恶意数字证书检测方法研究
2022-11-18努尔布力俞文杰
宋 丹,努尔布力,俞文杰
1(新疆大学 信息科学与工程学院,乌鲁木齐 830046)2(新疆大学 网络中心,乌鲁木齐 830046)3(新疆大学 软件学院,乌鲁木齐 830046)
1 引 言
随着许多应用和服务数字化的发展,加密作为保护信息的技术被广泛使用.谷歌透明度报告表示,截止2021年1月,谷歌浏览器加载的网页中有近95%使用HTTPS加密技术[1],安全是谷歌的首要任务,加密技术的使用,除了其机密性和真实性的预期好处,其也能帮助预防恶意攻击.同时,恶意攻击者也利用加密技术躲避检测,使得加密也成为恶意攻击者隐藏命令与控制(C2)活动的强大工具[2].思科加密流量分析报告指出,到2020年,超过70%的恶意软件活动将使用加密来隐藏恶意活动的传递、命令和控制[3].但是由于近年来HTTPS证书系统的结构缺陷,证书和证书颁发机构被破坏或操纵,更多的恶意攻击使用伪造、泄露密钥的证书或被恶意颁发的证书,恶意证书导致的恶意软件问题频发.此外,人们对证书所提供服务的认识仍然落后,当出现https://、绿色挂锁或绿色地址栏等证书标识符,大多人认为是安全或可信的,所以当出现证书警告时,用户会做出错误决策,用户教育的缺失是的攻击者有可乘之机.攻击者利用证书和用户对证书的信任感来欺骗用户[4],如何保护终端用户免受网络攻击等恶意软件问题变得越来越重要.
基于censys证书标签和证书黑名单匹配的检测方法,计算费时繁琐且对黑名单质量要求高.若对流量进行解密再重新加密以寻找威胁的方法会产生新漏洞.本文系统的使用证书的内容来实现恶意证书检测,从而预防恶意软件.本文是基于Catboost的恶意数字证书的检测方法,本文使用3264条良性证书数据和1632条恶意证书数据,分析证书的内容信息进行特征提取,将证书文本数据一边进行手工特征提取,一边使用TF-IDF方法进行特征提取,得到融合后的特征,其中手工特征提取中使用融合后的特征向量在Catboost等机器学习分类器进行训练.最后进行模型评估和特征评估,特征使用53个手工特征加前3个TF-IDF方法特征得到的特征模型效果最好,对比其他算法,Catboost算法准确率达到98.76%,运行时间对比中,LightGBM等算法的时间性能优于Catboost算法.
本研究的主要贡献是:
1)收集了1632条恶意证书数据和14388条良性证书数据,构造了恶意数字证书原始数据集.
2)本文融合基于恶意证书属性的手工特征和基于TF-IDF方法的特征,发现两类证书差异,更清晰的理解恶意证书的属性,得到恶意数字证书标准数据集.
3)改进了分类特征编码的方法,提出基于统计量的标签编码方法CLE方法.
4)提出基于Catboost的恶意证书检测方法,有效提高检测准确率.
2 相关工作
恶意证书的检测存在3种典型的检测方法.
2.1 基于黑名单的恶意证书检测
基于黑名单的检测策略是通过黑名单与证书或IP的匹配来完成的.当一个新连接来自任何黑名单中的已知恶意证书时,将其归类为恶意证书.文献[5]中黑名单包含两种形式的证书,SHA1指纹和恶意软件或恶意活动相关的序列号和主题信息,然后将每个连接与黑名单进行匹配.文献[6]针对黑名单维护的问题,提出了扩充现有黑名单的方法,提出基于机器学习的能够识别与已知恶意网站模式相似但尚未列入黑名单的网站,从而扩充黑名单列表.该检测方法的优点是操作简易,耗时少.其缺点是黑名单统计是否全面会直接影响到检测效率,黑名单统计的质量至关重要;许多恶意网站的活动时间短,被发现为恶意攻击后,用户访问会显示警告,所以攻击者也会减少恶意活动甚至关停网页,由于恶意攻击的不断更新,黑名单更新的工作很费时且繁琐.
2.2 基于证书内容的恶意证书检测
2011年,Mishari Almishari[7]等人提出全面研究SSL证书和广泛的测量,实现网络欺诈行为的检测.2015年6月Zheng Dong[8]等人也使用机器学习算法和公钥证书数据来检测钓鱼网站,随机森林算法中FPR较低且运行速度快,AUC值为0.98,平均概率算法中TPR较高,运行速度慢,但是AUC值为0.99.2016年9月ZHENG DONG[9]等人研究了基于证书内容的流氓证书检测.2017年,Sankalp Bagaria[10]等人使用证书特征和加密流量的流特征,来研究机器学习技术来让浏览器判断证书所属的服务器是否是恶意的,从而判断是否访问该网站.文献[11]中,2018年安全公司Splunk的研究人员使用支持向量机(SVM)算法对恶意软件活动中使用的证书进行检测,达到了91%的准确率.2018年末文献[12]采用了特征提取和深度神经网络,认为信息较少的证书更容易引起怀疑,从证书内容中提取了能够区分恶意证书和良性证书的特征,使用深度神经网络模型进行恶意证书检测,恶意软件证书检测的准确率为94.87%,钓鱼证书检测的准确率为88.64%.2019年7月,Kabilan Gnanavarothayan[13]等人使用神将网络分类算法,并参考文献[13]的特征,钓鱼证书检测使用43个特征准确率最高,为71.69%,恶意软件证书检测使用9个特征之后进行了标准化,准确率为94.2%.2020年4月Akanchha[14]研究了基于机器学习的钓鱼证书检测,最终C4.8决策树算法准确率最高,为97%.2021年,Li jiaxin等人[15]提出VFE证书特性获取系统,该系统从证书基础信息分析、标准检验、证书链建设、证书链验证中获得的证书特征,还加入了软件包和工具的一些输出特征.使用此系统提取到的特征,在机器学习模型中进行训练,结果显示集成学习模型效果最稳定且有效,平均准确率为95.9%,其中SVM模型准确率最高,为98.2%,其使用的VFE特征提取器也能捕获恶意X.509证书的关键特征.基于证书内容的检测方法的优点为使用证书中的必要字段作为特征,攻击者破坏这些数据的可能性小.其缺点是获取证书数据样本较繁琐,本文通过恶意证书的指纹值在互联网设备搜索引擎中来获取证书完整信息,操作繁琐且工作量大.
2.3 基于censys证书标签的恶意证书检测
文献[16]提出基于censys证书标签发现可疑中间人攻击SSL证书,共分为两步:发现可疑服务器证书,验证可以服务器.首先使用Censys中有 “trusted”和“unexpired”标签证书过滤形成可疑证书和信任证书两类数据,找到可疑证书的MITM主机的指纹值和IP地址,即发现了可疑服务器,用可疑网站域名重新扫描,提取相应的不受信任的证书,并测试他们是否为公开中间人攻击主机.其结果显示不受信任的证书的主机更容易收到中间人攻击.
3 恶意数字证书检测
针对恶意软件等恶意行动利用数字证书来影藏其恶意行为的问题,本文基于Catboost的恶意数字证书检测方法能实现恶意数字证书检测,成功实现恶意软件的预防.检测方法的技术路线是如图1所示,具体的步骤分为4步.
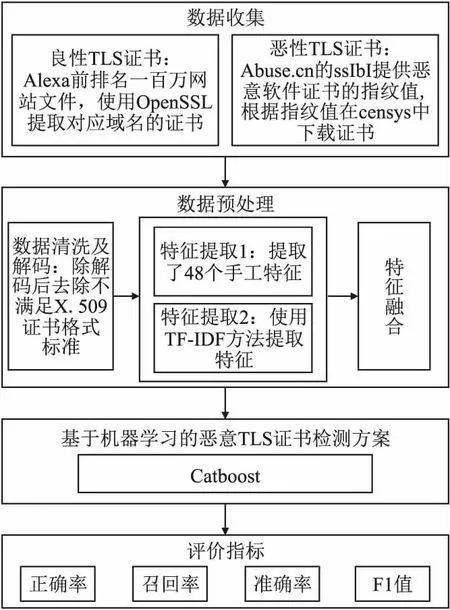
图1 恶意数字证书检测的技术路线图
第1步.数据收集.
第2步.数据预处理.首先进行数据清洗和解密,特征提取中,一部分特征属于手工特征,一部分使用TF-IDF方法提取特征,最后融合两组特征.
第3步.检测方案.对比使用Catboost等机器学习检测算法.
第4步.评价指标.评价分析实验结果.并分析特征的重要性.
3.1 数据收集
良性证书来自于根据Alexa排名前一百万的网站域名排名文件,使用openSSL工具包的s_client命令提取对应域名的证书文件,良性证书数据提取通过编写python脚本实现的.恶意证书是从abuse.ch中提供的恶意证书SHA1值,在censys网站获取该SHA1值对应的pem格式的证书文件.良性证书集有14388条数据,恶意证书数据共有2267条恶意数据.图2是证书收集阶段,加密的证书文件.

图2 加密证书样式
3.2 数据预处理
3.2.1 数据清洗及解码
对数据进行数据清洗工作,保证数据纯度的同时,又在一定程度上降低了数据的维度.数据清洗首先是使用OpenSSL开源工具包检测证书文件是否满足X.509证书格式标准.解密是通过使用OpenSSL的′openssl.exe x509-text-in ′命令,在命令行中完成加密证书文件的解密.良性数据经过数据清洗后,验证通过占比达到98%,数据均能通过检测.由于恶意证书数据每年收集数据较少且发现时间久的证书很多已被吊销,清洗后验证通过率为72%,数据数量从2267条减少到1632条.图3是解密后的数据,解密后的证书服从X.509证书标准结构.

图3 解密证书样式
3.2.2 特征提取
以数字证书内容为研究主体,研究其具有的发行者名称、使用者名称、有效性等多种组成部分,研究有助于识别攻击者常见模式的关键信息,得到特征.
2.2.2.1 手工特征
总共考虑了53个特征,特征从证书结构分别研究,分为4类特征,分别为证书属性部分、证书发行者属性、证书使用者属性和其他属性.其中特征的类型分为布尔型、数值型、文本型.特征的获取,一部分是直接从证书中获取的,另一部分是对证书内容的切分或组合转换得到的,不直接使用.目的是使用有用的特性来检查攻击者的行为和模式.其中手工特征提取同样使用Python编程脚本实现.
1)证书属性部分.
数值特征包括ExtensionNumber:证书中扩展内容的个数;certificate_serial_number_len:证书编号长度.
分类特征包括certificate_version:证书版本号;signature_algorithm_name:证书签名算法名;basic_constraints:基本约束;Extention_key_usage_value:密钥用法类型;Extention_extened_key_usage:密钥用法扩展;validity_time_to_unvalid:证书有效期天数.
布尔特征中,新加入IS_key_usage_value:是否含有密钥用法类型;IS_extened_key_usage:是否含有密钥用法扩展;IS_AuthorityKeyIdentifier:是否含有发行者密钥标识符;IS_SubjectKeyIdentifier:是否含有主题密钥标识符;IS_SubjectAlternativeName:是否含有主题别名;IS_ocspUrls:是否含有证书在线状态协议地址;IS_CrlDistributionPoints:是否含有证书撤销列表地址.
2)证书发行者属性.
数值特征包括IssuerElements:发行者元素个数.
布尔特征包括IS_Issuercommon_name:是否含有发行者通用名;IS_IssuerOrganization:是否含有发行者组织;IS_IssuerLocation:是否含有发行者地址;IS_IssuerCountry:是否含有发行者国家;IS_IssuerState:是否含有发行者声明;IS_IssuerSerialnumber:是否含有发行者序列号;Issuer_is_.com:发行者CN字段是否为“.com”的域名;Is_freecert:是否为免费生成证书;Is_IssuerCNisdomain.com:发行者CN是否为domain.com;Is_IssuerCNis*:发行者CN是否为*.新加Is_IssuerCNislocalhost:发行者CN是否为localhost;IS_IssuerOrganizationUnit:是否含有发行者组织单元;IS_IssuerEmailaddress:是否含有发行者邮箱.
3)证书使用者属性.
数值特征包括SubjectElements:使用者元素个数.
布尔特征包括IS_SubjectCommon_Name:是否含有使用者通用名;IS_SubjectOrganization:是否含有使用者组织;IS_SubjectLocation:是否含有使用者地址;IS_SubjectCountry:是否含有使用者国家;IS_SubjectState:是否含有使用者声明;Subject_is_.com:使用者CN字段是否为“.com”的域名;SubjectonlyCN:使用者主体是否只有CN字段;IS_SubjectCommonNameIp:使用者CN字段是否是IP地址,Is_IssuerCNisdomain.com:使用者CN是否为domain.com;Is_SubjectCNis*:使用者CN是否为*.新加Is_SubjectCNislocalhost.localdomain:使用者CN是否为localhost.localdomain;IS_SubjectCountryisXX:使用者国家是否为XX;IS_SubjectSerialnumber:是否含有使用者序列号;IS_SubjectOrganizationUnit:是否含有使用者组织单元;Is_IssuerCNisexample.com:使用者CN是否为example.com;IS_SubjectEmailaddress:是否含有使用者邮箱.
4)其他属性
布尔特征包括Is_selfsigned:证书是否为自签名证书;Is_extended_validated:证书是否为扩展验证;
Is_organization_validated:证书是否为组织验证;Is_individual_validated:证书是否为个人验证;Is_domian_validated:证书是否为域验证.新加入Is_validated:是否含有证书等级信息和Is_subjectandissuer_notCN:发行者使用者CN是否都没有.
本文提取的特征中,参考了文献[10]和文献[13],其余为本文新加特征组成,其中新加入了很多证书扩展、发行者和使用者属性特征.本文的分类特征需要使用2.2.3章节的基于统计量的标签向量化方法CLE方法,进行向量化处理.布尔类型的特征可直接用0,1数值进行替换成数值数据.
2.2.2.2 TF-IDF方法特征
证书解密后的数据,经过TF-IDF方法处理后得到特征.TF-IDF[17](term frequency-inverse document frequency)是一种使用统计的技术进行数据挖掘的常用加权技术,用于统计一个词语在全部文件中的重要程度.其中TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency),其计算公式如下:
(1)
(2)
tfidfi,j=tfi,j×idfi
(3)
其中ni,j是该词在文件dj中出现的次数,分母则是文件dj中所有词汇出现的次数总和;|D|表示语料库中的文件总数,分母表示含有ti的文件数目.
3.2.3 基于统计量的标签编码方法CLE
在本文中,含有离散型的分类特征要进行向量化操作,为了实现离散数据向量化,提出了基于统计量的标签编码count_LabelEncoder方法,简称CLE,即通过统计量来确定文本对应数值的映射图.上述分类特征,都要进行CLE的向量化操作.算法的步骤是:首先,分类数据进行缺失值填充,用“null”字符串填充.接着对合并的两类数据进行数值化处理,是先统计列特征字段数据的种类,并统计其出现频次,将出现频率高的数据特征的数值设置为1,次之的设置为2,以此类推,统计频数较高的数据特征的数值化的值越小.由于两类特征拥有不同的属性,其中良性特征拥有规范属性,但恶意特征拥有较多离群值,此特征向量化的方法,能实现类内特征的有效信息,能实现缩小类内特征,增大类间特征的作用,该算法对本文的离群值较敏感.算法描述如算法1所示.
算法1.The CLE algorithm
输入:良性与恶意合并数据特征集文件中其中某一特征
X={x1,x2,…,x8}
过程:使用“null”字符填充缺失值
for 1=1,2,…,8 do
df=dict(value_counts(xi))
k=1
for item in df:
df[item]=k
k=k+1
for row in xi:
dd=xi.loc[row]
yi.append(df[dd])
输出:Y={y1,y2,…,y8}
3.2.4 标准化
在本论文中,特征集分类特征和数值特征分布在非常不同的范围内.标准化是将数据集中的数值特征值转换为一个共同的规模的过程.为了规范化这两类特征,使用了最小最大归一化方法,公式(4)如所示:
(4)
这种标准化方法重新调整了[0,1]之间的特征范围.使用数据规范化的主要优点是增加数值稳定性、减少训练时间以及提高分类模型的精度.
3.2.5 特征融合
本文列特征的融合,直接将两个特征进行行上合并,手工特征连结特征了TF-IDF方法特征,形成了融合特征.即将两个特征向量组,列连接成一个特征向量组,若手工特征的个数为x,TF-IDF方法特征的个数为y,则融合特征的个数为x+y,即行数不变,列数改变.特征融合能汇集两个特征集中具有具差异的分类信息,增加特征的数量,提高分类的有效性.
3.3 Catboost算法
Catboost[18]是一种基于对称决策树的梯度提升算法,其能实现设置参数少、支持分类特征数据和高准确率的分类,其还支持GPU版本.与类似的前期算法XGBoost、LightGBM相比,CatBoost的改进了一些功能:其能自动处理分类特征,采用的是完全对称树,其加入了针对分类特征的组合特征,采用排序提升的方法对抗训练集中的噪声点,避免梯度估计的偏差,进而解决预测偏移的问题,缓解过拟合.其中自动处理分类特征的方法是首先使用热独编码,如果设置热独编码最大分类值个数限制,当超过限制数时,会首先对分类特征进行统计分析,计算每个分类值的出现频率,之后再加上超参数,生成新的数值特征,其公式如下:
(5)
其中countInClass表示当前列中有多少个分类值,prior是根据初始设定的参数确定的值,totalCount是具有与当前分类特征值匹配的对象的总数.Catboost的缺点是由于要进行分类特征的判断及处理,所以需要更多的计算时间和存储资源.
4 实验结果与分析
4.1 实验环境
本文的实验环境为:Windows系统,CPU主频8×3.4GHZ,运存16G,内存64GB,机器学习工具使用python中的scilit-learn0.20.3和keras2.2.4.
4.2 数据集
本文构建的证书数据集,具体特征如表1所示,由于数据集数据样本不均衡,接近40∶1,采用降采样,只使用前3264条良性证书,使数据比例为2∶1.

表1 实验数据表
4.3 评价指标
本文的使用的性能评价指标是标准的分类评估方法,包括准确率、召回率、精准率、F1值和运行时间.准确率、召回率、精准率、F1值的计算公式如下:

(6)

(7)

(8)
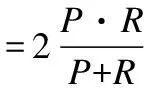
(9)
其中P,R,TP,FN,TN和FP分别是精准率,召回率,true positives的个数,false negatives的个数,true negatives的个数和false positives的个数.
4.4 参数选定
本文使用了用网格搜索遍历的策略,首先定义要进行参数的选择范围,根据定义的参数表格选择参数进行模型训练,通过准确率来评估参数的选定,得到最优的参数.表2是经过选择后得到的值.
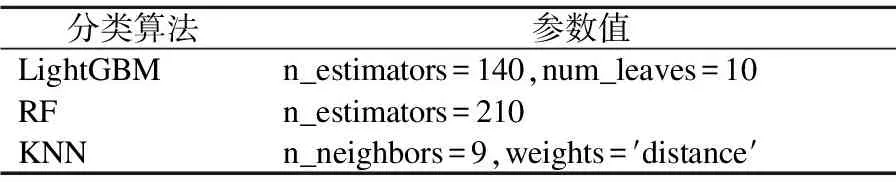
表2 参数选定表
LSTM模型中,epoch参数的选择,得到曲线图,如图4所示,该图随着训练轮数的增加,训练损失向下倾斜,验证损失向下倾斜,到达一个拐点,之后就慢慢达到了平滑,能正好拟合LSTM模型.能看到在epoch为6时,能慢慢平滑,中间会有些波动,通过多次训练模型都能在15次时都能达到平滑,所以文中的epoch设定为15.其中batch_size设置为32.

图4 LSTM模型准确率和损失值变化曲线
根据第2.2.2节中提到的特征,得到的特征包括TF-IDF特征和53个手工特征,通过处理解密后的数据,进行 TF-IDF处理,会得到不同个数的特征,进行了实验,对比不同特征个数的准确率变化,得到最合适的参数个数.得到图5,其中使用Catboost算法,对比了1到100区间内不同特征个数下准确率的变化,特征个数为3时准确率最高,3个特征分别为:′dns′,′com′,′timestamp′.在特征个数为3之后,会稳步的下降,之后又随着特征个数的增多准确率不断提高,选择的特征中,都会含有很多编码特征,但是编码特征属于证书的加密属性,不能提取出可解释的数据.所以选定TF-IDF特征个数为3.

图5 准确率变化图
4.5 实验结果与分析
本文使用的向量化算法是本文提出的基于统计量的标签编码方法CLE,该方法在2.2.3节中有详细介绍,但是本文使用的 Catboost算法可以处理本文的需要向量化的分类特征,为此做了对比实验,从结果表3能看出,使用Catboost进行向量化操作和使用CLE方法进行向量化操作,准确率相差1.84%,CLE方法能更好的表示数据.所以本文使用CLE方法进行分类特征编码.

表3 分类特征编码方法对比表
评估模型中,为更好的实现恶意证书检测,在机器学习算法中,对比了支持向量机(SVM)、K最近邻(KNN)、随机森林(RF)、多层感知器(MLP)、朴素贝叶斯(NB)、长短期记忆网络(LSTM)7种机器学习分类算法,以得到适用于证书数据的有效检测算法.得到表4结果表,可以看出,Catboost表现最优,其的准确率能达到98.76%,相似的决策树算法LightGBM和随机森林算法紧随其后,能看得出基于树和基于核的算法能较好的结果,基于神经网络和朴素贝叶斯的算法,不能得到较好的结果.

表4 模型评估结果表
通过表5所示,能看出由于要进行分类特征的处理所占用时间较长,Catboost算法的运行时间不是最优,但会比LightGBM和神经网络算法运行时间短.
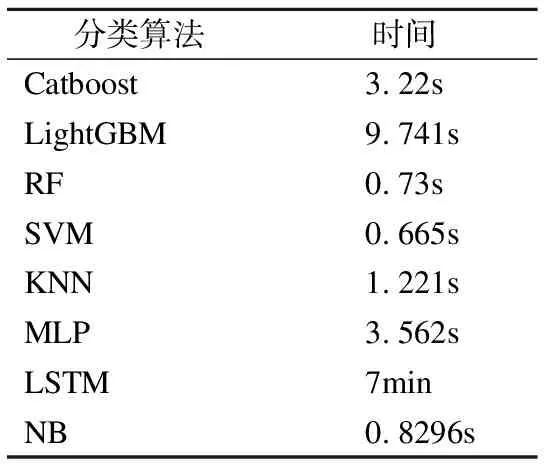
表5 运行时间表
模型解释中,得到了整体特征重要性图,如图6所示,其通过评估每个特征对预测结果的贡献程度,将模型得到的结果进行可视化展示,其值越大该特征对结果有促进作用,越小说明该特征对分类有抑制作用.其中的每一个数据点表示一组数据,结果如图6所示.可以看出本文加入的特征IS_key_usage_value:是否含有密钥用法类型,是对结果影响最大的特征,对分类有很好的促进作用.表现较好的布尔特征有密钥用法扩展、证书撤销列表地址、证书在线状态协议地址和主题别名,这些特征均属于本文加入的特征,这些布尔特征都是证书扩展属性中提取的特征,扩展属性显示了除去证书标准信息之外的其他信息,可以看出,良性证书中会有更多扩展属性,恶意证书中很少证书含有证书扩展属性.其中表现较好的分类特征包括基本约束、密钥用法类型、密钥用法扩展和证书签名算法名,在使用CLE向量化方法后,在分类中能拥有较好的特征重要性.其中TF-ID特征中′dns′特征也拥有较好的模型贡献度.还能看出证书是否为自签名证书或者免费证书,也是恶意证书进行恶意攻击的关键行为模式.

图6 整体特征重要性排序
5 总结与展望
本文实现恶意证书检测的完整处理过程,整个研究方法框架比较明确.通过加入良好的手工特征,提出分类数据编码的CLE方法,得到53个手工特征和3个TF-IDF特征利用Catboost方法实现了恶意证书检测的目的.Catboost学习模型表现优异,达到了98.76%的准确率,通过该模型的特征重要性排序图看出本文加入的特征能更好的区分两类特征,通过特征分析也能看出恶意证书中较少拥有证书扩展属性,自签名证书普遍被恶意证书使用.随着证书被用在恶意活动中,本文基于证书内容的检测操纵更容易且更全面监测恶意软件.但随着攻击的演变和攻击者对证书不同程度的操纵,未来可改进的方向:1)通过不断发现新的恶意模式并引入新的特征.2)由于本文收集的恶意证书数据是网站收集的恶意软件的恶意证书,恶意证书的种类不够全面.未来,将引入更多种类的恶意证书数据,扩充恶意数据集,改善数据不平衡的情况.3)引入其他检测技术,以提高整体检测效率.
