一种面向持久化内存的热点变量快速写入算法
2022-11-18燕保跃
燕保跃,姜 博
(北京航空航天大学 计算机学院 软件开发环境国家重点实验室,北京 100191)
1 引 言
近年来出现的新型非易失性内存(No-Volatile Memory,简称NVM)[1,2],具有掉电非易失、低功耗、低延迟、大容量、可字节寻址等诸多优良特性,取得了工业界和学术界的广泛关注[3-6].NVM旨在大幅度提升设备内存容量以及降低设备静态功耗的同时,提供可持久化字节寻址等特性以简化系统的设计.然而,新介质与传统的DRAM在读写性能、I/O访问特性等存在较大不同,从而对应用的设计带来较大挑战.尤其在保证数据持久化方面,虽然CPU可以直接通过load/store指令访问NVM[7,8],但从CPU寄存器到NVM控制器之间的大部分数据传输路径均掉电易失.用户需要显式使用昂贵的刷缓存指令(flush)以确保数据完整的从CPU缓存写入到NVM设备中.另外,现代CPU架构中通常采用乱序执行等技术加速指令流执行.为确保数据按照正确顺序被持久化,用户需要显式使用内存屏障指令(fence)以消除指令乱序执行带来的数据持久化不一致.
在降低持久化开销方面,现有工作主要从批量刷新、延迟刷新等入手以减少持久化操作的次数,或者从应用角度尝试减少上层逻辑中需要持久化的部分.然而这些方案难以应用到热点变量(dancing variable)的写入优化中.热点变量的更新涉及到频繁刷新同一个CPU缓存行.实验发现,现有NVM硬件体系结构下,频繁刷新同一个缓存行要比不同缓存行的开销大2倍.热点变量在实际的应用中普遍存在,如计数器、状态机等.因此针对热点变量的快速写入优化存在较大意义.
本文针对以上问题,提出了一种快速热点变量写入算法PDV(Persistent Dancing Variable),其核心思想为通过对热点变量设置多个位于不同缓存行的影子变量,在每次更新时采用轮询策略依次选择不同的影子变量进行更新,以确保每次更新刷新不同的缓存行.为了保证在系统恢复时能够解析出最新写入的影子变量,PDV对每个影子变量设置一个标签域(tag),在每次刷新影子变量同时根据当前状态设置对应标签域的值.本文证明,对于任意数量的影子变量,仅需2比特标签域即可保证PDV算法总能正确的恢复.在系统恢复时,PDV通过扫描热点变量所有影子变量的标签,从而计算出最近写入的影子变量.在Intel傲腾持久化内存平台的实验结果表明,PDV算法对于热点变量的写入性能提升高达1.9倍.
2 背景与动机
2.1 持久化内存
业界对于持久化内存的研究已经持续很多年,其最初被期望具备持久化与可字节寻址特性,用于解决DRAM的可扩展问题(scale).常见的持久化存储介质有相变存储器(PCM)[9-11]、忆阻器(Memristor)[12]、自旋扭矩磁阻存储区(STT-RAM)[13]以及可变电阻存储器(ReRAM)[14].这类存储器件提供与DRAM相同的字节寻址能力,但具备非易失性且相比DRAM具有更高的存储密度以及更低的静态功耗.2019年,Intel发布基于3DXPoint PCM存储介质的商用版持久化内存傲腾DCPMM,也是第一个在服务器领域大规模产业化的持久化内存设备.其单根PM内存条可提供512GB的容量,而传统的DRAM受限于刷新率、功耗等限制当前最大仅能提供64GB的单根容量.后文提及NVM也特指傲腾DCPMM.
当前,NVM在性能表现上慢于DRAM,但普遍快于传统的固态盘(SSD),因此曾被期望作为DRAM与SSD之间的持久化缓存层.大量已有文献对于NVM的读写特性已有较为充分的调研[8,15-22],本文不再详述.图1给出了当前NVM的主要硬件架构.和传统的DRAM类似,NVM通过iMC(integrated Memory Controller)控制器连接到CPU.iMC可以配置NVM工作在两种模式:内存模式(memory mode)和应用直连模式(app direct).在内存模式中,NVM仅作为更大容量的DRAM,且由iMC硬件自动接管DCPMM的使用.直连模式中,DRAM与NVM统一暴露给CPU接管,CPU可以直接通过load/store指令访问NVM.另外,NVM的存储介质与CPU基本的数据操作操作单位并不相同,DDR控制器以64字节(一个缓存行)为单位访问NVM内存模组,而NVM控制器以256字节为单位(XPLine)访问其持久化存储介质,因此产生一定的读写放大问题.虽然CPU以缓存行为单位刷新数据,但NVM硬件控制器当前仅能提供8字节的原子写入.由于本文重点关注NVM的持久化特性,因此配置其工作在应用直连模式.

图1 NVM主要硬件结构
2.2 数据持久化
虽然NVM可以提供字节寻址的可持久化存储,但在CPU的数据路径中,大多的路径依然是掉电易失的.如图1所示,写入路径中,CPU中的缓存(寄存器、多级缓存等)依然是掉电易失(注:Intel于2021年Q4发布第三代Xeon处理器,其将缓存纳入ADR域中,无需再显式使用缓存刷新指令[23]),仅当数据进入到iMC控制器后才能保证数据可以正确地写入并持久化到NVM中.Intel处理器平台定义了ADR(Asynchronous DRAM Refresh)域(domian)的概念,保证数据进入ADR域后可以由硬件保证掉电不易失.如图1右半部分所示,ADR域针对每一个DCPMM模组使用分别使用一个读等待队列(RPQ)以及写等待队列(WPQ),且在写入时以一定的时间间隔将WPQ中的数据刷入到控制器.
由于CPU的缓存是易失性的,因此用户需要显式使用刷缓存的指令以保证数据写回到NVM中[24,25].当前Intel提供clflush、clflushopt用于显式的淘汰某个缓存行并刷新到内存中,其中clflushopt可以针对不同的缓存行并行执行.其次,clwb指令用于刷新对应的缓存行到内存中而不淘汰对应行的数据.另外,Intel提供ntstore指令等一系列的指令用于绕过CPU缓存,而将数据直接写入到内存中,以旁路掉缓存的操作开销.然而由于现代X86处理器的乱序执行的高级特性,存储指令可能会被CPU重排用于提高内存访问吞吐量.乱序执行可能破坏数据存储的一致性,因此对于存储顺序有要求的场景需要显式通过内存屏障指令,如sfence等,强制存储操作按照指定的顺序进行.NVM写入性能受缓存行的数量影响较大,如图2(a)所示.其次频繁写入同一个缓存行的开销明显大于写入不同缓存航的开销,如图2(b)所示.其根本原因为写入不同的缓存行可以通过clflushopt并行,而单个缓存行只能串行进行.
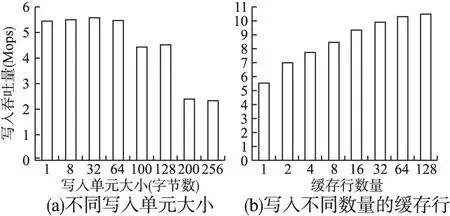
图2 NVM写入I/O特性
2.3 研究动机
热点变量在应用中普遍存在,但在传统的面向易失性DRAM的场景中,由于不需要保证持久化,因而不需要频繁的刷新该变量所在的缓存行.但在可持久化NVM应用场景中,热点变量的频繁更新需要频繁的调用刷新指令,因而难以避免频繁的刷新同一个缓存行.现代NVM硬件体系结构中,频繁刷新同一个缓存行的效率明显低于频繁刷新不同缓存行.一个直观的解决方案是针对热点变量设置多个位于不同缓存行的影子变量.每次更新时选择不同的影子变量.然而该种做法的一个较大的挑战是如何在系统恢复时确定最近更新的影子变量.本文提出PDV算法以解决以上问题.
3 模型概述
设置多个位于不同缓存行的影子变量(下文统一简称为影子)的方法存在两个难点.其一是每次如何选取不同的影子;其二是系统恢复时如何找到最近更新的影子.考虑图3所示的3个例子.例子(a)表示每次轮询选择下一个影子,但不记录任何额外的信息,该方式显然无法在恢复时确定最新的影子.例子(b)中,每次选择影子时均有持久化head指针记录所选影子的编号,但由于每次写入影子时均需要更新head指针,因此问题又被递归的引入.例子(c)中通过对每个影子添加一个标签,恢复时通过扫描标签信息计算出最近写入的影子,进而实现了每次均写入到不同的缓存行且又能够保证恢复时确定最近写入的影子.
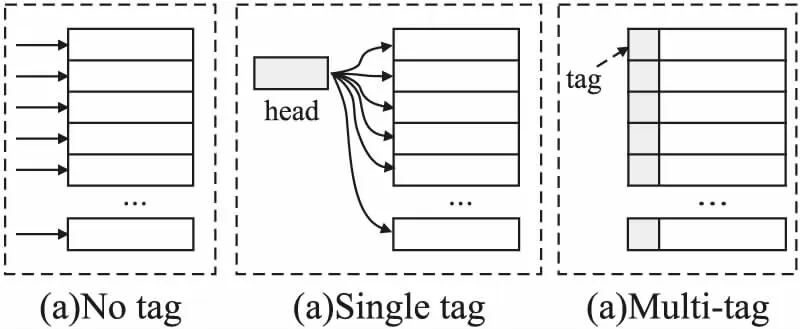
图3 访问不同影子变量的实例图

3.1 PDV模型
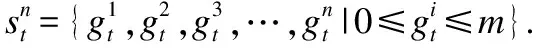
(1)
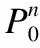
(2)

(3)

(4)
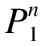
3.2 数据恢复
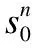






表1 快照集合判定的充分条件
证毕

证毕

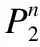
证毕
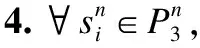
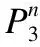
证毕
定理1.对于n个影子的热点变量,PDV算法总能够正确的恢复.
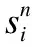
证毕
3.3 最小标签比特数
(5)
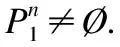
定理2.对于存在n≥2个影子的热点变量,PDV算法中每个标签所需的比特数与n无关,其恒为2比特.
证明:由上述分析可知,m≥2时,PDV总能正确恢复.因此每个影子标签最小所需的比特数为k=「log22+1⎤=2,且与n无关.
证毕
3.4 状态机设计
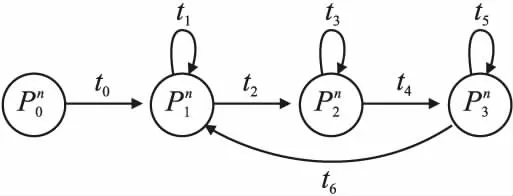
图4 PDV运行状态机

表2 PDV状态转移表
4 算法实现
算法1.PDV数据结构定义
1.Template
2.structPDV{
3.chari=-1; //轮询影子选择指示

5.chatc=0 //复用计数器
6. T*(*pdata)[N]=nulptr; //影子数组指针
/*操作接口*/
7. T getVal();
8.voidpersistVal();
9.voidrecoverFrom(T*(*p)[N]);
10. }//16 bytes in total
算法1给出了本文对于PDV的详细实现的细节.其中单个PDV实例运行时的内存开销为16字节(对齐后),其中包括8字节的影子变量所在NVM中的数组指针(第6行).运行时,i用于指示当前选择的影子,s表明当前的状态.由于推动PDV状态机的4个计数器同一时刻仅有一个计数器发挥作用,因此在实现中可以设置一个复用计数器c为状态计数器(第5行).PDV当前仅支持不大于8字节的基本类型,如char,short,int以及long类型.主要有两个原因.1)当前NVM硬件仅能确保不大于8字节的原子写入,因此更大的数据类型存在部分写问题(torn write);2)热点变量,如计数器等,大多以基本类型为主.所有影子的最高两位比特用于存储标签值,即c的最大值为2.
影子的分配在实现中分为两种:稀疏布局和密集布局.稀疏布局即每个影子独占一个缓存行,因而会导致空间浪费较严重.但当热点变量较少时,空间开销可以忽略不计,独占缓存行实现更为简单.密集布局允许不同热点变量的影子共享缓存行.在热点变量较多时该中方式可大幅度节省空间,但共享缓存行在一定程度上会降低性能.其本质上是空间开销和性能的折中考虑.在实现中,本文采用缓存池的方式提供不同的影子布局.
算法2.PDV数据持久化算法实现
1.voidPDV::persistVal(T val){
2. i=(i+1)%N;
3.chartag=0;
4.switchsdo
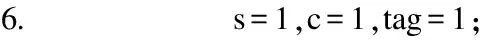

8.if(c<2)then
9. c++,tag=c;
10.else


13.if(c 14. c++,tag=3; 15.else 18.if(c 19. c++,tag=0; 20.else 22. persist((*pdata)[i],wrap(val,tag)); 23. } 算法3.PDV数据恢复算法实现 1.voidPDV::recoverFrom(T*(*p)[N]){ /*nb0记录标签值为0的数目*/ /*nbx记录标签值为0 /*n3记录标签值为3的数目*/ /*vm记录最大的标签值*/ 2.charnb0,nbx,nb3,vm←scan(p,N); 3.if(vm==0)then 4. initPDV(); //初始化 5.elseif(nb3==0∧vm>0)then 6. i=pos_max(p,N);// 引理2 7. s=1,c=vm; 8.elseif(nb3≥1nbx>0)then 9. i=pos_leap_m(p,N);// 引理 3 10. s=2,c=nb3; 11.elseif(nb0>1∧nb_3≥1∧nbx==0)then 12. i=pos_leap_0(p,N);// 引理 4 13. s=3,c=nb0; 14.else 19. /*输入数据不合法*/ 20. pdata=p; 23. } 如算法1所示,PDV提供3个操作接口:getVal获取当前值,persistVal更新值,recoverFrom启动恢复.在获取当前值时,PDV读取当前的影子并移除2比特的标签.在更新值时PDV通过算法2中的流程选择下一个影子以及计算标签值.算法2首先计算下一个影子的位置(第2行),之后根据当前的状态以及计数器的值确定下一个状态值以及变迁的值(第4到21行).最后将需要更新的值与标签值嵌合之后写入到选择的影子中并使用持久化指令刷入到NVM中(第22行). 在系统恢复时,PDV根据算法3流程扫描一个热点变量的所有影子的标签,并根据扫描结果计算最近的影子以及恢复当前的状态和每个状态对应的计数值.算法3首先统计当前所有影子标签的0值个数(nb0),中间值个数nbx,和3值个数n3以及最大值vm(第2行),之后根据引理1判断当前处于何种状态并根据引理2到4中的方法分别计算最近更新的影子(第3到19行).对于不合法的输入,PDV报告非法输入,由上层应用处理后续情况. 本文对PDV算法进行以下3个方面的评估:不同影子数对性能的影响,不同影子布局对性能和空间的影响,多线程环境下的影响.实验在阿里云ecs.re6p.2xlarge真实的持久化内存实例上进行.该实例配置8个Intel Xeon Platinum 8269CY CPU核心,32GB DRAM内存,126GB Intel傲腾持久化内存.实例运行Linux 4.19.91内存版本.傲腾内存按照SNIA[27]编程模型配置为应用直连模式,其中数据的缓存刷新使用clwb指令,且每次刷新操作后均紧跟内存屏障sfense指令. 该试验中,所有的影子均采用稀疏布局以保证不同的影子处于不同的缓存行.由于所有的影子独占64字节缓存行,不失一般性,实验采用4字节的int型热点变量进行评估.缓存池大小设置为不超过CPU LLC的大小,以尽量减少数据从NVM加载到CPU缓存的影响.由于实验主要测试写入的延迟,实验预先读取所有的缓存行以保证数据均已被加载到缓存中.每次更新热点变量时均写入不同的值,以确保对应的缓存行处于脏写状态(dirty).实验统计100万次写入的平均值,以减少噪声的影响. 图5表明,在64个影子的设置下,PDV对于热点变量的写入性能提升高达1.9倍,且在16个影子下性能已接近最优.PDV算法使得热点变量的更新被路由到不同的缓存行中.不同缓存行的刷新可以充分利用clwb的指令流并行化特性加速.而在无影子的情况下,这些写入均刷新同一个缓存行,导致clwb的并行化失效.其次PDV对每个影子仅引入2比特的标签开销,对于硬件实现较为友好. 图5 不同影子数的性能表现 该实验建立固定大小的缓存池,并从该缓存池中分配影子.缓存池的设计保证对单个PDV实例的所有影子均放置到不同的缓存行.但多个PDV实例的影子可能被放置在同一个缓存行以减少空间的占用.为了评估缓存池大小以及影子数量对性能的影响,实验设置影子数固定为16,但改变缓存池大小从1个缓存行到64个缓存行.实验设置两种不同的缓存池,分别用于分配4字节的int型变量以及1字节的char型变量.在对多个PDV实例的写入中,实验每次从中随机选择实例写入. 图6中,N=1表示实验中有一个PDV实例;size=1表示实验中缓存池大小设置为1个缓存行;x表示缓存池无法分配足够的影子.结果表明,在相同影子数下,随着缓存池的增大,吞吐量显著增加.因为大的缓存池分配影子时共享缓存行的概率更低.当size=1时,意味着所有的影子共享同一个缓存行.当size=32时,如果分配32个int型PDV实例,则意味着单个PDV实例的所有影子一定不会共享缓存行.共享缓存行是一种空间效率和时间效率的折中考虑.图6中,对于int类型,当缓存池大小为32且PDV实例数为32时,性能表现为9.1Mops.然而对于稀疏布局,32个int型带有16个影子的PDV实例性能表现为10.4Mops,1.14倍的性能提升却导致32倍的空间放大. 图6 不同缓存池与PDV实例下的性能表现 现代CPU体系结构通常采用缓存一致性算法确保缓存数据在多核CPU之间的数据一致性.多核CPU在频繁更新相同的缓存行时会出现性能比单核情况下更低的情况.为了评估多核情况下PDV的表现,实验设置多线程环境下的两种配置,其中每个线程使用独立的PDV实例.配置1,所有的PDV实例的所有影子均不共享缓存行,即稀疏部署.配置2,所有PDV的实例数固定为16,允许不同PDV的实例的影子共享缓存行,即密集布局.密集布局下多线程可能存在同时更新同一个缓存行的情况. 图7(a)中显示了配置一的实验结果.由于在该配置中,线程之间不共享缓存行,因此在平均每线程的吞吐量随着实例的影子数的增加而增加.但受限于硬件的总的并行能力,随着线程的增加,每个线程的平均吞吐量逐渐减少.另外,在多线程环境下,即使每个线程相对自己刷新不同的缓存行,但相对CPU缓存,不同线程仍然是刷新不同的缓存行,因此PDV在多线程环境下提升效果不明显.图7(b)中,影子之间可能存在共享缓存行,在多线程环境下,缓存池越大,平均每线程的吞吐随着线程的增加而下降更加缓慢.当缓存池较小时,在多线程情况下性能较单线程明显下降.多线程环境下可以通过设置线程独立的缓存池进一步提高吞吐. 图7 不同线程与不同影子数下的性能表现 本文指出在现代NVM硬件体系结构下,热点变量的更新导致频繁刷新同一个缓存行,开销较刷新不同缓存行大2倍左右.针对该问题,本文提出PDV算法,其为热点变量设置多个位于不同缓存行的影子变量,且为每个影子变量添加一个固定大小的标签.在每次更新热点变量时,PDV采用轮询策略选择不同的影子变量以确保每次写入不同的缓存行,同时根据当前的状态更新其对应的标签值,以确保在系统恢复时能正确的解析出最近更新的影子变量.对于任意数量的影子变量,本文证明了仅需要2比特大小的标签即可确保PDV总能正确的恢复.鉴于标签比特数与影子数无关,因此其对于后续硬件的实现较为友好.实验结果显示,PDV算法对于热点变量的写入速度提升高达1.9倍.


5 实验评估
5.1 影子数的影响

5.2 数据布局的影响
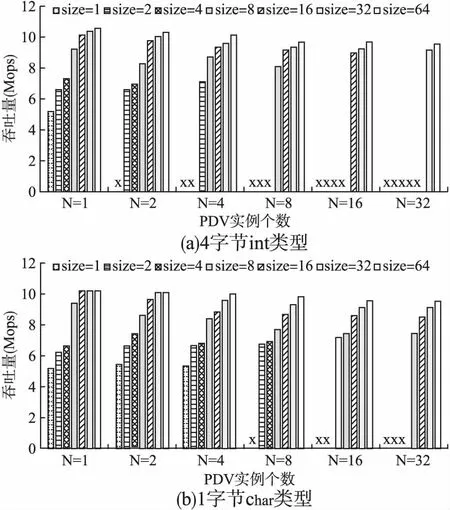
5.3 多线程环境

6 结 论
