基于改进的S-ReLU激活函数的图像分类方法
2022-11-16徐静萍王芳
徐静萍, 王芳
(燕山大学理学院, 秦皇岛 066004)
图像分类主要分为细粒度图像分类[1]和图像分类两个方向。细粒度图像主要针对同一个大类下的不同子类,它们类间差异小而类内差异大,而图像分类是针对不同物种进行的识别,物种的类间差异性大,相对更容易些。对于图像分类任务,如何高效地提取物种间具有区分性区域的特征成为学术界讨论最为热烈的问题。在深度学习(deep learning,DL)[2]没有提出之前,人们进行图像分类任务通常依靠的是人工设计的特征提取器,这需要研究者根据分类任务针对性的设计特征描述,人为设计局部不变性的特征描述需要大量的专业知识,这严重影响了模型的泛化能力。相较于传统手段图像识别,深度学习的出现使得图像分类的精度得到迅猛提升。随着人们对DL理解的加深,生成对抗性网络[3]、注意力机制[4]、胶囊网络[5]以及迁移学习[6]等一系列优秀的深度学习模型被引入,极大地拓展了图像分类任务的手段,具有分类效果好、模型精度高、应用范围广泛等诸多优点。
卷积神经网络(convolutional neural network,CNN)的发展,使得人们在计算机视觉任务中取得了巨大进展。在2012年的ImageNet 挑战赛中,He等[7]提出的CNN模型的识别性能首次超越了人类视觉能力,错误率仅有4.94%。激活函数是CNN模型性能迅猛提升的重要原因,它使模型具备了非线性性质,增加了模型的复杂度,解决了以线性函数为激活函数时不能处理线性不可分问题的难题,极大地提升了模型处理问题的能力。
Sigmoid[8]和Tanh[9]是最早应用于CNN的非线性饱和激活函数。但是Sigmoid和Tanh都存在软饱和问题,即当参数在训练过程中处于饱和区时,会出现梯度消失的现象。基于以上问题,Glorot等[10]提出了ReLU函数,它是非饱和激活函数,可以缓解饱和函数存在梯度消失的问题。由于ReLU将所有负值取为0,导致模型在训练过程中很容易出现“神经元死亡”[11],从而致使模型分类效果下降。SoftPlus[12]被认为是ReLU 的平滑近似,避免了ReLU 的“神经元死亡”的问题,但也导致了“均值偏移”的问题。Maas等[13]提出给所有样本负区域的值一个非零的斜率。Clevert等[14]解决了“均值偏移”的问题,提出了ELU,但也引入了和LeakyReLU类似的问题——需要人为设定超参数。He等[7]则建议将ReLU负值的斜率设为一个可学习的参数,解决了人工调参的难题,但由于函数两部分都是线性的,模型的非线性能力下降。Misra[15]提出了一个几乎处处光滑的非单调可导激活函数Mish,提升了模型的分类能力,同时也增加了模型的计算量。
针对目前的激活函数存在的问题,现将ReLU和SoftPlus组合优化,构造新的激活函数S-ReLU。 在MNIST 和CIFAR-10 数据集上,利用S-ReLU 与其他激活函数在LeNet-5 模型下进行实验,以对比分析不同激活函数分类效果。
1 相关工作
主要介绍了非饱和的非线性激活函数ReLU和SoftPlus,并分析了两者的优缺点。
1.1 ReLU激活函数
Glorot等[10]受到神经科学中人类脑神经元接受刺激后的表现的启发,首次将ReLU应用于神经网络中,通过让CNN模拟生物神经网络的工作流程,提升了模型的表达能力。ReLU 函数的形式为
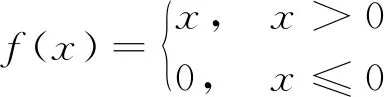
(1)
ReLU函数与饱和激活函数Sigmoid和Tanh相比,将模型的负区域取值归为0,使CNN具有了稀疏性,从而有效地解决了梯度消失的问题。但是,当训练阶段的学习率很大时,会出现“神经元死亡”现象,其图像如图1所示。
由图1可知,当x≤0时,其输出值与导数恒为0,一方面使模型输出具有了随机性,提升了模型的泛化能力;另一方面,使带有负样本信息的神经元无法工作,既造成了样本信息的缺失,又因其梯度常为0,导致权重无法更新。当x>0时,输出值随着x的增大而增大,其导数为1,数值小,计算简单,加快了模型的收敛速度。
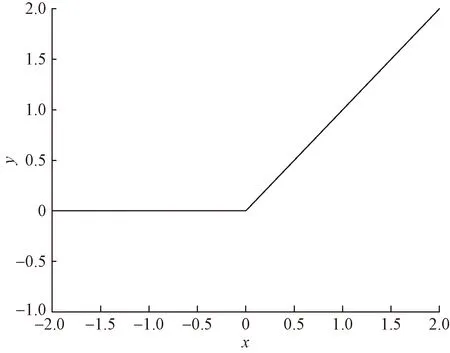
图1 ReLU函数
1.2 SoftPlus激活函数
SoftPlus被认为是ReLU 的平滑近似,它们具有许多相似性,SoftPlus 的表达式为
f(x)=ln(1+ex)
(2)
SoftPlus的图像如图2所示,由图1可知,当x<0时,ReLU直接让所有负值等于0,由图2可知,SoftPlus则使用一种更加平滑的方式减少负区域数值的输出,即随着x的增大,结果不断减小直至趋于0,避免了ReLU强制为0时导致的“神经元死亡”的问题,从而使网络模型变得更加稳定。
另外,由图2可知,SoftPlus的输出范围为(0,+∞),当x→+∞时,其导数为1,当x→-∞时,其导数为0,既具备了ReLU计算简单、收敛速度快的优点,又促进了负样本权重的更新。但当x<0时,其输出值恒为正值,导致了均值偏移。
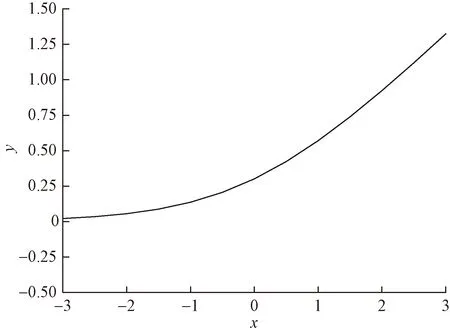
图2 SoftPlus函数
2 S-ReLU激活函数
基于ReLU函数和SoftPlus函数构造了一种新的函数S-ReLU,分析了它的性质,并将其与ReLU和SoftPlus进行对比分析,体现了S-ReLU的优势,然后给出了S-ReLU如何在模型中进行正向传播与误差优化。
2.1 S-ReLU函数
基于式(1)和式(2)所示两类激活函数构造如下的S-ReLU激活函数为
(3)
从式(3)可知,当x>0时,输出结果是恒等函数,即输入等于输出,而当x≤0时,输出结果是由ReLU和SoftPlus构成。
S-ReLU激活函数的导数为
(4)
式(4)中:α=ln(1+ex)。由f′+(0)=f′-(0)=1可知,f(x)是可微的,且从图3可以明显看到其导数并不是常数,因此,f(x)具有非线性,这将极大提高模型处理复杂问题的能力,增强模型的泛化能力。
图3 S-ReLU函数及导数
首先,与ReLU相比,S-ReLU增加了负样本信息,与SoftPlus在负区域取值总是恒大于0相比,S-ReLU取值有正有负,可以有效减缓“均值偏移”问题。与同是增加负样本信息利用率的ELU函数相比,S-ReLU 更加贴合生物学上神经元响应的特点,提升了模型的抗干扰能力。
其次,当x→+∞时,f(x)→∞,函数没有上界,可以加快模型的收敛速度和避免函数饱和后训练速度的急剧下降; 当x→-∞时,f(x)→0,说明函数是有下界的,使模型具有较强的正则性,增强了模型应对复杂问题的表达能力。
再次,S-ReLU函数由指数函数和对数函数构成,与只有恒等函数构成的函数[式(1)]相比更加复杂,使得S-ReLU函数在实际应用中需要更多的时间,但S-ReLU函数在正向传播过程中可以返回一个有效的负值,防止了梯度消失。
S-ReLU函数与ReLU函数的结构极度相似,使得S-ReLU函数也具备了ReLU函数的一些优点,如稀疏性,不仅可以减少模型的计算量,还能提升模型的表达能力,使网络更加关注任务本身。
2.2 基于S-ReLU的正向传播
假定每个神经元的输入值为z,经过激活函数后的输出结果为a,激活函数为σ,则
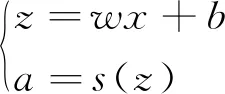
(5)
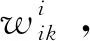
(6)
式(6)中:m为第i-1层的神经元个数。
当σ是S-ReLU函数时,有
(7)
从式(7)可知,S-ReLU与ReLU的不同之处是: 在模型的正向传播过程中,输入值小于等于0时,输出结果不再是固定常数零,它使得网络在反向传播过程中产生了一个小的梯度流,促进了网络中权重矩和偏置更新,进而减小了模型的错误率。
此外,为了简化式(7),还可以用矩阵表示为
ai=s(zi)=s(ai-1wi+bi)
(8)
2.3 权重和偏置的优化
神经网络在反向传播过程中利用梯度下降法[16]更新模型中的权重w和偏置b,并以此减少模型的误差,在多分类问题中经常在模型最后一层使用Softmax函数作为激活函数,并用交叉熵损失函数作为Loss函数,公式为
(9)
式(9)中:y为真实值;ak为预测结果。又因为在图像分类任务中常常会对数据标签进行one-hot处理,因此损失函数还可以化简为
L=-lnak
(10)
接下来将说明如何使用交叉熵损失函数和梯度下降法更新权重w和偏置b。
假定yi标签值为1,其他标签值为0,可得
(11)
最后一层的激活函数是Softmax,故为
(12)
以此类推,第l-1层有
(13)
式(13)中:
(14)
而权重w和偏置b的更新方法为
(15)
式(15)中:η为学习率,是后期设置的超参数。CNN通过多次正向、反向传播更新模型中的权重和偏置,从而缩小了精度误差,达到提升分类准确率的目的。
3 实验结果与分析
在MNIST和CIFAR-10数据集上将S-ReLU与其他激活函数应用LeNet-5[17]模型进行对比实验,并分析不同激活函数的分类效果。
3.1 实验条件
实验是在硬件参数为i5-7500 CPU,GTX960 GPU的tensorflow-gpu-1.1.0深度学习框架下进行的。在模型开始训练之前,对所有的数据集进行了数据预处理,且对除MNIST数据集之外的数据集使用平移、水平翻转、缩放等数据增强技术[18]以扩充数据。出于节约实验时间和成本的考虑,使用LeNet-5深度学习模型,为了更客观地对比不同激活函数的性能,除改变模型的激活函数外,相同数据集下的其他设置均一致。实验中,参与对比的激活函数为Tanh、ReLU、SoftPlus、ELU、Mish、Swish[19]和S-ReLU,所需参数设置如表1所示。
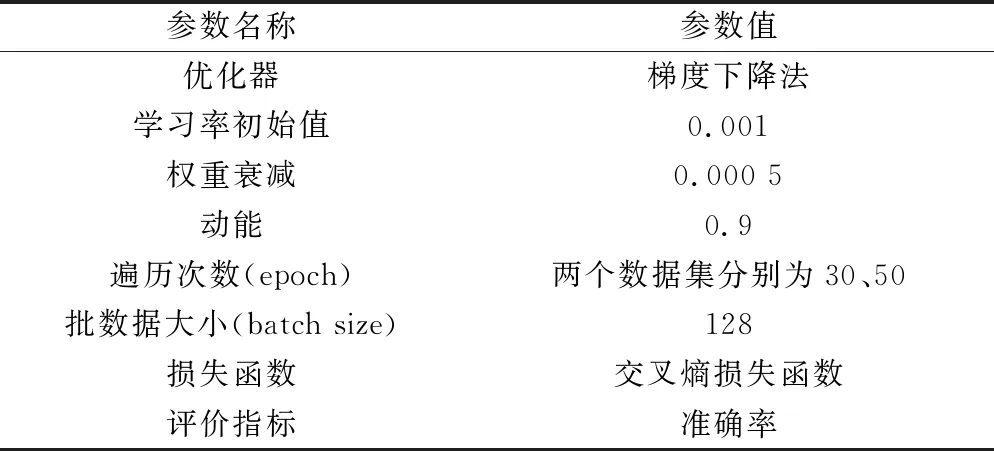
表1 实验超参数及指标设置
实验中采用的数据集是图像分类中最常用的数据集:MNIST[17]和CIFAR-10[20],其详细信息如表2所示。

表2 数据集信息
MNIST数据集有48 000张训练图片、12 000张验证图片和10 000张测试图片,每张图片是大小为28×28的灰度图,类别为0~9的10个数字。
CIFAR-10是由大小为32×32的60 000张RGB图片组成,包含鸟类、汽车、飞机等10个不同类别属性的物种。与MNIST数据集相比,尽管CIFAR-10也是10个类别,但由于其图像包含了更多额外的信息,因此识别难度会更大。
3.2 实验分析
3.2.1 MNIST数据集
MNIST数据集选择LeNet-5网络作为基准框架,其中批数据大小为100,遍历次数为30次。LeNet-5框架下,各个激活函数的分类效果如表3所示。
由表3可知,在遍历次数为30的情况下,7个激活函数都达到了96.9%以上的准确率,其中S-ReLU函数表现最为突出,达到了98.16%的准确率,误差仅为0.058 5。在相同的遍历次数下,与SoftPlus函数相比,准确率提升了1.18%,误差降低了0.0331。ReLU函数达到了97.97%的准确率。Mish与Swish都达到了97.7%以上。饱和激活函数 Tanh的准确率为97.67%,仅高于非饱和激活函数SoftPlus函数,准确率仅提高了0.69%。因此,从以上的实验结果上可知,非饱和激活函数整体上要优于饱和激活函数。
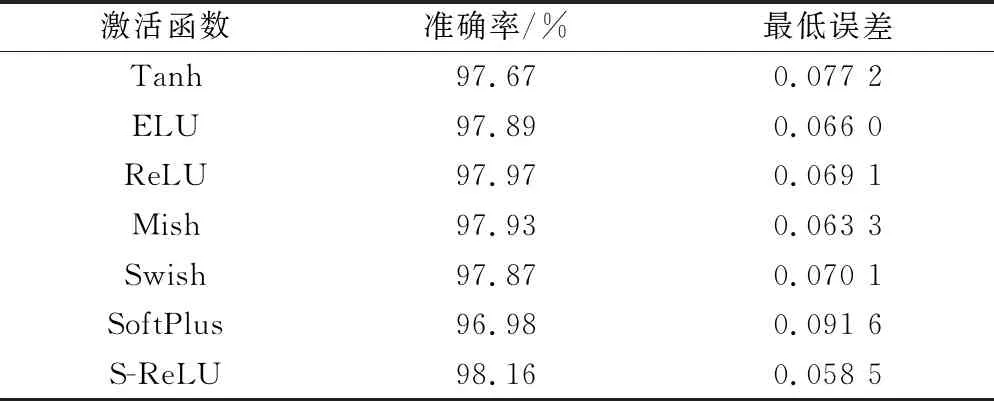
表3 LeNet-5框架下的各个激活函数对比
另外,需要说明的是,由于S-ReLU函数同时含有指数和对数函数,表达式相对复杂,所以在实验中,在同样的遍历次数下,S-ReLU的计算时间会比ReLU等函数更长些。
3.2.2 CIFAR-10数据集
为了进一步探索不同激活函数在同一深度学习框架下的图像分类效果,将7个激活函数应用到CIFAR-10数据集,同样采用LeNet-5框架进行对比实验。
表4可知,构造的S-ReLU函数分类效果最好,其准确率为63.64%,与SoftPlus相比,准确率提高了8.13%。激活函数Tanh 的准确率与非饱和激活函数Swish和SoftPlus相比分别提升了1.18%和3.29%。Mish的准确率为59.90%,仅次于S-ReLU函数。与此同时,Swish的准确率仅有57.62%。与MNIST数据集上的分类结果相比,模型表达能力有所下降,说明同一个激活函数在不同数据集会有不同的表现,因此在以后的实验中可以通过对不同的数据集选择恰当的激活函数的方式提高模型的表达能力。对比表3和表4可以得到,同样是10个类别,CIFAR-10数据集的准确率远低于MNIST数据集,这是由于CIFAR-10数据集是一个三通道的RGB图像,图像更容易受到光照、物体姿态、遮挡等因素的影响,从而导致模型的分类性能有所下降。
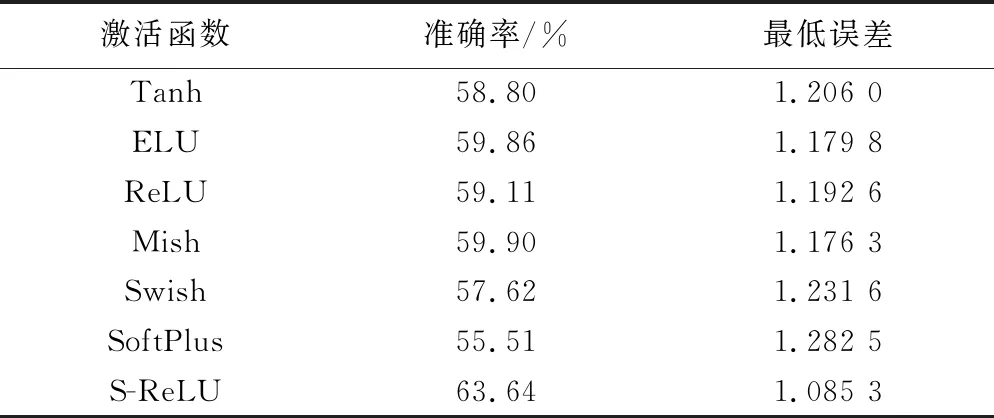
表4 CIFAR-10数据集中不同激活函数的结果比较
4 结论
针对目前函数存在的“神经元死亡”“均值偏移”和人工调参难的问题。提出了新的激活函数,并通过实验分析得到如下结论。
(1)S-ReLU在MNIST、CIFAR-10上均达到了现有激活函数的最好水平,且准确率分别提升了1.18%和8.13%。
(2)解决了ReLU函数的“神经元死亡”的问题,使模型能在为负区域数值引入负激活值和非零导数值的同时,维持了负区域的稀疏性。
(3)S-ReLU函数兼具了ReLU和SoftPlus的优点,负区域取值有正有负,更加贴合生物学上神经元响应的特点,提升了模型的抗干扰能力。
(4)S-ReLU不含有任何自定义的超参数,解决了ELU和LeakyReLU等人工调参的难题,且样本负区域函数是非线性的,提升了模型的非线性表达能力。
为了更好地利用S-ReLU函数的性能,今后还可以研究该激活函数在不同的学习率、优化器的表现,不断探索模型的网络结构,以寻求最优超参数值和模型设计。此外,还能进一步探索S-ReLU函数在目标检测、人脸识别、语义分割等应用场景的表现,拓展S-ReLU的使用范围。
