健美操运动员高难度视频动作识别方法研究
2022-11-16李慧萌金庆凯赵树桐
贺 莉,李慧萌,金庆凯,赵树桐
(皖西学院 体育学院,安徽 六安 237012)
随着健美操事业的发展,运动员的技术水平得到了大幅度的提高。在健美操运动竞技中,运动员对于高难度动作技术的掌握是获得胜利的核心[1]。在一些国际比赛中不难看出,国内健美操运动员与国外运动员之间的差距主要来自高难度动作,成套中难度动作整体布局均衡性不够,健美操运动员对高难度运动的完成质量也比较差[2]。针对这种问题,有专家建议采用录像分析法来训练运动员的动作技术,提高竞技水平,主要目的是通过动作图像揭示动作特点和规律,准确地捕捉各个瞬间,为运动员训练科学性提供理论依据[3]。
在对健美操运动员训练中,如何精确地识别高难度视频中的动作是一个难点。只有精确地识别出运动员的动作,才能更好地为健美操运动员的后续训练提供依据。视频动作识别技术一直是国内外研究的重点,特别是在计算机视觉技术发展越来越成熟之后,主要利用计算机来识别视频数据进行处理和识别[4-6]。人体运动识别技术应用范围十分广泛,国内外研究内容也比较多,如基于Kinect的动作识别方法、基于3D-LCRN的视频动作识别方法,这两种识别方法在实际应用中,受到光照、遮挡等因素的影响,动作特征的表征效果比较弱,方法的实用性需要进一步提高[7-9]。因此,本文提出健美操运动员高难度视频动作识别方法,以解决上述传统的视频动作识别方法中存在的问题。
1 健美操运动员高难度视频动作识别方法设计
1.1 检测视频动作
在检测前,设置一个判断阈值,对健美操高难度视频序列中相邻的两帧或多帧图像中相对应的像素点进行计算,计算出灰度差值的绝对值,与设置好的判断阈值相比较,从而提取出运动目标。以连续的两帧计算,计算公式为:

式(1)中表示包含动作目标的二值差分图像,Li(x, y)表示第i帧图像中(x, y)处的像素值,Li-1(x, y)表示前一帧图像中对应的像素值,ψ表示预先设置的阈值[10]。当G(x, y)的计算结果为1时,表示连续两帧图像对应像素点的灰度值大于设置的阈值ψ,通过这一判断可知,当前帧中的该像素点属于前景,反之属于背景[11]。将前景与背景区分开,即可完成对动作的检测。在后续操作中,提取出动作特征用于后续识别。
1.2 提取视频动作整体特征
使用Zernike矩提取视频动作整体特征,一幅图像的Zernike矩就是该图像在Zernike多项式上的投影。对于健美操高难度视频图像上的点(x, y),与其相对应的Zernike多项式为:


式(2)(3)(4)(5)中n为非负数,m为正整数或负整数,满足n-∣m∣为非负偶数,Um(a)表示角函数,Wnm(r)表示径向多项式[12]。具体表示为:

式(6)(7)中t表示方向,Zernike多项式和径向多项式Wnm(r)满足正交性,并且Zernike矩还具有旋转不变性,有效地减少了Zernike矩包含的冗余信息[13]。对于连续函数z(x, y),其相对于坐标原点的Zernike矩为

式(8)中F*nm(r, a)表示Zernike多项式的共轭多项式。对于图像,采用求和的方式来代替积分:

式(9)中L(x, y)表示图像中的像素值。对于某一帧图像,在计算前,将平移图像的重心到坐标原点,以单位圆为映射范围完成图像像素点的映射,再利用公式7计算出对应的Zernike矩[14]。对于一个图像序列,计算出3D Zernike矩的公式为:

式(10)(11)中O(i, x, y)是引入的第三维度,u和v表示的是由用户定义的参数,pic表示整个序列中图像的数目,-1表示前一帧图像的重心,表示当前图像的重心。在计算过程中视频图像可能存在不同的数目,为了避免对计算结果产生影响,对计算出的3D Zernike矩进行归一化处理。处理如下:

式(12)中C表示目标的像素个数。使用公式(9)和公式(11)来得到对应的3D Zernike矩即为目标的整体特征,在获得此特征后,使用CNN-RNN模型识别视频动作。
1.3 视频动作特征识别
由于健美操视频中时空场景比较复杂,图像中包含的大量噪声会影响动作识别的精确性,也会为识别方法增加不必要的计算量[15]。因此在提取特征之前,在视频动作识别过程中引入注意力机制,赋予CNN-RNN模型自动筛选人物相关特征功能。
通过一个串行支路将通道注意力和空间注意力连接起来。在通道注意力中,对获取通道注意力进行分散处理,将其映射在不同通道,增强通道有效信息,抑制通道无效信息,在空间注意力模块中,引入加权调整参数,对特征平面进行池化以及激活处理,获取通道值为1的空间注意力平面,得到注意力特征。
对空间位置权重加以反复更新,在下一刻CNN特征输入上映射空间注意力机制,充分结合时间以及上下文信息,基于动态学习观测关键动作特征变化。
对于动作识别过程中的时间注意力,之前在不同时刻权值获取中,基于卷积神经网络赋予不同时刻不同值,提高特征的表征能力。具体过程如图1所示。

图1 深度特征幅值过程示意图
以视频动作数据中包含的特征信息作为输入,使用CNN-RNN模型多层逐级地表征输入特征。通过LSTM,时序建模CNN导出特征,对视频动作时空特征加以积聚处理,将其输入分类器进行动作识别。识别过程如图2所示。

图2 CNN视频动作识别示意图
通过卷积神经网络,对任意帧图像高层表征加以导出,基于LSTM体系结构,对时序深度特征加以提取,该体系结构包括512个隐藏节点,特征输出在任意时刻都在发生。神经网络训练过程中,输出层不同视频片段的图像帧均分配到0-1权重,表征后面帧获取信息重要程度。在测试过程中,加权求和帧分数,通过softmax分类器加以分类,完成视频动作识别。至此,健美操运动员高难度视频动作识别方法设计完成。
2 健美操运动员高难度视频动作识别方法实验研究
2.1 实验准备
实验研究主要在MATLAB环境下进行,使用的视频序列为健美操基础动作数据集中的视频通过分帧化得到,在实验前将每一视频序列统一处理为灰度图像。实验采用的动作片段如图3所示。

图3 实验部分数据集
对于实验数据的处理,先对每个视频片段进行分帧处理,转化为彩色格式的图像序列,再将其转换为灰度图像序列,再使用不同的识别方法识别视频动作。
考虑到实验的公正可靠,实验以对比实验为主,将基于3D-LCRN的视频动作识别方法、基于Kinect的动作识别方法和提出视频动作识别方法作为实验对象,设计两组对比实验,验证识别方法的实用性。针对对比实验搭建的平台配置如表1所示。

表1 实验平台配置
设计的对比实验一组为识别精度实验与验证,另一组是计算复杂度实验与验证,其中:计算复杂度以计算成本和迭代次数来衡量。
2.2 计算复杂度实验结果与分析
为了验证视频动作识别方法的计算复杂度,使用MATLAB软件作为主要平台,将实验图像作为输入,使用不同的视频动作识别方法处理实验图像,通过MATLAB输出实验结果,如图4所示。

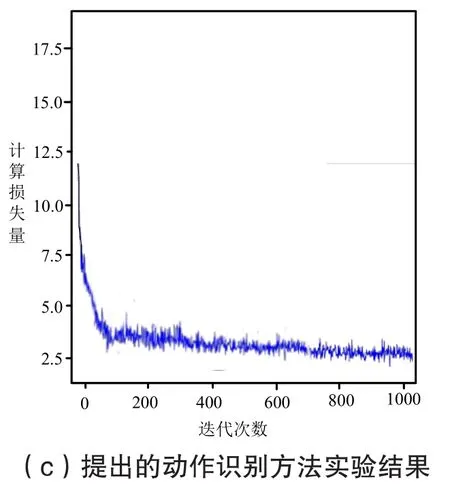
图4 不同识别方法的计算复杂度实验结果
对比观察图中结果可知,基于3D-LCRN的动作识别方法,在迭代计算过程中,计算并不稳定,在迭代次数达到200次左右时,计算损失量逐渐平稳,但是损失量在7.5以上,侧面说明了该识别方法的计算复杂度比较高;基于Kinect的动作识别方法在迭代计算过程中,计算比较稳定,同样在迭代次数达到200次左右,计算损失量逐渐平稳,损失量虽然没有上一识别方法多,但是整体计算复杂度也是比较高的;与前两组实验结果相比,提出的视频动作识别方法在迭代计算未达到200次时就已经有平稳的趋势,并且计算损失量极低,这一现象说明该方法的计算复杂度比较低。
2.3 识别精度实验结果与分析
在识别精度实验研究中,随机选择实验数据中某一组图像数据,将其作为识别目标,使用不同的视频动作识别方法识别实验视频数据,利用统计软件计算并输出识别精度结果,如表2所示。
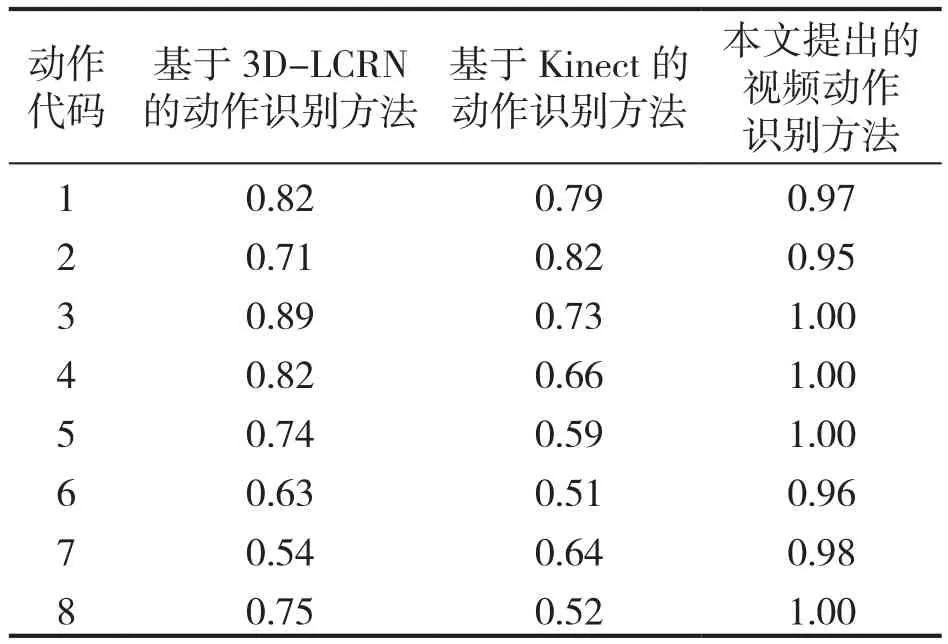
表2 不同识别方法识别精度实验结果
从表2中数据可以观察到,对于不同的健美操高难度动作,识别精度存在一定的差异。三组实验结果对比观察可知,本文提出的视频动作识别方法对于实验数据中的大多数动作均能达到1.00的识别精度,即使有未能达到1.00的,其识别水平也在0.95以上,但是另外两组数据显示,对于不同的视频动作,其识别精度不仅不稳定,而且识别水平较低,未能达到0.95以上。结合计算复杂度可知,设计的健美操运动员高难度视频动作识别方法计算复杂度低、识别精度高,该方法的实用性能更好。
3 结束语
本文围绕健美操运动员高难度视频的分析展开调查,在大量研究文献和资料的支持下,设计健美操运动员高难度视频动作识别方法,并在方法设计完成后,利用大量对比实验,验证了提出的视频动作识别方法的可靠性和实用性。目前,视频动作识别技术已经在众多领域得到了应用,考虑到基于视频内容的动作识别技术的重要性,在后续研究中,将对动作情感发掘和数据集的扩充进行深入研究与分析,进一步完善视频动作识别技术。
