上4类犯罪作为研究重点进行预测分析.
4 数据预处理
4.1 Mnd-Knox时空分布特征检验模型
频发型犯罪的发展规律通常被视为连续变量在时间轴上的横移运动,与传染病的流行态势极为相似[8].而Knox算法作为一种经典的传染病聚集性检验方法,将其理论应用于对犯罪数据预处理过程进行优化,能够实现案件间自相关性分析,从而得到犯罪近重复性信息.然而,传统的Knox检验方法需要人工确定阈值,在缺乏相关先验知识的情况下,主观人为确定的阈值会存在一定的随意性.如,She Bing等[9]在研究神宗和征出血热疾病时,人为指定空间阈值为500km和800km;Mja B等[10]将Knox算法应用于垃圾处理及占道经营事件研究,人为选取空间阈值为500m,时间阈值为3h;Yue Han等[11]逐一选取900km、1000km…2000km作为空间阈值,构建了12组权重矩阵,实验表明在不同阈值下事件呈现出的时空交互性差异较大,不能精准反映出事件真实的自相关性.
本文对传统Knox算法进行了改进,以案件对平均最邻近距离作为Knox检验阈值,Mnd-Knox算法能够体现出邻近案件点比疏远案件点存在更为紧密的关系,解决了传统Knox算法人工确定阈值的随意性问题.因此,本文在犯罪时空特征优化提取过程中,利用Mnd-Knox模块对犯罪近重复性的微观尺度进行分析.
Mnd-Knox算法具体流程如下:
本文首先利用如下公式计算案件对间的MND:
(6)
式中,n为案件点总数;min(dij)表示案件点i与其最邻近点j的距离.本文基于公式(1)将n个案件点两两配对得到n(n-1)/2组时空案件对,并计算每对案件间的实际空间距离sij和实际时间距离tij.当实际空间距离sij不大于空间阈值S时,认为案件对空间邻近;当实际时间距离tij不大于时间阈值t时,认为案件对空间邻近.4类临近关系的案件对数值见表2.

表2 Mnd-Knox指数逻辑结构表
表2中,D1为案件时空邻近对数,D2表示空间邻近对数,D3为时间邻近对数,D4为时空非邻近对数.时间邻近且空间邻近的案件对可被视为时空邻近案件.在得到所有案件时空邻近结构后,利用卡方检验方法对犯罪时空交互统计的显著性进行检验.卡方检验假设犯罪是否时间临近和是否空间邻近是独立无关的.
本文随机抽取一对案件,并计算空间邻近的概率:
(7)
式中,N表示案件总对数.
假设案件不存在时空交互性,本文通过比较理论值E(Di)和实际值Di的误差大小,计算卡方值χ2,并根据计算结果判断时空聚集程度的显著性.计算方法如下:
(8)
(9)
(10)
(11)
(12)
在拟合优度检验中,自由度v由矩阵的行数n和列数m计算可得:
v=(n-1)(m-1)
(13)
基于Python编程语言实现的Mnd-Knox算法优化流程如下:
算法1.Mnd-Knox算法的部分流程
输入:犯罪数据集S
输出:时间阈值Nt
1.def time_long(time1,time2,type=″day″)://时间差函数
2.day1=time.strptime(str(time1.strftime(″%Y-%m-%d″))
3.day2=time.strptime(str(time2.strftime(″%Y-%m-%d″))
4.iftype==′day′://时间转换
5.Nt=np.mean(b)
6.num=int(time.mktime(day1)))/(24*60*60)
7.returnabs(int(num))
8.endif
9.for i in range(len(S.timestamp)):
10. list_a=[]
11. for j in rang(i+1,len(S.timestamp)):
12.time_list=time_long(S.timestamp[i],
13.S.timestamp[j])//ti时刻与其他时刻的时间差列表
14.min_list.append(min(time_list))最邻近距离
15. endfor;
16.Nt=np.mean(b)//平均最邻近距离
17.endfor
18.returnNt
算法1中,time1和time2为任意两个案件点的时刻.
本文通过上述研究成果,分别计算得出芝加哥2016年4类案件的平均最邻近距离:1)盗窃案56m;2)殴打案145m;3)刑事损害案233m;4)袭击案64m.4类案件的时空检验结果如图2所示.横坐标上的时间不是一个时刻,而是代表一个累积量,也代表了犯罪案件发生的前后依赖关系.显然在宏观时间趋势下,犯罪时间域的分布离散程度越来越高,近重复程度逐渐减弱.

图2 时空检验图
本文选取95%置信度(即p<0.05)作为显著性判断标准,得到4类案件的时间阈值见表3.

表3 芝加哥2016年4类主要案件调查结果
本文所提出的Mnd-Knox算法能够在时空域中捕捉离散点间之间的依赖关系,从而可以识别出犯罪近重复性在时间和空间上的邻近性.本文根据所计算得出的4类案件近重复性时空分布阈值,确定适用于分析时空分布特征和犯罪近重复性的时空预测尺度.在构建犯罪预测模型时,本文选取其前一天及其前Nt天的犯罪频次作为模型的输入特征,以便为犯罪预测模型提供可用于分析离散案件点间依赖关系的犯罪近重复性因子,在加入该因子后模型输入层含有犯罪时间近重复性信息,能够为犯罪时空预测模型的构建提供案件自相关性分析的数据基础.
4.2 网格化地理信息管理方法
4.2.1 建立案件间空间邻近性权重矩阵
犯罪行为人多数会选择在其熟悉的环境内发生犯罪,但是以往犯罪预测研究中通常着重分析时间、空间和犯罪类型[12]等因素,未考虑网格的地理特征,使得模型无法预测空间维度上犯罪的位移.为此,本文在时空数据处理过程中添加网格化处理模块,并在该模块中采用网格化犯罪特征优化方法,通过空间邻近性构建空间权重矩阵,将多区域之间的关联性进行量化.
本文首先在地图上界定芝加哥市的边界,得到一个矩形的空间区域,然后在保证不破环犯罪链的前提下,将该区域划分为200*200的网格,并对网格进行编码后利用核密度估计法(Kernel Density Estimation,KDE)计算相邻网格的时间因素在不同网格距离下的影响权重,选择径向基函数作为核函数.径向基函数的取值仅依赖于到原点距离的实值,同时可控制函数的径向作用范围(即犯罪近重复范围),便于将有限维数据映射到高维空间,其形式定义为:
(14)
式中,σ为核密度函数的带宽,Δt表示时间段中任意时刻到某个犯罪中心点的时间长度,该中心的犯罪自相关性影响是局部的,所生成的平滑估计面可以展示时间区域内的犯罪聚集情况,对于某段时间内犯罪事件中的任意一点x,设xi(i=1,2,…,n)是该时间段内同类型犯罪的其他点,其中n为样本数量,xi到x的距离决定了该时间段内其他点对点x的权重.则点x处的犯罪概率密度为:
(15)
在上述研究基础上,本文构建了案件空间权重矩阵,其中网格编码为1-6的网格权重矩阵见表4,其中犯罪空间权重矩阵的行信息代表在一段时间内某犯罪区域对其他各区域的影响因子.

表4 网格编码前6的空间权重矩阵
基于Python编程语言实现的时空交互网格结构构建部分函数如下:
算法2.构建网格交互结构流程中部分函数
输入:数据集D,网格划分疏密度h
算法参数:芝加哥市区域边界经纬度City(x1,y1,x2,y2)分别为纬度(最南)、经度(最西)、纬度(最北)、经度(最东)
输出:网格化数据集D′
1.def get_diagonals(self)://定位子网格函数
2.map=self.get_map_coordinates()//获取网格边界
3.diagonals=[]
4.foriinrang(0,h*h-h-1):
5.if(i!=0andi%n==0):
6. continue
7. endif
8. diagonals.append((map[i],map[i+n+1]))
9. endfor
10.return diagonals
11.def get_map_coordinates(h)://获取区域边界函数
12. asserth>1//报错函数
13. epsilon=1e-6//取数据集中最大最小经纬度作为芝加哥的最大最小经纬度,并外扩epsilon
14. lat_start=D.lat.min()-epsilon
15. lat_end=D.lat.max()+epsilon
16. long_start=D.long.min()-epsilon
17. long_end=D.lat.min()+epsilon
18. delta_lat=abs(lat_end-lat_start)/h
19. delta_long=abs(long_end-long_start)/h//距离取绝对值
20. Chicago=City(lat_start,long_start,lat_end,long_end)
21. cells=Chicago.get_diagonals()//子网格划分
22. ……
4.2.2 时空网格交互结构建立以及数据不平衡性处理
随着时间的推移,犯罪空间影响权重是动态变化的,每一时段的犯罪空间影响权重因子都不相同.因此,本文构建时空网格交互结构将时间和空间因子顺序排列于网格中,来完成跨时空域的案件自相关性分析.本文在二维空间网格平面上,垂直于平面方向延伸出时间轴,得到三维立体网格结构,并以天为单位进行统计,得到一个200*200*366(其中2016年全年共366天)的时空网格交互结构.时空交互网格结构同时考虑时间和空间因素,将Mnd-Knox算法处理所得数据和空间影响权重因子同时映射到对应网格中,统计一定时间段内(即各类案件对应的近重复性阈值Nt)单位网格内的累积犯罪数据来分析犯罪在跨时空域上的分布特征.
在此基础上,针对犯罪数据不平衡问题,利用filter()和list.remove()函数筛选出“零案件”网格并将其移除,以平衡样本比例,避免了犯罪预测模型在学习训练过程中,出现预测结果倾斜的问题.不平衡性犯罪数据处理流程,如图3所示.

图3 数据不平衡性数据处理流程图
4.3 相关地理环境特征的选择
传统的犯罪预测方法通常仅单独考虑时间或空间因素[13],导致模型对时间和空间的选择敏感性较高.有研究注意到不同区域的犯罪均受地理环境特征影响,如气候变量[14,15]、失业率[16]、Twitter评论[17,18]等.因此,本文在犯罪时间、地点数据集的基础上扩充相关环境因子数据集,从kaggle公开数据集中选取气候特征、警察局位置及网络数据作为附加地理特征,见表5.

表5 附加地理特征数据集
其中气候特征,尤其是温度特征是导致罪犯产生犯罪行为的重要因素之一[19].本文将气候特征细分为降雪量、降水量、平均温度、最高温度和最低温度;警察局数据统计了芝加哥地区所有网络上公开的警察局位置经纬度;网络数据选择的是芝加哥地区yelp平台的公开数据集.yelp作为美国最大的点评网站,相关数据囊括芝加哥地区的网红餐馆、大型购物中心、高客满率酒店、热门旅游景点等热点位置.本文将网络数据中yelp热点位置与犯罪案件点位置进行对比,结果如图4所示,可以看出二者聚集性表现相似度极高.yelp可以反映出不同位置繁华程度、交通拥堵情况及人流量等特点,这些因素均可直接影响犯罪发生的可能性,故可以作为预测模型的附加地理特征.

图4 数据聚集性分析
5 神经网络训练算法及参数
5.1 神经网络训练算法
以往研究中,研究人员提出了多种基于数据驱动的建模方法,如DBSCAN[20]、多层感知机[21]、随机森林[22]、模糊BP神经网络[23]、模糊VIKOR算法[24]、卷积神经网络[25]等.在这些建模方法中,DNN相比于其他方法,在非线性系统建模方面优势明显[26].考虑到随着时间推移,不同网格内的犯罪案件的发生数量存在波动性(即时空犯罪影响因子的局部变异),本文采用基于Adam优化的DNN算法[27]捕捉犯罪时空序列中的异质性特征,高效拟合犯罪时空序列中的特征分布并进行犯罪预测.
5.2 模型参数

由于芝加哥数据集规模较小,为了防止过拟合,本文选用隐含层为3层的DNN网络结构.增加每层神经元的数量能在一定程度上提高模型的预测性能,但也同时提升了学习参数的复杂度,易造成过拟合,因此,本文将各层神经元数量设定为{5,10,20,50,100,150},并采用k-fold交叉验证[28]的方法确定隐层神经元数量,模型结构如图5所示.
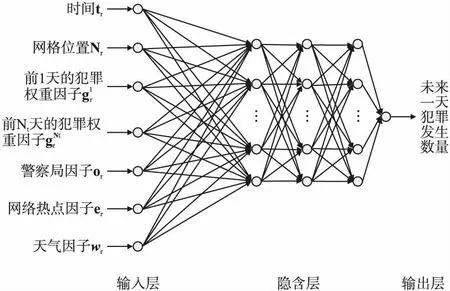
图5 犯罪预测DNN模型结构
6 实验结果与分析
6.1 模型评价指标
本文针对芝加哥犯罪数据采用上述方法进行实验研究,在训练预测模型时,均采用7:3的比例随机划分数据集,取70%的数据作为训练集,30%的数据作为测试集,并选择MAE值作为评价指标进行分析,以验证模型的有效性.具体计算公式如下:
(16)

6.2 模型有效性验证
6.2.1 实验结果对比
本节首先将经过简单处理(见第3节)后的数据作为基础模型的输入,并将基础模型预测性能与经过上文所述方法优化后的模型性能进行对比,见表6.

表6 各类案件模型性能评估MAE值
表6中的模型3结合了3种输入数据优化方法,包括:1)通过Mnd-Knox算法确定时空阈值;2)结合网格化地理信息管理方法对附加地理特征及基础犯罪特征在时空域中的自相关性进行提取后.由表6易知,模型3对于4类案件的预测均取得了较为理想的结果;对于犯罪近重复性表现较为突出的盗窃案而言,利用3种特征优化方法共同优化后的模型(即模型3)误差显著降低,预测性能有明显提升;而对于犯罪近重复性相对较弱的袭击案、刑事损害案和殴打案来说,模型3性能提升幅度相对较小,但仍具有很好的预测能力.这说明将本文所提出的3种优化方法综合运用于犯罪预测研究,能够深入分析犯罪案件间的自相关性,且有一定的积极作用.
本文进一步整合了不同类型案件数据下,3种优化方法的作用效果,如图6所示,其中纵坐标表示各方法的优化效果占总优化效果的比例.
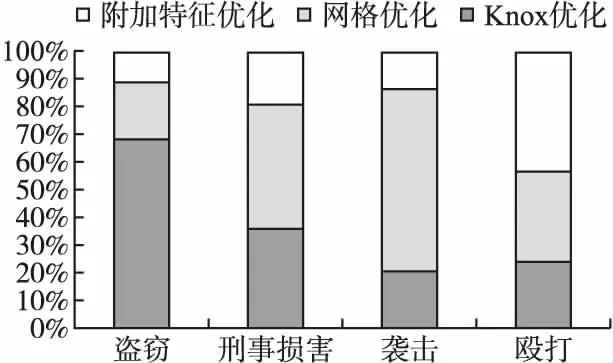
图6 3种优化方法效果对比图
由图6可知,对于全年案发数量最高的盗窃案而言,犯罪行为人实施犯罪前通常会掌握人们行为规律、窥测作案地点周围环境,然后选择作案目标、时机、逃跑路线等,且盗窃行为常带有习惯性,直接导致盗窃案件具有极高的近重复性,因此经过Mnd-Knox优化后,预测效果提升最为明显.而袭击案经过Mnd-Knox算法优化后的效果未达到最优,但经过网格化处理后的优化效果最佳,这与该类案件社会破坏力及影响规模极强的特性有关.同时袭击行为人需要进行充分准备、严密策划、严谨组织,但袭击目标较为特定,因此袭击案仍具有发生二次重复犯罪的可能性,但影响相对较小.另外,袭击组织形式呈网格化,在相应的网格结构中,没有明显的权利中心,只有大量不同的节点,每个节点均可为其他节点提供帮助与支持,所以对袭击案预测模型进行网格化城市管理优化效果显著.其次对于殴打案和刑事损害案而言,两者均表现出一定的近重复性,因此Mnd-Knox优化效果较好.在殴打案预测模型输入中附加地理特征后,优化效果较为良好,这说明这类案件受周围客观事物的影响较大,当某地区缺乏有效监管且具备有利的作案环境时,会导致该类案件频发.
6.2.2 与其他犯罪预测算法性能对比
对比研究中,本文选取目前最新的犯罪预测模型与本文提出的基于Mnd-Knox算法和时空交互网格结构改进的犯罪预测模型(即模型3)进行比较分析,见表7.对比模型的平均绝对误差数据由文献[29]提供,包含对盗窃、抢劫和抢夺案3类数据集的预测结果,该结果数据取值均保留到小数点后两位,本文采用MAE的平均值对比相应模型预测性能.

表7 评估模型性能的MAE值对比
对比各类模型MAE的平均值易知,模型3对不同类型案件的数据集进行预测,其预测性能表现最佳,均能稳定在较低的平均绝对误差水平上.而岭回归模型虽能在一定程度上拟合模型,但对于非线性的犯罪数据而言,容易出现回归结果失真的情况;弹性网络模型对重要特征的选择较为敏感,该模型适用于特征变量高度相关的情况,而犯罪数据常表现为离散的案件点,且案件间的自相关性从宏观数据间隔上难以被判别;K最近邻模型的回归前提是需要找到一个案件点的k个最近邻案件点,其中k值需要凭借先验知识确定,而导致实验结果的不稳定性,同时,犯罪近重复性的强弱是随案发地点、时间、周围环境、案件类型等因素动态变化,因此,在K最近邻模型中选择固定的k值不利于犯罪近重复性的分析.
6.2.3 4类案件的优化效果
图7和图8给出了4类案件模型预测效果图,在同一坐标尺度下,可更加直观地比较经过特征优化后的预测模型3与基础模型的预测效果.
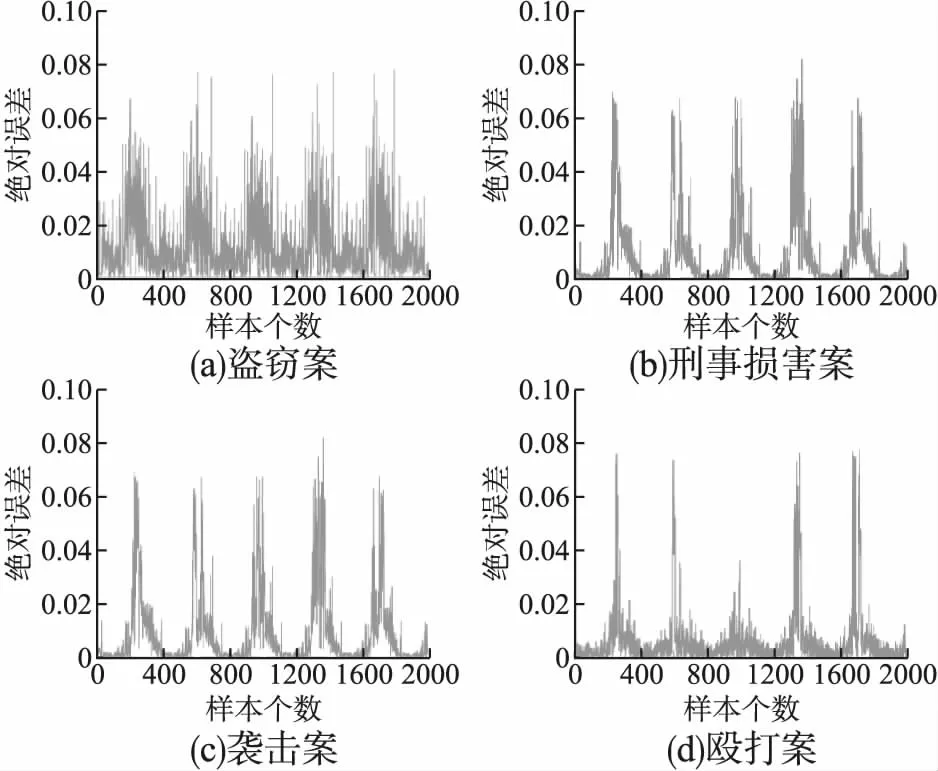
图7 基础模型预测误差
6.3 预测结果可视化
由图7和图8可以看出,除盗窃案以外的3类案件进行特征优化后的预测结果均出现多个误差峰值,这是由于案件发生时的特殊社会形势或犯罪行为人的反常表现所导致的.犯罪的发生受诸多因素共同作用,因此这些峰值的产生原因较为复杂,很难精准预测其规律性.但是,很显然进行特征优化后的模型整体性能得到了较大程度的提升,表明该模型能够较好地反映芝加哥市犯罪在时间和空间上的发生趋势.
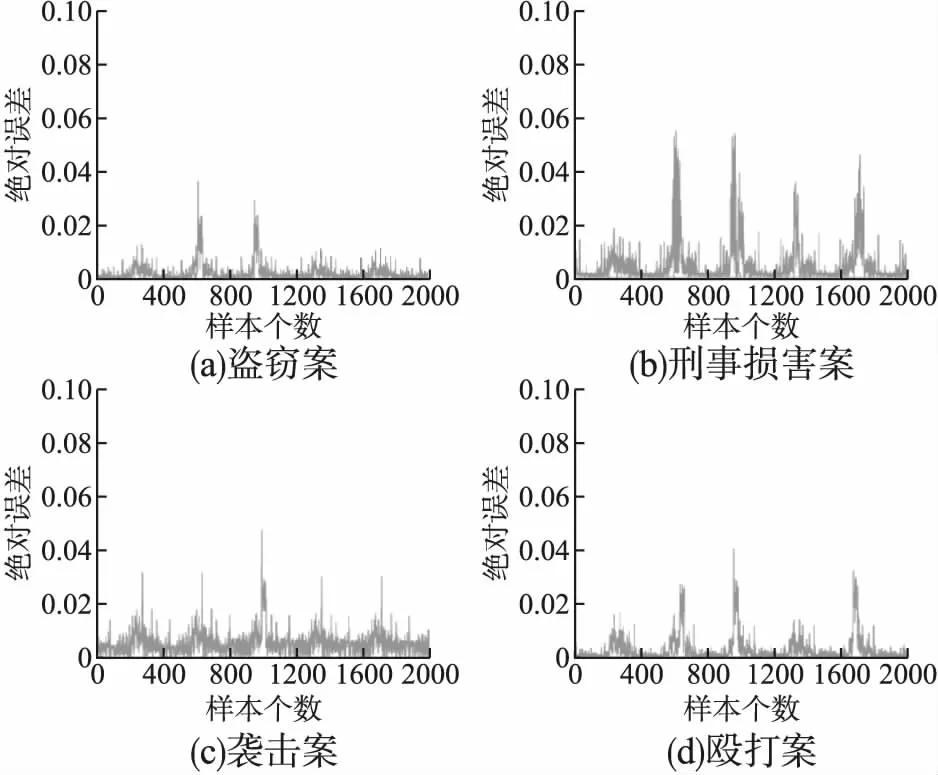
图8 模型3预测误差
由上述分析可知,基于Mnd-Knox及网格化地理信息管理方法进行特征优化的犯罪时空预测模型,能够较为充分地挖掘犯罪在时间及空间上的复杂内在规律,并预测未来一段时间内某地发生某类案件的概率.将犯罪预测结果投放在网格中进行可视化展示,可以直观地对决策人员加以指导.本文整合了4类案件预测结果,将犯罪率前50的网格作为犯罪热点,并利用Python中的Plotly Express进行可视化展示,如图9所示.
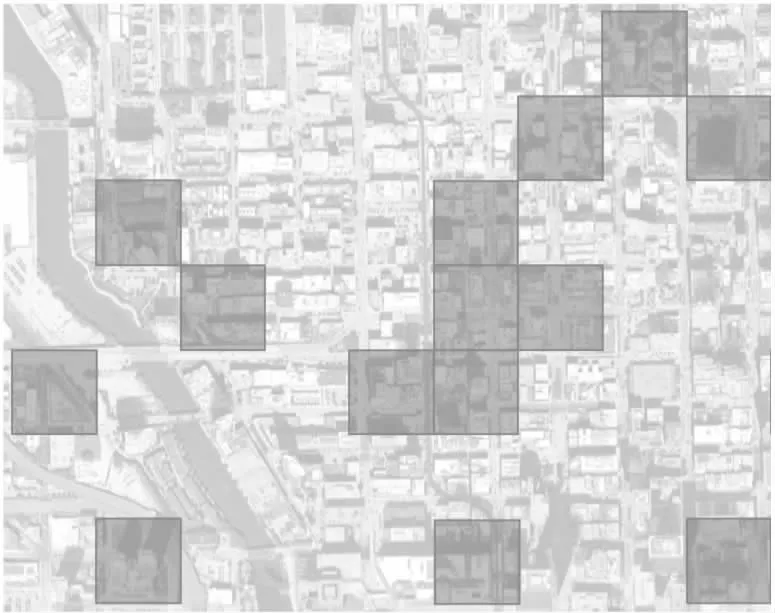
图9 犯罪热点图
图9中选取预测模型输出值较高的网格作为犯罪热点,方便相关人员采取及时有效的应对措施,并重点在犯罪热点地区进行警力和资源部署,同时可以根据预测结果制定短期及长期工作计划,以优化警力资源利用.
7 总 结
犯罪数据集的特征提取及预处理是犯罪预测研究中的关键一环.本文提出了一种基于Mnd-Knox及网格化管理的犯罪时空预测方法,针对以往研究中缺乏分析犯罪案件间时空自相关性的问题,借助Mnd-Knox算法确定时间和空间维度上近重复性的阈值,并利用该值提取与被预测点存在自相关性的时空特征,同时构建时空交互网格结构去除不均衡的犯罪数据,对时空分布特征提取进行了优化,最后融合附加地理特征,解决了现存数据利用不充分、犯罪特性考虑不周全等问题,从而提高了犯罪时空预测模型的性能.
本文主要贡献如下:
1)创新性地将传染病研究时空聚集度技术应用于犯罪领域,研究犯罪时空近重复性尺度,一方面创新性地采用有别于直接利用原始犯罪数据集进行预测的方法,克服了简单宏观预测导致数据利用不充分的问题;另一方面能够较好的拟合频发犯罪类型案件发展规律,考虑到邻近案件点比疏远案件点存在更为紧密的关系,使其在预测频发案件时具有更好的效果.
2)引入城市网格化管理思路,在犯罪点间的内部联系保留更完整的前提下,将预处理后的犯罪数据点投放到三维时空交互网格结构中,结合核密度估计法统计单位网格中的数据信息,再提供欠采样方法,解决了数据倾斜问题.
3)在分析犯罪时间地点数据的基础上,融合周围物理环境因素,如天气情况、警察局及热点地区位置信息共同作为模型输入,全面模拟犯罪环境,同时提高犯罪相关数据利用率及模型预测准确率.
4)结合常用误差度量标准对不同疏密程度的网格化预测模型进行评估,并利用犯罪热点地图可视化技术展示预测结果.
通过实验结果比较表明,本文所提出的优化模型用于预测4类案件后,模型性能表现良好,能够达到预期目标,特别是用于分析自相关性显著的案件类型时,效果最佳.下一步本文计划针对未来一周和未来半个月的犯罪数量进行预测,此时需要根据案件点距离的核密度变化调整预测模型的输入参数,从而能够为公安部门制定长期工作计划提供辅助作用.公安部门可借鉴本文预测结果,从长期及短期犯罪发生规律入手布置犯罪防控工作.
